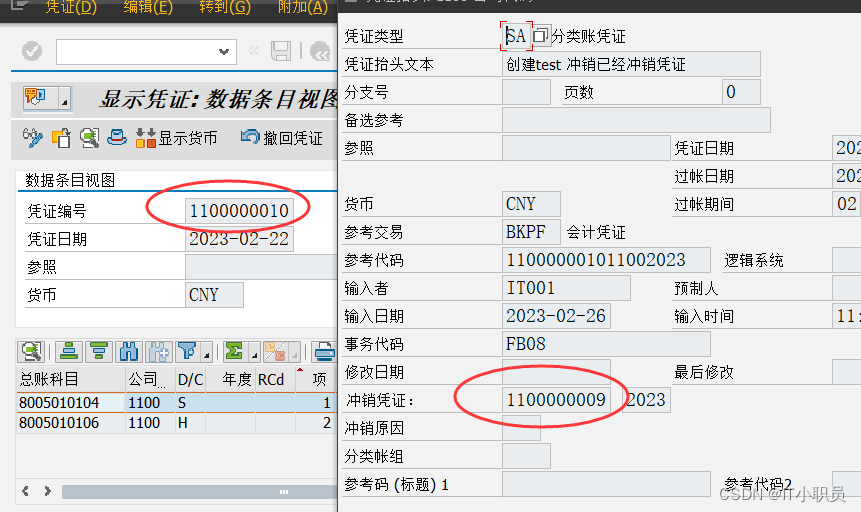
对话
我们是如何学会中文的?从0岁开始,听、说,也就是对话。
我们是如何学外语的?看教材,听广播,背单词。唯独缺少了对话!正是因为缺少了对话这个高效的语言学习方式,所以我们的英语水平才如此难以提高。
对于语言模型,同理。对话是涵盖一切 NLP 任务的终极任务。从此 NLP不再需要模型建模这个过程。比如,传统 NLP 里还有序列标注这个任务,需要用到 CRF 这种解码过程。在对话的世界里,这些统统都是冗余的。
其实 CRF 这项技术还是蛮经典的,在深度学习这块,CRF这也才过去没几年。人工智能发展之快,sigh……
in-context learning
以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。
GPT-3 就开始颠覆这种认知了。它提出了一种 in-context 学习方式。这个词没法翻译成中文,下面举一个例子进行解释。
用户输入到 GPT-3:你觉得 JioNLP 是个好用的工具吗?
GPT-3输出1:我觉得很好啊。
GPT-3输出2:JioNLP是什么东西?
GPT-3输出3:你饿不饿,我给你做碗面吃……
GPT-3输出4:Do you think jionlp is a good tool?
按理来讲,针对机器翻译任务,我们当然希望模型输出最后一句,针对对话任务,我们希望模型输出前两句中的任何一句。另外,显然做碗面这个输出的句子显得前言不搭后语,是个低质量的对话回复。
这时就有了 in-context 学习,也就是,我们对模型进行引导,教会它应当输出什么内容。如果我们希望它输出翻译内容,那么,应该给模型如下输入:
用户输入到 GPT-3:请把以下中文翻译成英文:你觉得 JioNLP 是个好用的工具吗?
如果想让模型回答问题:
用户输入到 GPT-3:模型模型你说说,你觉得 JioNLP 是个好用的工具吗?
OK,这样模型就可以根据用户提示的情境,进行针对性的回答了。
这里,只是告知了模型如何做,最好能够给模型做个示范,这也蛮符合人们的日常做事习惯,老师布置了一篇作文,我们的第一反应是,先参考一篇范文找找感觉。
在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“做数学加法,改错,翻译”同时进行。这其实就类似前段时间比较火的 prompt。
这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。注意啊,是超大模型才可以,一般几亿、十几亿参数的大模型是不行的。(我们这里没有小模型,只有大模型、超大模型、巨大模型)

1、要么做第一个,要么做最好的一个。
2、信念和目标,必须永远洋溢在程序员内心。3、最累的时候,家人是你最好的归宿。
4、C程序员永远不会灭亡。他们只是cast成了void。
5、真正的程序员认为自己比用户更明白用户需要什么。
6、退一步海阔天空,这是一种应有的心境。
7、过去的代码都是未经测试的代码。
8、优秀的判断力来自经验,但经验来自于错误的判断。
9、测试是来表明bug的存在而不是不存在。
10、我们这个世界的一个问题是,蠢人信誓旦旦,智人满腹狐疑。
11、一个好汉三个帮,程序员同样如此。
12、看再多的书是学不全脚本的,要多实践。13、无私奉献不是天方夜谭,有时候,我们也可以做到。
14、世界上只有两句真理:1、人一定会死。2、程序一定有Bug。
15、UNIX很简单。但需要有一定天赋的人才能理解这种简单。
16、程序中蕴含着很多的道理,唯有大彻大悟者方能体会其中的奥妙。
17、编程中我们会遇到多少挫折?表放弃,沙漠尽头必是绿洲。
18、做技术一定要一颗恒心,这样才不会半途而废。
19、不要被对象、属性、方法等词汇所迷惑;最根本的是先了解最基础知识。
20、请把书上的例子亲手到电脑上实践,即使配套光盘中有源文件。