集合
- 前言:图片
- 一、集合分类
- 1、实现 Collection 接口
- 2、实现 Map 接口
- 二、实现类定义
- 1、ArrayList(非线程安全)
- 2、LinkedList(非线程安全)
- 3、HashSet(非线程安全)
- 4、TreeSet(非线程安全)
- 5、HashMap(非线程安全)
- 6、HashTable (线程安全)
- 7、TreeMap(非线程安全)
- 三、常见面试题
- 1、线程安全(注意)
- 2、Java中常用的容器有哪些?
- 3、Arraylist 和 LinkedList的区别?
- 4、说说ArrayList 的扩容机制?
- 5、Array和ArrayList有何区别?
- 6、遍历 List 有哪些方法?
前言:图片
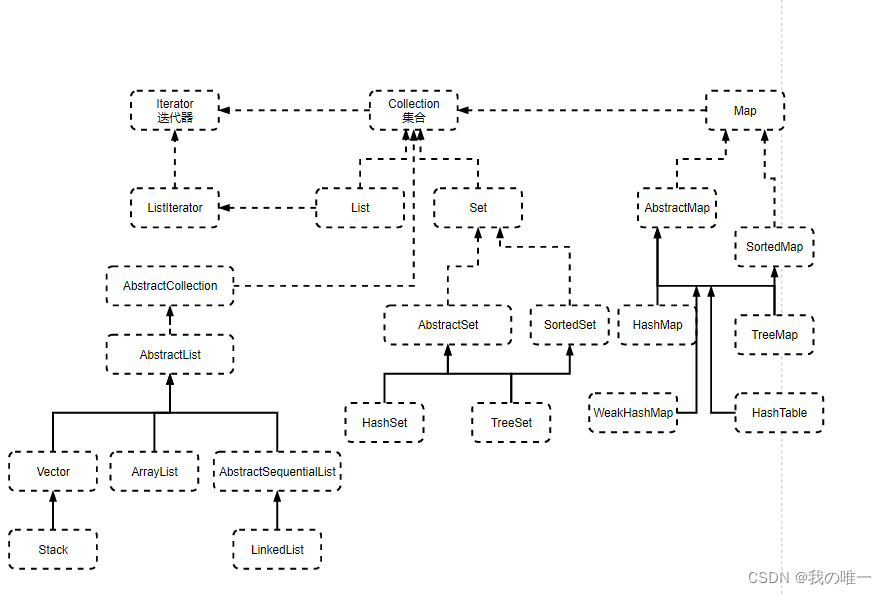
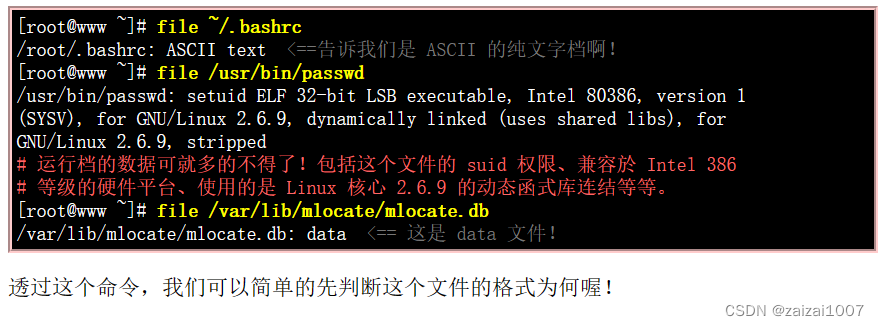
集合类是用来存放某类对象的。集合类有一个共同特点,就是它们只容纳对象(实际上是对象名,即指向地址的指针)。这一点和数组不同,数组可以容纳对象和简单数据。如果在集合类中既想使用简单数据类型,又想利用集合类的灵活性,就可以把简单数据类型数据变成该数据类型类的对象,然后放入集合中处理,但这样执行效率会降低。
一、集合分类
1、实现 Collection 接口
常见 List - 有序可重复接口集合(包含 ArraryList、LinkedList)、Set - 无序不重复集合(包含HashSet、TreeSet)。
2、实现 Map 接口
常见Map - 键值对形式 <k,v> 集合(包含HashMap、HashTable 和 TreeMap)。
二、实现类定义
1、ArrayList(非线程安全)
List接口的大小可变数组(动态数组)的实现,位于API文档的java.util.ArrayList。实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。
2、LinkedList(非线程安全)
一种常见的基础数据结构,是一种线性表(通过链表实现的),但是链表不会按线性表的顺序存储数据,而是每个节点里存到下一个节点的地址
3、HashSet(非线程安全)
基于HashMap实现的,容器中只能存储不重复的对象,可以 null 的集合。
4、TreeSet(非线程安全)
一个有序的集合,它的作用是提供有序的Set集合。
5、HashMap(非线程安全)
实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
6、HashTable (线程安全)
根据关键码值(Key value)而直接进行访问的数据结构。
7、TreeMap(非线程安全)
不仅实现了Map接口,还实现了java.util.SortMap接口,因此集合中的映射关系具有一定的顺序.但是在添加,删除,和定位映射关系上,TreeMap类比HashMap类的性能差一些。
三、常见面试题
1、线程安全(注意)
HashTable 是常见集合中唯一一个线程安全的
2、Java中常用的容器有哪些?
- Set
TreeSet 基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
HashSet 基于HashMap实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet 是 HashSet 的子类,并且其内部是通过 LinkedHashMap 来实现的。内部使用双向链表维护元素的插入顺序。 - List
ArrayList 基于动态数组实现,支持随机访问。
Vector 和 ArrayList 类似,但它是线程安全的。
LinkedList 基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。 - Queue
LinkedList 可以用它来实现双向队列。
PriorityQueue 基于堆结构实现,可以用它来实现优先队列。
ArrayQueue基于数组实现,可以用它实现双端队列,也可以作为栈。
TreeMap 基于红黑树实现。 - HashMap
1.7基于数组+链表实现,1.8基于数组+链表+红黑树。链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。 - HashTable 和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入
- HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。(现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高(1.7 ConcurrentHashMap 引入了分段锁, 1.8 引入了红黑树)。)
- LinkedHashMap继承自 HashMap。使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
详见二所述
3、Arraylist 和 LinkedList的区别?
- ArrayList
底层是基于数组实现的,查找快,增删较慢。LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - LinkedList
底层是基于链表实现的。确切的说是循环双向链表(JDK1.6之前是双向循环链表、JDK1.7之后取消了循环),查找慢、增删快。LinkedList链表由一系列表项连接而成,一个表项包含3个部分︰元素内容、前驱表和后驱表。因此内存空间占用比ArrayList 更多。
4、说说ArrayList 的扩容机制?
(1)当使用add方法的时候首先调用ensureCapacityInternal方法,传入 size+1进去,检查是否需要扩容
(2)如果空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA,就初始化为默认大小10,获取“默认的容量”和要扩容的大小两者之间的最大值
(3)和当前数组长度比较,如果 if (minCapacity - elementData.length > 0)执行grow扩容方法
(4)将数组扩容为原来的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1);
(5)检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量
(6)再检查新容量newCapacity 是否超出了ArrayList所定义的最大容量,若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE(MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8)
(7)ArrayList 中copy数组的核心就是System.arraycopy方法,将original数组的所有数据复制到copy数组中,这是一个本地方法
5、Array和ArrayList有何区别?
- Array可以容纳基本类型和对象,而ArrayList只能容纳对象
- Array是指定大小的,ArrayList 的容量是根据需求自动扩展
- ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等
6、遍历 List 有哪些方法?
- for循环遍历:遍历者自己在集合外部维护一个计数器,依次读取每一个位置的元素
- Iterator遍历:基于顺序存储集合的Iterator可以直接按位置访问数据。基于链式存储集合的Iterator,需要保存当前遍历的位置,然后根据当前位置来向前或者向后移动指针
- foreach遍历:也就是增强for循环,foreach内部也是采用了Iterator的方式实现,但使用时不需要显示地声明Iterator
- 本人最经常用的是 for 循环,主要是由下标,可以进行更多操作。
未完待续。。。
学习了一晚上的集合,发现集合里的东西真的蛮多的 ~~~ , 在现在实际开发中一般只是用ArrayList 和 HashMap,对其他的确实了解的不是很透彻,为了性能,可以使用更多的!