数据结构理论
1.1 数据
数据:是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。
1.2数据结构概念
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
1.3 算法的概念
算法是特定问题求解步骤的描述,在计算机中表现为指令的有限序列,算法是独立存在的一种解决问题的方法和思想。
对于算法而言,语言并不重要,重要的是思想。
1.3.1算法和数据结构区别
数据结构只是静态的描述了数据元素之间的关系,高效的程序需要在数据结构的基础上设计和选择算法。
算法是为了解决实际问题而设计的
数据结构是算法需要处理的问题载体
数据结构与算法相辅相成
1.3.2 算法的比较
现在我们需要写一个求1 + 2 + 3 + … + 100的结果程序,你应该怎么写呢?
大多数人马上回写出下面C语言代码(或者其他语言):
int i ,sum = 0; n = 100;
for(int i = 1 ;i <= n;i++)
{
sum = sum + i;
}
printf(“ %d ” , sum);当然,如果这个问题让高斯来去做,他可能会写如下代码:
int sum = 0 ,n = 100;
sum = ( 1 + n) * n / 2
printf(“%d”,sum)很显然,不论是从人类还是计算机的角度来看,下列的算法效率会高出很多,这就是一个好的算法会让你的程序更加的高效。
1.3.3 算法的特性
算法具有五个基本的特性:输入、输出、有穷性、确定性和可行性
输入输出:算法具有零个或多个输入、至少有一个或多个输出。
有穷性:指算法在执行有限的步骤之后,自动结束而不会出现无限循环,并且每一个步骤在可接受的时间内完成。
确定性:算法的每一步骤都有确定的含义,不会出现二义性。
可行性:算法的每一步都必须是可行的,也就是说,每一步都能通过执行有限次数完成。
1.4 数据结构分类
按照视点的不同,我们把数据结构分为逻辑结构和物理结构。
1.4.1 逻辑结构
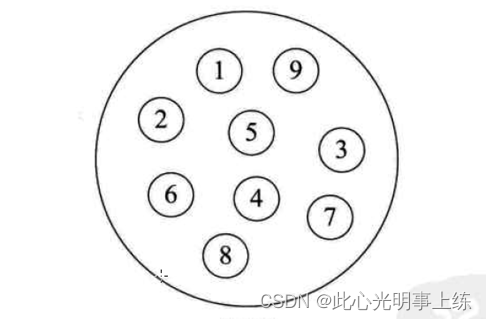
集合结构:集合结构中的数据元素除了同属于一个集合外,他们之间没有其他关系。各个数据元素是平等的。他们共同属于同一个集合,数据结构中的集合关系类似于数学中的集合,如下图所示
线性结构:线性结构中的数据元素之间是一对一的关系。如图:

树形结构:树形结构中是数据元素之间存在一种一对多的层次关系,如图:
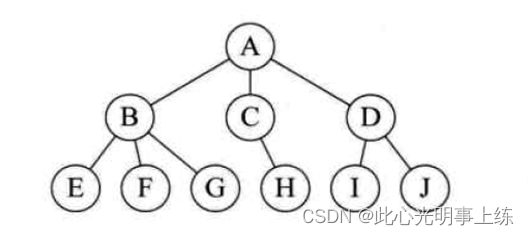
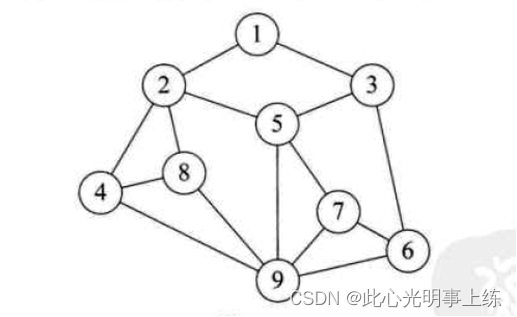
图形结构:图形结构的数据元素是多对多的关系,如果:
1.4.2 物理结构
说完了逻辑结构,再说下物理结构,也有的书称为存储结构。
物理结构:是指数据的逻辑结构在计算机中的存储形式,共分为两种:顺序存储和链式存储。
顺序存储:是把数据元素存放在地址连续的存储单元里,其数据的逻辑关系和物理关系是一致的,如图:

如果所有数据结构都很简单有规律,一切就好办了,可实际上,总有人想要插队,或者放弃排队,所以元素集合中就会添加、删除掉成员,显然面对这样时常要变化的结构,顺序存储是不科学的,那怎么办呢
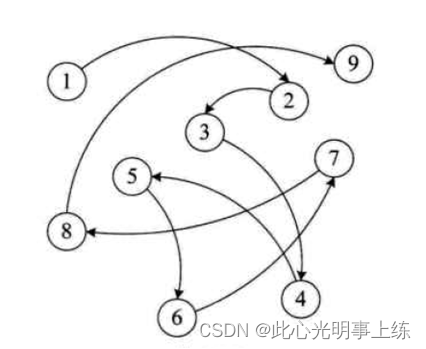
链式存储结构:是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的。数据元素的存储关系并不能反映其逻辑关系,因此需要用一个指针存放数据元素的地址,这样通过地址就可以找到相关数据的位置。如图:
2. 线性表
2.1线性表基本概念
线性结构是一种最简单且常用的数据结构。线性结构的基本特点是节点之间满足线性关系。本章讨论的动态数组、链表、栈、队列都属于线性结构。他们的共同之处,是节点中有且只有一个开始节点和终端节点。按这种关系,可以把它们的所有节点排列成一个线性序列。但是,他们分别属于几种不同的抽象数据类型实现,它们之间的区别,主要就是操作的不同。
线性表是零个或者多个数据元素的有限序列,数据元素之间是有顺序的,数据元素个数是有限的,数据元素的类型必须相同。
线性表的性质:
a0 为线性表的第一个元素,只有一个后继。
an 为线性表的最后一个元素,只有一个前驱。
除 a0 和 an 外的其它元素 ai,既有前驱,又有后继。
线性表能够逐项访问和顺序存取。
线性表的抽象数据类型定义:
ADT线性表(List)
Data
线性表的数据对象集合为{ a1, a2, ……, an },每个元素的类型均为DataType。其中,除第一个元素a1外,每个元素有且只有一个直接前驱元素,除了最后一个元素an外,每个元素有且只有一个直接后继元素。数据元素之间的关系是一一对应的。
Operation(操作)
// 初始化,建立一个空的线性表L。
InitList(*L);
// 若线性表为空,返回true,否则返回false
ListEmpty(L);
// 将线性表清空
ClearList(*L);
// 将线性表L中的第i个位置的元素返回给e
GetElem(L, i, *e);
// 在线性表L中的第i个位置插入新元素e
ListInsert(*L, i, e);
// 删除线性表L中的第i个位置元素,并用e返回其值
ListDelete(*L, i, *e);
// 返回线性表L的元素个数
ListLength(L);
// 销毁线性表
DestroyList(*L);2.2线性表的顺序存储
通常线性表可以采用顺序存储和链式存储。这节课我们主要探讨顺序存储结构以及对应的运算算法的实现。
采用顺序存储是表示线性表最简单的方法,具体做法是:将线性表中的元素一个接一个的存储在一块连续的存储区域中,这种顺序表示的线性表也成为顺序表。
2.2.1线性表顺序存储(动态数组)的设计与实现
动态数组:将数组开闭到堆区,实现动态扩展。
用户的数据类型,无法确定
用户的数据无法确定创建在堆区还是栈上
不管数据是在栈上,还是在堆区,都会放在内存上,就会有地址,我们只要维护数据的地址就可
如果原来数组容量不够了,就开闭一个更大的内存,并且将原有数据拷贝到新空间下,释放掉原有内存,维护新空间的首地址
操作要点:
插入元素算法
判断线性表是否合法
判断插入位置是否合法
判断空间是否满足
把最后一个元素到插入位置的元素后移一个位置
将新元素插入
线性表长度加1
获取元素操作
判断线性表是否合法
判断位置是否合法
直接通过数组下标的方式获取元素
删除元素算法
判断线性表是否合法
判断删除位置是否合法
将元素取出
将删除位置后的元素分别向前移动一个位置
线性表长度减1
元素的插入
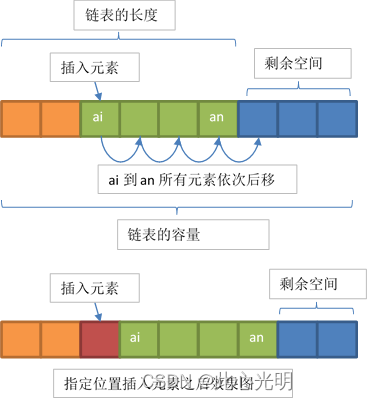
元素的删除

注意: 链表的容量和链表的长度是两个不同的概念
初始化数组
遍历数组
插入数组
删除数组
销毁数组
//动态数组结构体
struct dynamicArray{
//真实在堆区开辟数组的指针
void ** pAddr;
//数组容量
int m_Capacity;
//数组大小
int m_Size;
}
//初始化数组 参数:初始化数组容量 返回值:动态数组指针
struct dynamicArray * init_dynamicArray(int capacity){
if(capacity <= 0){
return NULL;
}
//给动态数组分配内存
struct dynamicArray * arr = malloc(sizeof(struct dynamicArray));
if(arr == NULL) {
return NULL;
}
//给属性赋值
arr->pAddr = malloc(sizeof(void *)*capacity);
arr->m_Capacity = capacity;
arr->m_Size = 0;
return arr;
}
//插入数组
void insert_dynamicArray(struct dynamicArray * arr, void * data, int pos) {
if(arr == NULL){
return;
}
if(data == NULL){
return;
}
if(pos < 0 || pos > arr->m_Size) {
//尾插入
pos = arr->m_Size;
}
//判断数组是否满了
if(arr->m_Size == arr->m_Capacity){
//1、计算新内存空间大小
int newCapacity = arr->m_Capacity * 2;
//2、开辟新空间
void ** newSpace = malloc(sizeof(void *)*newCapacity);
//3、将原空间下数据拷贝到新空间下
memcpy(newSpace, arr->pAddr, sizeof(void *) * arr->m_Capacity)
//4、释放原空间
free(arr->pAddr);
//5、更改指针指向
arr->pAddr = newSpace;
//6、更新新容量
arr->m_Capacity = newCapacity;
}
//将新元素插入到数组中指定位置
for(int i = arr->m_Size -1; i >= pos; i--){
arr->pAddr[i+1] = arr->pAddr[i];
}
//将数据插入到指定位置
arr->pAddr[pos] = data;
//更新数组大小
arr->m_Size++;
}
//遍历数组
void foreach_dynamicArray(struct dynamicArray * arr, void (*mPrint)(void *)){
if(arr == NULL){
return;
}
for(int i=0; i<arr->m_Size; i++){
myPrint(arr->pAddr[i])
}
}
//删除数组
//按照位置删除数据
void removeByPos_dynamicArray(struct dynamicArray * arr, int pos){
if(arr == NULL){
return;
}
if(pos < 0 || pos > arr->m_Size-1){//无效位置
return;
}
//删除指定位置的元素,从前往后移动
for(int i = pos; i < arr->m_Size; i++) {
arr->pAddr[i] = arr->pAddr[i + 1];
}
//更新数组大小
arr->m_Size--;
}
//按值的方式删除数据
void removeByValue_dynamicArray(struct dynamicArray * arr, void * data, int(*myCompare)(void *, void*)){
if(arr == NULL){
return;
}
if(data == NULL){
return;
}
for(int i = 0; i < arr->m_Size; i++){
//if(arr->pAddr[i] == data)
//利用回到函数 让用户自己告诉我们如何比较数据
if(myCompare(pAddr[i], data)){
removeByPos_dynamicArray(arr, i)
break;
}
}
}
//销毁数组
void destroy_dynamicArray(struct dynamicArray * arr){
if(arr == NULL){
return;
}
//内部维护在堆区数组指针先释放
if(arr->pAddr != NULL){
free(arr->pAddr);
arr->pAddr = NULL;
}
free(arr);
arr = NULL;
}
struct Person{
char name[64];
int age;
}
//回调函数打印数据
void printPerson(void * data){
struct Person * person = data;
printf("姓名:%s 年龄:%d\n", person->name, person->age);
}
//回调函数 对比删除数据
int myCompare(void * data1, void * data2){
struct Person * p1 = data1;
struct Person * p2 = data2;
//if(strcmp(p1->name, p2->name) == 0 && p1->age == p2->age) {
// return 1;
//} else {
// return 0;
//}
return strcmp(p1->name, p2->name) == 0 && p1->age == p2->age;
}
void test(){
//初始化动态数组
struct dynamicArray * arr = init_dynamicArray(5);
struct Person p1 = {"赵云", 18};
struct Person p2 = {"张飞", 19};
struct Person p3 = {"关羽", 20};
struct Person p4 = {"刘备", 19};
struct Person p5 = {"诸葛亮", 12};
struct Person p6 = {"黄忠", 17};
printf("插入数据前--- 数组容量:%d\n", arr->m_Capacity);
printf("插入数据前--- 数组大小:%d\n", arr->m_Size);
//插入数据
insert_dynamicArray(arr, &p1, 0);
insert_dynamicArray(arr, &p2, 0);
insert_dynamicArray(arr, &p3, 1);
insert_dynamicArray(arr, &p4, -1);
insert_dynamicArray(arr, &p5, 1);
insert_dynamicArray(arr, &p6, 0);
//黄忠 张飞 诸葛亮 关羽 赵云 刘备
foreach_dynamicArray(arr, printPerson);
printf("---------------------------------------------------\n");
printf("插入数据后--- 数组容量:%d\n", arr->m_Capacity);
printf("插入数据后--- 数组大小:%d\n", arr->m_Size);
//按照位置 删除诸葛亮
removeByPos_dynamicArray(arr, 2);
printf("删除诸葛亮后遍历结果:\n");
foreach_dynamicArray(arr, printPerson);
printf("---------------------------------------------------\n");
printf("插入数据后--- 数组容量:%d\n", arr->m_Capacity);
printf("插入数据后--- 数组大小:%d\n", arr->m_Size);
//按数值 删除刘备
struct Person p = {"刘备", 19};
removeByValue_dynamicArray(arr, &p, myCompare)
printf("删除刘备后遍历结果:\n");
foreach_dynamicArray(arr, printPerson);
printf("---------------------------------------------------\n");
printf("插入数据后--- 数组容量:%d\n", arr->m_Capacity);
printf("插入数据后--- 数组大小:%d\n", arr->m_Size);
//销毁
destroy_dynamicArray(arr);
arr = NULL;
}2.2.2优点和缺点
优点:
无需为线性表中的逻辑关系增加额外的空间。
可以快速的获取表中合法位置的元素。
缺点:
插入和删除操作需要移动大量元素。
2.3线性表的链式存储(单向链表)
前面我们写的线性表的顺序存储(动态数组)的案例,最大的缺点是插入和删除时需要移动大量元素,这显然需要耗费时间,能不能想办法解决呢?链表。
链表为了表示每个数据元素与其直接后继元素之间的逻辑关系,每个元素除了存储本身的信息外,还需要存储指示其直接后继的信息。
链表详解参考文章->跳转
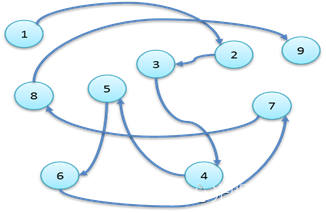
单链表
线性表的链式存储结构中,每个节点中只包含一个指针域,这样的链表叫单链表。
通过每个节点的指针域将线性表的数据元素按其逻辑次序链接在一起(如图)。

概念解释:
表头结点
链表中的第一个结点,包含指向第一个数据元素的指针以及链表自身的一些信息
数据结点
链表中代表数据元素的结点,包含指向下一个数据元素的指针和数据元素的信息
尾结点
链表中的最后一个数据结点,其下一元素指针为空,表示无后继。

2.3.1线性表的链式存储(单项链表)的设计与实现
插入操作

node->next = current->next;
current->next = node;删除操作
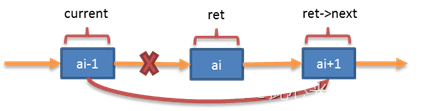
current->next = ret->next;2.3.2优点和缺点
优点:
无需一次性定制链表的容量
插入和删除操作无需移动数据元素
缺点:
数据元素必须保存后继元素的位置信息
获取指定数据的元素操作需要顺序访问之前的元素
2.3.3 常用单向链表(案例)
#define _CRT_SECURE_NO_WARNINGS
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
//节点结构体
struct LinkNode {
//数据域
void * data;
//指针域
struct LinkNode * next;
};
//链表结构体
struct LList {
//头节点
struct LinkNode pHeader;
//链表长度
int m_Size;
};
//void * 别名
typedef void * LinkList;
//初始化链表
LinkList init_LinkList() {
//分配内存
struct LList * mylist = malloc(sizeof(struct LList));
if (mylist == NULL) {
return NULL;
}
//给头节点属性初始化
//mlist->pHeader.data = NULL;
mylist->pHeader.next = NULL;
mylist->m_Size = 0;
return mylist;
}
//返回链表长度
int size_LinkList(LinkList list) {
if (list == NULL) {
return -1;
}
//还原链表真实结构体
struct LList * mylist = list;
return mylist->m_Size;
}
//插入节点
void insert_LinkList(LinkList list, int pos, void * data) {
if (list == NULL) {
return;
}
if (data == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
if (pos < 0 || pos > mylist->m_Size) {
//无效位置 尾插
pos = mylist->m_Size;
}
//创建临时节点 通过循环找到待插入位置的前驱节点位置
struct LinkNode * pCurrent = &mylist->pHeader;
for (int i = 0; i < pos; i++) {
pCurrent = pCurrent->next;
}
//此时 pCurrent就是插入位置的前驱节点
//创建新节点
struct LinkNode * newNode = malloc(sizeof(struct LinkNode));
newNode->data = data;
newNode->next = NULL;
//建立节点之间的联系
newNode->next = pCurrent->next;
pCurrent->next = newNode;
//更新链表长度
mylist->m_Size++;
}
//遍历链表
void foreach_LinkList(LinkList list, void(*myPrint)(void *)) {
if (list == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
struct LinkNode * pCurrent = mylist->pHeader.next;
for (int i = 0; i < mylist->m_Size; i++) {
myPrint(pCurrent->data);
pCurrent = pCurrent->next;
}
}
//删除链表节点
//按位置删除
void removeByPos_LinkList(LinkList list, int pos) {
if (list == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
if (pos < 0 || pos > mylist->m_Size - 1) {
//无效位置
return;
}
//找到待删除位置的前驱节点位置
struct LinkNode * pCurrent = &mylist->pHeader;
for (int i = 0; i < pos; i++) {
pCurrent = pCurrent->next;
}
//pCurrent就是待删除节点的前驱节点位置
//利用指针记录待删除节点
struct LinkNode * pDel = pCurrent->next;
//更改指针指向
pCurrent->next = pDel->next;
//释放待删除节点
free(pDel);
pDel = NULL;
//更新链表长度
mylist->m_Size--;
}
//按值删除
void removeByValue_LinkList(LinkList list, void * data, int(*myCompare)(void *, void *)) {
if (list == NULL) {
return;
}
if (data == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
//创建两个辅助指针变量
struct LinkNode * pPrev = &mylist->pHeader;
struct LinkNode * pCurrent = mylist->pHeader.next;
//遍历链表
for (int i = 0; i < mylist->m_Size; i++) {
if (myCompare(data, pCurrent->data)) {
//找到删除数据,开始删除
//更改指针指向
pPrev->next = pCurrent->next;
//释放节点
free(pCurrent);
pCurrent = NULL;
//更新链表长度
mylist->m_Size--;
break;
}
//辅助指针向后移动
pPrev = pCurrent;
pCurrent = pCurrent->next;
}
}
//清空链表
void clear_LinkList(LinkList list) {
if (list == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
struct LinkNode * pCurrent = mylist->pHeader.next;
for (int i = 0; i < mylist->m_Size; i++) {
//记录下一个节点的位置
struct LinkNode * pNext = pCurrent->next;
free(pCurrent);
pCurrent = pNext;
}
mylist->pHeader.next = NULL;
mylist->m_Size = 0;
}
//销毁链表
void destroy_LinkList(LinkList list) {
if (list == NULL) {
return;
}
//先清空再销毁
clear_LinkList(list);
free(list);
list = NULL;
}
struct Person {
char name[64];
int age;
};
//回调函数打印数据
void printPerson(void * data) {
struct Person * person = data;
printf("姓名:%s 年龄:%d\n", person->name, person->age);
}
//回调函数 对比删除数据
int myCompare(void * data1, void * data2) {
struct Person * p1 = data1;
struct Person * p2 = data2;
return strcmp(p1->name, p2->name) == 0 && p1->age == p2->age;
}
void test() {
//初始化链表
LinkList mylist = init_LinkList();
//mylist->m_Size = -1; //用户访问不到真实链表中的属性
struct Person p1 = { "赵云", 18 };
struct Person p2 = { "张飞", 19 };
struct Person p3 = { "关羽", 20 };
struct Person p4 = { "刘备", 19 };
struct Person p5 = { "诸葛亮", 12 };
struct Person p6 = { "黄忠", 17 };
insert_LinkList(mylist, 0, &p1);
insert_LinkList(mylist, 0, &p2);
insert_LinkList(mylist, 1, &p3);
insert_LinkList(mylist, -1, &p4);
insert_LinkList(mylist, 1, &p5);
insert_LinkList(mylist, 100, &p6);
//遍历链表 张飞 诸葛亮 关羽 赵云 刘备 黄忠
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
printf("---------------------------------------------------\n");
printf("删除刘备后遍历结果:\n");
removeByPos_LinkList(mylist, 4);
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
struct Person p = { "关羽", 20 };
printf("---------------------------------------------------\n");
printf("删除关羽后遍历结果:\n");
removeByValue_LinkList(mylist, &p, myCompare);
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
printf("--清空-----------------------------------------------\n");
clear_LinkList(mylist);
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
destroy_LinkList(mylist);
mylist = NULL;
}
//程序入口
int main() {
test();
system("pause"); // 按任意键暂停 阻塞功能
return EXIT_SUCCESS; //返回 正常退出值 0
}2.3.4 单向链表企业版本(案例)
设计:节点只维护指针域,不维护数据,而用户的数据需要预留4个字节让底层设计者使用
#define _CRT_SECURE_NO_WARNINGS
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
//节点结构设计
struct LinkNode {
//只维护指针域
struct LinkNode * next;
};
//链表结构体
struct LList {
struct LinkNode pHeader; //头节点
int m_Size; //链表长度
};
typedef void * LinkList;
//初始化链表
LinkList init_LinkList() {
struct LList * mylist = malloc(sizeof(struct LList));
if (mylist == NULL) {
return NULL;
}
mylist->m_Size = 0;
mylist->pHeader.next = NULL;
return mylist;
}
void insert_LinkList(LinkList list, int pos, void * data) {
if (list == NULL) {
return;
}
if (data == NULL) {
return;
}
struct LList * mylist = list;
if (pos < 0 || pos > mylist->m_Size - 1) {
pos = mylist->m_Size;
}
//取出用户数据前4个字节空间
struct LinkNode * myNode = data;
//找到待插入位置的前驱节点
struct LinkNode * pCurrent = &mylist->pHeader;
for (int i = 0; i < pos; i++) {
pCurrent = pCurrent->next;
}
//更改指针指向
myNode->next = pCurrent->next;
pCurrent->next = myNode;
//更新链表长度
mylist->m_Size++;
}
//遍历
void foreach_LinkList(LinkList list, void(*myPrint)(void *)) {
if (list == NULL) {
return;
}
struct LList * mylist = list;
//pCurrent 指向第一个有真实数据 节点
struct LinkNode * pCurrent = mylist->pHeader.next;
for(int i = 0; i < mylist->m_Size; i++){
//pCurrent 就是用户数据的首地址
myPrint(pCurrent);
pCurrent = pCurrent->next;
}
}
//返回链表长度
int size_LinkList(LinkList list) {
if (list == NULL) {
return -1;
}
//还原链表真实结构体
struct LList * mylist = list;
return mylist->m_Size;
}
//删除
//按位置
void removeByPos_LinkList(LinkList list, int pos) {
if (list == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
if (pos < 0 || pos > mylist->m_Size - 1) {
//无效位置
return;
}
//找到待删除位置的前驱节点位置
struct LinkNode * pCurrent = &mylist->pHeader;
for (int i = 0; i < pos; i++) {
pCurrent = pCurrent->next;
}
//pCurrent就是待删除节点的前驱节点位置
//利用指针记录待删除节点
struct LinkNode * pDel = pCurrent->next;
//更改指针指向
pCurrent->next = pDel->next;
//free(pDel);数据是用户开辟的,不用自己管理释放
//更新链表长度
mylist->m_Size--;
}
//按值删除
void removeByValue_LinkList(LinkList list, void * data, int(*myCompare)(void *, void *)) {
if (list == NULL) {
return;
}
if (data == NULL) {
return;
}
//还原链表真实结构体
struct LList * mylist = list;
//创建两个辅助指针变量
struct LinkNode * pPrev = &mylist->pHeader;
struct LinkNode * pCurrent = mylist->pHeader.next;
//遍历链表
for (int i = 0; i < mylist->m_Size; i++) {
if (myCompare(data, pCurrent->next)) {
//找到删除数据,开始删除
//更改指针指向
pPrev->next = pCurrent->next;
//更新链表长度
mylist->m_Size--;
break;
}
//辅助指针向后移动
pPrev = pCurrent;
pCurrent = pCurrent->next;
}
}
//销毁链表
void destroy_LinkList(LinkList list) {
if (list == NULL) {
return;
}
free(list);
list = NULL;
}
struct Person {
struct LinkNode node;
char name[64];
int age;
};
//回调函数打印数据
void printPerson(void * data) {
struct Person * person = data;
printf("姓名:%s 年龄:%d\n", person->name, person->age);
}
//回调函数 对比删除数据
int myCompare(void * data1, void * data2) {
struct Person * p1 = data1;
struct Person * p2 = data2;
return strcmp(p1->name, p2->name) == 0 && p1->age == p2->age;
}
void test1() {
//初始化链表
LinkList mylist = init_LinkList();
struct Person p1 = { NULL,"赵云", 18 };
struct Person p2 = { NULL,"张飞", 19 };
struct Person p3 = { NULL,"关羽", 20 };
struct Person p4 = { NULL,"刘备", 19 };
struct Person p5 = { NULL,"诸葛亮", 12 };
struct Person p6 = { NULL,"黄忠", 17 };
//插入数据
insert_LinkList(mylist, 0, &p1);
insert_LinkList(mylist, 0, &p2);
insert_LinkList(mylist, 1, &p3);
insert_LinkList(mylist, -1, &p4);
insert_LinkList(mylist, 1, &p5);
insert_LinkList(mylist, 100, &p6);
//遍历链表 张飞 诸葛亮 关羽 赵云 刘备 黄忠
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
printf("---------------------------------------------------\n");
printf("删除刘备后遍历结果:\n");
removeByPos_LinkList(mylist, 4);
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
struct Person p = { NULL,"关羽", 20 };
printf("---------------------------------------------------\n");
printf("删除刘备后遍历结果:\n");
removeByValue_LinkList(mylist, &p, myCompare);
foreach_LinkList(mylist, printPerson);
printf("链表长度为:%d\n", size_LinkList(mylist));
destroy_LinkList(mylist);
mylist = NULL;
}
//程序入口
int main() {
test1();
system("pause"); // 按任意键暂停 阻塞功能
return EXIT_SUCCESS; //返回 正常退出值 0
}