MapReduce用于大规模数据集的并行运算,所以性能优化也是需要重点关注的内容,下面是我在学习过程中,对于MapReduce 性能优化的点,分享大家学习,enjoy~~
MapReduce的运行流程

以上是MapReduce的运行流程,所以我们在考虑优化的时候主要从五个方面考虑:数据输入、Map阶段、Reduce阶段、Shuffle阶段和其他调优属性。
在执行MapReduce任务前,将小文件进行合并,大量的小文件会产生大量的map任务,增大map任务装载的次数,而任务的装载比较耗时,从而导致MapReduce运行速度较慢。因此我们采用CombineTextInputFormat来作为输入,解决输入端大量的小文件场景。
Map阶段优化
在 map 端,避免写入多个 spill 文件可能达到最好的性能,一个 spill 文件是最好的。通过估计 map 的输出大小,设置合理的 mapreduce.task.io.sort.* 属性,使得 spill 文件数量最小,重点内容有:
(1)减少溢写(spill)次数:通过调整io.sort.mb及sort.spill.percent参数值,增大触发spill的内存上限,减少spill次数,从而减少磁盘IO。
(2)减少合并(merge)次数:通过调整io.sort.factor参数,增大merge的文件数目,减少merge的次数,从而缩短mr处理时间。
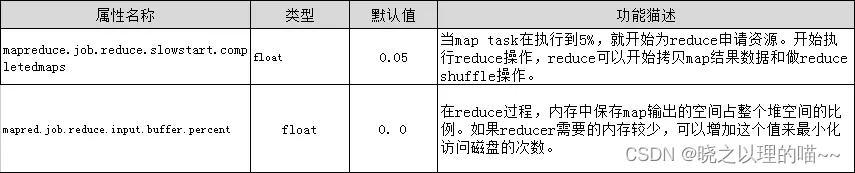
(3)在map之后,不影响业务逻辑前提下,先进行combine处理,减少I/O。我们在上面提到的那些属性参数,都是位于mapred-default.xml文件中,这些属性参数的调优方式如表所示。
(1)合理设置map和reduce数:两个都不能设置太少,也不能设置太多。太少,会导致task等待,延长处理时间;太多,会导致map、reduce任务间竞争资源,造成处理超时等错误。
(2)设置map、reduce共存:调整slowstart.completedmaps参数,使map运行到一定程度后,reduce也开始运行,减少reduce的等待时间。
(3)规避使用reduce:因为reduce在用于连接数据集的时候将会产生大量的网络消耗。通过将MapReduce参数setNumReduceTasks设置为0来创建一个只有map的作业。
(4)合理设置reduce端的buffer:默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多一个写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销。这样一来,设置buffer需要内存,读取数据需要内存,reduce计算也要内存,所以要根据作业的运行情况进行调整。
我们在上面提到的属性参数,都是位于mapred-default.xml文件中,这些属性参数的调优方式如表所示。
Shuffle阶段
Shuffle阶段的调优就是给Shuffle过程尽量多地提供内存空间,以防止出现内存溢出现象,可以由参数mapred.child.java.opts来设置,任务节点上的内存大小应尽量大。
我们在上面提到的属性参数,都是位于mapred-site.xml文件中,这些属性参数的调优方式如表所示。

reduce 优化
在 reduce 端,如果能够让所有数据都保存在内存中,可以达到最佳的性能。通常情况下,内存都保留给 reduce 函数,但是如果 reduce 函数对内存需求不是很高,将 mapreduce.reduce.merge.inmem.threshold(触发合并的 map 输出文件数)设为 0,mapreduce.reduce.input.buffer.percent(用于保存 map 输出文件的堆内存比例)设为1.0,可以达到很好的性能提升。在2008年的TB级别数据排序性能测试中,Hadoop 就是通过将 reduce 的中间数据都保存在内存中胜利的。

其他优化
MapReduce还有一些基本的资源属性的配置,这些配置的相关参数都位于mapred-default.xml文件中,我们可以合理配置这些属性提高MapReduce性能,下面列举了部分调优属性。

环形缓冲区
Map 的输出结果是由 collector 处理的,每个 Map 任务不断地将键值对输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫 Kvbuffer,名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个 Kvmeta 的别名,在Kvbuffer 的一块区域上穿了一个 IntBuffer(字节序采用的是平台自身的字节序)的马甲。数据区域和索引数据区域在 Kvbuffer 中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次 Spill 之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长的,Kvbuffer存放指针的 bufindex 是一直向上增长,比如 bufindex 初始值为0,一个 Int 型的 key 写完之后,bufindex 增长为4,一个 Int 型的 value 写完之后,bufindex 增长为8。
索引是对在 kvbuffer 中的键值对的索引,是个四元组,包括:value 的起始位置、key 的起始位置、partition 值、value 的长度,占用四个 Int 长度,Kvmeta 的存放指针的Kvindex 每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如 Kvindex 初始位置是 -4,当第一个键值对写完之后,(Kvindex+0) 的位置存放 value 的起始位置、(Kvindex+1) 的位置存放 key 的起始位置、(Kvindex+2) 的位置存放 partition 的值、(Kvindex+3) 的位置存放 value 的长度,然后 Kvindex 跳到 -8 的位置,等第二个键值对和索引写完之后,Kvindex 跳到 -12 位置。
以上内容,均来自网络学习整理,仅供大家学习交流,如有侵犯,联系删除哦!







![[数据结构]:06-队列(链表)(C语言实现)](https://img-blog.csdnimg.cn/b3ecae3eb7c2422ba896c6694ec376bb.png)