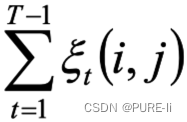Learning Transferable Visual Models From Natural Language Supervision 利用自然语言的监督信号学习可迁移的视觉模型
概述
迁移学习方式就是先在一个较大规模的数据集如ImageNet上预训练,然后在具体的下游任务上再进行微调。这里的预训练是基于有监督训练的,需要大量的数据标注,因此成本较高。近年来,出现了一些基于自监督的方法,这包括基于对比学习的方法如MoCo和SimCLR,和基于图像掩码的方法如MAE和BeiT,自监督方法的好处是不再需要标注。但是无论是有监督还是自监督方法,它们在迁移到下游任务时,还是需要进行有监督微调,而无法实现zero-shot。
有监督模型:在新的数据集上需要定义新的分类器来重新训练。
自监督模型:代理任务往往是辅助来进行表征学习,在迁移到其它数据集时也需要加上新的分类器来进行有监督训练。
NLP领域,基于自回归或者语言掩码的预训练方法已经取得相对成熟,而且预训练模型很容易直接zero-shot迁移到下游任务。
创新点:用文本的弱信号帮助有监督的模型取得更好的效果,实现zero-shot分类,实现预训练模型。
CLIP是一种基于对比学习的多模态模型,是用文本作为监督信号来训练可迁移的视觉模型。CLIP(Con trastive Language-Image Pre-training)采用从互联网收集的4亿个(图像,文本)对的数据集预测哪个标题与哪个图像相配这样简单的预训练任务。通过对30多个不同的现有计算机视觉数据集进行基准测试来研究这种方法的性能,这些数据集涵盖了诸如OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。 该模型不需要任何数据集的专门训练地迁移到大多数任务中,并且通常与完全监督的基线旗鼓相当。例如,CLIP不需要使用ImageNet的128万个训练实例中的任何一张图片就可以达到ResNet-50的准确率。
原理

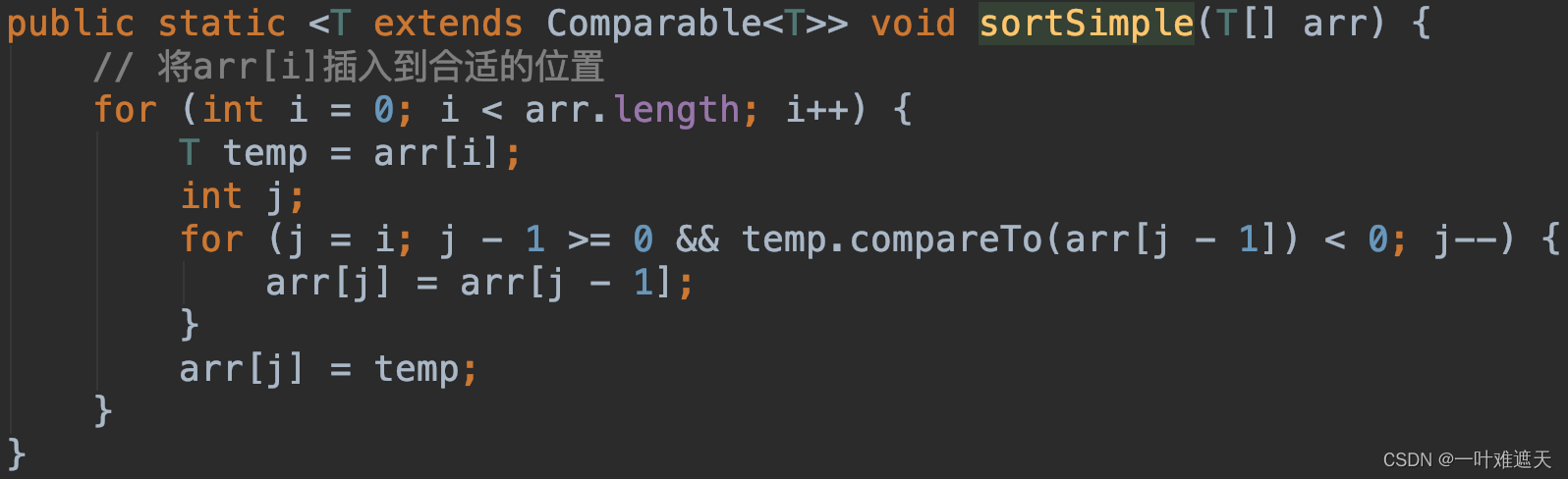
图1.CLIP方法摘要。标准的图像模型联合训练一个图像特征提取器和一个线性分类器来预测一些标签,而CLIP联合训练一个图像编码器和一个文本编码器来预测一批(图像,文本)训练例子的正确配对。
CLIP通过联合训练一个图像编码器和文本编码器来学习一个多模态的嵌入空间,训练目标是最大化批次中N个正确对的图像和文本嵌入的余弦相似性,同时最小化N2-N个错误对的嵌入的余弦相似性。CLIP为图像编码器考虑了两种不同的架构:ResNet-50和ViT。文本编码器使用transformer,文本序列用[SOS]和[EOS]标记括起来,transformer的最高层在[EOS]标记处的激活被视为文本的特征表示,它被层层规范化,然后线性投影到多模态嵌入空间。
对于ResNet图像编码器,我们使用了一个简单的基线,即平均分配额外的计算量来增加模型的宽度、深度和分辨率。对于文本编码器,我们只将模型的宽度扩展到与ResNet的计算宽度增加成正比,而完全不扩展深度,因为我们发现CLIP的性能对文本编码器的容量不太敏感。

实验
对于每个数据集,我们使用数据集中所有类别的名称作为潜在的文本配对的集合,并根据CLIP预测最可能的(图像,文本)配对。更详细一点,我们首先通过各自的编码器计算图像的特征嵌入和可能的文本集合的特征嵌入。 然后计算这些嵌入的余弦相似度,用temperature参数τ进行缩放,并通过softmax归一化为一个概率分布。注意,这个预测层是一个多叉逻辑回归分类器,具有L2归一化的输入、L2归一化的权重、无偏差和temperature 缩放。

表1.将CLIP与之前的zero-shot迁移图像分类结果进行比较。CLIP在所有三个数据集上的性能都有很大的提高。
在表1中,我们将Visual N-Grams与CLIP进行了比较。最好的CLIP模型将ImageNet的准确率从概念证明的11.5%提高到76.2%,并与原始ResNet-50的性能相匹配,而没有使用这个数据集的128万个带标记的训练实例。另外,CLIP模型的前5名准确率明显高于他们的前1名,这个模型的前5名准确率为95%,与Inception-V4相匹配。以zero-shot的设置匹配一个强大的、完全监督的基线的性能的能力表明CLIP是向灵活和实用的zero-shot计算机视觉分类器迈出的重要一步。

图4.提示工程和合集提高了zero-shot性能。与使用无上下文的类名的基线相比,提示工程和合集在36个数据集上平均提高了近5个点的zero-shot分类性能。这一改进与使用基线zero-shot方法的4倍计算量的收益相似,但在多次预测中摊销时是 "免费 "的。
一个常见的问题是多义性。当一个类的名称是提供给CLIP文本编码器的唯一信息时,由于缺乏上下文,它无法区分哪个词的意义。在某些情况下,同一个词的多种意义可能被包括在同一个数据集中的不同类中!通常文本是一个完整的句子,以某种方式描述图片。为了帮助弥补这一分布差距,我们发现使用提示模板 "A photo of a {label}. ",有助于指定文本是关于图片的内容。这通常比只使用标签文本的基线提高了性能。例如,仅仅使用这个提示就使ImageNet的准确性提高了1.3%。指定类别也是有帮助的。例如,在Oxford-IIIT Pets上,使用 "A photo of a {label}, a type of pet. "来帮助提供背景,效果很好。

图5.Zero-shot CLIP与完全超视距的基线具有竞争力。在27个数据集的评估套件中,Zero-shot CLIP分类器在16个数据集(包括ImageNet)上的表现优于适合ResNet-50特征的完全监督线性分类器。

图6.Zero-shot CLIP的性能优于少数的线性探针。Zero-shot CLIP与在相同特征空间上训练的4-shot线性分类器的平均性能相匹配,并且几乎与公开可用模型中的16-shot线性分类器的最佳结果相匹配。对于BiT-M和SimCLRv2,性能最好的模型被高亮。浅灰色线条是评估套件中的其他模型。本分析中使用了20个每类至少有16个例子的数据集。
局限
尽管zero-shot CLIP表现很好,但仍然需要大量的工作来提高CLIP的任务学习和迁移能力。 要达到整体的最先进的性能,zero-shot的CLIP需要增加1000倍的计算量,这在目前的硬件训练中是不可行的,进一步研究改进CLIP的计算和数据效率将是必要的。
zero-shot CLIP在一些细分的、专门的、复杂的或抽象的任务上表现不好。
对那些真正超出分布的数据的泛化性很差。虽然CLIP可以灵活地生成各种任务和数据集的零样本分类器,但CLIP仍然仅限于从一个给定的零样本分类器中选择那些概念。
CLIP对数据的利用并不高效。将CLIP与自监督和自我训练方法结合起来比标准监督学习数据效率高。