一:spring data jpa介绍
spring data:其实spring data就是spring提供了一个操作数据的框架。而spirng data jpa只是spring data框架下的一个基于jpa标准操作数据的模块。
spring data jpa:基于jpa的标准对数据进行操作。简化操作持久层的代码。只需要编写接口就可以。
二:springboot整合spring data jpa
1.搭建整合环境:maven工程继承springboot父工程
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
2.修改pom文件添加坐标
<!-- spring data jpa的springboot启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.30</version>
</dependency>
<!-- 连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
3.在项目中添加application.yml文件
spring:
# 配置数据源
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8
username: root
password: root
# 配置连接池
type: com.alibaba.druid.pool.DruidDataSource
# 配置jpa
jpa:
# 配置正向工程
hibernate:
ddl-auto: update
# 配置在控制台打印sql语句
show-sql: true
4.添加实体类
@Entity //表示该类是实体类
@Table(name="tb_users") //表示正向工程生成的表名为tb_users
public class User {
@Id //表示该字段为主键
@GeneratedValue(strategy=GenerationType.IDENTITY) //表示该键生成策略为自增
@Column(name="id") //生成的表中对应的字段为id
private Integer id;
@Column(name="username")
private String name;
@Column(name="age")
private Integer age;
@Column(name="address")
private String address;
...}
5.编写dao接口
public interface UserRepository extends JpaRepository<User, Integer> {
}
6.在pom文件中添加测试启动器的坐标
<!-- test工具的启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
7.创建启动类
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
8.编写测试代码
//JpaRepository--添加数据
@Test
public void testSave() {
User user = new User();
user.setName("成龙");
user.setAge(42);
user.setAddress("中国深圳");
this.userRepository.save(user);
}
三:spring data jpa提供的核心接口
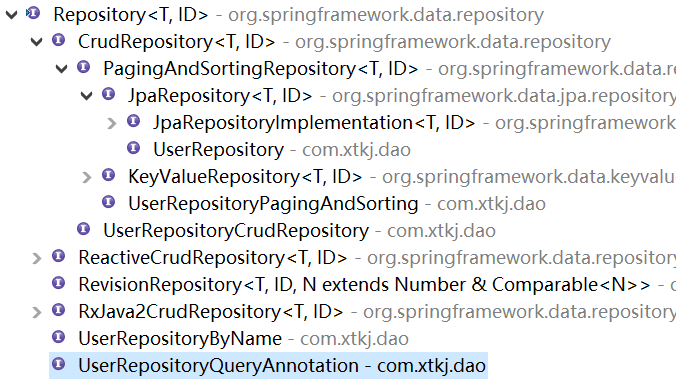
1.Repository接口
2.CrudRepository接口
3.PagingAndSortingRepository接口
4.JpaRepository接口
5.JpaSpecificationExecutor接口
四:Repository接口的使用
1.提供了方法名称命名查询方式
1.1编写接口
public interface UserRepositoryByName extends Repository<User, Integer> {
//方法名称必须遵循驼峰式命名规则。
//findBy(关键字)+实体属性名(首字母大写)+查询条件(首字母大写)
public List<User> findByName(String name);
public List<User> findByNameAndAge(String name,Integer age);
public List<User> findByNameLike(String name);
}
1.2测试代码
//Repository--方法名称命名测试
@Test //单条件查询
public void testFindByName() {
List<User> userList = this.userRepositoryByName.findByName("zlg");
for (User user : userList) {
System.out.println(user);
}
}
@Test //多条件查询
public void testFindByNameAndAge() {
List<User> userList = this.userRepositoryByName.findByNameAndAge("zlg", 23);
for (User user : userList) {
System.out.println(user);
}
}
@Test //模糊查询
public void testFindByNameLike() {
List<User> userList = this.userRepositoryByName.findByNameLike("z%");
for (User user : userList) {
System.out.println(user);
}
}
2.提供了基于@Query注解的查询与更新
2.1编写接口
//Repository接口的@query注解查询
public interface UserRepositoryQueryAnnotation extends Repository<User, Integer> {
//采用hibernate的hql语句查询(User类名,name实体属性,:name别名 对应@Param中的key)
@Query("from User where name = :name")
public List<User> findByNameUserHQL(@Param("name")String name);
//采用slq语句
@Query(value="select * from tb_users where username = ?",nativeQuery=true)
public List<User> findByNameUserSQL(String name);
//更新操作
@Query("update User set name = :name where id = :id")
@Modifying //需要执行一个更新操作
public void updateUserNameById(@Param("name")String name,@Param("id")Integer id);
}
2.2测试代码
//Repository--@Query注解测试
@Test //hql语句查询
public void testFindByNameUserHQL() {
List<User> userList = this.userRepositoryQueryAnnotation.findByNameUserHQL("zlg");
for (User user : userList) {
System.out.println(user);
}
}
@Test //sql语句查询
public void testFindByNameUserSQL() {
List<User> userList = this.userRepositoryQueryAnnotation.findByNameUserSQL("成龙");
for (User user : userList) {
System.out.println(user);
}
}
@Test //修改数据
@Transactional //@Test与@Transactional一起使用时,事务是自动回滚的
@Rollback(false) //取消自动回滚
public void testUpdateUserNameById() {
this.userRepositoryQueryAnnotation.updateUserNameById("葛优", 1);;
}
五:CrudRepository接口
1.CrudRepository接口,主要是完成一些增删改查操作。CrudRepository接口继承Repository接口。

2.编写接口
//CrudRepository接口
public interface UserRepositoryCrudRepository extends CrudRepository<User, Integer> {
}
3.测试代码
//CrudRepository--测试
@Test //添加数据
public void testCrudRepositorySave() {
User user = new User();
user.setAddress("中国杭州");
user.setAge(16);
user.setName("姜文");
this.userRepositoryCrudRepository.save(user);
}
@Test //修改数据
public void testCrudRepositoryUpdate() {
User user = new User();
user.setId(4);
user.setAddress("中国广州");
user.setAge(28);
user.setName("姜文");
this.userRepositoryCrudRepository.save(user);
}
@Test //根据id查询
public void testCrudRepositoryFindById() {
Optional<User> user = this.userRepositoryCrudRepository.findById(4);
System.out.println(user);
}
@Test //查询所有
public void testCrudRepositoryFindAll() {
List<User> userList = (List<User>)this.userRepositoryCrudRepository.findAll();
for (User user : userList) {
System.out.println(user);
}
}
@Test //根据id删除数据
public void testCrudRepositoryDeleteById() {
this.userRepositoryCrudRepository.deleteById(4);
}
六:PagingAndSortingRepository接口
1.该接口提供了分页与排序的操作。该接口集成了CrudRepository接口。

2.编写接口
//PagingAndSortingRepository接口
public interface UserRepositoryPagingAndSorting extends PagingAndSortingRepository<User, Integer> {
}
3.测试代码
//PagingAndSortingRepository--测试
@Test //排序测试
public void testPagingAndSortingRepositorySort() {
//Sort对象封装了排序规则
Sort sort = new Sort(Direction.DESC, "id");
List<User> userList = (List<User>)this.userRepositoryPagingAndSorting.findAll(sort);
for (User user : userList) {
System.out.println(user);
}
}
@Test //分页测试
public void testPagingAndSortingRepositoryPaging() {
//Pageable封装了分页的参数,当前页,每页显示的条数。当前页是从零开始。
//PageRequest.of(page,size): page当前页,size每页显示的条数
Pageable pageable = PageRequest.of(0, 2);
Page<User> page = this.userRepositoryPagingAndSorting.findAll(pageable);
System.out.println("总条数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
for (User user : page.getContent()) {
System.out.println(user);
}
}
@Test //排序+分页排序
public void testPagingAndSortingRepositorySortAndPaging() {
//PageRequest.of(int page, int size, Direction direction, String... properties)
//page:当前页,size:每页条数,direction:排序方向,properties:以哪个实体属性进行排序
Pageable pageable = PageRequest.of(0, 2, Direction.DESC, "id");
Page<User> page = this.userRepositoryPagingAndSorting.findAll(pageable);
System.out.println("总条数:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
for (User user : page.getContent()) {
System.out.println(user);
}
}
七:JpaRepository接口
1.该接口继承了PagingAndSortingRepository接口。对继承的父接口中的方法的返回值进行适配。

2.编写接口
//参数一T:当前需要映射的实体
//参数二ID:当前映射的实体中的OID(主键)的类型
public interface UserRepository extends JpaRepository<User, Integer> {
}
3.测试代码
八:JpaSpecificationExecutor接口
1.该接口主要是提供了多条件查询的支持,并且可以在查询中添加分页与排序。JpaSpecificationExecutor是单独存在。完全独立。

2.编写接口
//JpaSpecificationExecutor接口
public interface UserRepositorySpecification extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User> {
}
3.测试代码
//6.JpaSpecificationExecutor--测试
@Test //单条件测试
public void testJpaSpecificationExecutor1() {
//Specification:用于封装查询条件, 接口的对象用匿名内部类。
Specification<User> spec = new Specification<User>() {
//Predicate:封装了单个的查询条件
//Root<User> root:查询对象的属性的封装
//CriteriaQuery<?> query:封装了我们要执行查询中的各个部分信息,select from order by
//CriteriaBuilder criteriaBuilder:查询条件的构造器,定义不同的查询条件
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) {
//where name = "周星驰"
//equal(arg0,arg1): arg0:查询的条件属性 arg1:条件的值
Predicate pre = criteriaBuilder.equal(root.get("name"), "周星驰");
return pre;
}
};
List<User> userList = this.userRepositorySpecification.findAll(spec);
for (User user : userList) {
System.out.println(userList);
}
}
@Test //多条件测试
public void testJpaSpecificationExecutor2() {
Specification<User> spec = new Specification<User>() {
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) {
//一个Predicate封装一个查询条件,两个条件用数组或集合
Predicate[] pre = new Predicate[] {
criteriaBuilder.equal(root.get("name"), "周星驰"),
criteriaBuilder.equal(root.get("age"), 36)
};
//and(pre):pre是可变数组,通过and方法将多个条件连接起来
return criteriaBuilder.and(pre);
}
};
List<User> userList = this.userRepositorySpecification.findAll(spec);
for (User user : userList) {
System.out.println(user);
}
}
4.多条件查询的第二种写法
@Test //多条件测试第二种写法
public void testJpaSpecificationExecutor3() {
Specification<User> spec = new Specification<User>() {
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) {
//一个Predicate封装一个查询条件,两个条件用数组或集合
//and(pre):pre是可变数组,通过and方法将多个条件连接起来
//return criteriaBuilder.and(criteriaBuilder.equal(root.get("name"), "周星驰"),criteriaBuilder.equal(root.get("age"), 36));
//where (name = "周星驰" and age = 36) or id = 1 --and的优先级比or高,不用括号也可以
return criteriaBuilder.or(criteriaBuilder.and(criteriaBuilder.equal(root.get("name"), "周星驰"),criteriaBuilder.equal(root.get("age"), 36)),criteriaBuilder.equal(root.get("id"), "1"));
}
};
//sort封装排序规则
Sort sort = new Sort(Direction.DESC, "id");
List<User> userList = this.userRepositorySpecification.findAll(spec,sort);
for (User user : userList) {
System.out.println(user);
}
}
九:关联映射操作
1.一对多的关联关系
需求:角色与用户的一对多的关联关系
角色:一方(Role) 用户:多方(User)
1.1 User实体类
//多对一关系
@ManyToOne(cascade=CascadeType.PERSIST) //级联添加(添加用户的同时添加相应的角色)
@JoinColumn(name="role_id") //维护外键
private Role role; //tostring()方法中不能打印输出role对象,编译会报错
1.2 Role实体类
//一对多关系
@OneToMany(mappedBy="role") //添加user中外键对象属性
private Set<User> users = new HashSet<>();
1.3测试多对一的关联关系
//多对一关系测试
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes=Application.class)
public class OneToManyTest {
@Autowired
private UserRepository userRepository;
//多对一关系的添加
@Test
public void testSave() {
//创建一个用户
User user = new User();
user.setAddress("中国杭州");
user.setAge(32);
user.setName("姜文");
//创建一个角色
Role role = new Role();
role.setRolename("管理员");
//关联
role.getUsers().add(user); //主表(先添加主表数据)
user.setRole(role); //从表(再添加从表数据)
//保存
this.userRepository.save(user);
}
//多对一关系的查询
@Test
public void testFind() {
Optional<User> user = this.userRepository.findById(5); //根据id查询User
System.out.println(user.get()); //打印输出User对象
String rolename = user.get().getRole().getRolename(); //获取rolename
System.out.println(rolename);
}
}
2.多对多的关联关系
需求:角色与菜单多对多关联关系
角色:多方 菜单:多方
2.1 Role实体类
//@JoinTable:映射中间表
//中间表中属性joinColumns:当前表主键所关联的中间表中的外键字段
//CascadeType.PERSIST添加数据时级联新建,FetchType.EAGER表示关系类在主体类加载的时候同时加载,立即加载
@ManyToMany(cascade=CascadeType.PERSIST,fetch=FetchType.EAGER)
@JoinTable(name="t_role_menu",joinColumns=@JoinColumn(name="role_id"),inverseJoinColumns=@JoinColumn(name="menu_id"))
private Set<Menu> menus = new HashSet<>();
2.2 Menu实体类
@ManyToMany(mappedBy="menus") //mappedBy:建立类之间的双向关联,保证数据一致性
private Set<Role> roles = new HashSet<>();
2.3测试多对多的关联关系
//RoleRepository接口
public interface RoleRepository extends JpaRepository<Role, Integer>{
}
//多对多关联关系的测试
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes=Application.class)
public class ManyToManyTest {
@Autowired
private RoleRepository roleRepository;
//多对多关系的添加操作
@Test
public void testSave() {
//创建角色对象
Role role = new Role();
role.setRolename("项目经理");
//创建菜单对象
Menu menu = new Menu();
menu.setFatherid(0);
menu.setMenuname("xxx管理系统");
Menu menu2 = new Menu();
menu2.setFatherid(1);
menu2.setMenuname("项目管理");
//关联
role.getMenus().add(menu);
role.getMenus().add(menu2);
menu.getRoles().add(role);
menu2.getRoles().add(role);
//保存
this.roleRepository.save(role);
}
//多对多关系的查询操作
@Test
public void testFind() {
Optional<Role> role = this.roleRepository.findById(2);
System.out.println(role.get());
}
}
十:扩展知识
Java Persistence API定义了一种定义,可以将常规的普通Java对象(有时被称作POJO)映射到数据库。这些普通Java对象被称作Entity Bean。除了是用Java Persistence元数据将其映射到数据库外,Entity Bean与其他Java类没有任何区别。事实上,创建一个Entity Bean对象相当于新建一条记录,删除一个Entity Bean会同时从数据库中删除对应记录,修改一个Entity Bean时,容器会自动将Entity Bean的状态和数据库同步。
@Entity注释指名这是一个实体Bean,@Table注释指定了Entity所要映射带数据库表,其中@Table.name()用来指定映射表的表名。如果缺省@Table注释,系统默认采用类名作为映射表的表名。实体Bean的每个实例代表数据表中的一行数据,行中的一列对应实例中的一个属性。
@Column注释定义了将成员属性映射到关系表中的哪一列和该列的结构信息,属性如下:
1)name:映射的列名。如:映射tbl_user表的name列,可以在name属性的上面或getName方法上面加入;
2)unique:是否唯一;
3)nullable:是否允许为空;
4)length:对于字符型列,length属性指定列的最大字符长度;
5)insertable:是否允许插入;
6)updatetable:是否允许更新;
7)columnDefinition:定义建表时创建此列的DDL;
8)secondaryTable:从表名。如果此列不建在主表上(默认是主表),该属性定义该列所在从表的名字。
@Id注释指定表的主键,它可以有多种生成方式:
1)TABLE:容器指定用底层的数据表确保唯一;
2)SEQUENCE:使用数据库德SEQUENCE列莱保证唯一(Oracle数据库通过序列来生成唯一ID);
3)IDENTITY:使用数据库的IDENTITY列莱保证唯一;
4)AUTO:由容器挑选一个合适的方式来保证唯一;
5)NONE:容器不负责主键的生成,由程序来完成。
@GeneratedValue注释定义了标识字段生成方式。
@Temporal注释用来指定java.util.Date或java.util.Calender属性与数据库类型date、time或timestamp中的那一种类型进行映射。
@OneToOne注释指明User与Card为一对一关系,@OneToOne注释有5个属性:targetEntity、cascade、fetch、optional和mappedBy。
1)targetEntity:Class类型的属性
2)mappedBy:String类型的属性。定义类之间的双向关联。如果类之间是单向关系,不需要提供定义,如果类和类之间形成双向关系。就需要使用这个属性进行定义,否则可能引起数据一致性的问题。
3)cascade:CascadeType类型。该属性定义类和类之间的级联关系。定义级联关系将被容器视为当前类对象及其关联类对象采取相同的操作,而且这种关系是递归的。cascade的值只能从CascadeType.PERSIST(级联新建)、CascadeType.REMOVE(级联删除)、CascadeType.REFRESH(级联刷新)、Cascade.MERGE(级联更新)中选择一个或多个。还有一个选择是使用CascadeType.ALL,表示选择全部四项。
4)fetch:FetchType类型的属性。可选择项包括:FetchType.EAGER和FetchType.LAZY。前者表示关系类在主体类加载的时候同时加载,后者表示关系类在被访问时才加载。默认值是FetchType.LAZY。
5)optional:表示被维护对象是否需要存在。如果为真,说明card属性可以null,也就是允许没有身份证,未成年人就是没有身份证。
实例:
//一对一
//Class Card
@OneToOne(optional=false,cascade=CascadeType.REFRESH)
@JoinColumn(referencedColumnName="id")
private User user;
//一对多
//Class Order
@OneToMany(targetEntity=OrderItem.class,cascade=CascadeType.ALL,mappedBy="order")
private Set set=new HashSet();
//class OrderItem
@ManyToOne(cascade=CascadeType.REFRESH,optional=false)
@JoinColumn(name="item_order_id",referencedColumnName="order_id")
private Order order;
//多对多
//Class Student
@ManyToMany(cascade=CascadeType.ALL,targetEntity=Teacher.class)
@JoinTable(name="tbl_stu_teacher",inverseJoinColumns={@JoinColumn(name="teacher_id",referencedColumnName="teacher_id")},joinColumns={@JoinColumn(name="student_id",referencedColumnName="student_id")})
private Set set=new HashSet();
//Class Teacher
@ManyToMany(targetEntity=Student.class,mappedBy="set")
private Set set=new HashSet();