MergeTree
- 一、MergeTree逻辑存储结构
- 二、MergeTree物理存储结构
- 三、总结
一、MergeTree逻辑存储结构

- 如上图所示,在排序键(CountrID、Date)上做索引,数据会按照这两个字段先后排序
- ClickHouse是稀疏索引,每隔8192行做一个索引,如(a,1),(a,2),比如想查a,要读取[0,3)之间的内容,稀疏索引会导致数据的额外读取
- CounterID in (a,h),服务器会读取标记号在[0,3)和[6,8)区间中的数据
- CounterID in (a,h) and Date = 3,服务器会读取标记号在[1,3)和[7,8)区间中的数据
- 如果只是查Date = 3,那会读取[1,10]中的数据,和mysql索引差不多,遵循最左前缀原则,虽然是稀疏索引,但是效率还是比全表扫描高的
- ClickHouse不要求主键唯一,所以可以插入多条具有相同主键的行
二、MergeTree物理存储结构
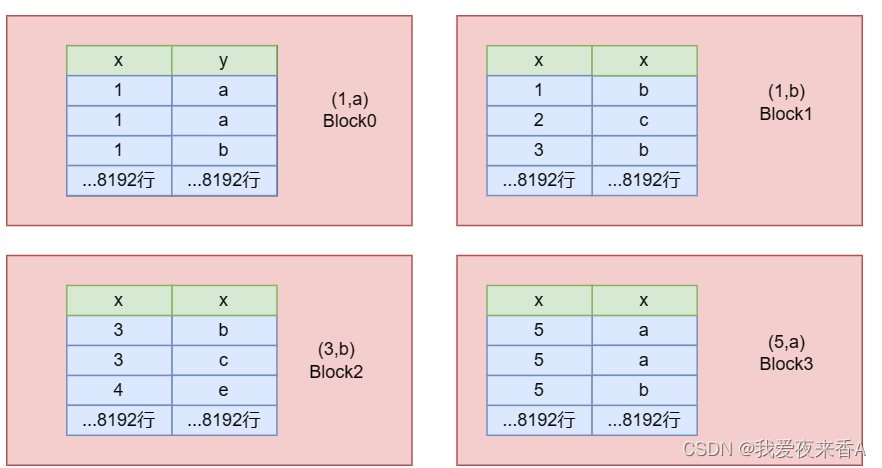
- MergeTree表中的数据存储于chunk中(通常是64KB到1MB)
- 每隔8192行数据,是1个block,主键每隔8192行,取一主键列的数据,存在primary.idx文件中,同时记录这是第几个block
- 表中的所有列都存在chunk分离的 c o l u m n . b i n 文件中 , 一个列对应一个 column.bin文件中,一个列对应一个 column.bin文件中,一个列对应一个column.bin文件
- 同样,对于每一列都有带标记的$column.mrk文件,该文件记录的是每个第N行在数据文件中的偏移量,建立了primary.idx与column.bin之间的映射关系
1、查询过程(x、y为主键,z为非主键)
- 根据查询条件(判断是否主键)
- 根据primary.idx(常驻内存),找到数据在block的哪个位置
- 把.mrk文件将数据加载到内存
- 根据.mrk文件的偏移量找到.bin文件中的数据段
1)、全主键(where x = ‘3’ and y = ‘c’)
- 判断,只需扫描block
- 使用.mrk文件,定位到数据
- 加载内存过滤返回
2)、半主键
- 若是最左前缀主键,扫描过程同全主键一样
- 若不是最左前缀主键,扫描过程几乎同非主键一样,存在过滤效果差的情况
3)、非主键(where z = ‘’)
- 等效于where x = any and y = any and z = ‘’;
- 取所有block
- 取所有mrk里的所有数据偏移量,即全扫描
- 过滤返回
4)、主键+非主键(where x = ‘’ and z = ‘’)
- 利用主键x,找到x的block,同时也一定是z要过滤的block
- 取出x、z.mrk文件中的偏移量(定位数据)
- 加载内存过滤返回
2、写入的过程
- 当你向MergeTree中插入一堆数据时,数据按主键排序并形成一个新的分块。为了保证分块的数量相对较少,有后台线程定期选择一些分块并将它们合并成一个有序的分块,这就是MergeTree的名称来源
- MergeTree不是LSM树,因为它不包含memtable和log(HBase是有的,数据写到memtable后就直接返回写入成功,因为有预写日志备份了,所以HBase适合写):插入的数据直接写入文件系统,这使得它仅适用于批量插入数据,而不适用于非常频繁的一行一行插入,大约每秒一次是没问题的,但是每秒一千次就有问题
三、总结
Clickhouse分别吸取了mysql引擎MylSAM和LSM树的长处,索引方面,使用稀疏索引
在数据文件上,沿用LSM树的数据段内数据有序,借助稀疏索引定位数据段
在存储方面,类似MylSAM,将索引文件和数据文件分开,同时引入列存,将索引文件和数据文件按照列字段粒度进行拆分,每个列独立存储