文章目录
- 一、xgboost库与XGB的sklearn API
- XGBoost的三大板块
- 二、梯度提升树
- 提升集成算法:重要参数n_estimators
- 三、有放回随机抽样:重要参数subsample
- 四、迭代决策树:重要参数eta
- 总结
一、xgboost库与XGB的sklearn API
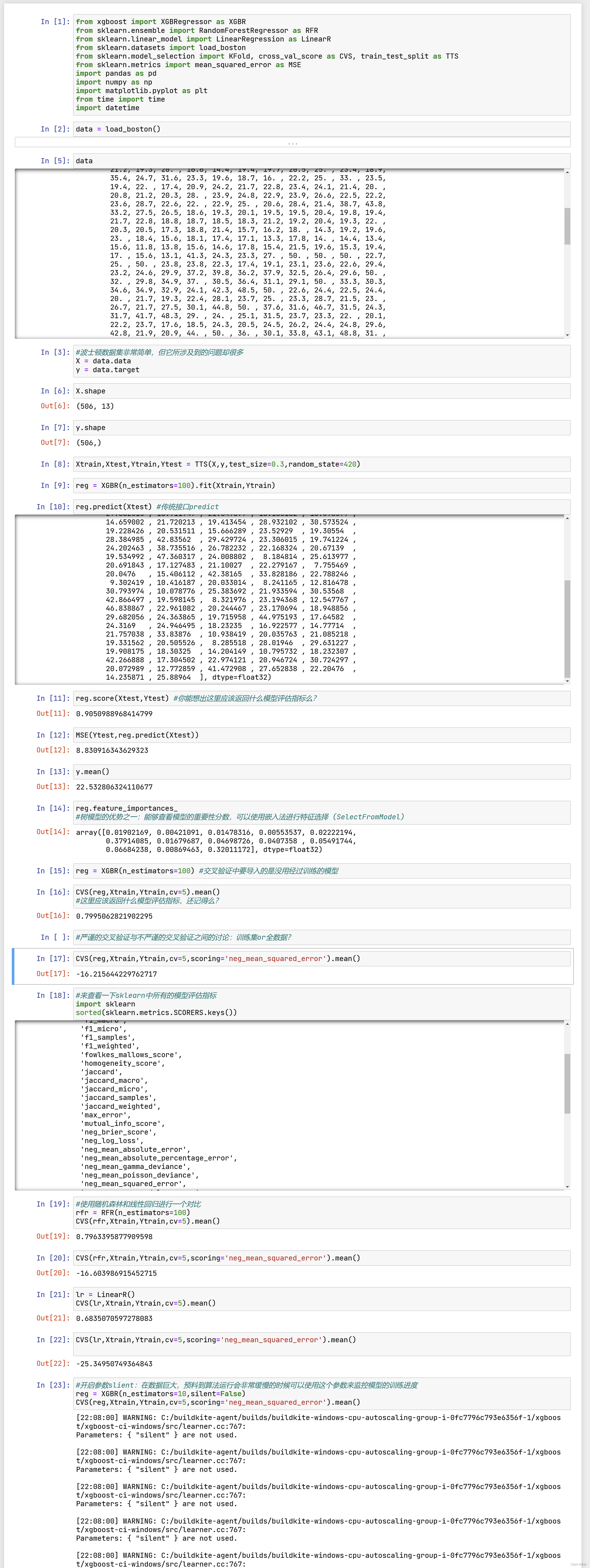
现在,我们有两种方式可以来使用我们的xgboost库。第一种方式,是直接使用xgboost库自己的建模流程。
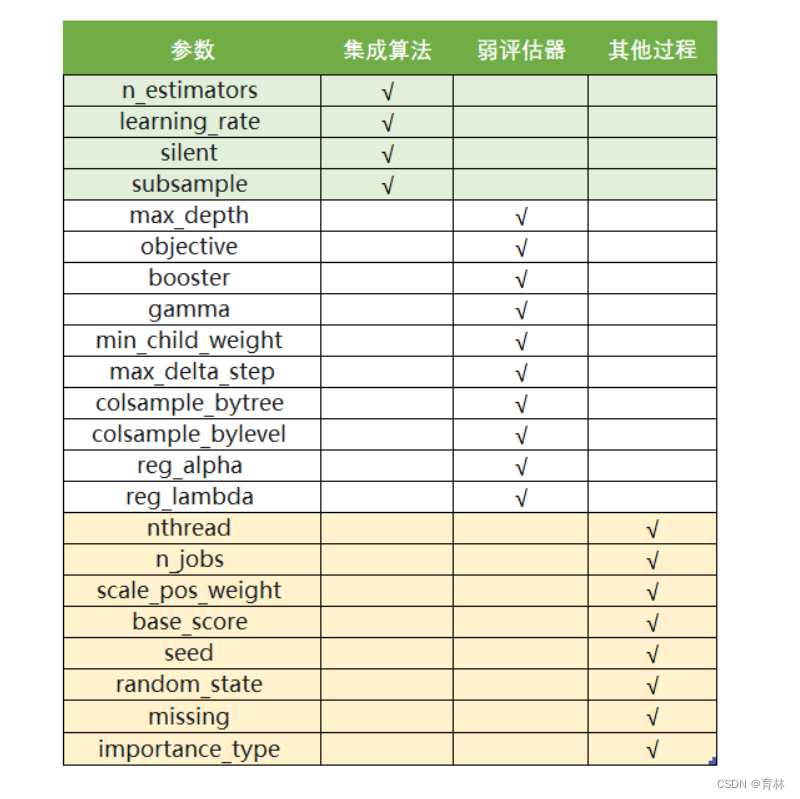
params {eta, gamma, max_depth, min_child_weight, max_delta_step, subsample, colsample_bytree,
colsample_bylevel, colsample_bynode, lambda, alpha, tree_method string, sketch_eps, scale_pos_weight, updater,
refresh_leaf, process_type, grow_policy, max_leaves, max_bin, predictor, num_parallel_tree}
xgboost.train (params, dtrain, num_boost_round=10, evals=(), obj=None, feval=None, maximize=False,
early_stopping_rounds=None, evals_result=None, verbose_eval=True, xgb_model=None, callbacks=None,
learning_rates=None)
或者,我们也可以选择第二种方法,使用xgboost库中的sklearn的API。这是说,我们可以调用如下的类,并用我们
sklearn当中惯例的实例化,fit和predict的流程来运行XGB,并且也可以调用属性比如coef_等等。当然,这是我们回
归的类,我们也有用于分类,用于排序的类。他们与回归的类非常相似,因此了解一个类即可。
class xgboost.XGBRegressor (max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective=‘reg:linear’, booster=‘gbtree’, n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0,
subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
base_score=0.5, random_state=0, seed=None, missing=None, importance_type=‘gain’, **kwargs)
看到这长长的参数条目,可能大家会感到头晕眼花——没错XGB就是这门复杂。但是眼尖的小伙伴可能已经发现了,
调用xgboost.train和调用sklearnAPI中的类XGBRegressor,需要输入的参数是不同的,而且看起来相当的不同。但
其实,这些参数只是写法不同,功能是相同的。比如说,我们的params字典中的第一个参数eta,其实就是我们
XGBRegressor里面的参数learning_rate,他们的含义和实现的功能是一模一样的。只不过在sklearnAPI中,开发团
队友好地帮助我们将参数的名称调节成了与sklearn中其他的算法类更相似的样子。
所以对我们来说,使用xgboost中设定的建模流程来建模,和使用sklearnAPI中的类来建模,模型效果是比较相似
的,但是xgboost库本身的运算速度(尤其是交叉验证)以及调参手段比sklearn要简单。我们的课是sklearn课堂,
因此在今天的课中,我会先使用sklearnAPI来为大家讲解核心参数,包括不同的参数在xgboost的调用流程和sklearn
的API中如何对应,然后我会在应用和案例之中使用xgboost库来为大家展现一个快捷的调参过程。如果大家希望探
索一下这两者是否有差异,那必须具体到大家本身的数据集上去观察。
XGBoost的三大板块
二、梯度提升树
class xgboost.XGBRegressor (max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective=‘reg:linear’, booster=‘gbtree’, n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0,
subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
base_score=0.5, random_state=0, seed=None, missing=None, importance_type=‘gain’, **kwargs)
提升集成算法:重要参数n_estimators
XGBoost的基础是梯度提升算法,因此我们必须先从了解梯度提升算法开始。梯度提升(Gradient boosting)是构
建预测模型的最强大技术之一,它是集成算法中提升法(Boosting)的代表算法。集成算法通过在数据上构建多个弱
评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。弱评估器被定义为是表现至少比
随机猜测更好的模型,即预测准确率不低于50%的任意模型。
集成不同弱评估器的方法有很多种。有像我们曾经在随机森林的课中介绍的,一次性建立多个平行独立的弱评估器的
装袋法。也有像我们今天要介绍的提升法这样,逐一构建弱评估器,经过多次迭代逐渐累积多个弱评估器的方法。提
升法的中最著名的算法包括Adaboost和梯度提升树,XGBoost就是由梯度提升树发展而来的。梯度提升树中可以有
回归树也可以有分类树,两者都以CART树算法作为主流,XGBoost背后也是CART树,这意味着XGBoost中所有的树
都是二叉的。接下来,我们就以梯度提升回归树为例子,来了解一下Boosting算法是怎样工作的。
梯度提升回归树是专注于回归的树模型的提升集成模型,其建模过程大致如下:最开始先建立一棵树,然后逐
渐迭代,每次迭代过程中都增加一棵树,逐渐形成众多树模型集成的强评估器。
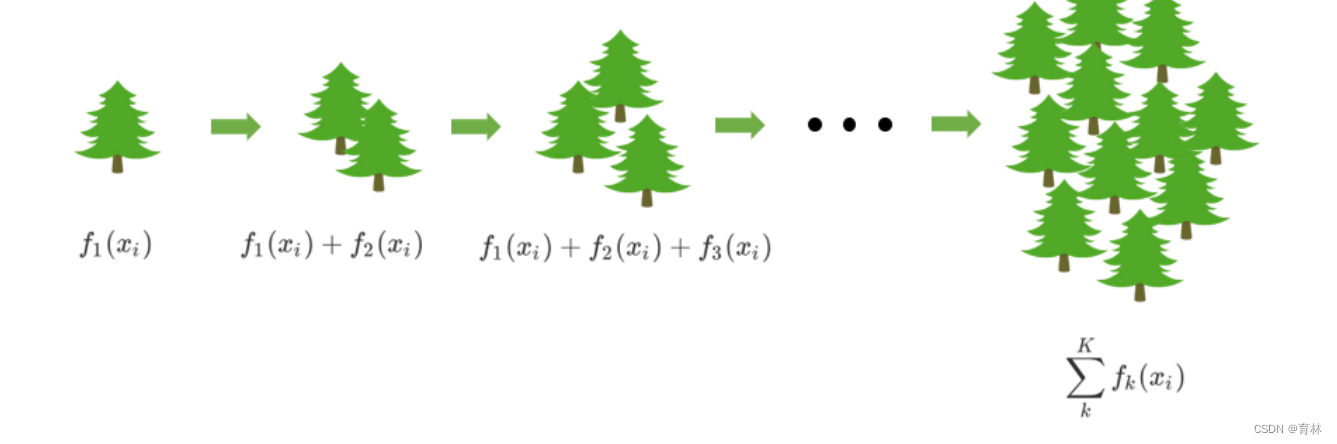
对于梯度提升回归树来说,每个样本的预测结果可以表示为所有树上的结果的加权求和:
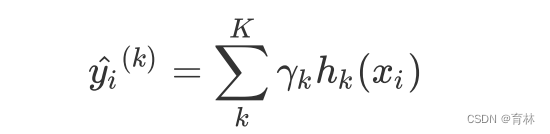
其中, 是树的总数量, 代表第 棵树, 是这棵树的权重, 表示这棵树上的预测结果。
值得注意的是,XGB作为GBDT的改进,在 上却有所不同。对于XGB来说,每个叶子节点上会有一个预测分数
(prediction score),也被称为叶子权重。这个叶子权重就是所有在这个叶子节点上的样本在这一棵树上的回归取
值,用 或者 来表示,其中 表示第 棵决策树, 表示样本 对应的特征向量。当只有一棵树的时候,
就是提升集成算法返回的结果,但这个结果往往非常糟糕。当有多棵树的时候,集成模型的回归结果就是所有树的预
测分数之和,假设这个集成模型中总共有 棵决策树,则整个模型在这个样本 上给出的预测结果为:
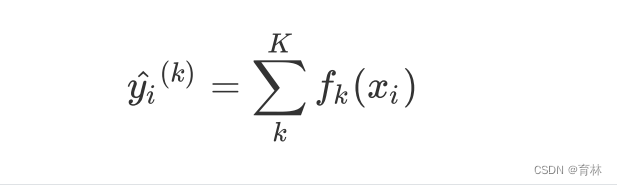
回忆一下我们曾经在随机森林中讲解过的方差-偏差困境。在机器学习中,我们用来衡量模型在未知数据上的准确率
的指标,叫做泛化误差(Genelization error)。一个集成模型(f)在未知数据集(D)上的泛化误差 ,由方差
(var),偏差(bais)和噪声(ε)共同决定。其中偏差就是训练集上的拟合程度决定,方差是模型的稳定性决定,噪音是不
可控的。而泛化误差越小,模型就越理想。
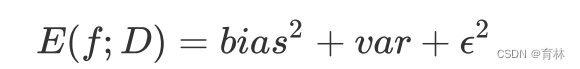
三、有放回随机抽样:重要参数subsample
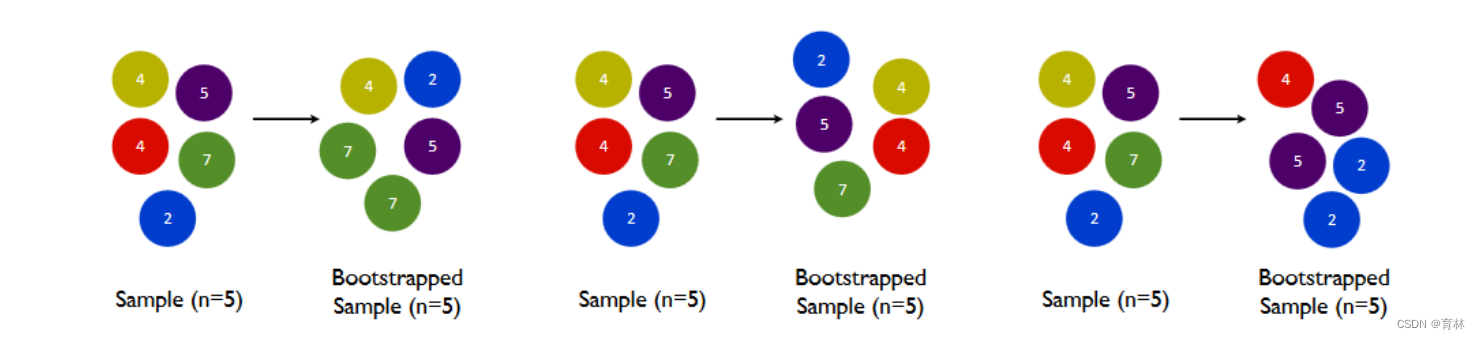
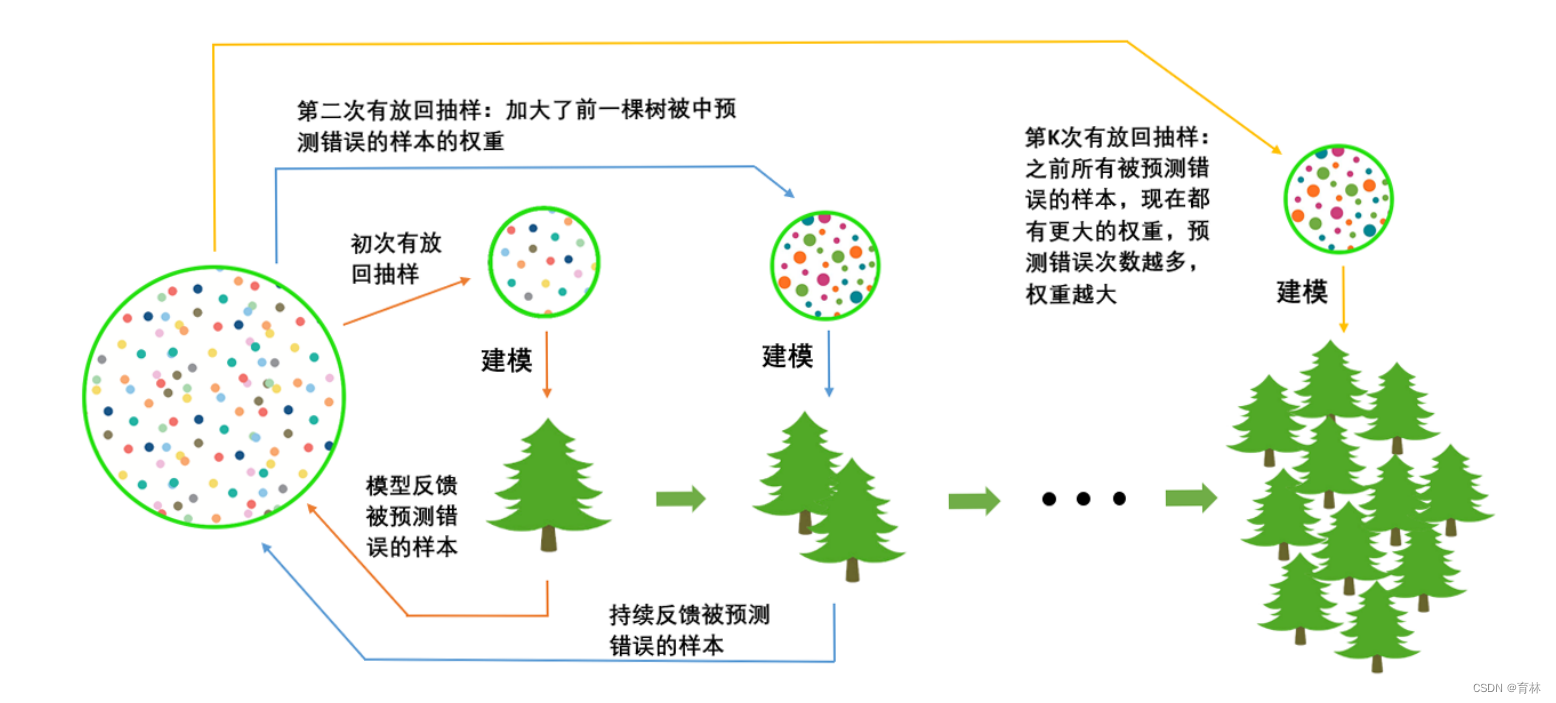
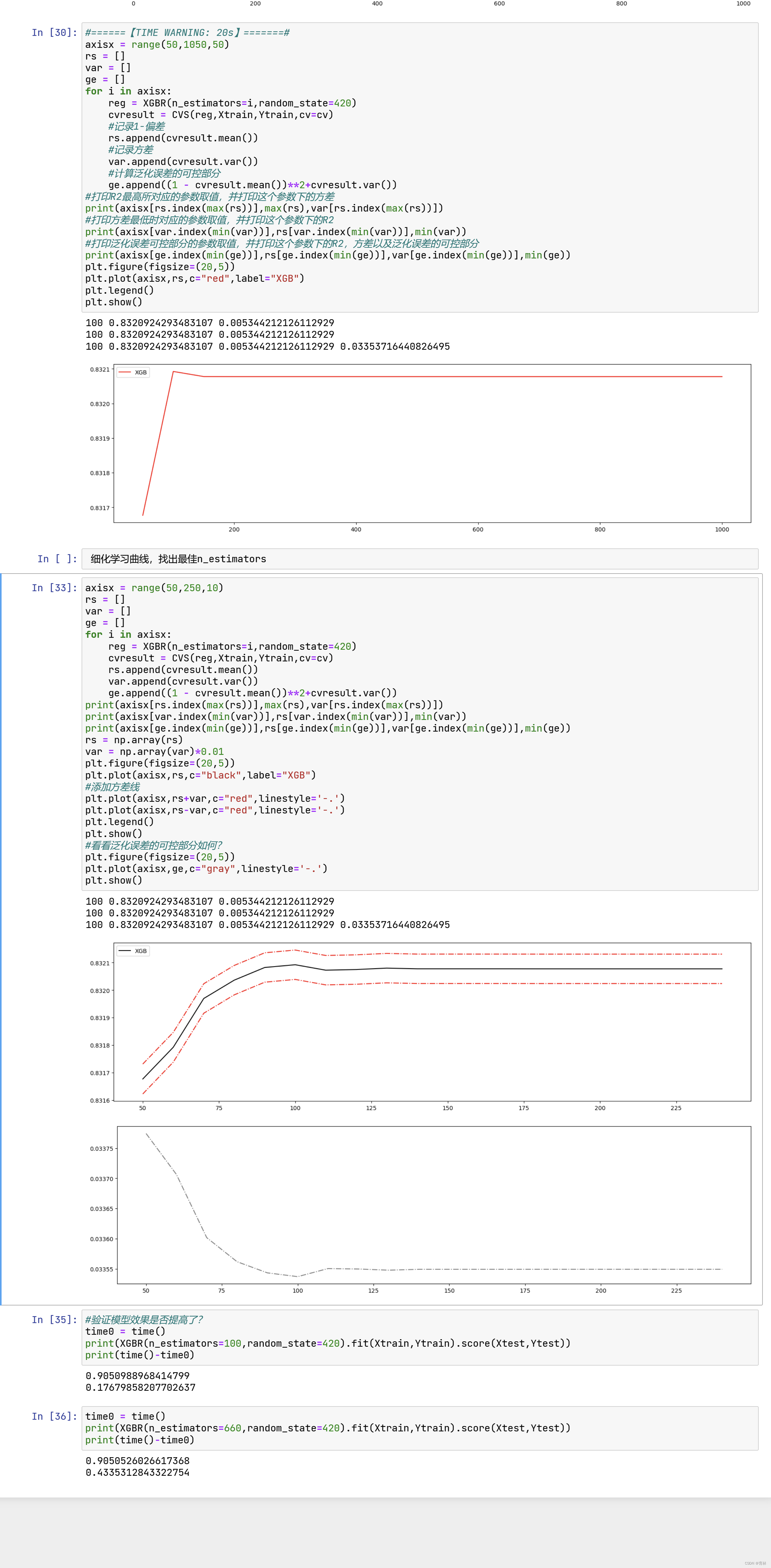
首先我们有一个巨大的数据集,在建第一棵树时,我们对数据进行初次又放回抽样,然后建模。建模完毕后,我们对
模型进行一个评估,然后将模型预测错误的样本反馈给我们的数据集,一次迭代就算完成。紧接着,我们要建立第二
棵决策树,于是开始进行第二次又放回抽样。但这次有放回抽样,和初次的随机有放回抽样就不同了,在这次的抽样
中,我们加大了被第一棵树判断错误的样本的权重。也就是说,被第一棵树判断错误的样本,更有可能被我们抽中。
基于这个有权重的训练集来建模,我们新建的决策树就会更加倾向于这些权重更大的,很容易被判错的样本。建模完
毕之后,我们又将判错的样本反馈给原始数据集。下一次迭代的时候,被判错的样本的权重会更大,新的模型会更加
倾向于很难被判断的这些样本。如此反复迭代,越后面建的树,越是之前的树们判错样本上的专家,越专注于攻克那
些之前的树们不擅长的数据。对于一个样本而言,它被预测错误的次数越多,被加大权重的次数也就越多。我们相
信,只要弱分类器足够强大,随着模型整体不断在被判错的样本上发力,这些样本会渐渐被判断正确。如此就一定程
度上实现了我们每新建一棵树模型的效果都会提升的目标。
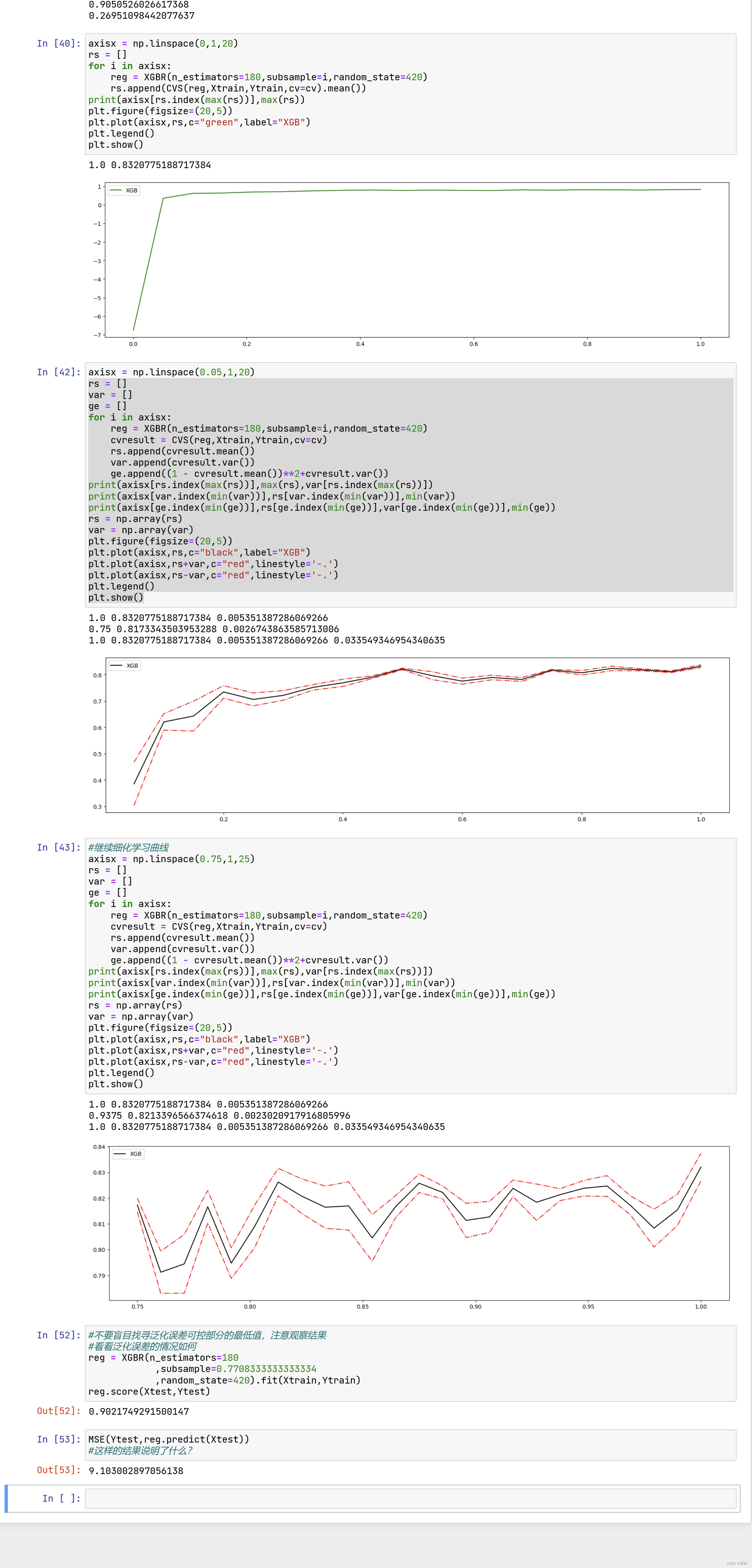
四、迭代决策树:重要参数eta
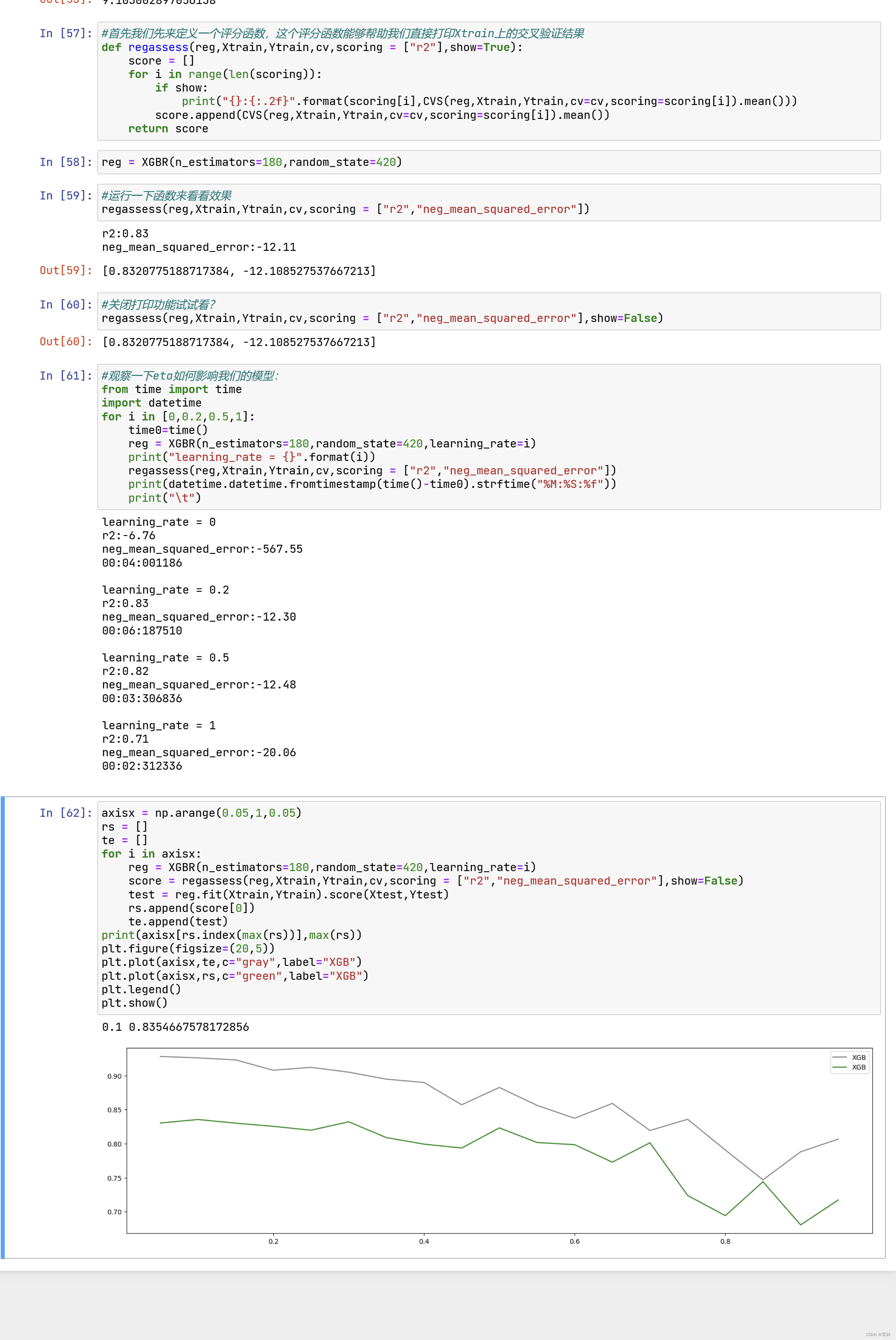
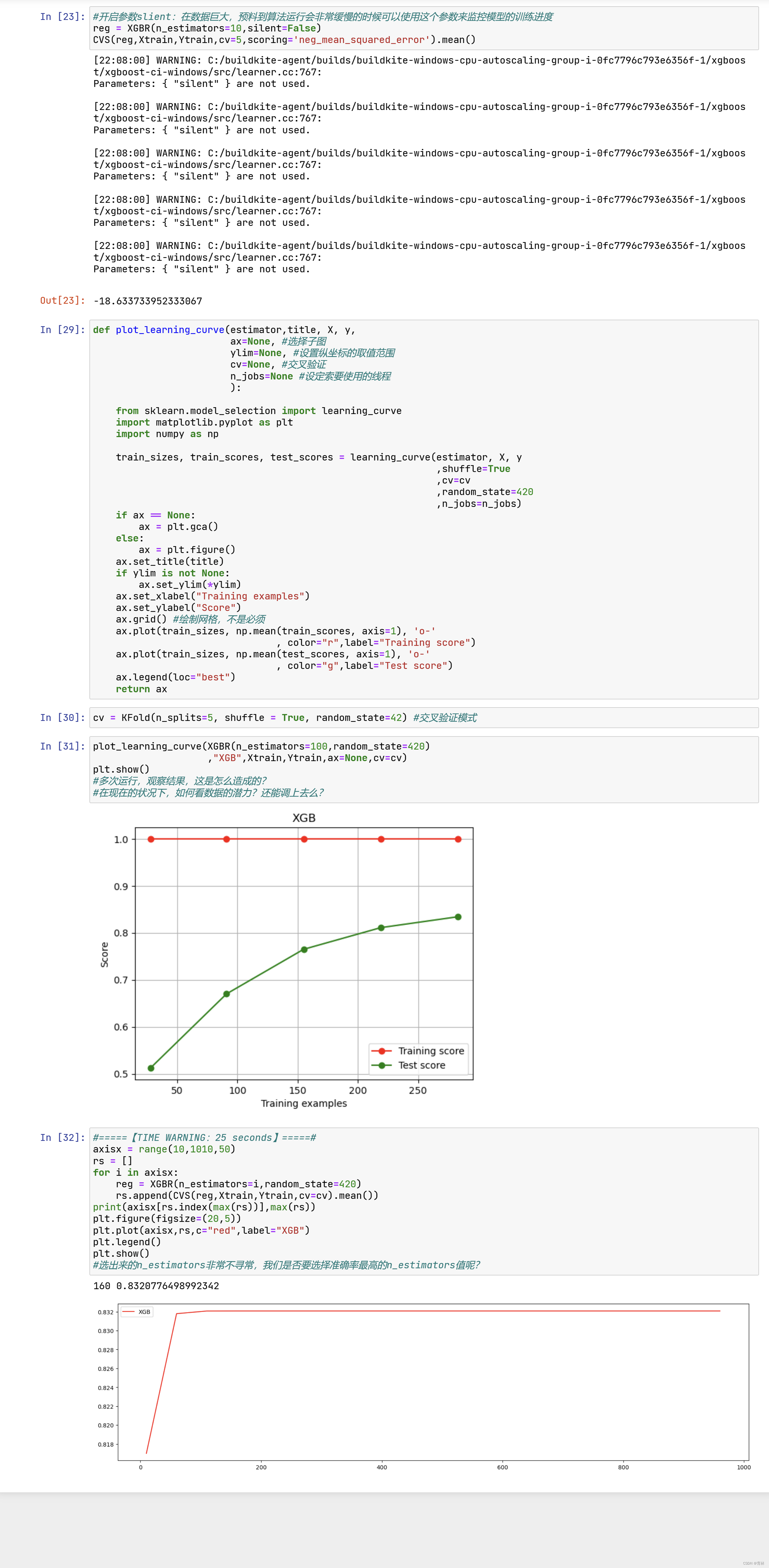
虽然从图上来说,默认的0.1看起来是一个比较理想的情况,并且看起来更小的步长更利于现在的数据,但我们也无
法确定对于其他数据会有怎么样的效果。所以通常,我们不调整 ,即便调整,一般它也会在[0.01,0.2]之间变动。如
果我们希望模型的效果更好,更多的可能是从树本身的角度来说,对树进行剪枝,而不会寄希望于调整 。
梯度提升树是XGB的基础,本节中已经介绍了XGB中与梯度提升树的过程相关的四个参数:n_estimators,
learning_rate ,silent,subsample。这四个参数的主要目的,其实并不是提升模型表现,更多是了解梯度提升树的
原理。现在来看,我们的梯度提升树可是说是由三个重要的部分组成:
- 一个能够衡量集成算法效果的,能够被最优化的损失函数Obj
- 一个能够实现预测的弱评估器fk(x)
- 一种能够让弱评估器集成的手段,包括我们讲解的迭代方法,抽样手段,样本加权等等过程
XGBoost是在梯度提升树的这三个核心要素上运行,它重新定义了损失函数和弱评估器,并且对提升算法的集成手段
进行了改进,实现了运算速度和模型效果的高度平衡。并且,XGBoost将原本的梯度提升树拓展开来,让XGBoost不
再是单纯的树的集成模型,也不只是单单的回归模型。只要我们调节参数,我们可以选择任何我们希望集成的算法,
以及任何我们希望实现的功能。












![[SSD综述 1.3] SSD及固态存储技术半个世纪发展史](https://img-blog.csdnimg.cn/img_convert/7b9e77a9b0fd4e8588ca6ceb7298ee39.png)