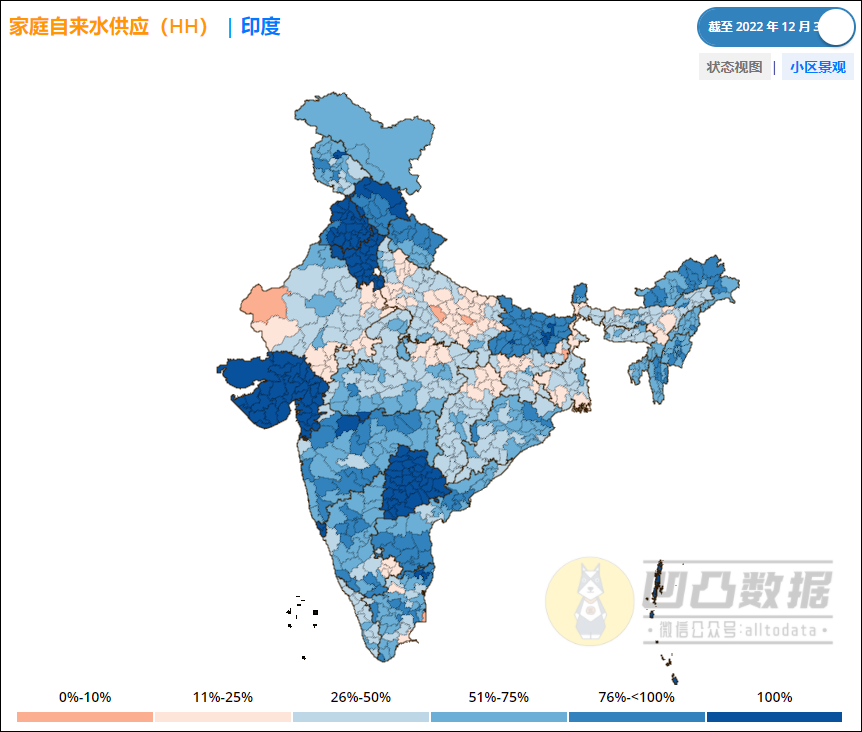
人生苦短,快学Python!
今天我们进行一次实战案例分享,以全球预期寿命与人均 GPD数据为例,写一篇 Python 中漂亮散点图的快速指南。除了正常的数据清洗/处理、还会进行简单的统计分析,实现数据处理-统计分析-可视化一条龙。
你会发现,用 Python 画如此漂亮的专业插图 ,So easy!
数据处理
所用数据:全球预期寿命与人均 GPD数据(已校正通货膨胀和跨国价格差异)
数据来源:https://ourworldindata.org/
本文所用数据和代码已打包,获取方式见文末。
导入数据:
import pandas as pd
expectancy_data = pd.read_csv("life-expectancy-vs-gdp-per-capita.csv")
# 为方便起见,重命名列
expectancy_data.rename(columns={"Entity":"Country",
"Life expectancy at birth (historical)": "Expectancy",
"GDP per capita": "GDP",
"Population (historical estimates)": "Population"}, inplace=True)
expectancy_data
输出:
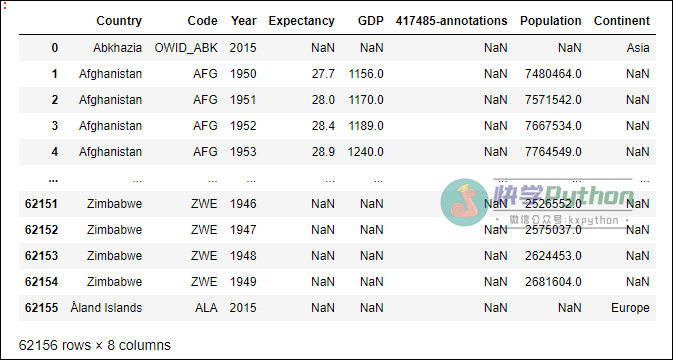
该数据表中的最新数据是2021年,但由于“均国内生产总值”这列数据只有道2018年的,所以我们本文便以2018年的数据为基础进行分析和可视化。同时,由于我们无法对缺失值进行分析,注意删除缺失值。
GDP_data = expectancy_data[~expectancy_data["GDP"].isna()]
GDP_data = GDP_data[GDP_data["Year"] == 2018]
GDP_data = GDP_data[GDP_data["Country"] != "World"]
GDP_data
输出:
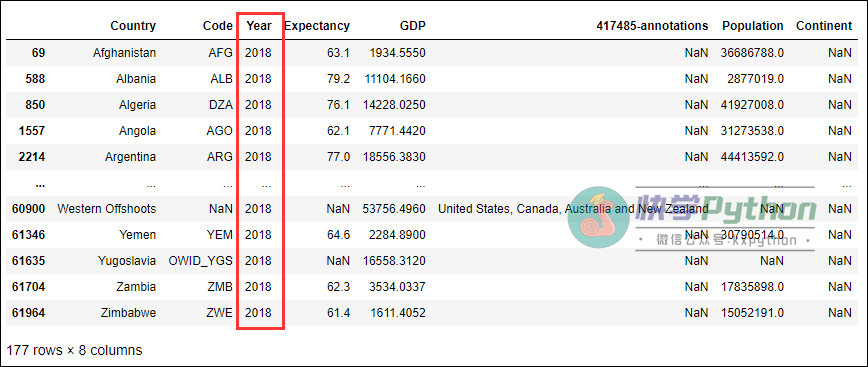
这样我们便完成了最基本的数据处理工作。
可视化
今天的可视化还会用到seaborn,它是一个调用 matplotlib 的统计绘图库
(https://github.com/mwaskom/seaborn)
导入所需Python库:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
import matplotlib.patches as mpatches
sns.set_style('darkgrid', {'font.sans-serif': ['simhei','FangSong']})
注意,上述代码最后一行是为了解决中文乱码。
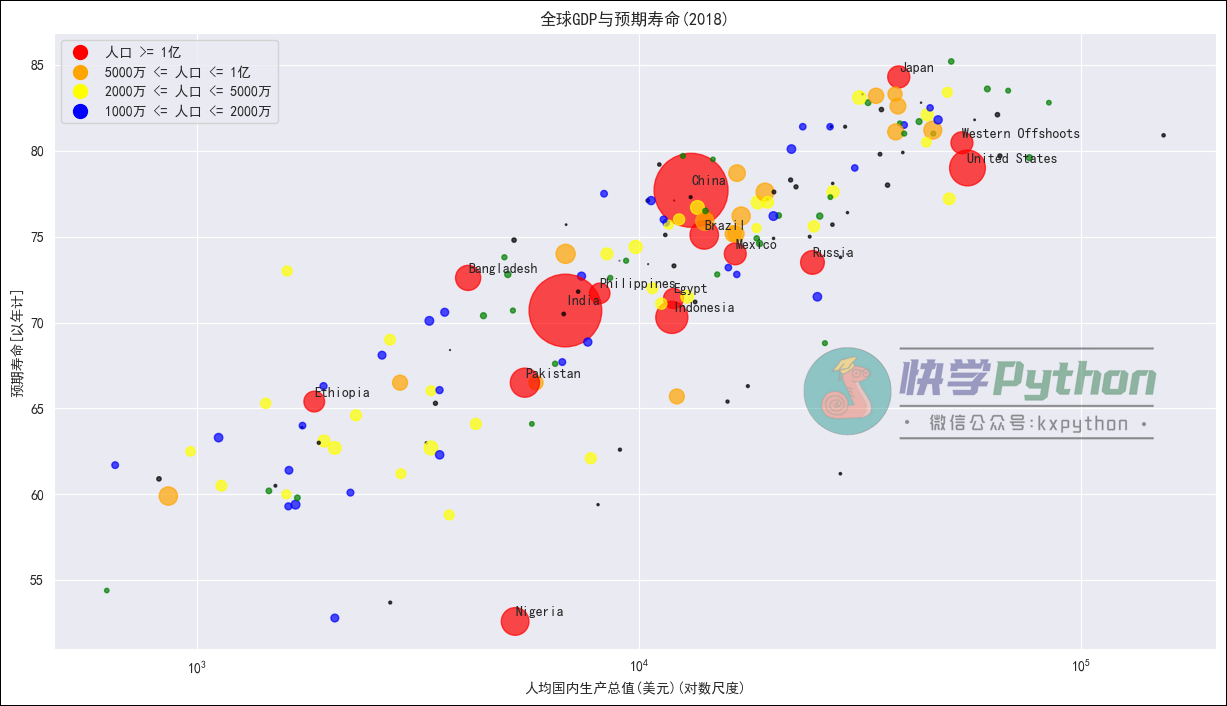
接下来我们便可以使用Matplotlib+seaborn制作漂亮的散点图,其中重要的一步是我们将Population列缩放一百万倍并乘以 2,这可以在绘制散点图时控制点的大小,人口越多,点越大。此外,我们还可以注释人口密度高的点,我们可以使用该plt.annotate()方法来完成。
df_new = pd.DataFrame(imputted_data, columns=["Expectancy", "GDP", "Population"])
df_new["Country"] = GDP_data.Country.tolist()
df_new = df_new[["Country", "Expectancy", "GDP", "Population"]]
for col in df_new.columns:
if col != "Country":
df_new[col] = df_new[col].apply(lambda x: round(x, 3))
df_country = df_new.groupby("Country").mean().reset_index()
df_country = df_country[["Country", "Expectancy", "GDP", "Population"]]
country = df_country["Country"]
GDP = df_country["GDP"]
life_exp = df_country["Expectancy"]
factor = 1000000
population = (df_country["Population"]/factor)*2
plt.figure(figsize=(15, 8))
plt.scatter(GDP, life_exp, s = population, alpha=0.9)
df_high_pop = df_country[df_country["Population"] >= 100000000]
for row in df_high_pop.to_dict(orient="records"):
plt.annotate(row["Country"], (row["GDP"], row["Expectancy"]+0.3), fontsize=10)
plt.xscale('log')
plt.xlabel('人均国内生产总值(美元)(对数尺度)')
plt.ylabel('预期寿命[以年计]')
plt.title('全球GDP与预期寿命(2018)',fontweight="bold")
plt.show()
输出结果:
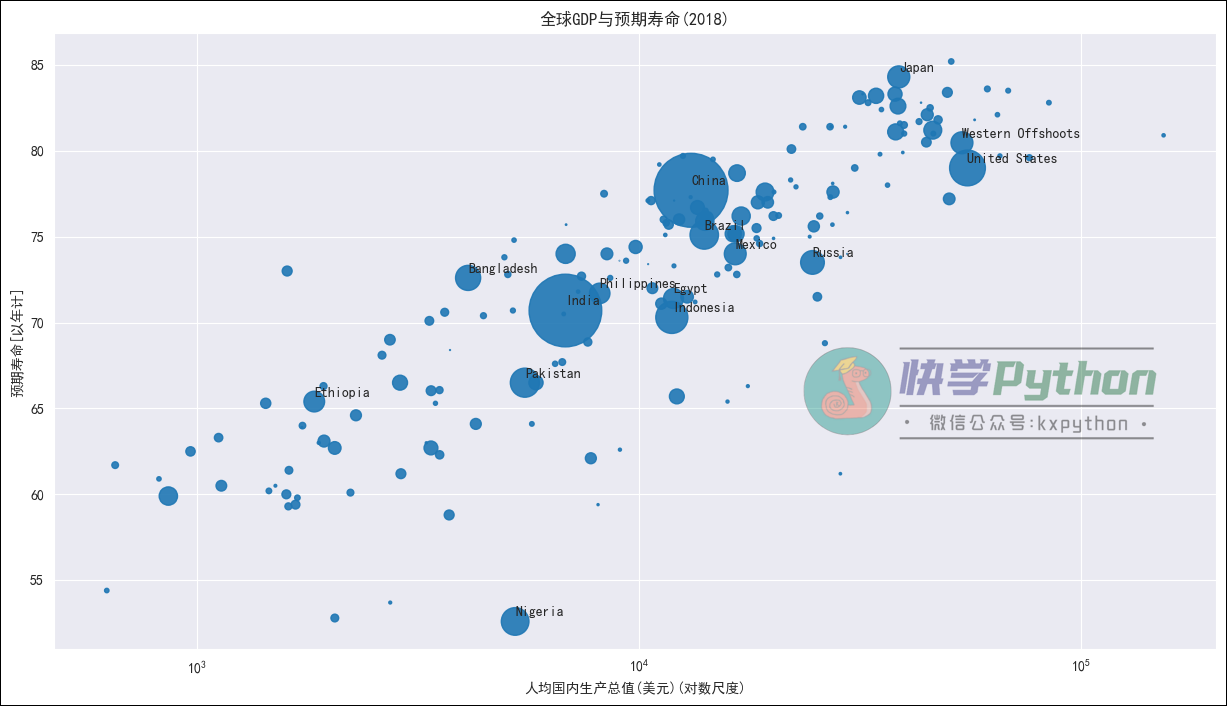
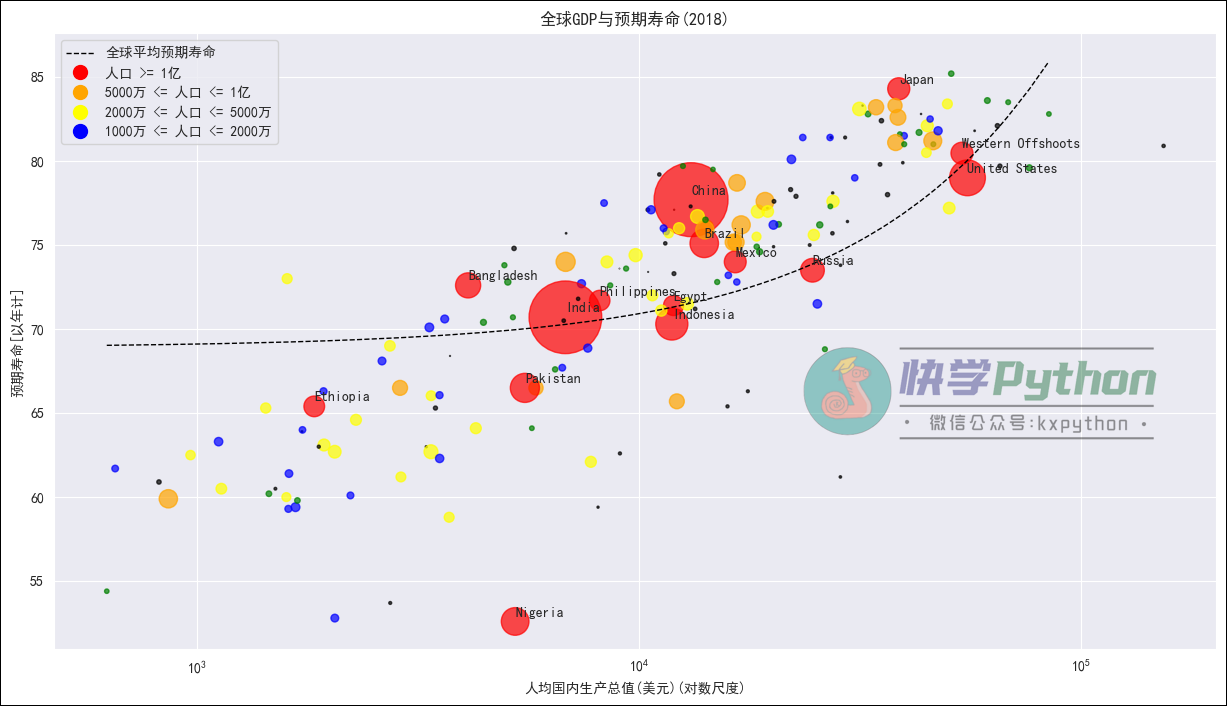
接下来还可以继续优化我们的散点图。比如在我们的数据中对每个国家/地区的人口密度点进行颜色编码,然后根据人数分配不同的颜色;
此外,我们还可以使用plt.legend()增加图例,如下图所示。

回归
进一步优化:基于KNN算法的新方法使得我们现在可以更便捷地处理缺失值,并且与直接用均值、中位数相比更为可靠。利用“近朱者赤”的KNN算法原理,这种插补方法借助其他特征的分布来对目标特征进行缺失值填充。
# sklearn
from sklearn.impute import KNNImputer
from sklearn.linear_model import ElasticNetCV
imputer = KNNImputer(n_neighbors=3)
imputted_data = imputer.fit_transform(df[["Expectancy", "GDP", "Population"]])
我们另外还想在散点图上画一条非常漂亮的线,用于帮助我们提供一种快速评估各个国家相对于总体趋势的状况的方法。我们可以使用Scikit-learn中的ElasticNet,它是一个使用 L1 和 L2 正则化训练的线性回归模型。它是 LASSO 和岭回归技术的混合体,因此它也非常适合显示严重多重共线性(特征彼此高度相关)的模型。
部分代码(完整下载见文末):
if regression:
reg = ElasticNetCV(cv=5, random_state=0)
X, y = np.array(GDP).reshape(-1, 1), life_exp
reg.fit(X,y)
y_pred = reg.predict(X)
reg_data = pd.DataFrame(X, columns=["X"])
reg_data["y_pred"] = y_pred
reg_data = reg_data.sort_values(by="X").reset_index().drop("index", axis=1)
reg_data = reg_data[reg_data["y_pred"] <= 90]
使用训练好的模型,绘制一条拟合曲线:
人生苦短,快学Python!
如果喜欢今天分享的文章,别忘了给我们点赞支持一下!
大家如果本文涉及的代码感兴趣,可以点击下方卡片,关注公众号【朱小五】(非本号)后台回复“花卉”即可获取对应【图片+完整代码】文件。
最近我花了两年写的新书已经上市,也算是我在CSDN博客分享Python知识3年的一个总结!

《快学Python:自动化办公轻松实战》点击蓝字查看书籍详情,感谢支持
![[数据结构]:06-队列(链表)(C语言实现)](https://img-blog.csdnimg.cn/b3ecae3eb7c2422ba896c6694ec376bb.png)