目录
前言
总结:
第一个问题的解决
基于BlockingQueue的生产者消费者模型
第二个问题的解决
wait的唤醒漏洞
深度理解生产者消费者模型
代码体现
锁的设计
总结:
前言
在多线程的条件变量遗留到此的问题。
#问:条件满足时,我们在唤醒指定的进程 —— 怎么知道条件是否满足?
#问:条件变量中mutex的意义?
1. 例子说明,生产者消费者模型的基本组成概念。

- 供货商只负责(关心)生产,超市只负责(关心)如何将商品卖给消费者。
意义:完成了解耦的过程,通过让不同的角色,进行逻辑解耦,通过超市的方式来进行提高效率。
- 超市去购买供货商的商品,并不是超市需要。是消费者需要,所以超市的本质就是一个商品的缓冲区。
具有交易场所的好处(存在的原因):
因为有缓冲区交易场所的存在,数据可以暂时的放入其中。消费者只用向交易场所索要数据,无需向生产者索要。
- 逻辑层面上解耦:大大的降低了生产者与消费者的耦合度,双方无需见面。
- 目标层面上提高效率:生产者可以提前将数据放入交易场所,消费者可以拿到提前准备好的数据,大大提高效率。
既然这个超市是一个共享资源,所以无论是消费者还是生产者,必须要保证生产者生产的过程、消费者消费的过程,是安全的。
生产者之间、消费者之间:
如果此时有两个供货商,并且超市对二者其中的商品只需要一种,于是此时供货商A与供货商B就具备竞争关系。
同样的道理,当商品只有一个了,而消费者A与消费者B都想要这个商品,于是此时消费者A与消费者B就具备竞争关系。
总结:
组成结构:
- 有二个角色
- 生产者、消费者
- 有一个场所:
- 交易场所(对于生产者、消费者,交易场所是共享资源)
组成关系:
- 生产者和生产者:竞争关系 / 互斥关系。
- 消费者和消费者:竞争关系 / 互斥关系。
- 生产者和消费者:互斥关系、同步关系。
- 互斥:生产者放入并放完了,消费者拿到的才是所需且完整的。
- 同步:没货消费者等待,生产者生产。有货消费者取走,生产者等待。
#问:如何编写生产者消费模型?
本质上就是通过代码来维护:1(场所)、2(角色)、3(关系)原则,代码表现 1、2 。锁和条件变量体现 3 。
2. 用基本工程师思维,重新理解CP。
生产者与消费者 = 线程承担 —— 给线程进行角色划分
交易产所 = 某种数据结构表示的缓冲区
商品 = 数据
也就是说,未来写的代码是有一部分线程生产对应的数据,放在特定数据结构的缓冲区里。另外一部分线程,消费对应的数据,然后对数据进行处理。
- 交易产所中有多少新增商品?—— 生产者最清楚。
- 交易产所中有多少空间足以放置商品?—— 消费者最清楚。
第一个问题的解决
当我们给线程角色化之后,当生产者生产了数据,生产者就会知道这个数据可以被读取了,于是便可以通知消费者。同样,消费者将数据拿走,消费者就会知道空间又有了,于是便可以通知生产者。
于是便可以使得消费者进程与生产者进程,互相同步的完成生产者消费者模型。

#问:消费者如何使用发送过来的数据?
#问:生产者生产的数据是从哪里来的?
基于BlockingQueue的生产者消费者模型
BlockingQueue(阻塞队列),在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)。
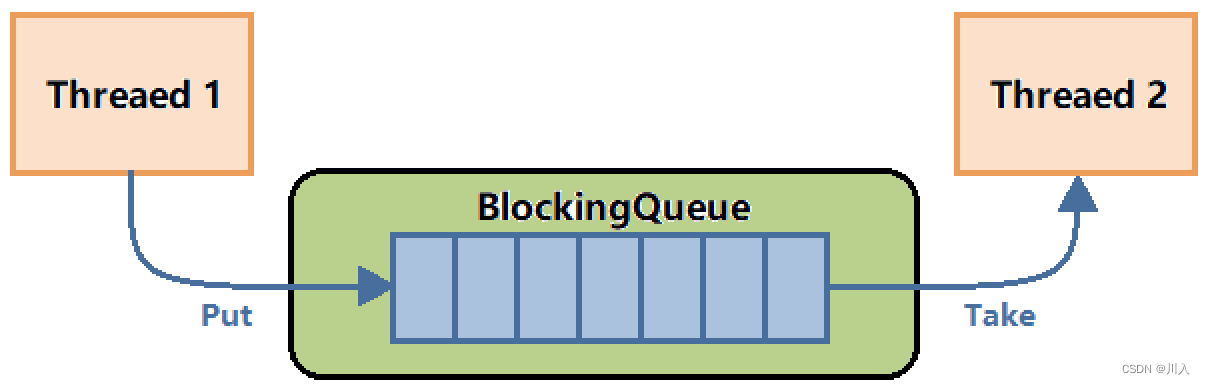
融会贯通的理解:
我们可以发现 BlockingQueue 就与进程间通讯中的管道的概念极为相似,所以前面所学习的进程间通讯的本质就是:
- 前提:让不同的进程看见同一份资源。
- 本质:生产者消费者模型。
管道本身就是一个简单的阻塞队列,有数据就消费,没数据就等。
STL中,一般的容器都不是线程安全的,因为大部分容器都有自动扩容的功能(空间适配器),其是自动扩容,归还空间、申请空间,就是访问全局数据结构 —— 不安全,一般STL是为了支持支撑我们去进行高新能服务,但是线程完全就需要用户自己维护了。
我们需要封装实现一个BlockingQueue,即阻塞队列存储位置是需要的,其次我们需要读取和存储数据,所以就需要知道该阻塞队列的容量大小:
std::queue<T> bq_; // 阻塞队列
int capacity_; // 容量上限有生产者向BlockingQueue中放数据,消费者向BlockingQueue中取数据,所以BlockingQueue就是共享资源,就很可能出现生产者正在生产,消费者就来消费了,也就是说生产者线程正在push,消费者线程就直接跑上来读取pop,导致访问出错。于是需要通过互斥锁保证队列安全:
pthread_mutex_t mtx_; //通过互斥锁保证队列安全消费者向BlockingQueue中取数据,问题是说明时候拿数据,怎么知道什么时候有的数据,就会导致消费者频繁的申请锁、释放锁,甚至生产者线程申请锁抢不过消费者线程,导致生产者无法成功生产数据,消费者就无法拿到数据,造成内耗。所以需要使用条件变量,让生产者注意满(不可生产了),消费者注意空(不可消费了):
pthread_cond_t isEmpty_; // 用其表示阻塞队列,是否为空的条件 - 消费者
pthread_cond_t isFull_; // 用其表示阻塞队列,是否为满的条件 - 生产者第二个问题的解决
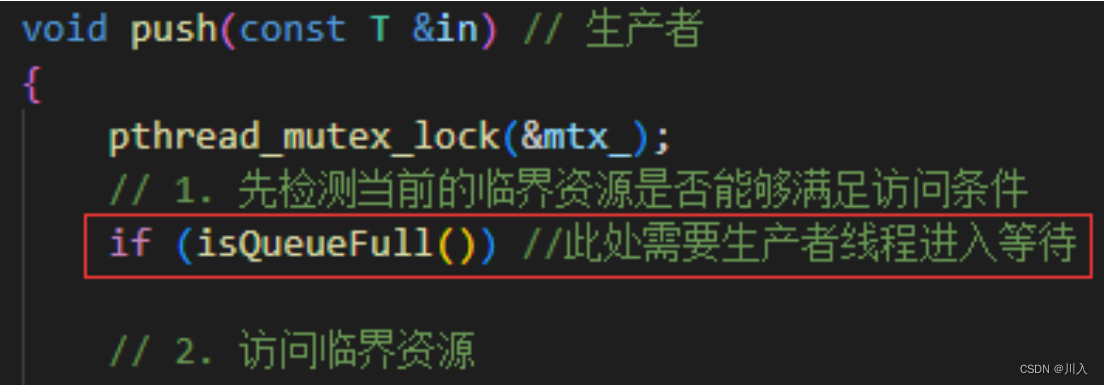
但是我们可以发现一个问题。我们的生产者线程,因为条件不满住而进入等待,但是检测当前的临界资源是否能够满足访问条件是处于临界区中的。
#问:所以这线程是持有锁的!如果他去等待了,锁该怎么办呢?
pthread_cond_wait第二个参数是一个锁,当成功调用wait之后,传入的锁,会被自动释放!因为生产者线程因为条件不满足,而导致进入等待,如果其将锁一起带走挂起等待,就会导致消费者没有办法申请锁进行数据的读取。生产者线程的挂起就没有意义了。
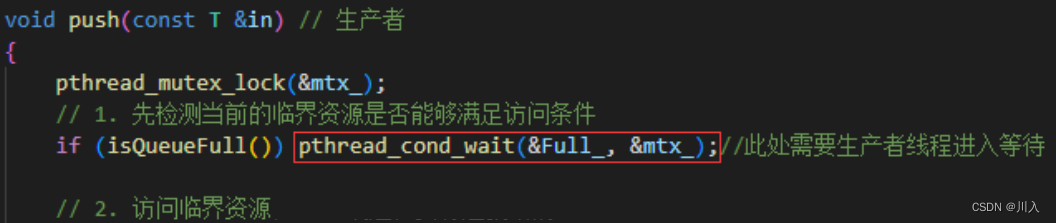
现在我们知道了,其是如何被挂起等待的,那:
#问:线程被唤醒时,其从哪里醒来?
(所谓的挂起,在代码级别的表现就是,该线程会在pthread_cond_wait函数处阻塞)从哪里阻塞挂起,就从哪里唤醒,被唤醒的时候,我们还是在临界区被唤醒的。
#问:线程被唤醒时,在临界区被唤醒,锁呢?
当我们被唤醒的时候,pthread_cond_wait,会自动帮助我们线程获取锁。
#问:生产者都被挂起了如何知道的,资源就绪?对于消费同样的道理,如何知道的?
作为一个生产者,确实无法得知资源的就绪,所以使用加锁并检测的,并且挂起也确实更不可能知道。但是:
- 生产者需要的资源 - 消费者知道。所以:生产者由消费者唤醒。
- 消费者需要的资源 - 生产者知道。所以:消费者由生产者唤醒。
发送生产和消费的唤醒的条件变量通知时候,对应方如果没有等待,没任何问题。接收方会自动将这个通知信息丢弃。
于是此时我们就完成了一个极为简易的生产者消费者模型:
BlockQueue.hpp
#pragma once
#include <queue>
#include <iostream>
#include <pthread.h>
// #define INT_TX(mtx) pthread_mutex_init(&mtx, nullptr)
const int gDefaultCap = 5;
template <class T>
class BlockQueue
{
private:
bool isQueueEmpty()
{
return bq_.size() == 0;
}
bool isQueueFull()
{
return bq_.size() == capacity_;
}
public:
BlockQueue(const int capacity = gDefaultCap) : capacity_(capacity)
{
// INT_TX(mtx_);
pthread_mutex_init(&mtx_, nullptr);
pthread_cond_init(&Empty_, nullptr);
pthread_cond_init(&Full_, nullptr);
}
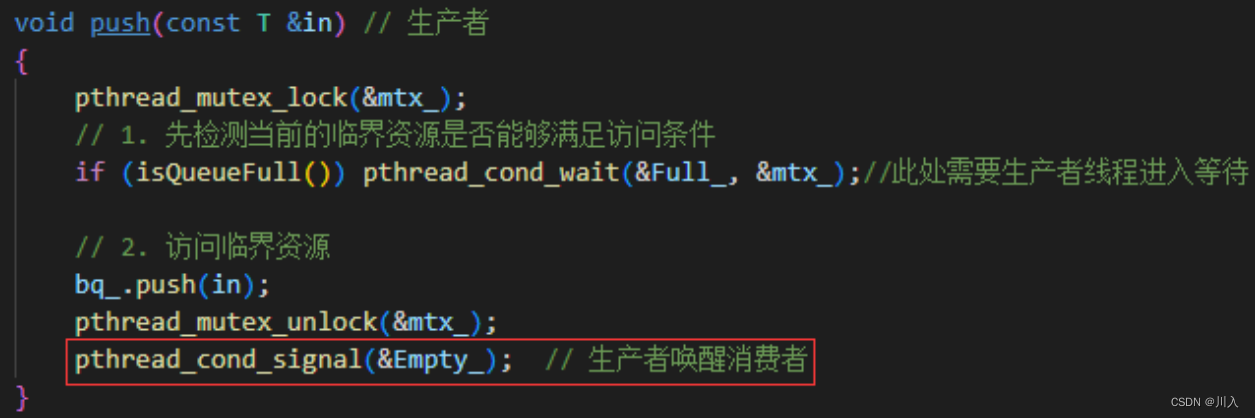
void push(const T &in) // 生产者
{
pthread_mutex_lock(&mtx_);
// 1. 先检测当前的临界资源是否能够满足访问条件
if (isQueueFull()) pthread_cond_wait(&Full_, &mtx_);//此处需要生产者线程进入等待
// 2. 访问临界资源
bq_.push(in);
pthread_mutex_unlock(&mtx_);
pthread_cond_signal(&Empty_); // 生产者唤醒消费者
}
void pop(T *out) // 消费者
{
pthread_mutex_lock(&mtx_);
// 1. 先检测当前的临界资源是否能够满足访问条件
if (isQueueEmpty()) pthread_cond_wait(&Empty_, &mtx_);//此处需要消费者线程进入等待
// 2. 访问临界资源
*out = bq_.front();
bq_.pop();
pthread_mutex_unlock(&mtx_);
pthread_cond_signal(&Full_); // 生产者唤醒消费者
}
~BlockQueue()
{
pthread_mutex_destroy(&mtx_);
pthread_cond_destroy(&Empty_);
pthread_cond_destroy(&Full_);
}
public:
std::queue<T> bq_; // 阻塞队列
int capacity_; // 容量上限
pthread_mutex_t mtx_; // 通过互斥锁保证队列安全
pthread_cond_t Empty_; // 用其表示阻塞队列,是否为空的条件 - 消费者等
pthread_cond_t Full_; // 用其表示阻塞队列,是否为满的条件 - 生产者等
};ConProd.cc
#include "BlockQueue.hpp"
#include <unistd.h>
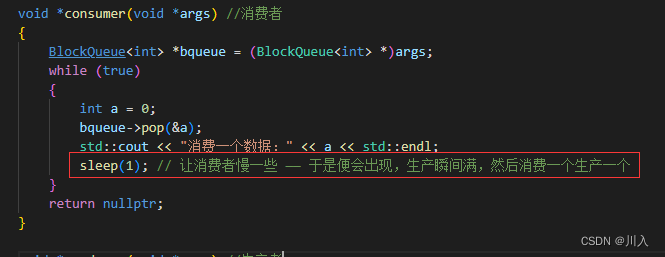
void *consumer(void *args) // 消费者
{
BlockQueue<int> *bqueue = (BlockQueue<int> *)args;
while (true)
{
int a = 0;
bqueue->pop(&a);
std::cout << "消费一个数据:" << a << std::endl;
sleep(1); // 让消费者慢一些 —— 于是便会出现,生产瞬间满,然后消费一个生产一个
}
return nullptr;
}
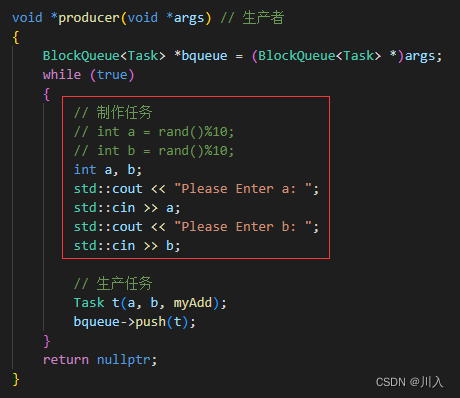
void *producer(void *args) // 生产者
{
BlockQueue<int> *bqueue = (BlockQueue<int> *)args;
int a = 1;
while (true)
{
bqueue->push(a);
std::cout << "生产一个数据:" << a++ << std::endl;
}
return nullptr;
}
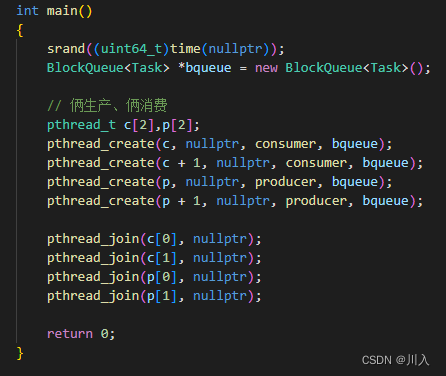
int main()
{
BlockQueue<int> *bqueue = new BlockQueue<int>();
pthread_t c, p;
pthread_create(&c, nullptr, consumer, bqueue);
pthread_create(&p, nullptr, producer, bqueue);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
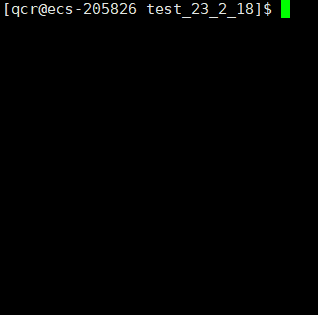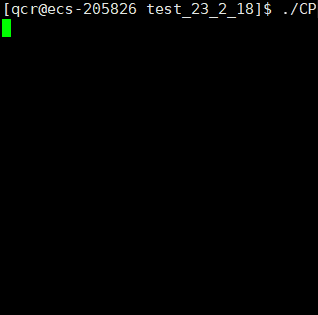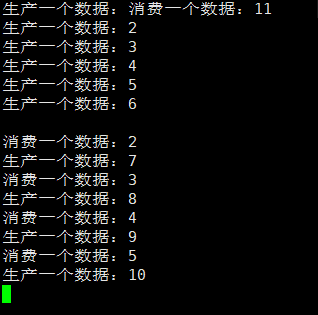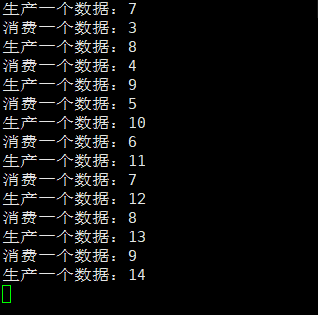
}上述代码关键点:
(生产者不sleep)
补充:
对于消费者不sleep、生产者sleep是同理的,消费因为生产慢而变慢了,即:生产一个消费一个。
在实际生产、消费的时候,我们是可以加一些策略的,不一定非要生产一个消费一个。假如生产的要慢一些,那么我们可以通过让生产者生产的数据超过总容量的一半的时候,才来消费。如何知晓数据是否超过一般,就需要进行访问类成员capacity_,而其就是临界资源。所以:
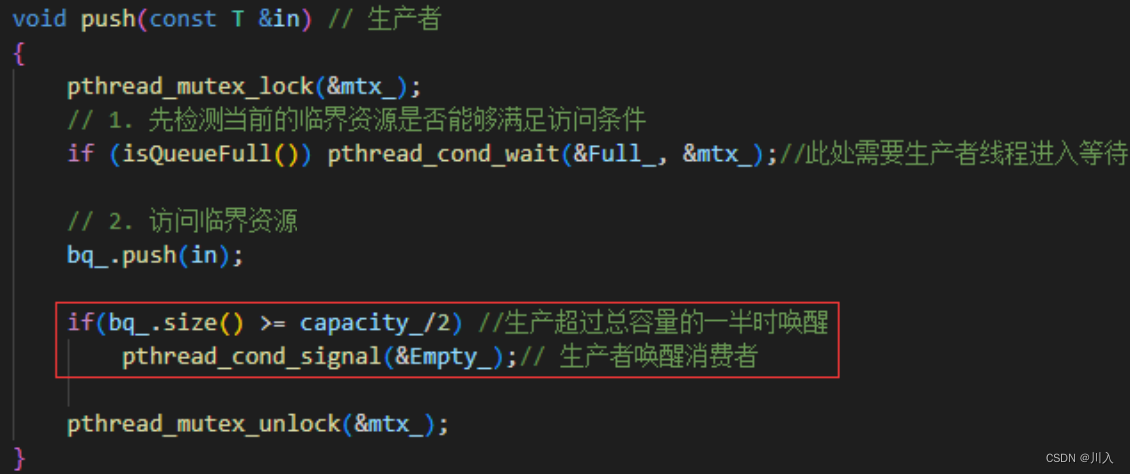
#问:为什么唤醒在解锁之前、解锁之后都没有问题?
- 解锁之前唤醒:被唤醒的线程,本来是在条件变量下等,现在变为了在锁上等(因为生产者还没释放锁,但是在对应的条件变量唤醒了)。
如果是多个线程,也就是说多个线程在等待条件变量,可是我们也就唤醒一个线程。就算是唤醒全部等待线程,也就是唤醒的所有线程和正执行的线程竞争锁。
- 解锁之后唤醒:唤醒之后,去申请释放的锁。如果也就是刚唤醒,锁已经被其他线程拿走了,没有关系,唤醒的去锁上等待。这个时候,该线程是重新去竞争这把锁,在竞争成功后才会被彻底的唤醒,然后继续(wait)向后执行。
Note:
解锁之前、解锁之后释放,完全没有问题,也就是在对应的一个条件变量下等待,唤醒后去申请一个锁,申请了锁,大不了就锁上等待。
上面的实现就基本完善了,但是是一个不完整的代码,还有问题在:
wait的唤醒漏洞
pthread_cond_wait:只要是一个函数,就可能调用失败。
也就是说,pthread_cond_wait只要在调用的时候,如果调用失败也就是,没有被成功阻塞。线程也就会继续向后执行,对于如生产者,执行的时候队列是满的。此时也就因为使用的是STL,就导致数据个数超过我们设置的capacity_,是不合理的。
pthread_cond_wait:可能存在伪唤醒的情况。
当前唤醒条件并未满足,就唤醒了当前线程,因为signal的唤醒是比较简单粗暴的,其并不清楚其他线程什么状况,反正执行了就直接唤醒。
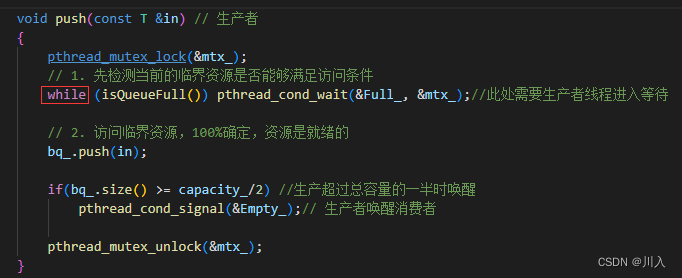
对于以上两种情况,正确做法应该是:
不应该让其继续向后访问,而是让其重新回过头,醒来时不是继续向后执行,而时重新再次确认一下,当前的生产 / 消费条件,是否满足要求。
深度理解生产者消费者模型
#问:生产者生产数据到缓冲区,消费者从缓冲区消费数据,这不就是数据的来回拷贝吗?那所谓的效率提高体现在哪里?
#问:消费者如何使用发送过来的数据?
不管从哪来(如网络上获取),反正要很多时间去获取数据。
#问:生产者生产的数据是从哪里来的?
消费者也要花费很多的时间,处理所拿到的数据。
通过学习可以发现:
虽然有条件变量来同步生产者、消费者的执行顺序,但是生产过程和消费过程依然时互斥的。是串行的访问对应的缓冲区(厂库)数据,这么看来也并没有提高效率。所以其实生产者消费者模型提高的效率体现不在这。
比如消费线程在拿到线程后需要花很多的时间去处理数据,当期申请数据的时候,可并没有访问厂库、申请锁(因为数据已经被消费者线程拿到,并处于自己的上下文当中)。所以当其处理数据的时候,生产者可以继续花费时间去生产数据,同时还可以将数据放到缓冲区(厂库)里。所以两个线程就是实现了,一定程度上的并发。
所以生产者消费者模型的效率的提高:主要体现在,通过缓冲区的特点,实现生产和消费,更好的利用生产者线程和消费者线程,来提高它们的并发度。
生产者忙于生产(找)数据,消费者可以使用缓冲区中的历史数据,进行处理 —— 并发执行。
代码体现
我们需要是,在往代码当中,也就是阻塞队列当中,投递任务。让生产者和消费者处理数据的过程。
我们封装一个计算器的处理方式:
我们生成一个计算任务,然后将这个计算任务交给对应的消费线程,让消费线程来完成这个任务。
Task.hpp
#pragma once
#include <iostream>
#include <functional>
typedef std::function<int (int, int)> func_t;
class Task
{
public:
Task()
{}
Task(const int a, const int b, func_t func):a_(a), b_(b), func_(func)
{}
int operator()()
{
return func_(a_, b_);
}
int getTheA(){ return a_; }
int getTheB(){ return b_; }
private:
int a_;
int b_;
func_t func_;
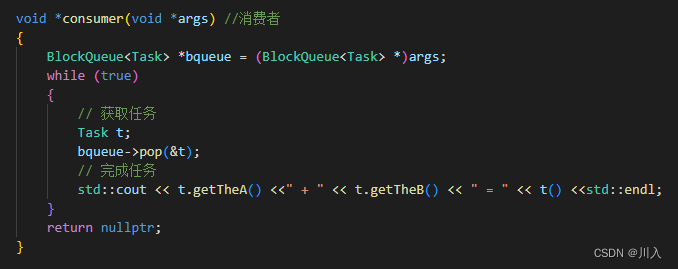
};消费者线程:
生产者线程:

BlockQueue.hpp
#pragma once
#include <queue>
#include <pthread.h>
// #define INT_TX(mtx) pthread_mutex_init(&mtx, nullptr)
const int gDefaultCap = 5;
template <class T>
class BlockQueue
{
private:
bool isQueueEmpty()
{
return bq_.size() == 0;
}
bool isQueueFull()
{
return bq_.size() == capacity_;
}
public:
BlockQueue(const int capacity = gDefaultCap) : capacity_(capacity)
{
// INT_TX(mtx_);
pthread_mutex_init(&mtx_, nullptr);
pthread_cond_init(&Empty_, nullptr);
pthread_cond_init(&Full_, nullptr);
}
void push(const T &in) // 生产者
{
pthread_mutex_lock(&mtx_);
// 1. 先检测当前的临界资源是否能够满足访问条件
while (isQueueFull()) pthread_cond_wait(&Full_, &mtx_);//此处需要生产者线程进入等待
// 2. 访问临界资源,100%确定,资源是就绪的
bq_.push(in);
if(bq_.size() >= capacity_/2) //生产超过总容量的一半时唤醒
pthread_cond_signal(&Empty_);// 生产者唤醒消费者
pthread_mutex_unlock(&mtx_);
}
void pop(T *out) // 消费者
{
pthread_mutex_lock(&mtx_);
// 1. 先检测当前的临界资源是否能够满足访问条件
while (isQueueEmpty()) pthread_cond_wait(&Empty_, &mtx_);//此处需要消费者线程进入等待
// 2. 访问临界资源,100%确定,资源是就绪的
*out = bq_.front();
bq_.pop();
pthread_mutex_unlock(&mtx_);
pthread_cond_signal(&Full_); // 生产者唤醒消费者
}
~BlockQueue()
{
pthread_mutex_destroy(&mtx_);
pthread_cond_destroy(&Empty_);
pthread_cond_destroy(&Full_);
}
public:
std::queue<T> bq_; // 阻塞队列
int capacity_; // 容量上限
pthread_mutex_t mtx_; // 通过互斥锁保证队列安全
pthread_cond_t Empty_; // 用其表示阻塞队列,是否为空的条件 - 消费者等
pthread_cond_t Full_; // 用其表示阻塞队列,是否为满的条件 - 生产者等
};ConProd.cc
#include "BlockQueue.hpp"
#include "Task.hpp"
#include <unistd.h>
#include <iostream>
#include <ctime>
// 加法
int myAdd(int x, int y)
{
return x + y;
}
void *consumer(void *args) //消费者
{
BlockQueue<Task> *bqueue = (BlockQueue<Task> *)args;
while (true)
{
// 获取任务
Task t;
bqueue->pop(&t);
// 完成任务
std::cout << t.getTheA() <<" + " << t.getTheB() << " = " << t() <<std::endl;
}
return nullptr;
}
void *producer(void *args) //生产者
{
BlockQueue<Task> *bqueue = (BlockQueue<Task> *)args;
while (true)
{
// 获取任务
int a = rand()%10;
int b = rand()%10;
Task t(a, b, myAdd);
// 生产任务
bqueue->push(t);
}
return nullptr;
}
int main()
{
srand((uint64_t)time(nullptr));
BlockQueue<Task> *bqueue = new BlockQueue<Task>();
pthread_t c, p;
pthread_create(&c, nullptr, consumer, bqueue);
pthread_create(&p, nullptr, producer, bqueue);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
}
甚至可以:
上述都是单生产、单消费,如果是多生产、多消费,这个时候再使用前面所写的代码,照样是可以的。因为我们用的是互斥锁,就这一把锁,既能维护多生产也能维护多消费,都是再竞争的情况下,只有谁竞争成功了,才能进入区间(临界区)当中。
#问:多生产、多消费的意义?
我们可以发现,在多生产、多消费中,生产和生产、消费和消费,也是互斥关系!维护这种关系,使得增加了竞争锁的成本。所以意义不在这个表面上,而是如果任务很多,一个消费者线程拿出数据进行处理的时候,其余的线程也可以进入缓冲区中去竞争任务,另一个消费者线程拿出数据也可以跑去处理。
多生产、多消费的主要意义:
让生产行为和消费行为,即:生产之前、消费之后,可以并发的有多个执行流同时进行生产、同时进行数据处理。
所以,当生产数据需花费时间大量、处理数据花费时间大量,就可以搞成多生产、多消费。
Note:
中间的交易场所,更多的是为了解决生产和消费的耦合度问题,以此让他俩可以并发起来。
#问:如何理解,如果有多个消费者(生产者),多个消费者(生产者)的并发?
不可能在获取任务时并发,因为它们彼此与彼此之间是互斥的。而最耗费时间的并不是拿任务这个过程,而是生产和处理的过程,并发并不是拿任务并发,而是处理任务并发,这也就是提高效率的关键所在。
#问:是不是消费者(生产者)越多越好?
不是说线程越多就越好,假设该任务耗费的时间就不长,很快的处理完成,这个时候使用很多线程并发执行,就是不合理的、没有意义。这个时候主要的体系反而最耗费时间的,反而是从缓冲区拿数据。
多线程,操作系统还要调度,而其中的上下文切换等,反而使得成本上升。
锁的设计
利用类变量lockGuard,利用其属于栈上开辟的临时对象,将我们需要加锁的mtx_,传进去。其中构造lockguard对象就必定会调用其构造函数,其内部会自动lock。
这之后我们就无需再自己调用解锁了,因为其是代码块级别的代码,所以lockguard对象只会在该代码块中有效,即:走出代码块,lockguard对象会自动调用析构函数,其内部会自动unlock。
总结:
深刻理解条件变量:
#问:为什么要有条件变量?
就是为了判定某些条件满不满足。根本原因就是每一个线程想访问临界资源,其必须要先申请锁,进入之后才能到所谓的临界区中,才能通过检测发现临界资源满不满足,然后才能被访问。
(先持有锁,再检测资源),这也就是为什么条件变量与互斥锁经常耦合在一起的原因。
Note:
有互斥锁:为了保证安全。
有条件变量:互斥锁只能够互斥,里面的资源使用,需要资源满足对应要求 —— 检测。




![[架构之路-121]-《软考-系统架构设计师》-计算机体系结构 -3-汇编语言与ARM系统的初始化](https://img-blog.csdnimg.cn/img_convert/a61431ba399354b5d5fd596471fdbc23.png)