问题背景:
在对一套两节点Oracle RAC19.18集群进行部署时,出现启动数据库实例就会出现主机出现重启的情况,检查发现主机重启是由于节点集群被驱逐导致。
问题:
两节点Oracle RAC19.18集群,启动数据库实例会导致主机出现重启。
问题分析:
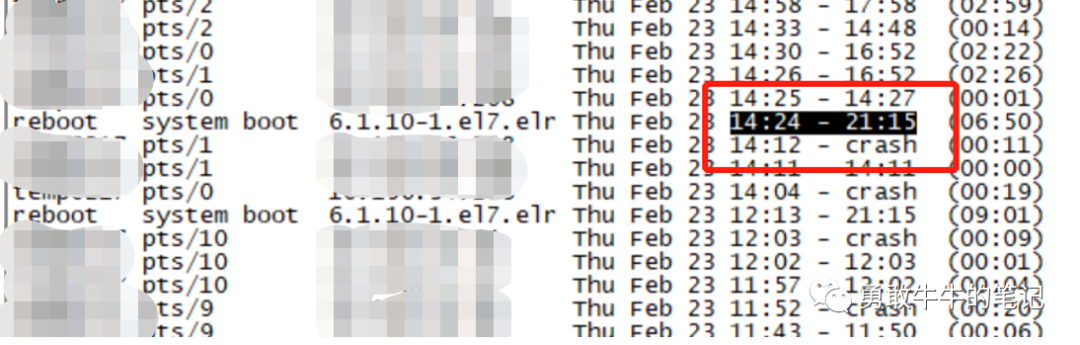
主机多次出现重启,拿最近一次节点一的重启时间2023-02-23 14:24进行分析
首先查看节点一主机的日志/var/log/messages,只有主机14:24:00的启动日志,除此以外没有明显的错误信息,主机日志没有提供有价值的信息。
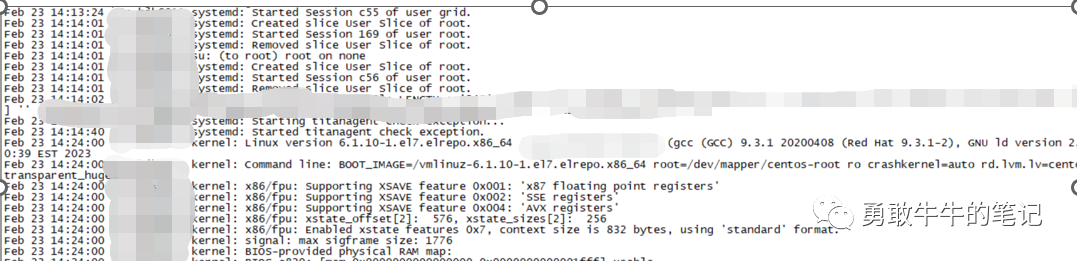
查看节点一的集群的alert日志,在14:19:04出现节点一被节点二驱逐的信息this node was evicted by node 2以及出现reboot advisory message text:oracssdagent,这里我们可以确认主机重启的原因是由于节点一被驱逐所导致。

在节点二的集群alert日志,可以看到14:18:53节点二ASM发起kill节点一成员ASM的信息Member kill issued by PID for 1members,group DB:+ASM。
在14:19:03升级为节点驱逐,节点二发起节点一驱逐"Member kill issued by node 2 is being escalated to evict node 1 。

查看节点一,节点二的ocssd日志ocssd.trc,进一步分析被驱逐的原因,
节点一在14:15:29开始出现检查gipc超时的信息gipcretTimeout。

节点一在14:18:48ocssd出现进程终止Death被隔离以及gipc网络断开的报错。

节点二在14:18:53发起了kill member ASM的操作Kill requested for group DB+ASM。

节点二由于kill member的操作没有在规定时间内完成升级,在14:19:03升级为节点驱逐 node kill。

节点一的ocssd日志显示,在14:19:04,在节点一执行的驱逐操作都出现异常abort,驱逐是通过异常终止的方式。


从节点二的ocssd日志来看,直到14:19:30驱逐节点一的操作还没完成node(1) exceeded graceful shutdown,并且由于配置IPMI管理员用户,IPMI-kill管理口登陆主机的方式进行重启也没法进行Node kill could not beperformed. Admin or connection validation failed。

直到14:19:31,节点一的cssagent/cssmonit监控不到ocssd的本地心跳,发起了主机重启,整个节点驱逐才结束。

所以,整个对节点一的驱逐过程,一开始是从节点二的ASM发起的成员驱逐member kill,由于member kill没有在规定时间内完成,升级为节点驱逐node kill,节点驱逐最终触发了节点一的主机重启,驱逐之前集群的ocssd的网络,存储以及本地心跳正确,可能存在问题的地方在发起驱逐的ASM实例以及gipc进程。
接下来,分析ASM实例的alert日志以及trc文件
节点一ASM的alert日志,在14:18:33出现节点二的驱逐信息Received an instance abort message from instance 2,除此以外没有明显的异常信息。
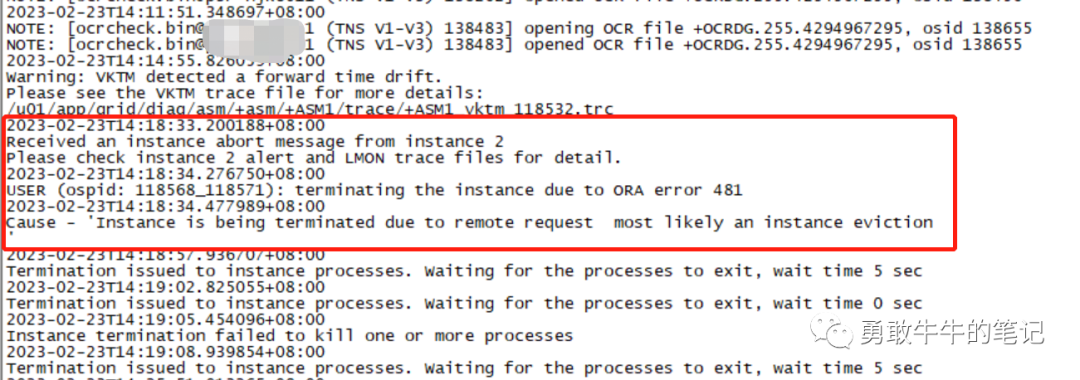
节点二ASM的alert日志,可以发现14:17:58在节点二LMD与节点一的通信出现问题Communications reconfiguration: instance_number 1 from LMD0。
节点二14:18:33发起了实例驱逐Evicting instance 1 from cluster。

节点二查看LMD的进程trc文件,出现等待节点一ACK返回超时。

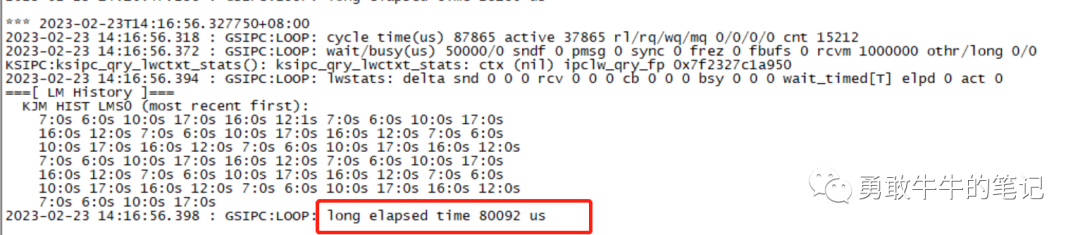
问题时间段节点一并没有产生的LMD,LMON日志,只能从LMS进程去分析是否存在其他问题,LMS进程的日志显示出现调用时间过长的信息GSIPC:LOOP: long elapsed time 80092 us,进程可能存在资源不够的问题。
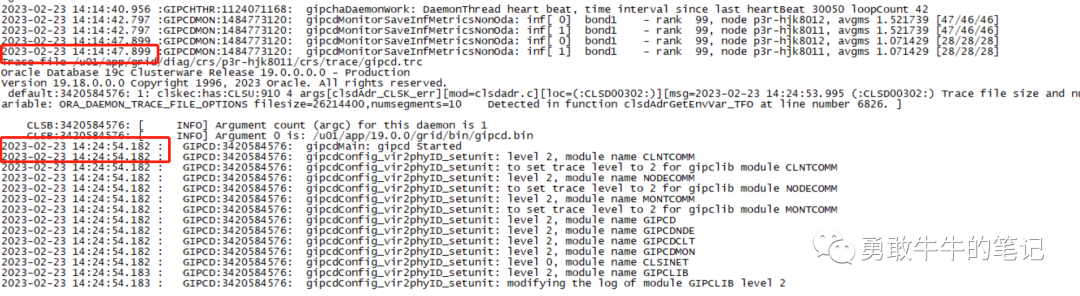
接下来分析节点一的GIPC进程日志,发现存在异常的地方缺失了14:14:47-14:24:54日志,分析到这里,结合之前gipc进程超时、LMD进程超时、进程日志写丢失,严重怀疑操作系统的资源存在问题。
查看问题时间段的OSW监控信息,发现存在内存耗尽的情况,可以看到从14:10:21的剩余内存394G到最后一次记录14:14:22的剩余内存29G,平均每分钟使用内存70G+(这个时间段正在启动数据库实例),按照这个内存使用在14:15分之后主机的内存已经耗尽,这个内存耗尽时间与问题发生时间(14:15:29~14:19:30)一致。
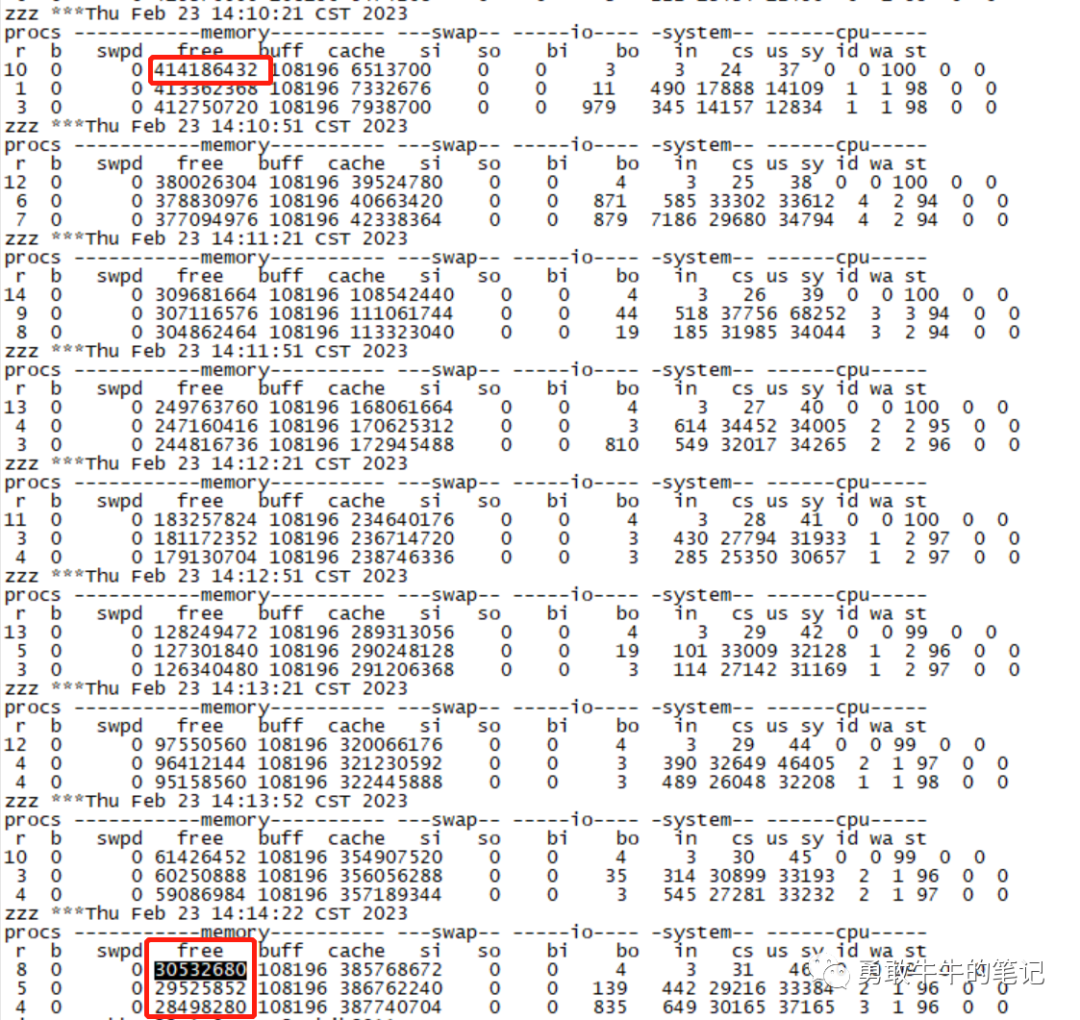
分析主机内存耗尽的原因,当前主机的内存配置为1TB,实例的SGA+PGA内存为650G,其中SGA内存占450G,这个内存配置正常情况下内存还是足够的充裕的。
查看内存的配置情况,发现配置的600GB大页内存完全没有被数据库实例所使用,也就是说实例启动的SGA 450G内存全初始化到非大页内存(424G)里面,所以导致剩余的内存被耗尽。
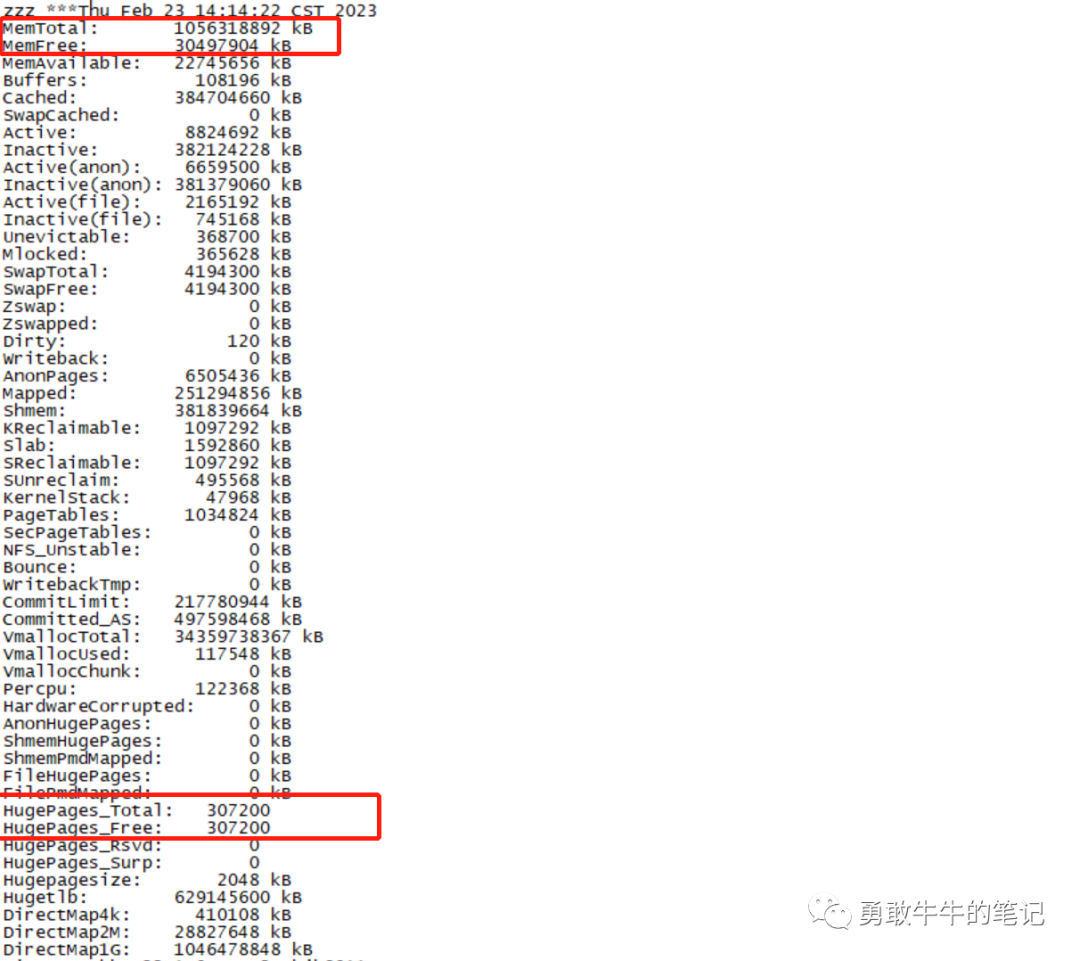
问题原因:
综合上述的分析信息,我们可以确认RAC集群主机重启的原因为:
1 集群节点一被节点二驱逐引发了节点一的ocssd进程异常终止,导致ocssd监控进程cssagent/cssmonit监控不到ocssd的本地心跳,触发了主机重启。
2 集群节点二驱逐节点一的原因为,节点一的主机内存耗尽引发集群GIPC,LMD进程异常,导致节点一无法正常响应节点二的通信,触发了节点驱逐。
3 节点一主机内存耗尽的原因为,数据库的大页内存没有被使用,导致数据库实例的SGA内存全初始化到非大页内存里面,导致剩余的内存被耗尽。
问题解决:
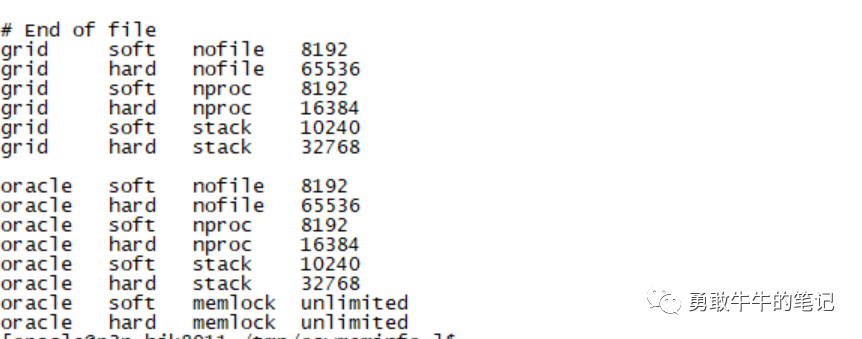
查看用户大页内存的配置/etc/security/limits.conf,oracle用户当前配置memlock并没有问题。
重启主机以及数据库实例,大页内存也没有得到使用,之后在MOS上查到大页内存未被使用的文章Not Able To Start The Database, fails with ORA-27125: unable to create shared memory segment (Doc ID 2242978.1)
文章里面说到大页内存有可能需要配置操作系统权限来创建部分共享大页,通过为Oracle用户配置参数vm.hugetlb_shm_group=<gid>以分配权限。
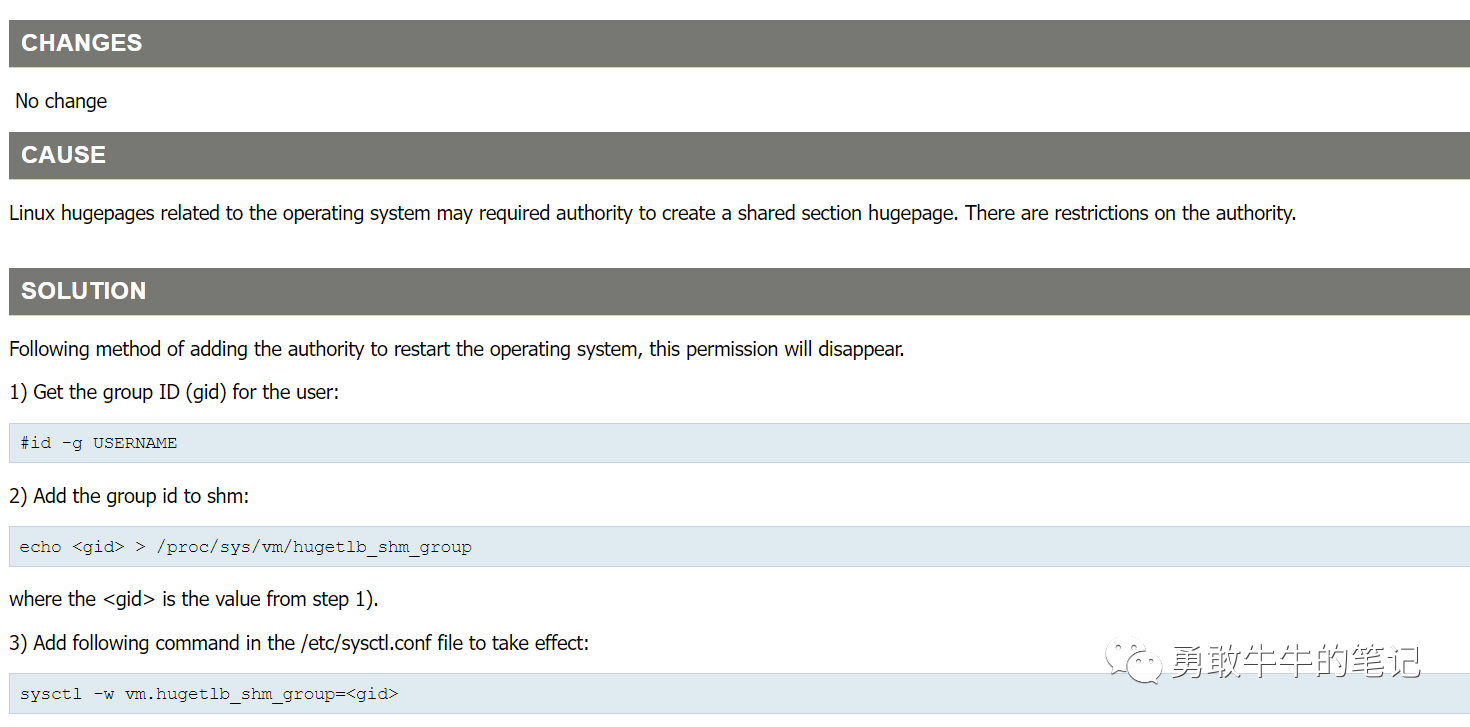
为Oracle用户配置创建大页内存权限后,大页内存终于被实例加载使用,此后,集群主机重启问题再也没有发生,问题得到了解决。
---在/etc/sysctl.conf里面配置
vm.hugetlb_shm_group=54321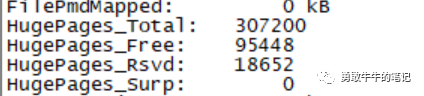
最后,还剩下一点待解决的疑问,那就是hugetlb_shm_group参数是否一定需要配置,因为在其他服务器上,通常不需要单独去设置hugetlb_shm_group参数,Oracle实例也可以使用到巨页内存,但本案例,的确是需要去配置参数才能使用到大页内存...


![[架构之路-121]-《软考-系统架构设计师》-计算机体系结构 -3-汇编语言与ARM系统的初始化](https://img-blog.csdnimg.cn/img_convert/a61431ba399354b5d5fd596471fdbc23.png)