在图像识别领域,卷积神经网络是非常常见和有用的,我们试图将它应用到文本的情感分类上,如何处理呢?其实思路也是一样的,图片是二维的,文本是一维的,同样的,我们使用一维的卷积核去处理一维的文本(当作一维的图片)即可。这样也可以达到图片抽取特征类似的效果,也可以捕捉到临近词之间的关联。
下面是这节将需要导入的包跟模块
import d2lzh as d2l
from mxnet import gluon,init,nd
from mxnet.contrib import text
from mxnet.gluon import data as gdata,loss as gloss,nn一维卷积层
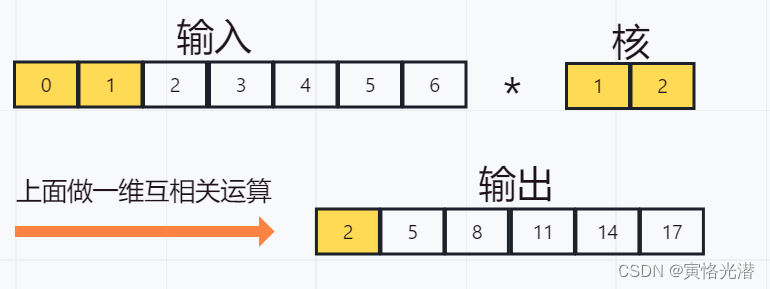
一维卷积层的原理跟前面学到的二维卷积层是一样的,一维卷积层使用一维的互相关运算,在一维互相关运算中,卷积窗口从输入数组的最左边开始,按照从左往右的顺序,依次在输入数组上滑动,当卷积窗口滑动到某一个位置时,窗口中的输入子数组就跟核数组按元素相乘并求和。
我们来直观的看图就明白了,输入是宽为7的一维数组,核数组宽为2,输出的宽度:7-2+1=6,高亮颜色的地方按照元素相乘再相加:0x1+1x2=2,如下图:
以前的图很多都是通过CorelDraw来画图,现在使用小画桌来在线画图还是挺方便快捷的,推荐大家使用。
一维互相关运算函数如下:
def corr1d(X,K):
w=K.shape[0]
Y=nd.zeros((X.shape[0]-w+1))
for i in range(Y.shape[0]):
Y[i]=(X[i:i+w]*K).sum()
return Y
X,K=nd.array([0,1,2,3,4,5,6]),nd.array([1,2])
print(corr1d(X,K))
'''
[ 2. 5. 8. 11. 14. 17.]
<NDArray 6 @cpu(0)>
'''跟图片中的结果是一样的,接下来看下多通道的输入和多个卷积核是怎么计算的,先看图:
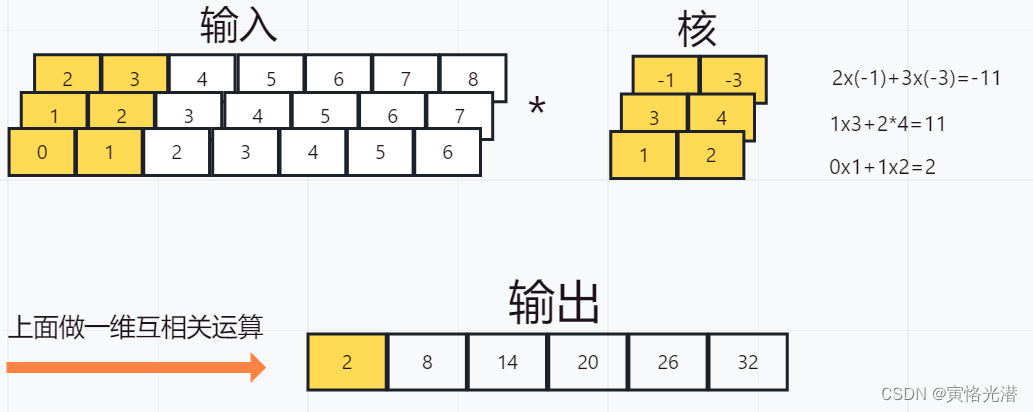
然后我们也使用一个函数来验证下多通道的结果:
def corr1d_multi_in(X,K):
return nd.add_n(*[corr1d(x,k) for x,k in zip(X,K)])
X=nd.array([[0,1,2,3,4,5,6],[1,2,3,4,5,6,7],[2,3,4,5,6,7,8]])
K=nd.array([[1,2],[3,4],[-1,-3]])
print(corr1d_multi_in(X,K))
'''
[ 2. 8. 14. 20. 26. 32.]
<NDArray 6 @cpu(0)>
'''没有问题,其中*星号是将结果列表变为add_n函数的位置参数,然后进行相加运算。上图的三通道输入的一维卷积运算,是可以看作单通道输入的二维卷积互相关运算。如下图:
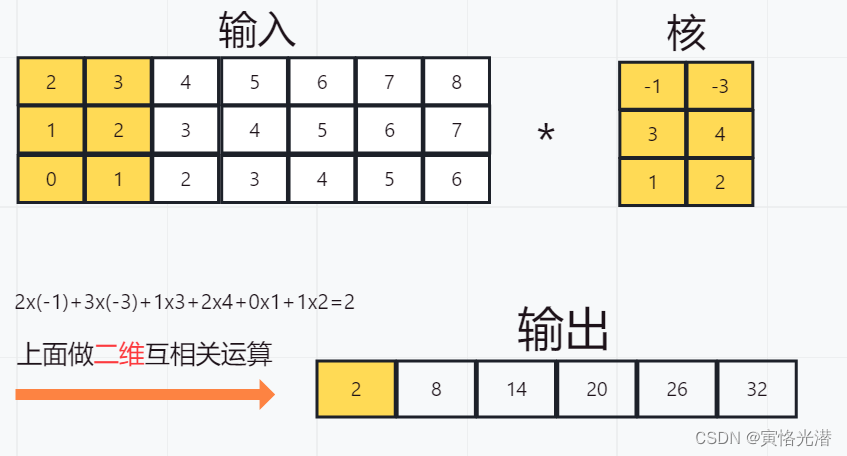
时序最大池化层
前面的文章介绍的卷积运算有接池化层,这里同样的,也有一维的池化层。textCNN中使用的时序最大池化(max-over-time pooling)层实际上对应的是一维全局最大池化层:假设输入包含多个通道,各通道由不同时间步上的数值组成,各通道的输出即该通道所有时间步中最大的数值。因此,时序最大池化层的输入在各个通道上的时间步数可以不同。
在textCNN模型中是怎么使用卷积层与时序最大池化层的,我们先画个图来直观感受下:
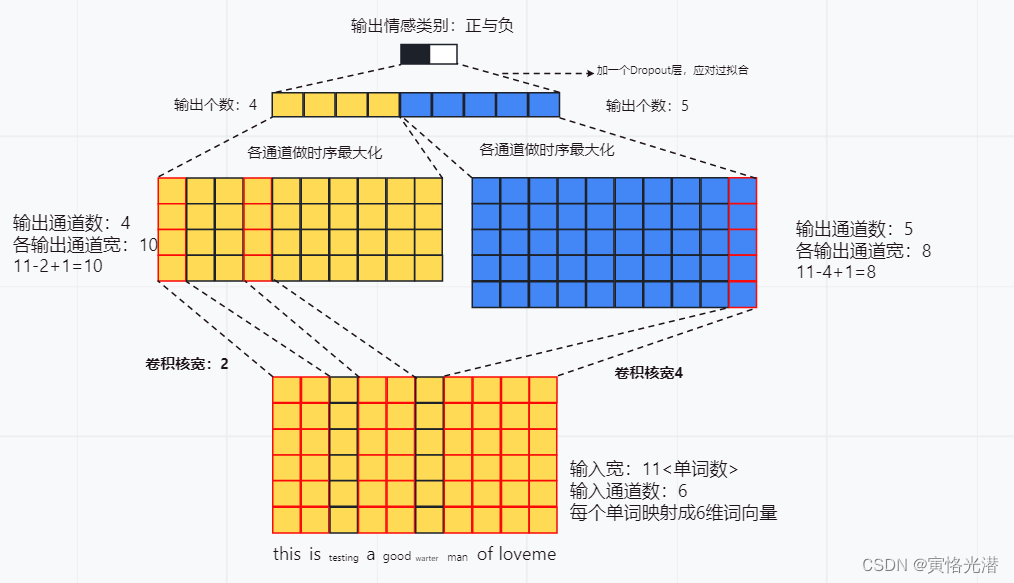
图片比较直观感受到这个模型的流程,接下来我们设计这个模型,在此之前整理数据集,还是使用前面介绍的电影评论数据集来做情感分析
batch_size=64
d2l.download_imdb()
train_data,test_data=d2l.read_imdb('train'),d2l.read_imdb('test')
vocab=d2l.get_vocab_imdb(train_data)
train_iter=gdata.DataLoader(gdata.ArrayDataset(*d2l.preprocess_imdb(train_data,vocab)),batch_size,shuffle=True)
test_iter=gdata.DataLoader(gdata.ArrayDataset(*d2l.preprocess_imdb(test_data,vocab)),batch_size)
创建textCNN模型
textCNN模型主要步骤如下:
1、定义多个一维卷积,分别对这些输入做卷积计算,宽度不同的卷积核可能会捕捉到不同个数的相邻词的相关性,从图中我们也可以看到卷积核的一个宽度是2,另一个是4
2、对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连结为向量
3、通过全连接层将连接后的向量变换为有关各类别的输出,这里可以加一个Dropout丢弃层来应对过拟合
实现模型的代码,这里使用两个嵌入层,一个的权重固定,另一个的权重参与训练
class TextCNN(nn.Block):
def __init__(self,vocab,embed_size,kernel_sizes,num_channels,**kwargs):
super(TextCNN,self).__init__(**kwargs)
self.embedding=nn.Embedding(len(vocab),embed_size)
# 不参与训练的嵌入层
self.constant_embedding=nn.Embedding(len(vocab),embed_size)
self.dropout=nn.Dropout(0.5)
self.decoder=nn.Dense(2)
# 时序最大池化层没有权重,所以可以共用一个实例
self.pool=nn.GlobalMaxPool1D()
self.convs=nn.Sequential()
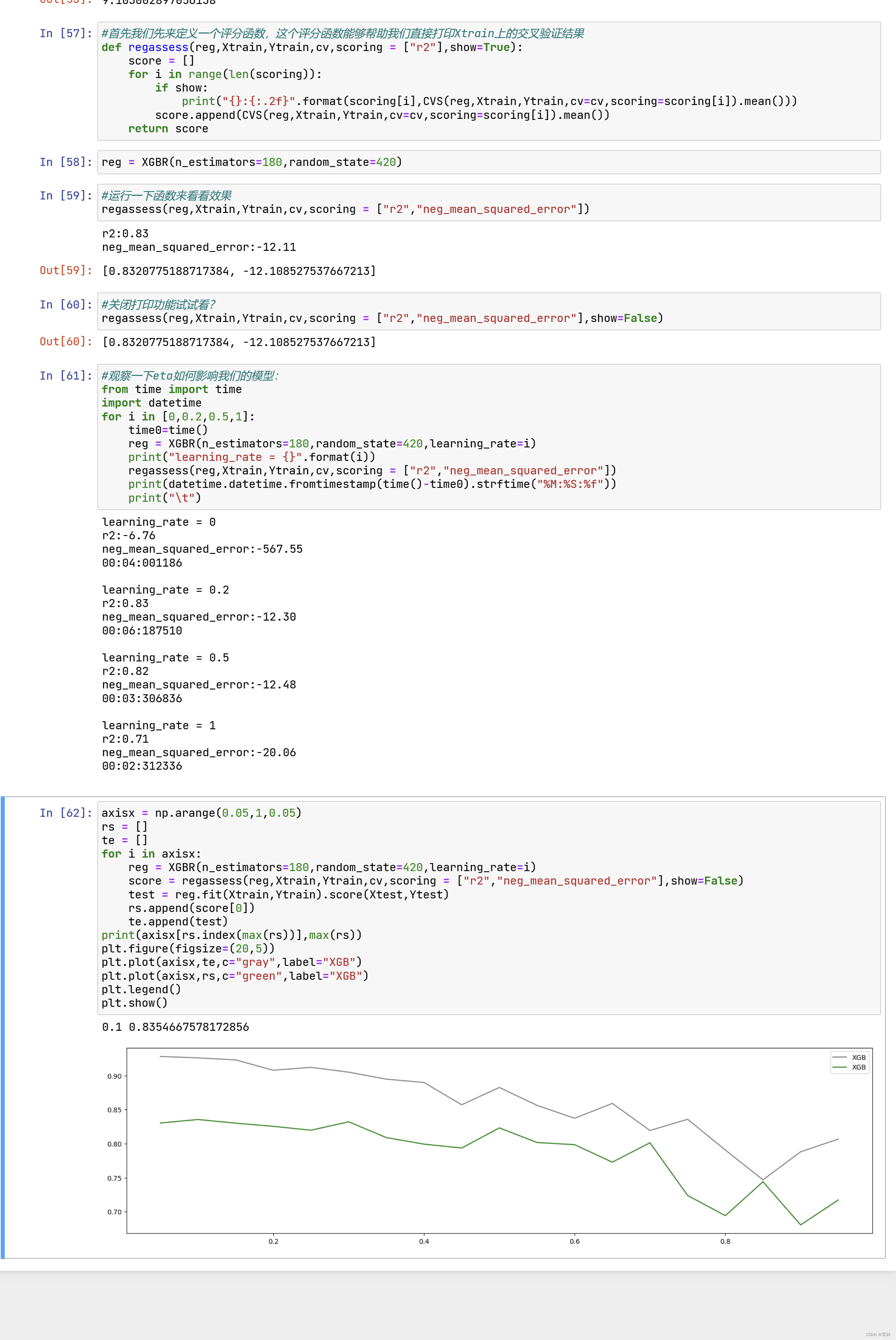
# 添加多个一维的卷积层
for c,k in zip(num_channels,kernel_sizes):
# NCW
self.convs.add(nn.Conv1D(c,k,activation='relu'))
def forward(self,inputs):
# NWC(批量大小,词数,词向量维度[通道])的两个嵌入层的输出按照词向量维度dim=2连结
embeddings=nd.concat(self.embedding(inputs),self.constant_embedding(inputs),dim=2)
# 一维卷积的输入格式是NCW,所以进行形状变换
embeddings=embeddings.transpose((0,2,1))
# 对于每个一维卷积层,在时序最大池化后会得到一个形状为(批量大小,通道大小,1)的NDArray
# 使用flatten函数去掉最后一维,然后在通道维上连结
encoding=nd.concat(*[nd.flatten(self.pool(conv(embeddings))) for conv in self.convs],dim=1)
# 应用丢弃法后使用全连接层得到输出
outputs=self.decoder(self.dropout(encoding))
return outputs
#创建textCNN实例,3个卷积层,其核宽分别是3,4,5,输出通道数均为100
embed_size,kernel_size,num_channels=100,[3,4,5],[100,100,100]
ctx=d2l.try_all_gpus()
net=TextCNN(vocab,embed_size,kernel_size,num_channels)
net.initialize(init.Xavier(),ctx=ctx)训练模型
模型的创建,这里使用100维的GloVe词向量,对于GloVe的了解可以参阅:自然语言处理(NLP)之求近义词和类比词<MXNet中GloVe和FastText的模型使用>
glove_embedding=text.embedding.create('glove',pretrained_file_name='glove.6B.100d.txt',vocabulary=vocab)
# 这个嵌入层的权重参数训练
net.embedding.weight.set_data(glove_embedding.idx_to_vec)
# 固定权重
net.constant_embedding.weight.set_data(glove_embedding.idx_to_vec)
net.constant_embedding.collect_params().setattr('grad_req','null')预训练词向量搞定之后就开始训练模型
lr,num_epochs=0.001,5
trainer=gluon.Trainer(net.collect_params(),'adam',{'learning_rate':lr})
loss=gloss.SoftmaxCrossEntropyLoss()
d2l.train(train_iter,test_iter,net,loss,trainer,ctx,num_epochs)
# 预测
print(d2l.predict_sentiment(net,vocab,['this','movie','is','very','nice']))
print(d2l.predict_sentiment(net,vocab,['this','movie','is','so','bad']))
print(d2l.predict_sentiment(net,vocab,['this','movie','is','not','bad']))
print(d2l.predict_sentiment(net,vocab,['this','movie','is','too','bad']))
'''
epoch 1, loss 0.6138, train acc 0.714, test acc 0.832, time 44.2 sec
epoch 2, loss 0.3582, train acc 0.844, test acc 0.852, time 43.5 sec
epoch 3, loss 0.2646, train acc 0.892, test acc 0.864, time 43.5 sec
epoch 4, loss 0.1711, train acc 0.937, test acc 0.868, time 43.3 sec
epoch 5, loss 0.1081, train acc 0.962, test acc 0.858, time 43.4 sec
positive
negative
negative
negative
'''可以看到训练的准确度还是很不错的,测试的准确度也可以,有待提高,第三条影评识别错误,其余都预测对了。
对于准确度的提高,有两个方向可以去做,还记得吗,就是 MXNet中使用双向循环神经网络BiRNN对文本进行情感分类<改进版>
这篇文章中的两种方法,使用SpaCy分词工具和扩大词向量的维度,有兴趣的伙伴们可以去试试。