目录
- Hadoop介绍
- Hadoop集群
- HDFS分布式文件系统基础
- 文件系统与分布式文件系统
- HDFS简介
- HDFS shell命令行
- HDFS工作流程与机制
- HDFS集群角色与职责
- HDFS写数据流程(上传文件)
- HDFS读数据流程(下载文件)
Hadoop介绍
用Java语言实现开源
允许用户使用简单的编程模型实现对海量数据发分布式计算处理
Hadoop核心组件:
- HDFS :存储
- YARN:资源调度
- MapReduce:计算
广义Hadoop是指大数据生态圈
HAdoop特点:扩容能力、成本低、效率高、可靠性(多份复制)
Hadoop集群
Hadoop包括两个集群:HDFS集群、YARN集群

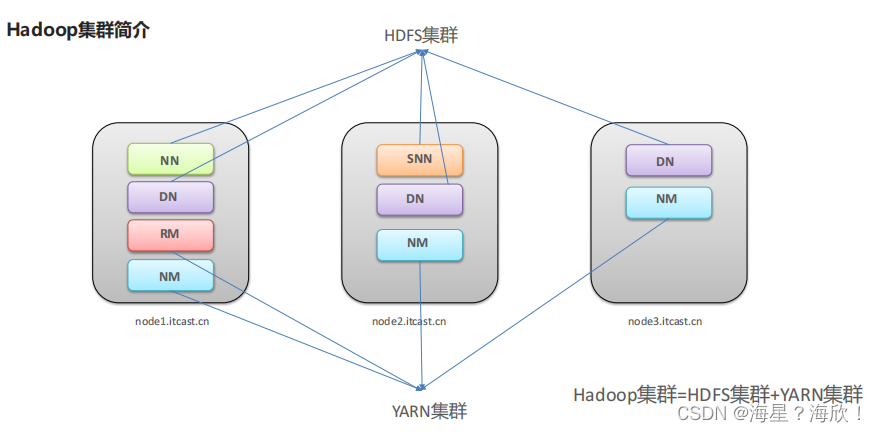
- 逻辑上分离:两集群相互之间没有依赖关系,互不影响
- 物理上在一起:往往部署在同一台物理服务器上
- MapReduce是计算框架、代码层面的组件,没有集群之说
启停操作:
- 手动逐个进程启停:
- shell脚本一键启停
HDFS集群:start-dfs.sh stop-dfs.sh
YARN集群:start-yarn.sh stop-yarn.sh
hadoop集群: start-all.sh stop-all.sh
启动完毕后可以使用jps命令查看进程是否启动成功
Hadoop启动日志路径 /expert/server/hadoop-3.3.0/logs/
- HDFS本质是一个文件系统
- 有目录树结构,和Linux类似
HDFS分布式文件系统基础
文件系统与分布式文件系统
文件系统是一种存储组织数据的方法,实现了数据的存储、分级组织,访问获取等,使得用户对文件访问和查找变得容易
传统文件系统多指单机文件系统,比如Windows文件系统、Linux文件系统、FTP文件系统等,特点是:
- 带有抽象的目录树结构,树都是从/根目录开始调度
- 树中节点分为:目录和文件
- 从根目录开始,节点路径具有唯一性
数据:底层是存储在磁盘上的,用户只需基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成
元数据:记录数据的数据
文件系统元数据,一般指文件大小、最后修改时间、底层存储位置、属性,所属用户、权限等信息
大数据时代下,单机遇到问题:成本大,计算效率低、性能低
分布式存储系统核心属性:分布式存储、元数据记录、分块存储、副本机制
1,分布式存储
问题:存储遇到瓶颈
单机纵向扩展:磁盘不够家磁盘,有上限瓶颈限制
多机横向扩展:机器不够加机器,理论上无限扩展 —多机分布式
2,元数据记录
文件分布在不同机器上不利于查找 — 元数据记录,快速定位文件位置
3,文件分块存储
问题:文件过大导致单机存不下,上传下载效率低
解决:将文件分块,存储在不同机器上,针对块并行操作提高效率
4,副本机制
问题:硬件故障,数据容易丢失
解决:不同机器设置备份,冗余存储、保证数据安全
总结:分布式存储系统核心属性:
- 分布式存储:无限支持海量数据存储
- 元数据记录:快速定位文件位置便于查找
- 文件分块存储:块并行操作提高效率
- 设置副本备份:冗余存储,保证数据安全
HDFS简介
HDFS:HAdoop分布式文件系统
作为大数据生态圈最底层,主要用于解决大数据存储问题,HDFS使用多台计算机存储文件,并且提供统一的访问接口
HDFS的核心架构目标:故障检测和自动快速恢复
HDFS对文件要求write-one-read-many。一个文件一旦创建、写入、关闭之后就不需要修改了
HDFS适合场景:大文件、一次写入多次访问,低成本部署、高容错数据流式访问
HDFS不适合场景:小文件、数据交互式访问、频繁任意修改、低延迟处理
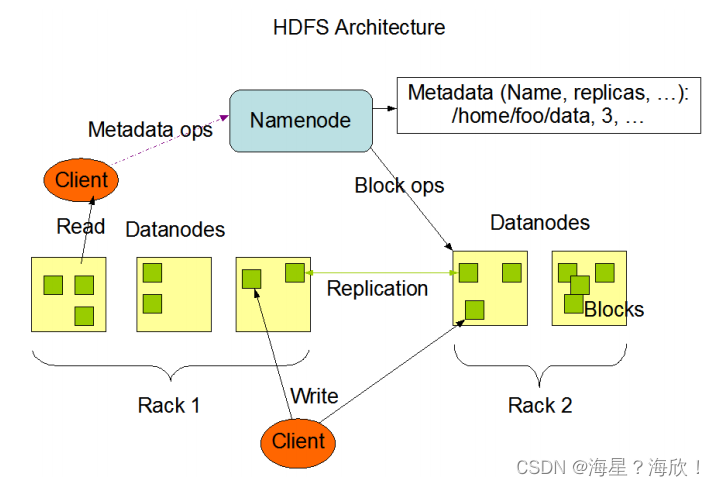
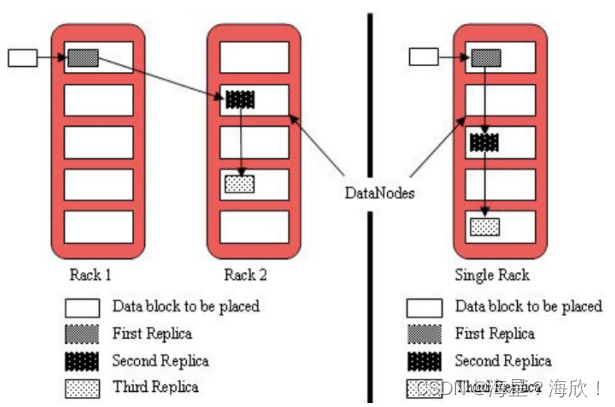
图中rack指机架
特点:
-
主从架构:1个Namenode 5个Datenodes
Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务 -
数据都是小方块–分块存储
HDFS中的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块,即只有文件超过1278时才会被分块 -
块与块之间replication–副本备份
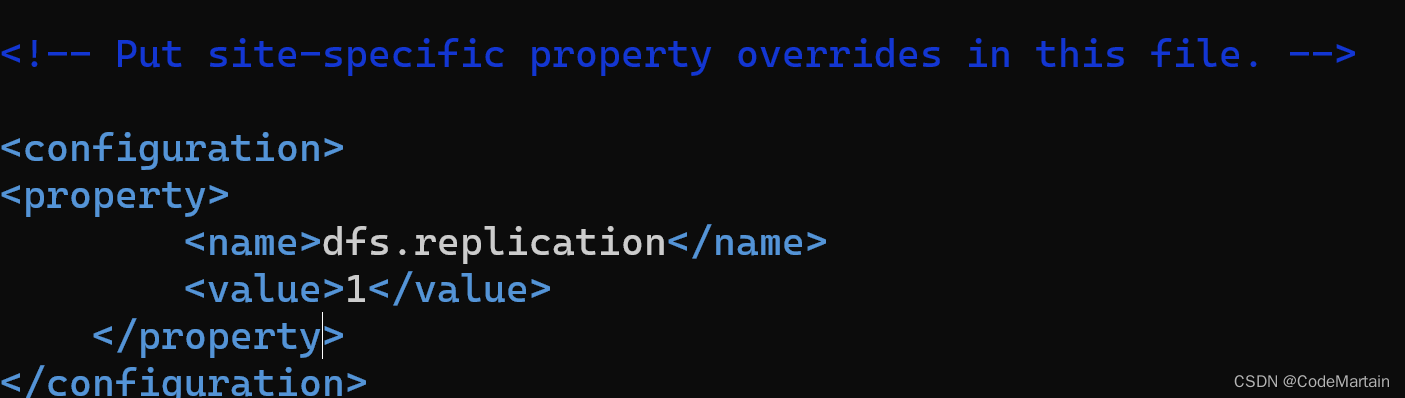
副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本。 -
Namenode中记录Metadata元数据
在HDFS中,Namenode管理的元数据具有两种类型:
1.文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
2.文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。 -
抽象统一的目录树结构
HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件
HDFS shell命令行
命令行CLI:指用户通过键盘输入指令,计算机接收到指令后予以执行的一种人机交互方式
Hadoop中shell命令行:hadoop fs [generic options]
在node1中输入:
hadoop fs -ls file:///
#查看的本地文件系统
hadoop fs -ls hdfs://node1:8020/
#查看hdfs根目录下
hdoop fs -ls /
#输出的是hdfS的目录,是因为设置的默认是hdfs
cat /export/server/hadoop-3.3.0/etc/hadoop/core-size.html
#查看,可以看到默认的是hdfs
hdfs中shell命令和Linux很相似
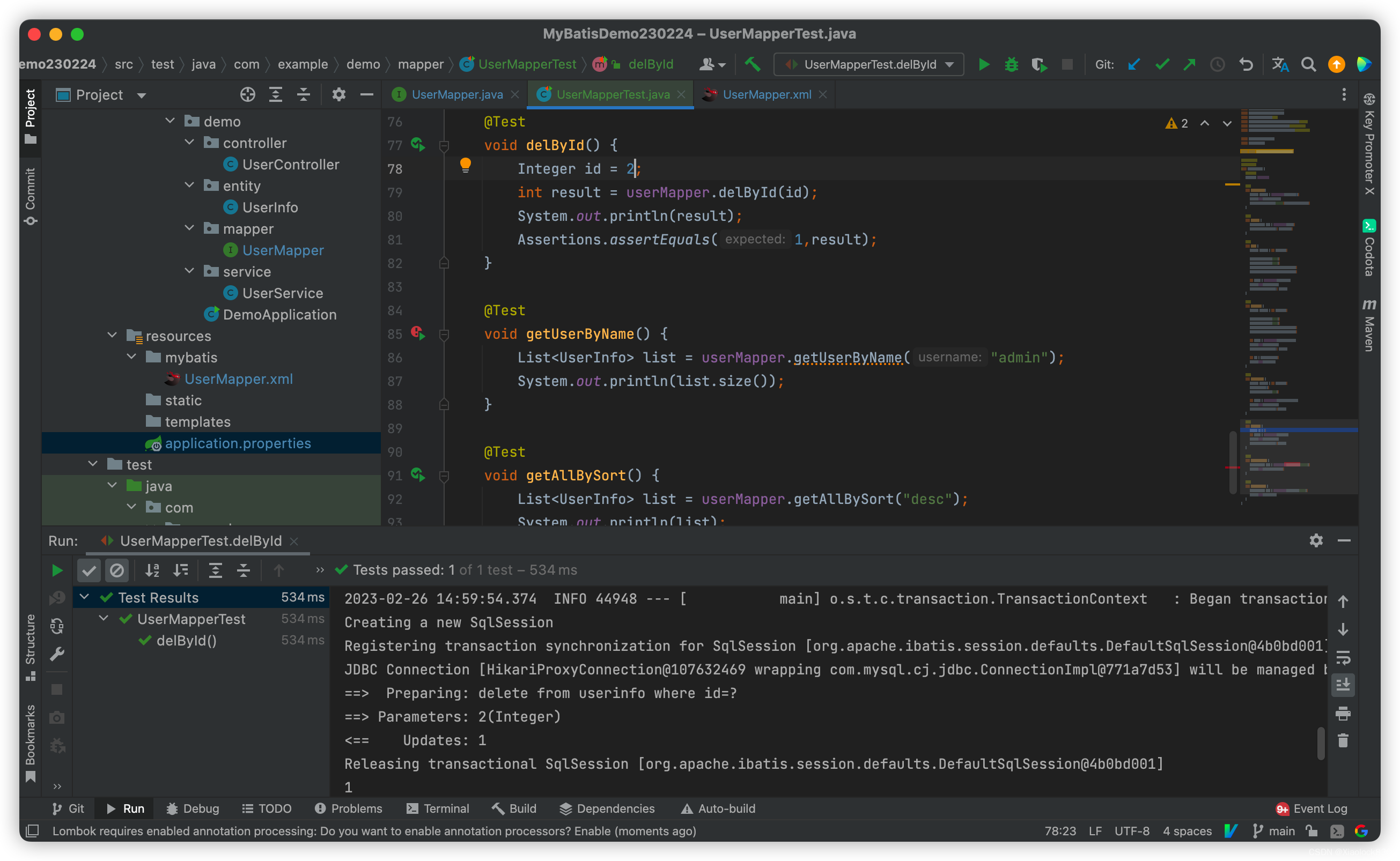
hadoop fs -mkdir [-p]
hadoop fs -ls [-h] [-R] [
hadoop fs -put [-f] [-p] … 上传文件到指定目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)
hadoop fs -put file:///root/2.txt hdfs://node1:8020/ithei
#将本地root目录下2.txt文件上传到hefs上node1端口号8020的ithei文件下
#上面的省略写法:
hadoop fs -put 2.txt /
hadoop fs -cat … 查看hdfs文件内容
hadoop fs -cat /ithei/2.txt
hadoop fs -get [-f] [-p] … 下载hdfs上文件到本地
hadoop fs -get /ithei/2.txt ./666.txt
#将hdfs上ithei文件夹下2.txt文件下载到本地/根目录下,并改名为了666.txt
hadoop fs -cp [-f] … 拷贝hdfs文件
Hadoop fs -put 1.txt #1.txt上传到hads
hadoop fs -cat /1.txt
hadoop fs -appendToFile … 将所有给定本地文件的内容追加到给定dst文件.追加合并
echo 1 > 1.txt #将内容1写入1.txt
echo 2 > 2.txt
echo 3 > 3.txt
hadoop fs -put 1.txt / #先将1.txt上传
hadoop fs -cat /1.txt #查看hdfs上/目录下1.txt内容,输出1
hadoop fs -appendToFile 2.txt 3.txt /1.txt #将2.txt与3.txt追加到1.txt中
hadoop fs -cat /1.txt #再次查看,输出1,2,3
官方指导文档
HDFS工作流程与机制
HDFS集群角色与职责
主角色:namenode
- NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
- NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
- 基于此,NameNode成为了访问HDFS的唯一入口。
- NameNode内部通过内存和磁盘文件两种方式管理元数据。(内存速度快,但是断电数据丢失,所以也放在磁盘文件上)
- namenode仅存储HDFS的元数据,并不存储数据块
- namenode知道任何给定文件的块列表和位置。用户想要查找某文件都必须通过namenode
- namenode并不持久存储每个文件中各个块所在的datenode信息,关机后只记录有哪些文件,文件中有哪些块并不知道,这些信息在系统启动中由小弟汇报过来
- namenode需要大内存,因为元数据存储需要大内存
- namenode是Hadoop集群中的单点故障(单点故障:某一个局部出问题会导致整体出问题。上课老师与同学中,老师便是一个单点故障)
从角色:datanode
- DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储
- 并和NameNode配合维护着数据块,要删就删,要增就增
- datenode负责最终块block的存储,也称为slave,从角色
- 启动时,会将自己注册到nameode并汇报自己所有的块列表
- 当某个datenode关闭时,不会影响数据,因为是默认3副本,冗余存储
- datenode在部署时需要大量硬盘空间,即大磁盘,因为实际数据在datenode中
主角色辅助角色: secondarynamenode
- 充当NameNode的辅助节点,但不能替代NameNode
- 主要是帮助主角色进行元数据文件的合并动作。可以理解为主角色的“秘书”
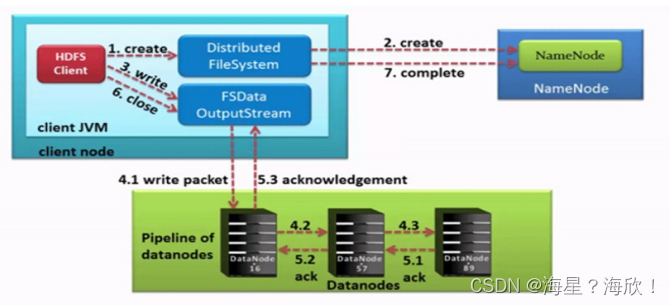
HDFS写数据流程(上传文件)
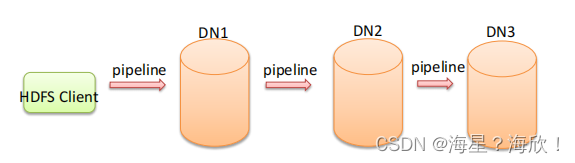
Pipeline管道
这是HDFS在上传文件写数据过程中采用的一种数据传输方式
- 客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
- 为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
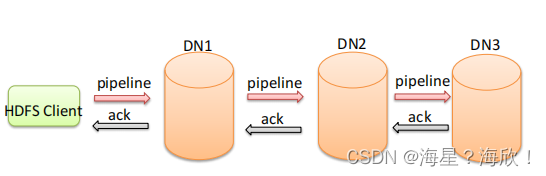
ACK应答响应 - ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
- 在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全
默认3副本存储策略
- 第一块副本:优先客户端本地,否则就近随机
- 第二块副本:不同于第一块副本的不同机架。机架类似机柜
- 第三块副本:第二块副本相同机架不同机器。
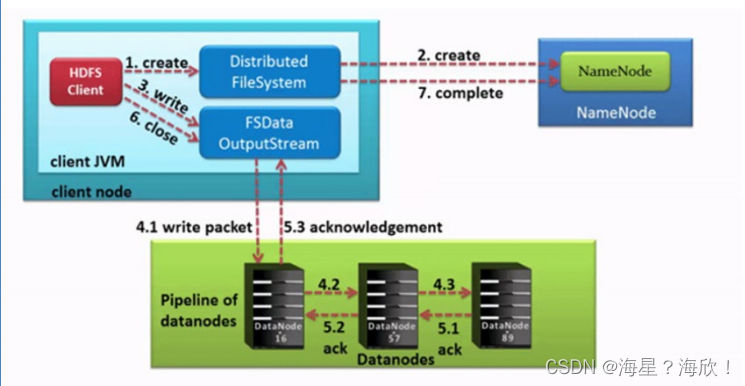
上传文件流程:
- HDFS客户端创建对象实例DistributedFileSystem, 该对象中封装了与HDFS文件系统操作的相关方法。
- 调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。
检查通过, NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。 - 客户端通过FSDataOutputStream输出流开始写入数据。
- 客户端写入数据时,将数据分成一个个数据包(packet 默认64k), 内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储
- 传输的反方向上,会通过ACK机制校验数据包传输是否成功;
- 客户端完成数据写入后,最后在FSDataOutputStream输出流上调用close()方法关闭。
- DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回。
最小复制是由参数dfs.namenode.replication.min指定,默认是1.只要有一个副本成功就认为是上传成功。
HDFS读数据流程(下载文件)

读数据流程:
-
HDFS客户端创建对象实例DistributedFileSystem, 调用该对象的open()方法来打开希望读取的文件。
-
DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置(分批次读取)信息。
-
DistributedFileSystem将FSDataInputStream输入流返回到客户端以供其读取数据。
-
客户端在FSDataInputStream输入流上调用read()方法。然后,已存储DataNode地址的InputStream连接到文件中第一个块的最近的DataNode。数据从DataNode流回客户端,结果客户端可以在流上重复调用read()。
-
当该块结束时,FSDataInputStream将关闭与DataNode的连接,然后寻找下一个block块的最佳datanode位置。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流
客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。 -
一旦客户端完成读取,就对FSDataInputStream调用close()方法。





![[数据结构]:06-队列(链表)(C语言实现)](https://img-blog.csdnimg.cn/b3ecae3eb7c2422ba896c6694ec376bb.png)