文章目录
- 前言
- 使用
- 总结
前言
我们在日常开发中,当我们遇到大数据量处理的时候,总是苦恼有时候到底慢在哪?
在coding的时候就要注意以下几点:
- 循环内打印日志
- 循环内查询sql
- 循环内多次发送http请求
- 查询的时候尽量指定查询字段,不要*或者全部字段查询
- 不要在循环内频繁new 新对象,最好改为指向新的引用地址来优化。例子如下
// 错误的方法
for(int i = 0; i < 100000; i++){
A a = new A;
}
// 正确的方法
A a = null;
for(int i = 0; i < 100000; i++){
a = new A;
}
// 这样的好处就是避免创建太多造成GC
在大体遵循以上的规则之后还是慢的时候,我们就可以使用Arthas来进行判断到底哪里慢,(避免我们到处打日志来判断,这样效率太低了)
使用
这里的时候主要是面向本地开发使用。当然我们也可以使用在我们的服务器取监控。
-
安装
https://blog.csdn.net/Cloud826/article/details/98969109,略:down下来一解压就行 -
使用
-
在arthas目录cmd进入

-
使用as.bat (win基本都是这个.bat启动,Linux使用.sh启动)启用监听对应的pid
-
pid 使用java的jvisualvm判断,cmd jvisualvm打开
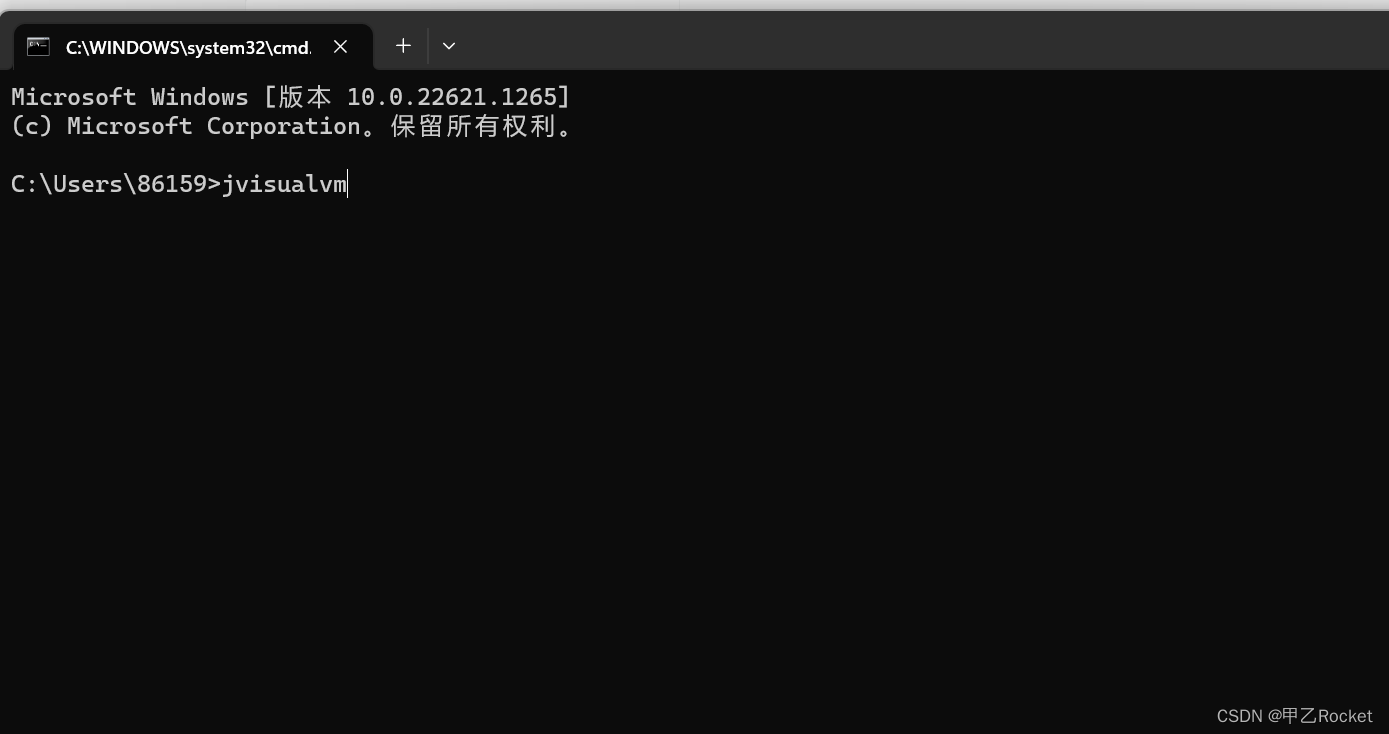
4. 输入pid 在as.bat后面
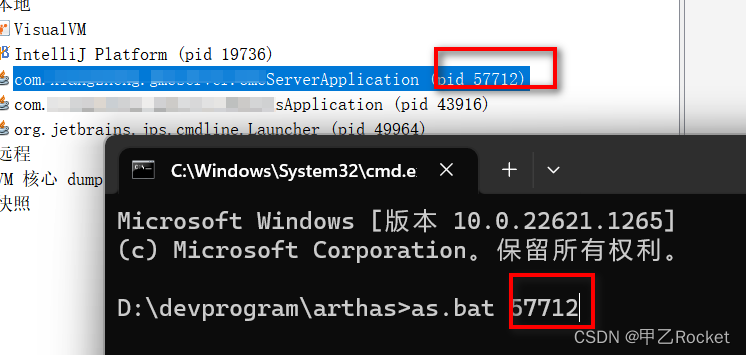
5. 进入界面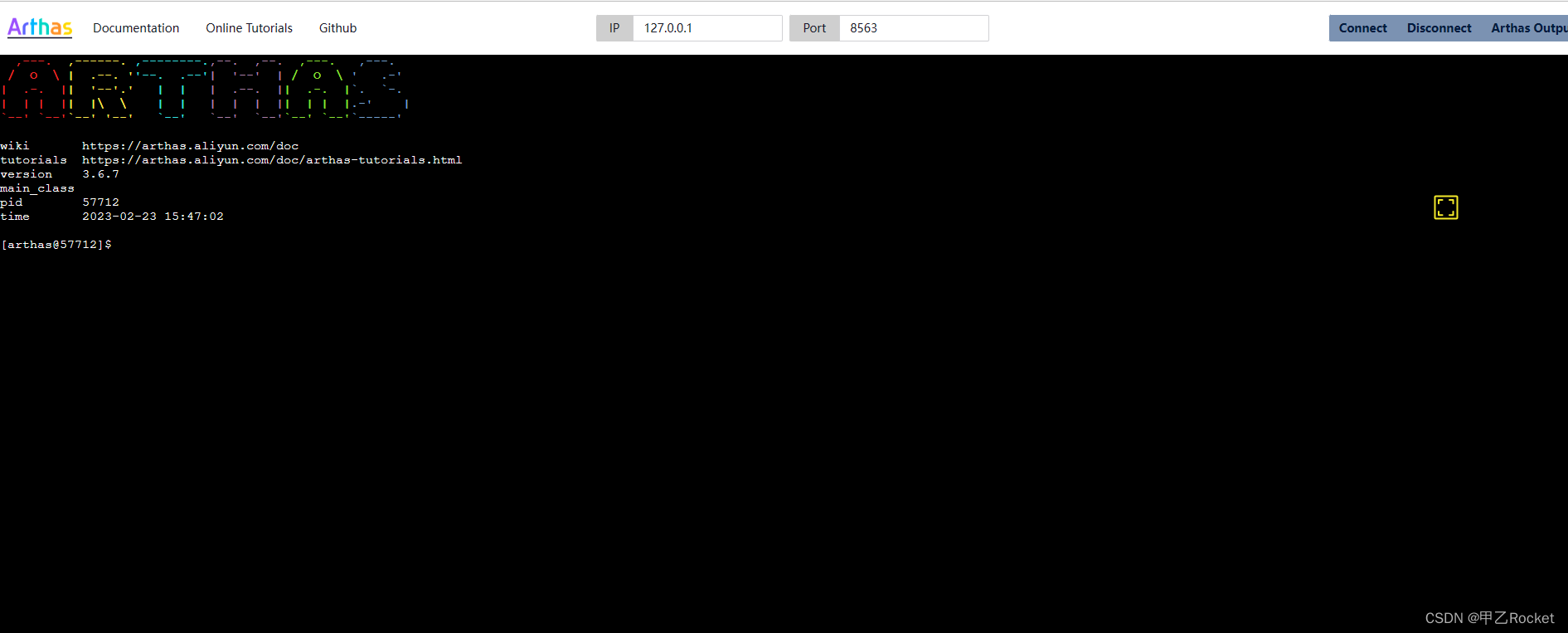
-
判断耗时(为例)
官方文档,还有其他的命令供参考:
https://arthas.aliyun.com/doc/trace.html#%E6%8D%AE%E8%B0%83%E7%94%A8%E8%80%97%E6%97%B6%E8%BF%87%E6%BB%A4

-
查看耗时判断优化的方法
优化的方法同上
再加点:能不能进行中间变量的缓存
总结
arthas的功能不止判断耗时这么简单,还要分析堆栈的功能。
本文仅已优化代码耗时,避免我们使用log一点一点判断