这些是之前的文章,里面有一些基础的知识点在前面由于前面已经有写过,所以这一篇就不再详细对之前的内容进行描述
Python自动化测试实战篇(1)读取xlsx中账户密码,unittest框架实现通过requests接口post登录网站请求,JSON判断登录是否成功
Python自动化测试实战篇(2)unittest实现批量接口测试,并用HTMLTestRunner输出测试报告
Python自动化测试实战篇(3)优化unittest批量自动化接口测试代码,ddt驱动+yaml实现用例调用,输出HTMLTestRunner测试报告
Python自动化测试实战篇(4)selenium+unttest+ddt实现自动化用例测试,模拟用户登陆点击交互测试,Assert捕获断言多种断言
Python自动化测试实战篇(5)优化selenium+unittest+ddt,搞定100条测试用例只执行前50条
本篇主要是对之前的代码用PO分层的方式去优化梳理整个的自动化测试的流程
主要就是针对之前写过的文章进行用PO分层的思想去优化代码
Python自动化测试实战篇(6)用PO分层模式及思想,优化unittest+ddt+yaml+request登录接口自动化测试
- PO分层简介
- 1.本篇运用的PO分层流程图
- 2.未优化之前的代码
- 3.用PO分层优化自动化代码
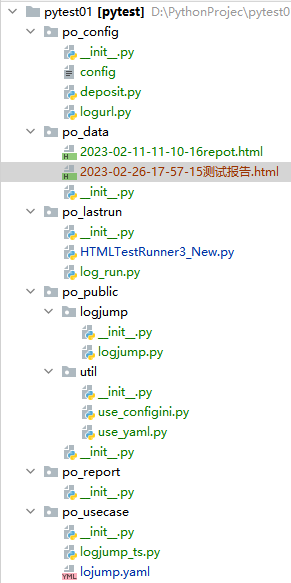
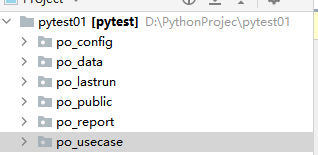
- 1.po_public 存放公共包
- 2.po_config 存放项目包的路径
- 3.po_data 存放数据报告
- 4.po_usecase 存放测试用例和unittest的测试组件
- 5.po_lastrun 存放运行文件
PO分层简介
PO分层主要是为了帮助已经进入自动化的公司进行在测试用例上的维护,增强代码可读性,和减少用例维护的成本,将测试代码和业务代码进行一个分离开来。
也就是意味着你用selenium用来做自动化和接口自动化测试的代码实际上是分开,但是最终你还是可以一起调用,但是如果你换了需要换一个其他的功能进行测试时,你又要重新写一套新的测试用例,这样就非常浪费时间。
PO分层就是将这些分开,变成一个模块,就像是餐厅大厨炒菜那样
假如我需要做红烧鱼那么我就调用后厨进行红烧鱼的制作,那么前面的选材-洗菜-切菜过程都是一样,我只要去考虑怎么烧鱼好吃和烧鱼多久的问题,以及那个加强和优化那个环境更好留住顾客和增加翻台率
同样的如果我换了一道菜变成鲫鱼汤,那么也很简单只要在最后变成熬汤的方法就可以,前面的那些功能也是一样。
实现功能复用,减少重复创建的流程,这就是PO思想,如果不用的话那么我需要在后厨重新搞一遍,那样又是浪费很多时间。
1.本篇运用的PO分层流程图
那么结合到自动中如何走?
大致如下图所示:

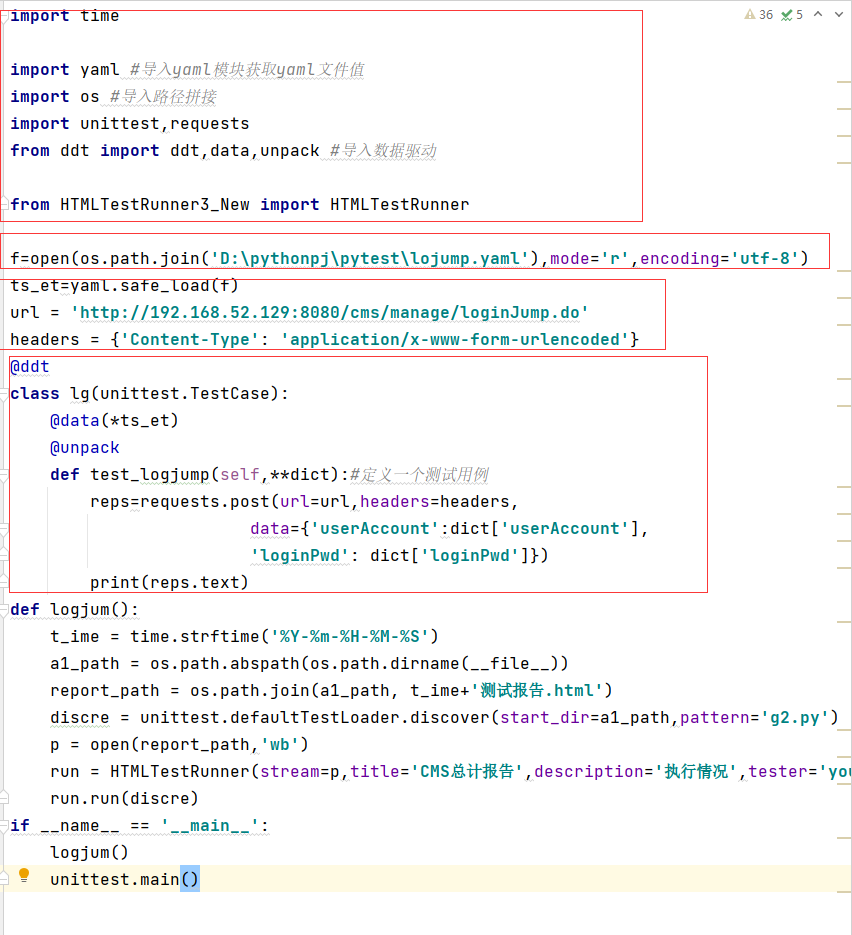
2.未优化之前的代码
可以看到未优化前的代码虽然能够让人一眼就能看清晰知道需要做些什么,但是对于复用性较差,如果更换了功能再去调用的话结果就非常复杂
import time
import yaml #导入yaml模块获取yaml文件值
import os #导入路径拼接
import unittest,requests
from ddt import ddt,data,unpack #导入数据驱动
from HTMLTestRunner3_New import HTMLTestRunner
f=open(os.path.join('D:\pythonpj\pytest\lojump.yaml'),mode='r',encoding='utf-8')
ts_et=yaml.safe_load(f)
url = 'http://192.168.52.129:8080/cms/manage/loginJump.do'
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
@ddt
class lg(unittest.TestCase):
@data(*ts_et)
@unpack
def test_logjump(self,**dict):#定义一个测试用例
reps=requests.post(url=url,headers=headers,
data={'userAccount':dict['userAccount'],
'loginPwd': dict['loginPwd']})
print(reps.text)
def logjum():
t_ime = time.strftime('%Y-%m-%H-%M-%S')
a1_path = os.path.abspath(os.path.dirname(__file__))
report_path = os.path.join(a1_path, t_ime+'测试报告.html')
discre = unittest.defaultTestLoader.discover(start_dir=a1_path,pattern='g2.py')
p = open(report_path,'wb')
run = HTMLTestRunner(stream=p,title='CMS总计报告',description='执行情况',tester='you')
run.run(discre)
if __name__ == '__main__':
logjum()
unittest.main()
我可以用PO分层将这里面的内容分开存放
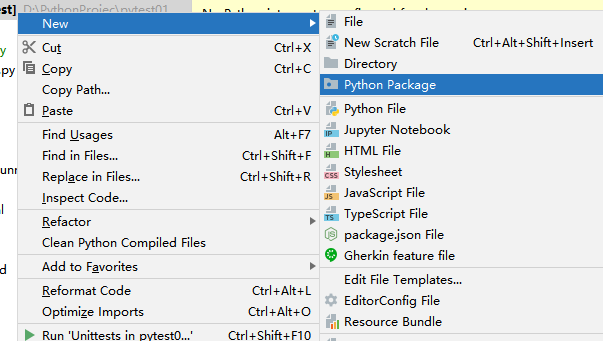
3.用PO分层优化自动化代码
在Pycharm中新建6个包用于存放相应的功能
1.po_public 存放公共包
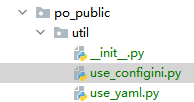
定义两个方法用户后续调用时使用
新建 use_configini.py
import configparser
class use_ini:
def __init__(self,file):#定义一个构造方法
self.file1 = configparser.ConfigParser()#创建对象
self.file1.read(file)
def read_ini(self,a,b):
value = self.file1.get(a,b)#获取变量节点和变量名称
return value#获取文件中变量节点的值
新建 use_yaml.py
from po_config.deposit import *
import yaml
class use_yml:
@staticmethod
def re_yml(filename):
yml = open(os.path.join(yaml_path,filename),encoding='utf-8')
data = yaml.safe_load(yml)
return data
if __name__ == '__main__':
print(use_yml.re_yml('lojump.yaml'))
新建 logjump.py
#用于存放通用的登录元素
class logjump:
useraccount =('userAccount','')
password = ('loginPwd','')
2.po_config 存放项目包的路径
在这里将这些路径类的放在po_config这个包里面

新建一个config.ini文件用于存放路径
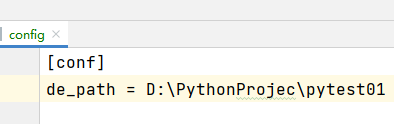
新建一个deposit.py文件
import time
import yaml #导入yaml模块获取yaml文件值
from po_public.util.use_configini import *
import os #导入路径拼接
import unittest,requests
# from ddt import ddt,data,unpack #导入数据驱动
#获取ini的绝对路径
po_cofing_path=os.path.abspath(os.path.dirname(__file__))
get_path=use_ini(os.path.join(po_cofing_path,'config')).read_ini('conf','de_path')
print(get_path)
#封装一个yaml路径
yaml_path = os.path.join(get_path,'po_usecase')
#封装测试报告路径
time_t = time.strftime('%Y-%m-%d-%H-%M-%S')
testlog = os.path.join(get_path,'po_data',time_t+'测试报告.html')
print(testlog)
新建一个logurl.py文件
url = 'http://192.168.52.129:8080/cms/manage/loginJump.do'
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
3.po_data 存放数据报告
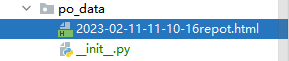
4.po_usecase 存放测试用例和unittest的测试组件
这里直接将yaml用例放进去即可
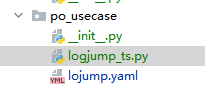
新建logjump_ts.py 存放调用登录用例测试
import unittest,requests
from ddt import ddt,data,unpack #导入数据驱动
from po_config import logurl
from po_public.util import use_yaml
ts_et=use_yaml.re_yml#调用yaml
url = logurl.url #调用 url
headers = logurl.headers #调用存放的headers
@ddt
class lg(unittest.TestCase):
@data(*ts_et)
@unpack
def test_logjump(self,**dict):#定义一个测试用例
reps=requests.post(url=url,headers=headers,
data={'userAccount':dict['userAccount'],
'loginPwd': dict['loginPwd']})
print(reps.text)
if __name__ == '__main__':
unittest.main()
5.po_lastrun 存放运行文件
新建一个log_run.py文件
可以看到用PO分层思想优化过后的代码很明显减少了很多,很多重复性的东西就可以直接复用
import unittest
from po_config.deposit import *
from po_lastrun.HTMLTestRunner3_New import HTMLTestRunner
def logjump():
unitRun =unittest.defaultTestLoader.discover(start_dir=get_path,pattern='logjummp.py')
f=open(testlog,'wb')#导入存放测试报告的地址
run=HTMLTestRunner(stream=f,title='登录报告',description='结果如下',tester='yourname')
run.run(unitRun)#执行对应文件中的测试报告
if __name__ == '__main__':
logjump()#函数调用函数执行结果
使用PO分层之后,每个模块都可以随时修改,而不用一个功能出现就重新创建一次,影响工作效率