目录
学习python的一些基础知识
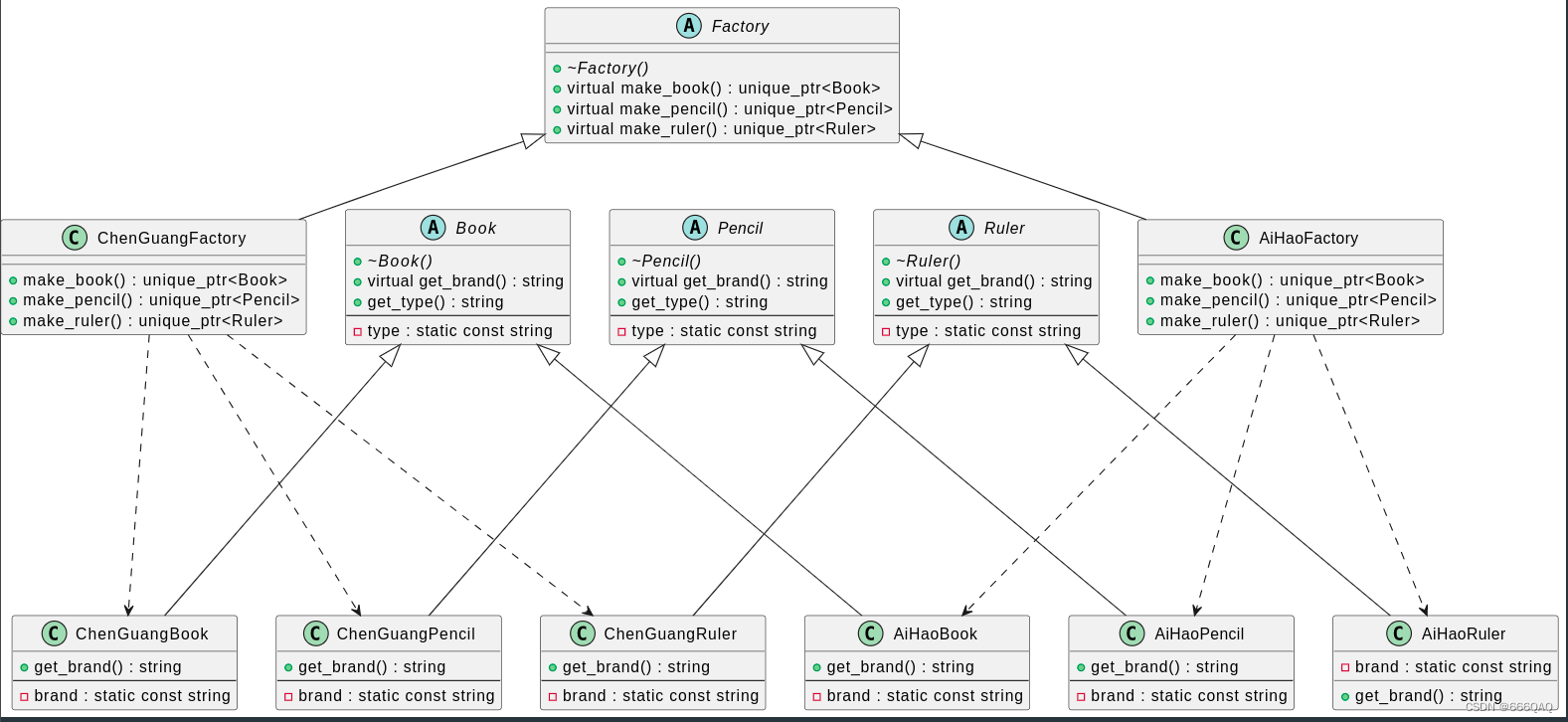
argparser
assert关键字
让你秒懂Python 类特殊方法__getitem__
lxml.etree.fromstring的使用
统计一下json文件内的种类
正脸红外光
正脸-混合红外光
正脸-交叉偏振光
正脸-平行偏振光
正脸-紫外光
正脸-棕色光
调用mydataset可视化 --- 修改目标
主文件
调用split_data把数据集根据名字分成训练集和验证集
把train.txt作为VOCDataSet的参数txtname传入
VOCDateSet构造函数里文件路径
xml_list 存的是每个xml的位置
调用getitem特殊方法得到每个文件的类别信息
调用parse_xml_to_dict将每个xml文件的object提取放入data内
将从data里提取出的object信息放入boxes和labels中
需要修改的文件内容
pascal_voc_classes.json文件的内容
修改split_data内容,分离出json_train和json_val文件
构造函数
getitem函数
学习python的一些基础知识
argparser
python之parser.add_argument()用法——命令行选项、参数和子命令解析器_夏普通的博客-CSDN博客_parser.add_argument
import os
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description=__doc__)
# 训练设备类型
parser.add_argument('--A', default='3', help='device')
parser.add_argument('--B', default='4', help='device')
args = parser.parse_args()
print(args.A)
print(args.A)
print(type(args.A))
print(type(args.B))
print(int(args.A)+1)
print(int(args.A)+1)在Edit Configurations里输入参数


从结果里可以看到其实输入的参数是str类型的,可以强制转换
5
5
<class 'str'>
<class 'str'>
6
6assert关键字
python中assert的用法(简洁明了)_花里梦雨的博客-CSDN博客_python assert用法


报错:
让你秒懂Python 类特殊方法__getitem__
凡是在类中定义了这个__getitem__ 方法,那么它的实例对象(假定为p),可以像这样
p[key] 取值,当实例对象做p[key] 运算时,会调用类中的方法__getitem__。
让你秒懂Python 类特殊方法__getitem__ - 知乎
lxml.etree.fromstring的使用
lxml.etree.fromstring的使用_夏夏今天学习了吗的博客-CSDN博客
该方法是将xml格式转化为Element 对象,Element 对象代表 XML 文档中的一个元素。

统计一下json文件内的种类
Python常用小技巧(五)——批量读取json文件_码农邦的博客-CSDN博客_python批量读取json文件
正脸红外光

正脸-混合红外光

正脸-交叉偏振光

正脸-平行偏振光

正脸-紫外光

正脸-棕色光

其实就是标注了四个种类:eyes eyebrow nose mouth
调用mydataset可视化 --- 修改目标
注:这不是预测 只是把矩形四个点和label提出之后 再用这几个点在原图中画出位置
修改mydataset文件将json转数据集能达到这个效果就o


主文件
调用split_data把数据集根据名字分成训练集和验证集
train.txt里面长这样

把train.txt作为VOCDataSet的参数txtname传入

VOCDateSet构造函数里文件路径
有三个文件路径
root 根目录
annotation_root xml文件位置
img_root 图片位置

xml_list 存的是每个xml的位置

将xml_list存入类内
调用getitem特殊方法得到每个文件的类别信息

调用parse_xml_to_dict将每个xml文件的object提取放入data内
data = self.parse_xml_to_dict(xml)["annotation"]
print("--------------data-------------------")
print(type(data))
print(data)调用函数后data:
--------------data-------------------
<class 'dict'>
{
'filename': '2009_001291.jpg', 'folder': 'VOC2012',
'object': [{'name': 'train', 'bndbox': {'xmax': '317', 'xmin': '96', 'ymax': '389', 'ymin': '100'},
'difficult': '0',
'occluded': '0',
'pose': 'Unspecified',
'truncated': '0'}],
'segmented': '0',
'size': {'depth': '3', 'height': '500', 'width': '408'},
'source': {'annotation': 'PASCAL VOC2009', 'database': 'The VOC2009 Database', 'image': 'flickr'}
}
将从data里提取出的object信息放入boxes和labels中
for obj in data["object"]:
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为nan
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.class_dict[obj["name"]])
if "difficult" in obj:
iscrowd.append(int(obj["difficult"]))
else:
iscrowd.append(0)需要修改的文件内容
pascal_voc_classes.json文件的内容
本来这个文件存储的就是类别对应的序号,这里是在给自制的数据集可视化的部分。

修改split_data内容,分离出json_train和json_val文件


构造函数
修改文件路径
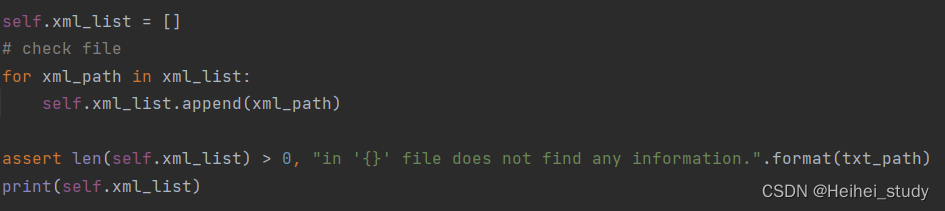
最后的目的就是在self.xml_list里存储json文件
getitem函数
for obj in data["shapes"]:
#用多边形标注时
#print(obj)
if obj['shape_type']=='polygon':
#print(len(obj['points']))
label = obj['label']
xmin=ymin=100000
xmax=ymax=0
for point in obj['points']:
if point[0]<xmin:
xmin=float(point[0])
elif point[0]>xmax:
xmax=float(point[0])
if point[1]<ymin:
ymin=float(point[1])
elif point[1]>ymax:
ymax=float(point[1])
else:
label = obj['label']
xmin = float(obj['points'][0][0])
xmax = float(obj['points'][1][0])
ymin = float(obj['points'][0][1])
ymax = float(obj['points'][1][1])索引到类别信息的位置
暂时有两种情况 1.多边形 2.矩形
在多边形的处理中,找出点x的最小最大值和y的最小最大值分别赋值给xmin xmax ymin ymax
矩形直接转换