关于http协议的基础知识就不介绍了。主要介绍它的报文格式。
如何显示http的报文;
浏览器登录服务端的IP和端口:
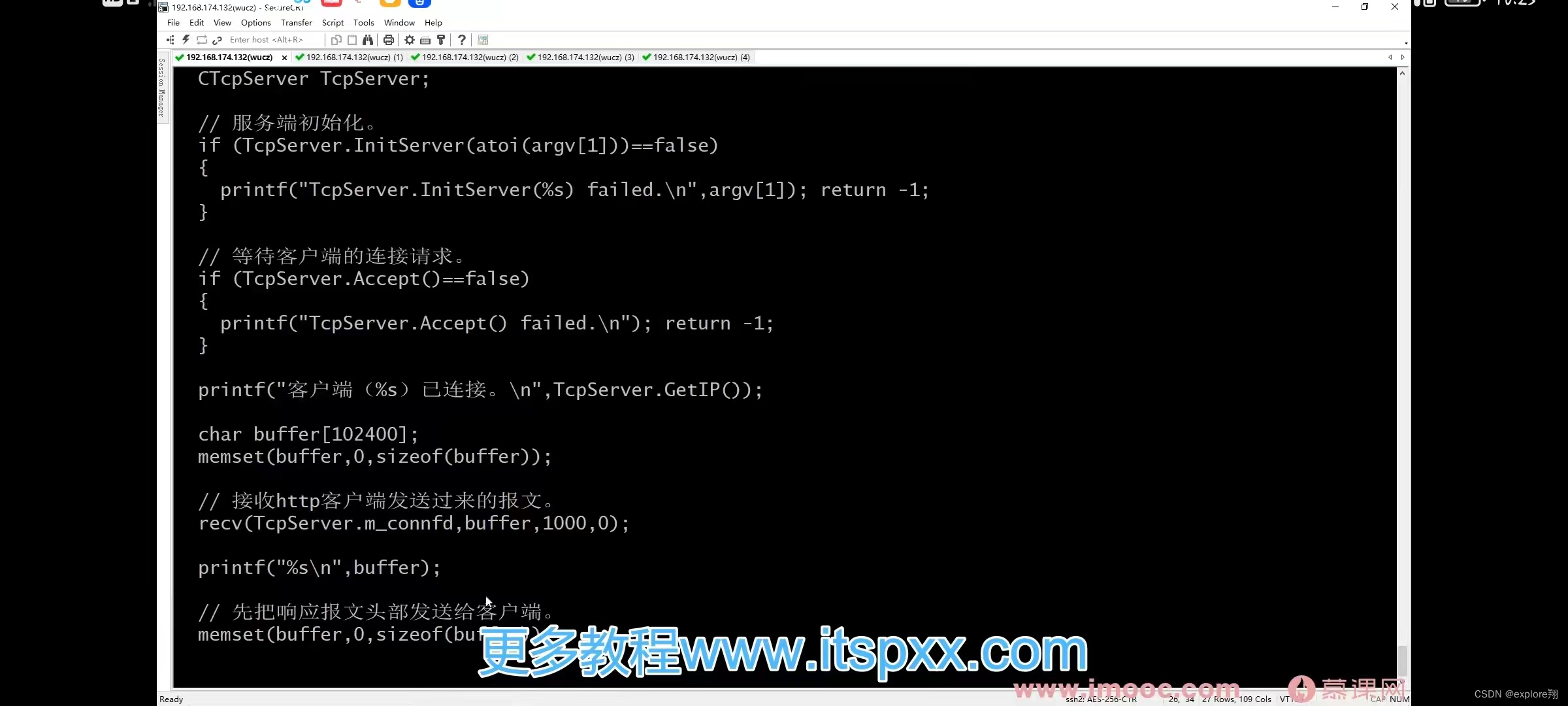
服务端接收http客户端发过来的报文:recv(connfd,buffer,1000,0),打印出来。
请求报文格式是请求行,请求头部,请求内容。

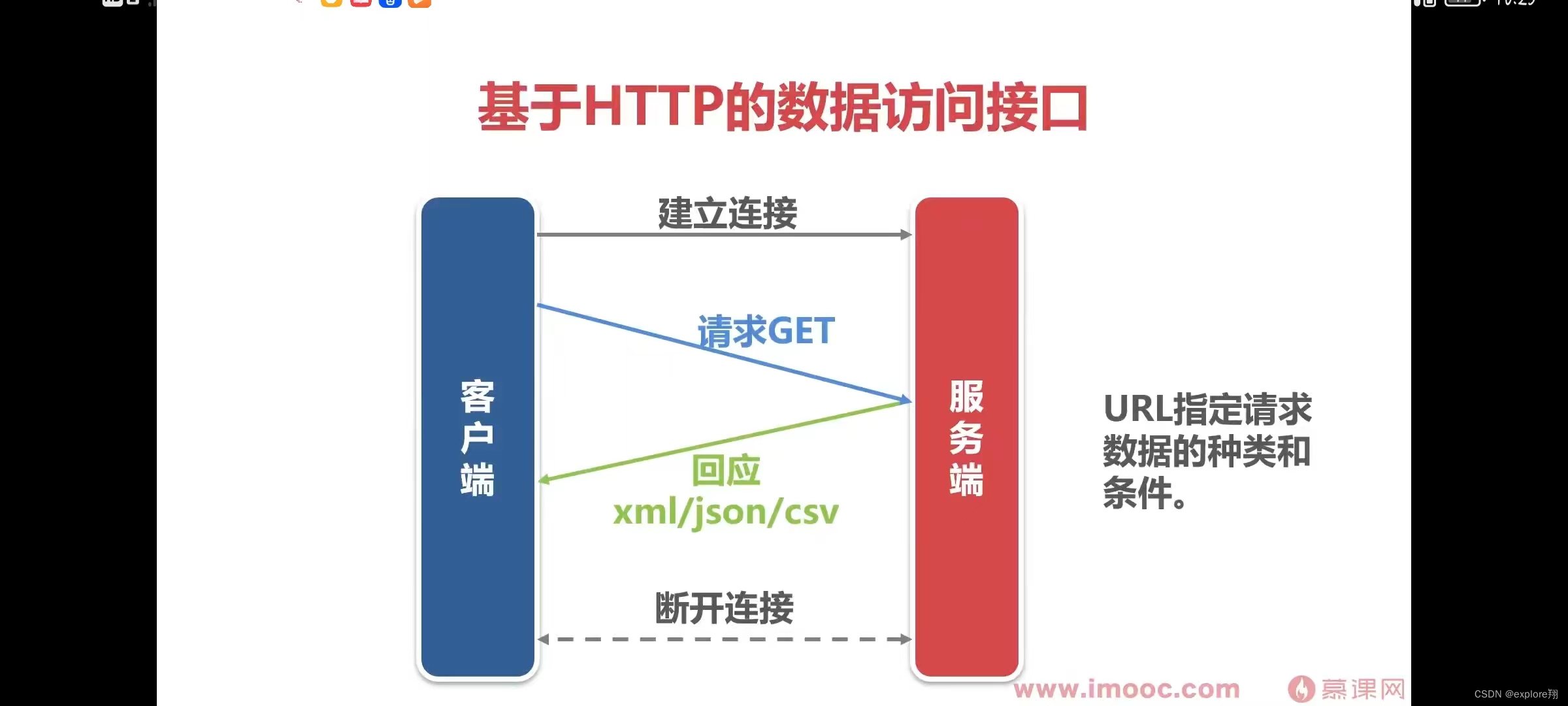
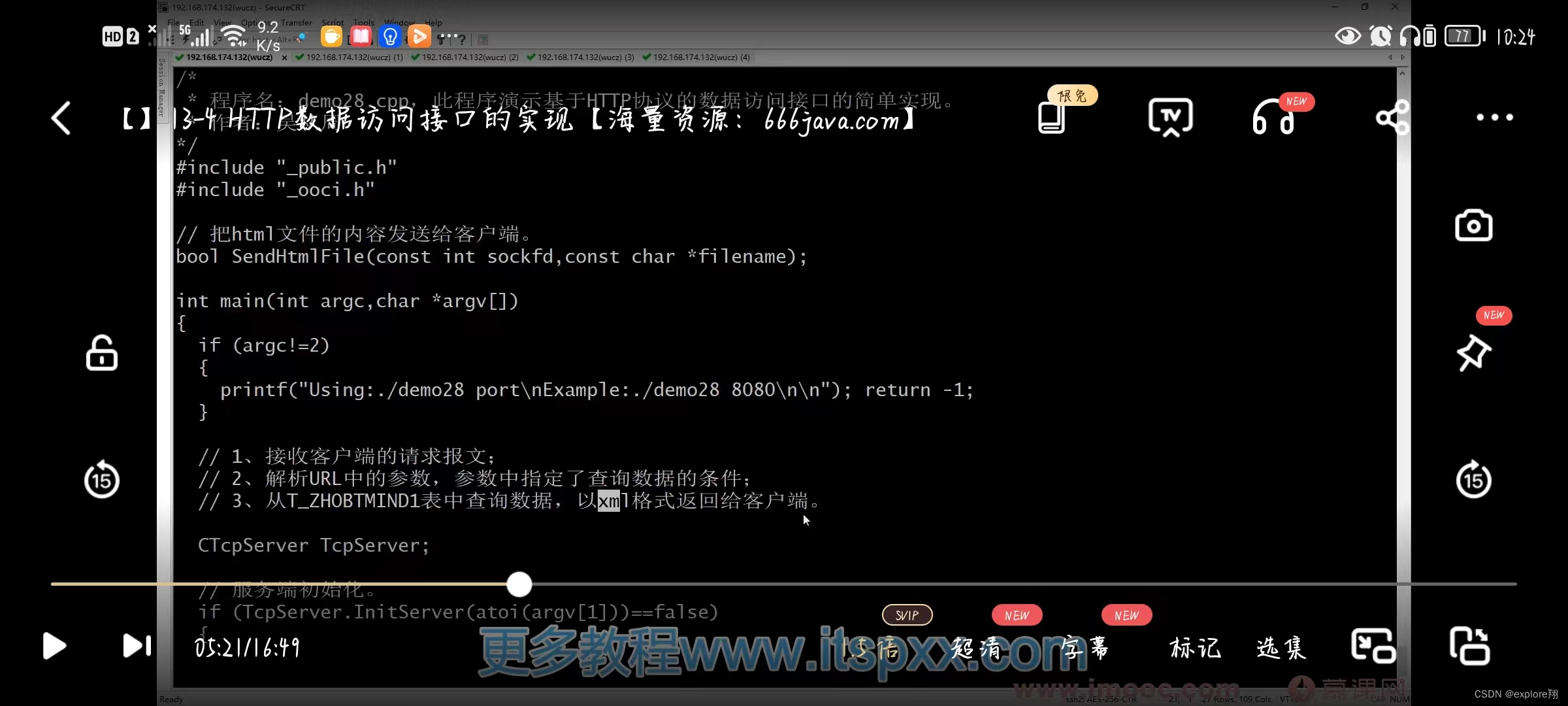
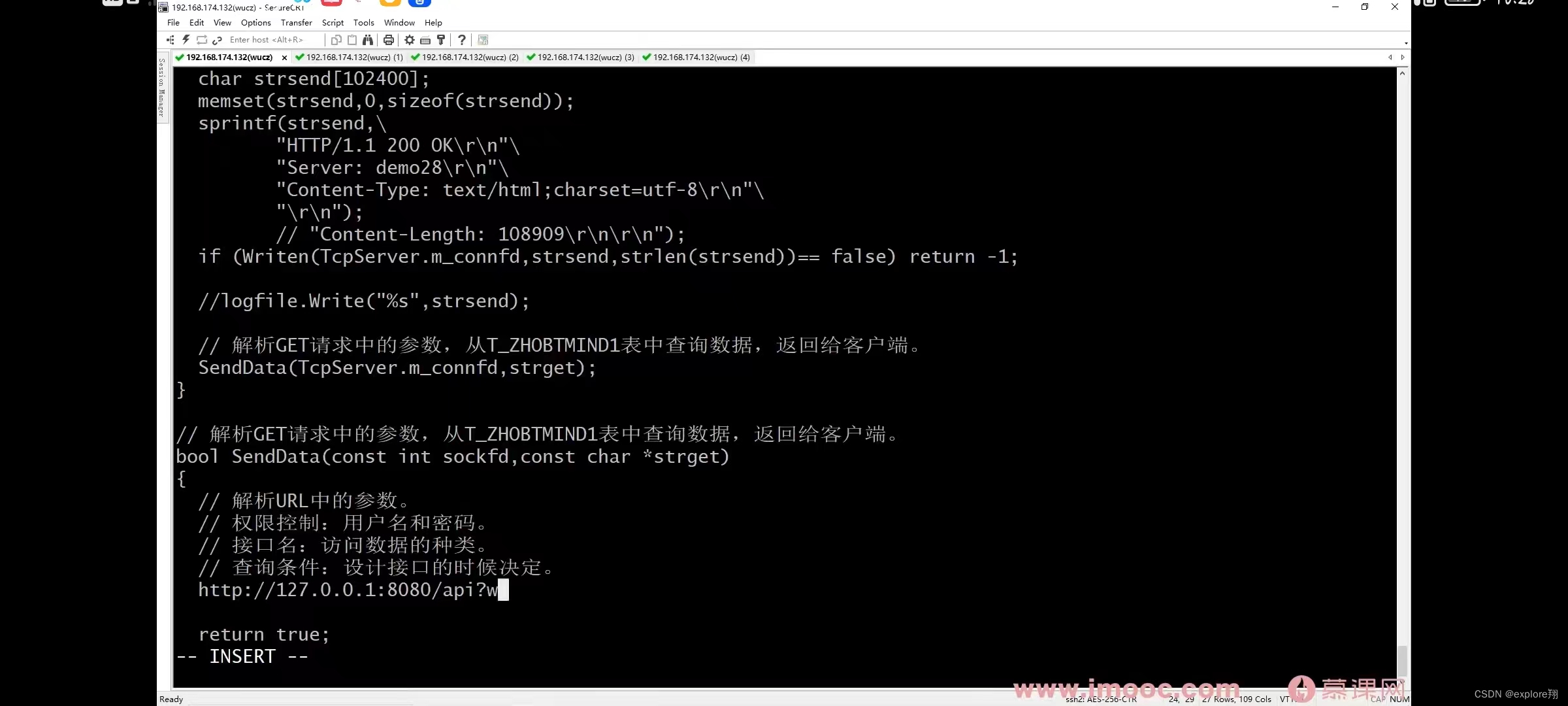
使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制。例如,/index.jsp?id=100&op=bind
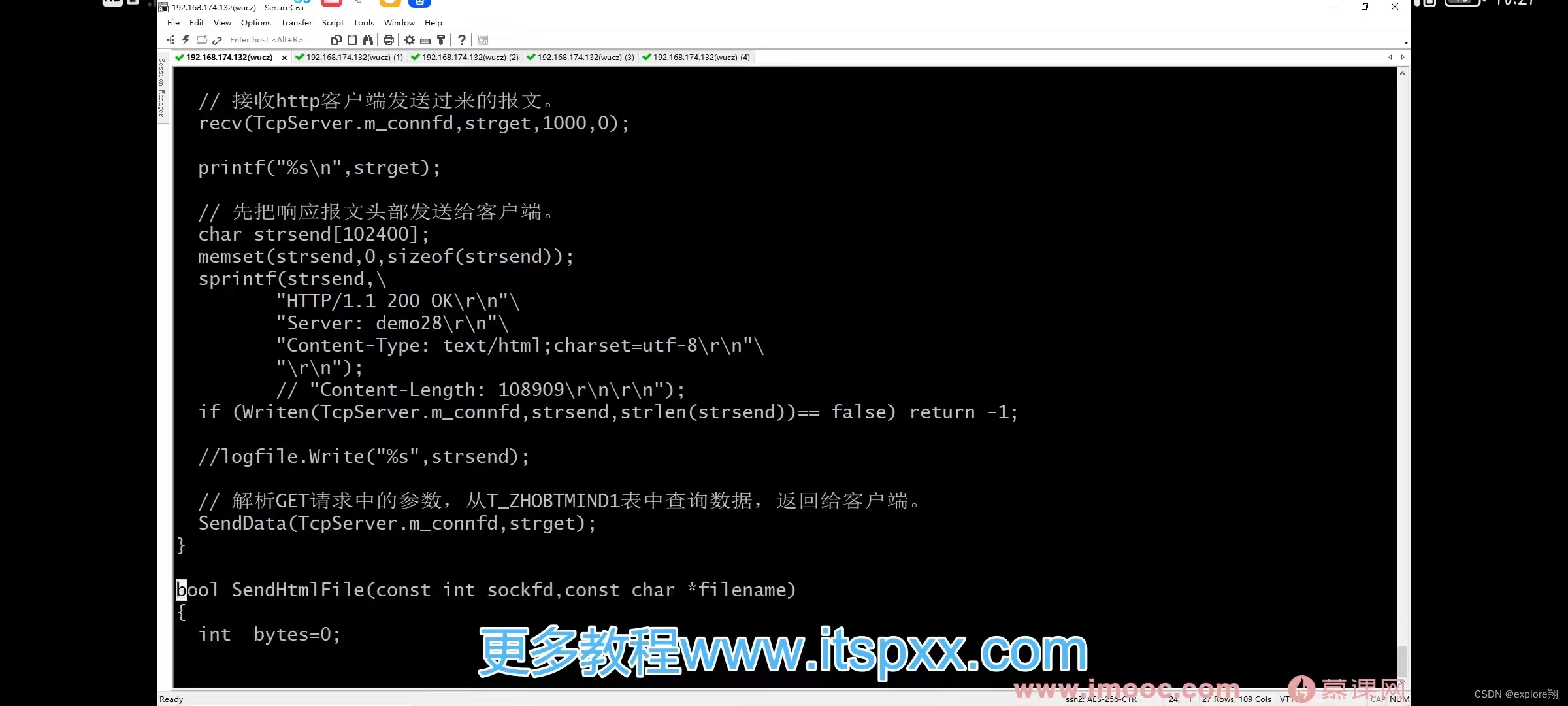
也可以利用客户端程序向服务端(比如某个网站)发送请求,网站服务端会回复,响应报文的头部,后面的数据就是网页的内容。
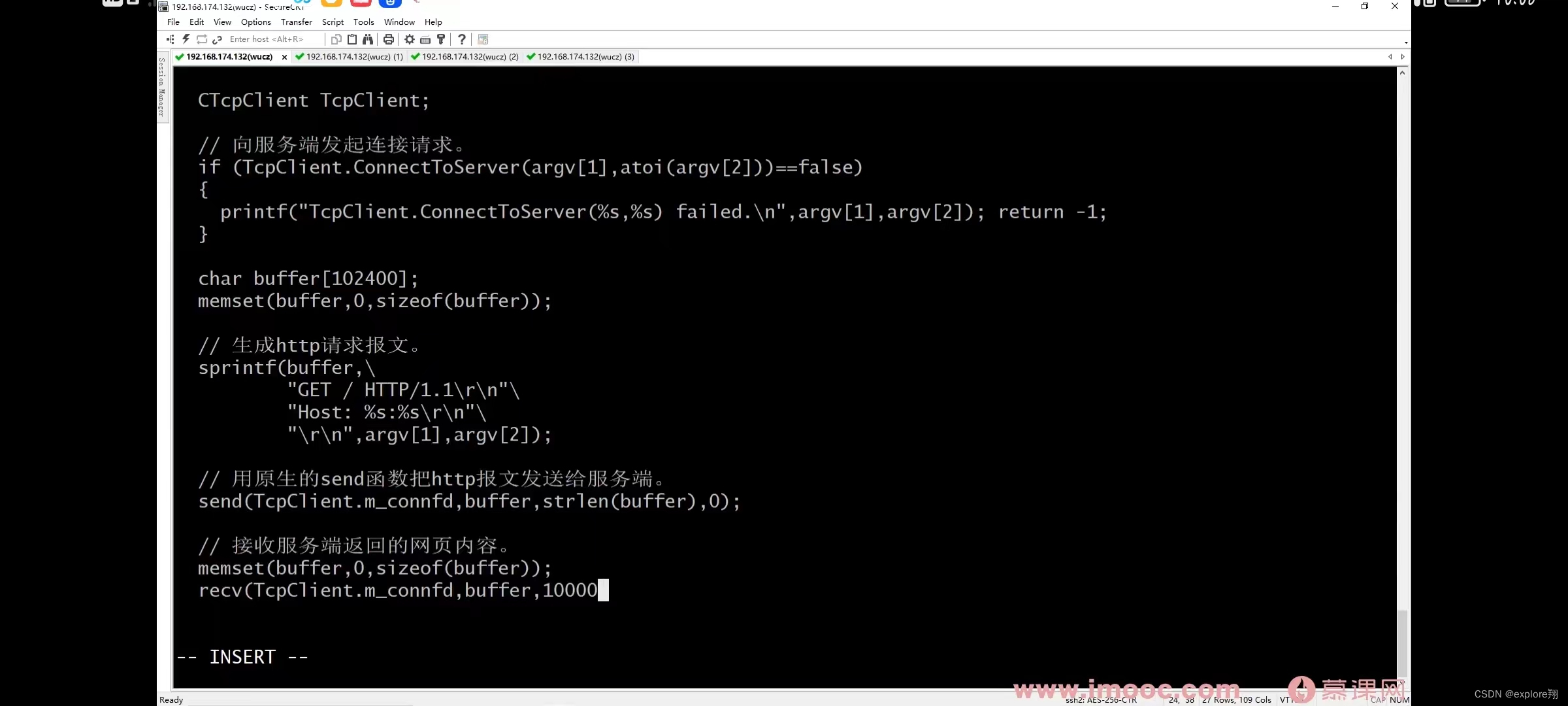
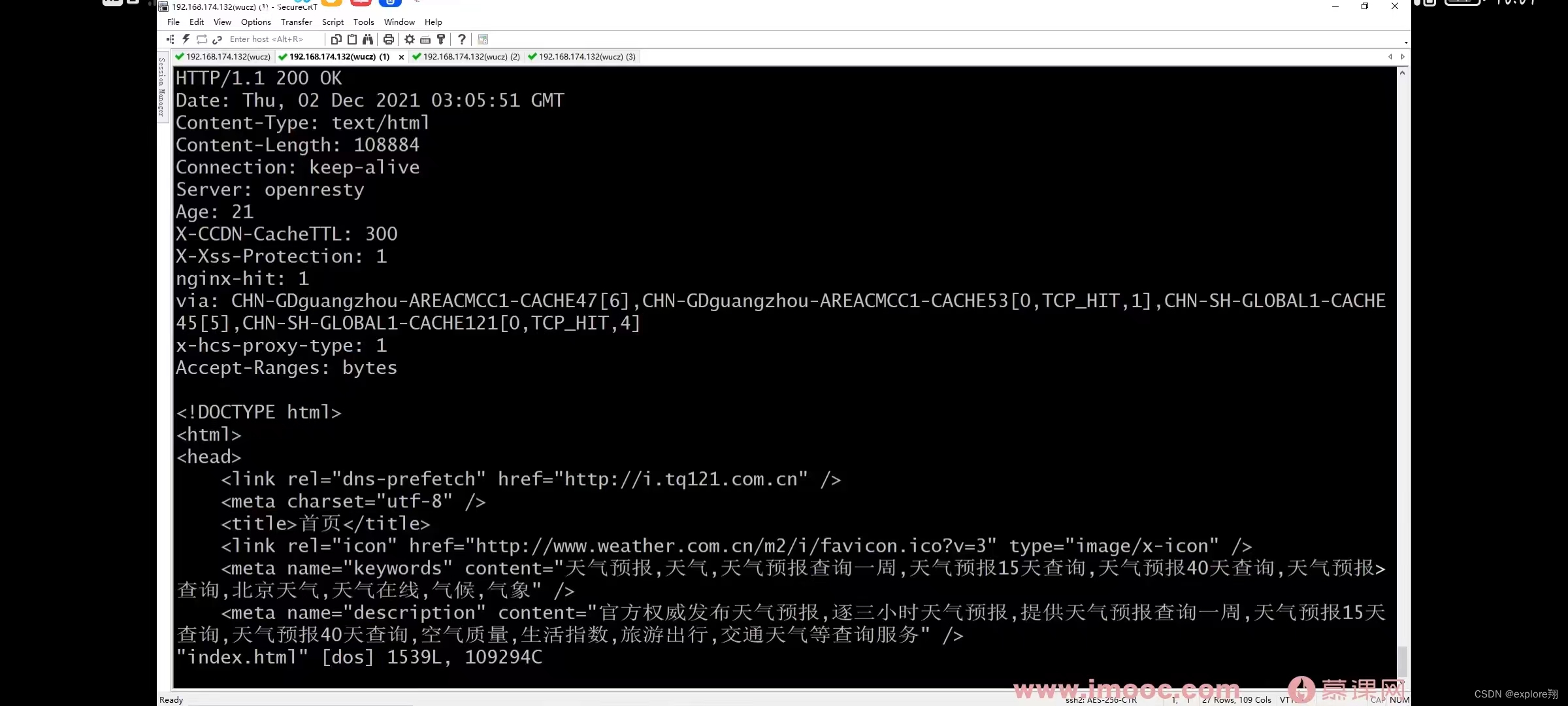
客户端如何知道响应的数据结束了?
如果网络断开,通信结束;
检查头部的content_length字段;
如果没有该字段,但是有transfer_encoding:chunked。表示内容采用分块传输。

2、实现简单的数据访问接口
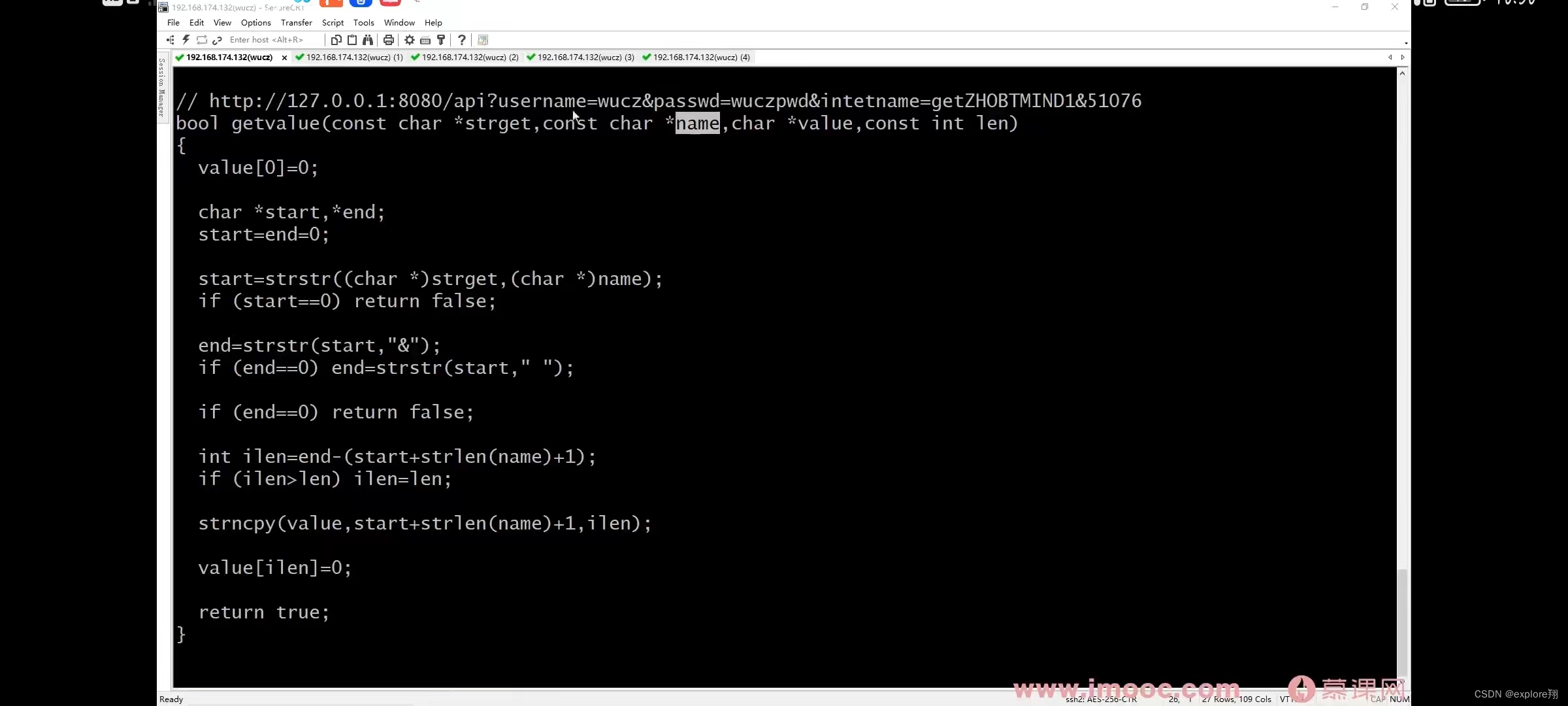
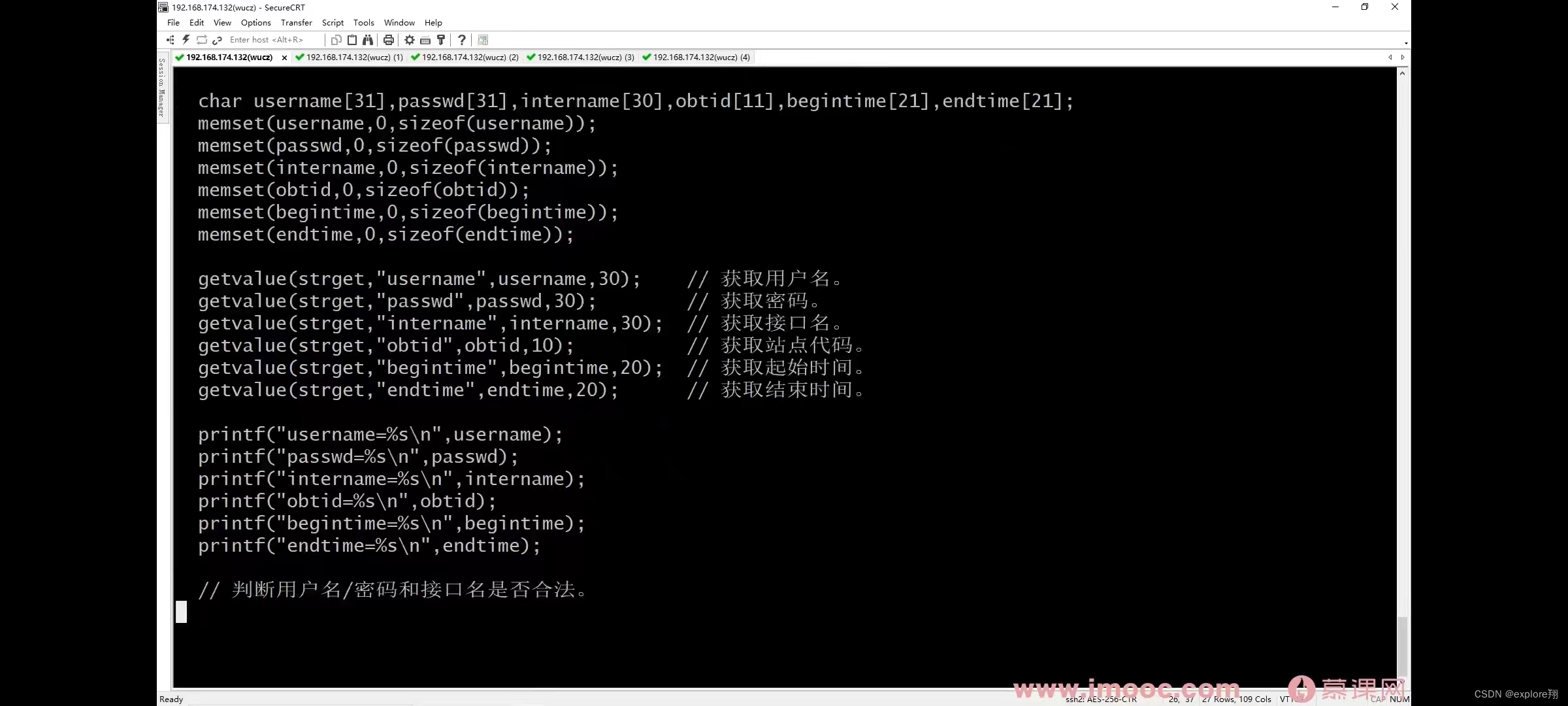
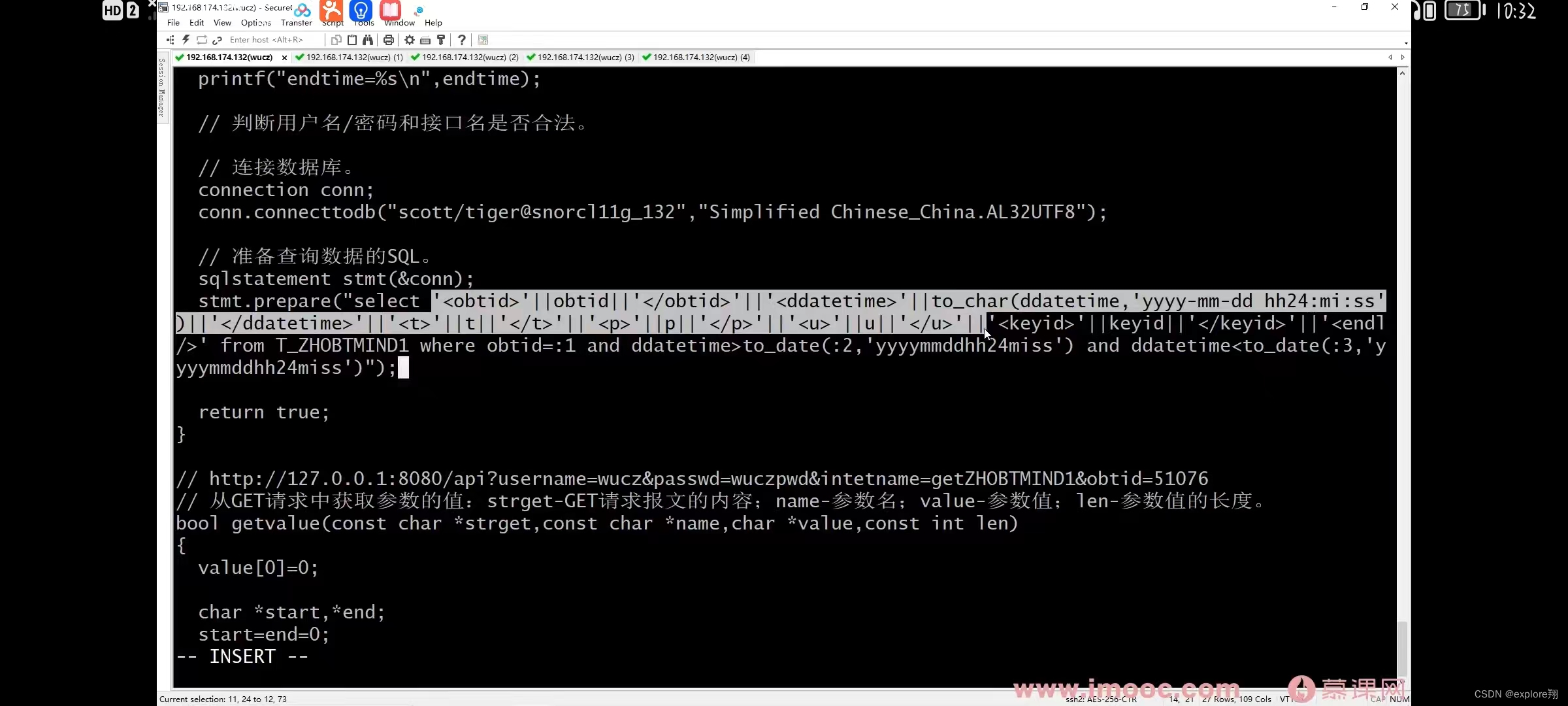
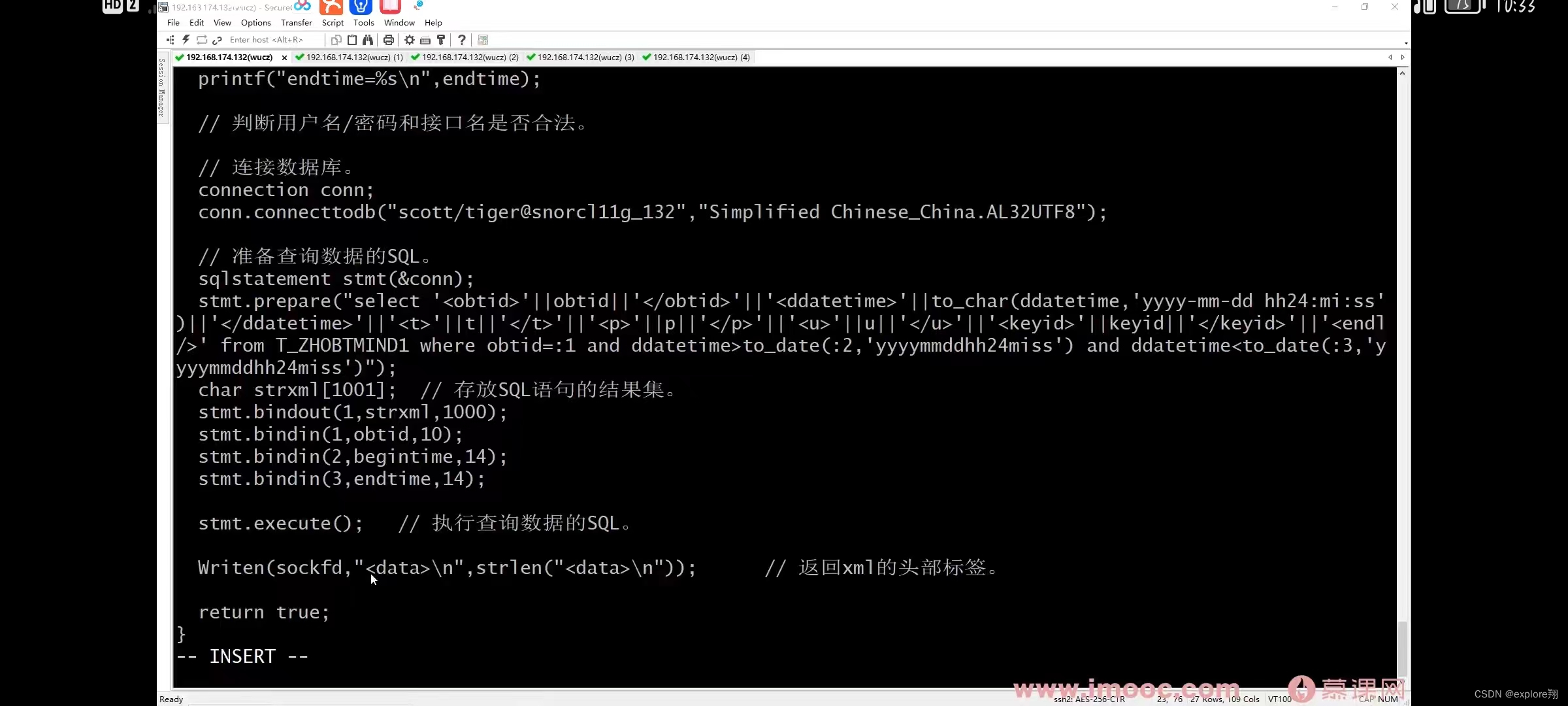
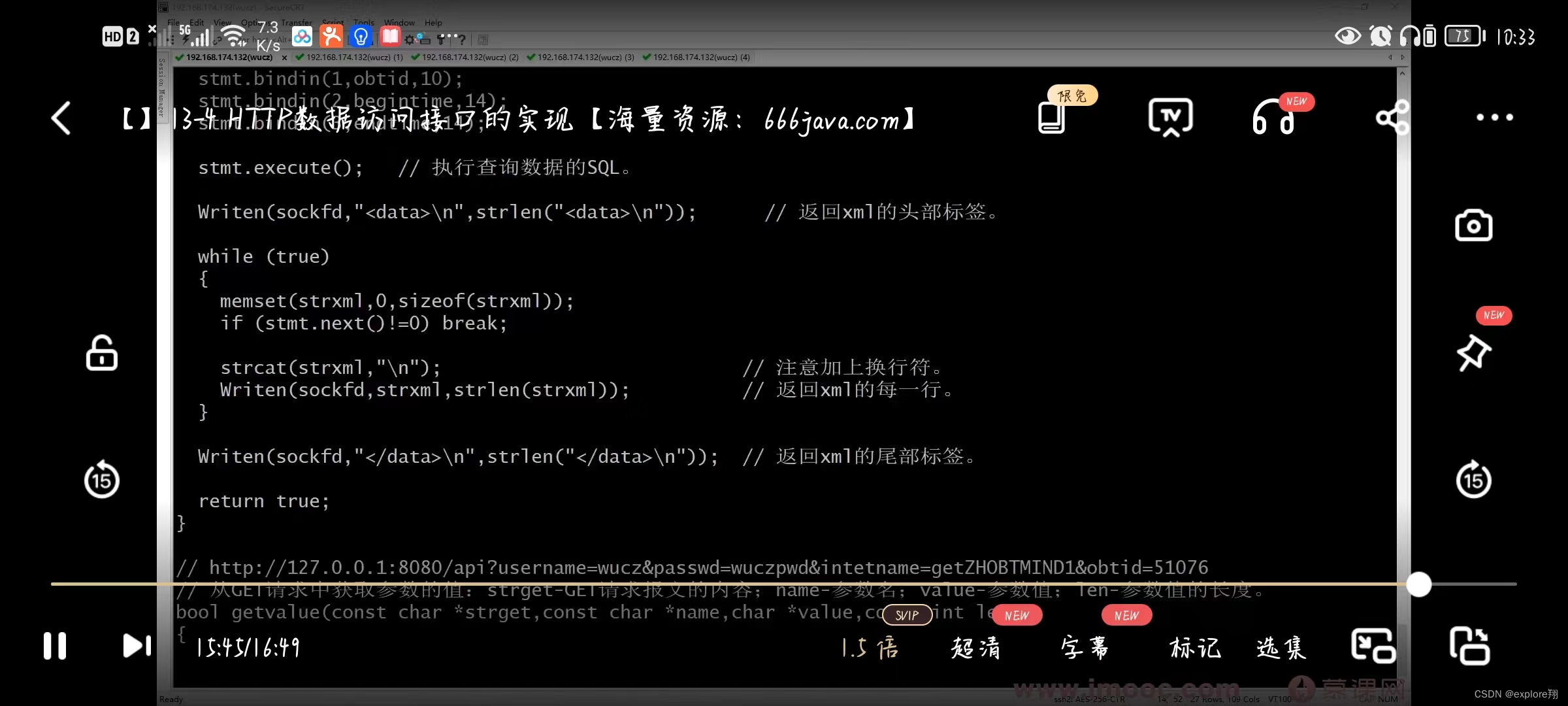
注意点:线程退出会清理自己的资源,进程退出会清理所有线程资源,所以需要加锁,不然会重复释放。
数据库连接池的实现
每连接每线程的缺点:数据库一个连接,客户端和服务端都占内存(几MB到10MB);每个线程需要占用10M的虚拟内存和大于10M的固定内存;
创建线程和连接数据库需要时间;
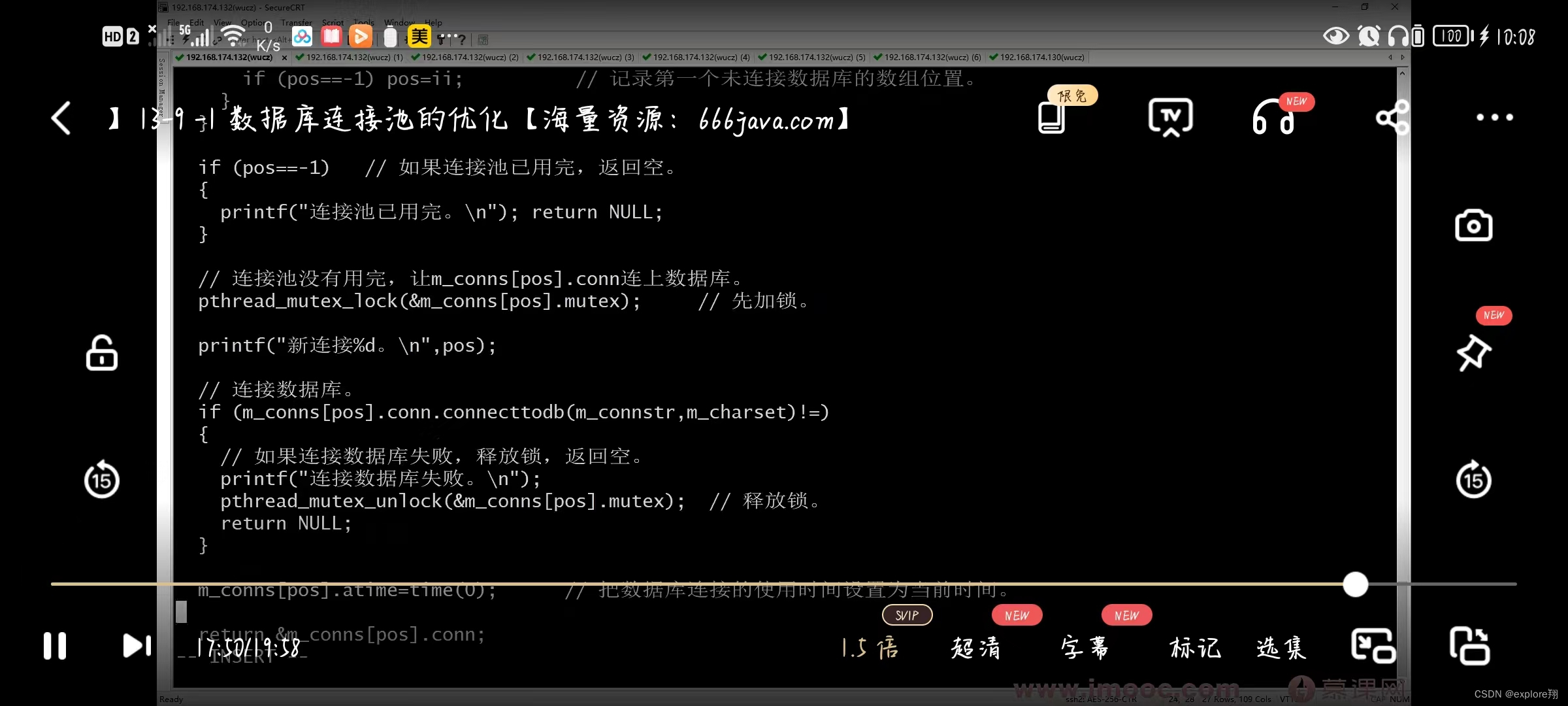
在主进程预先创建n个数据库连接,每个线程需要用数据库时就从连接池中取一个空闲的连接,用完归还;数据库连接池需要锁保护(每个连接都有一把锁);
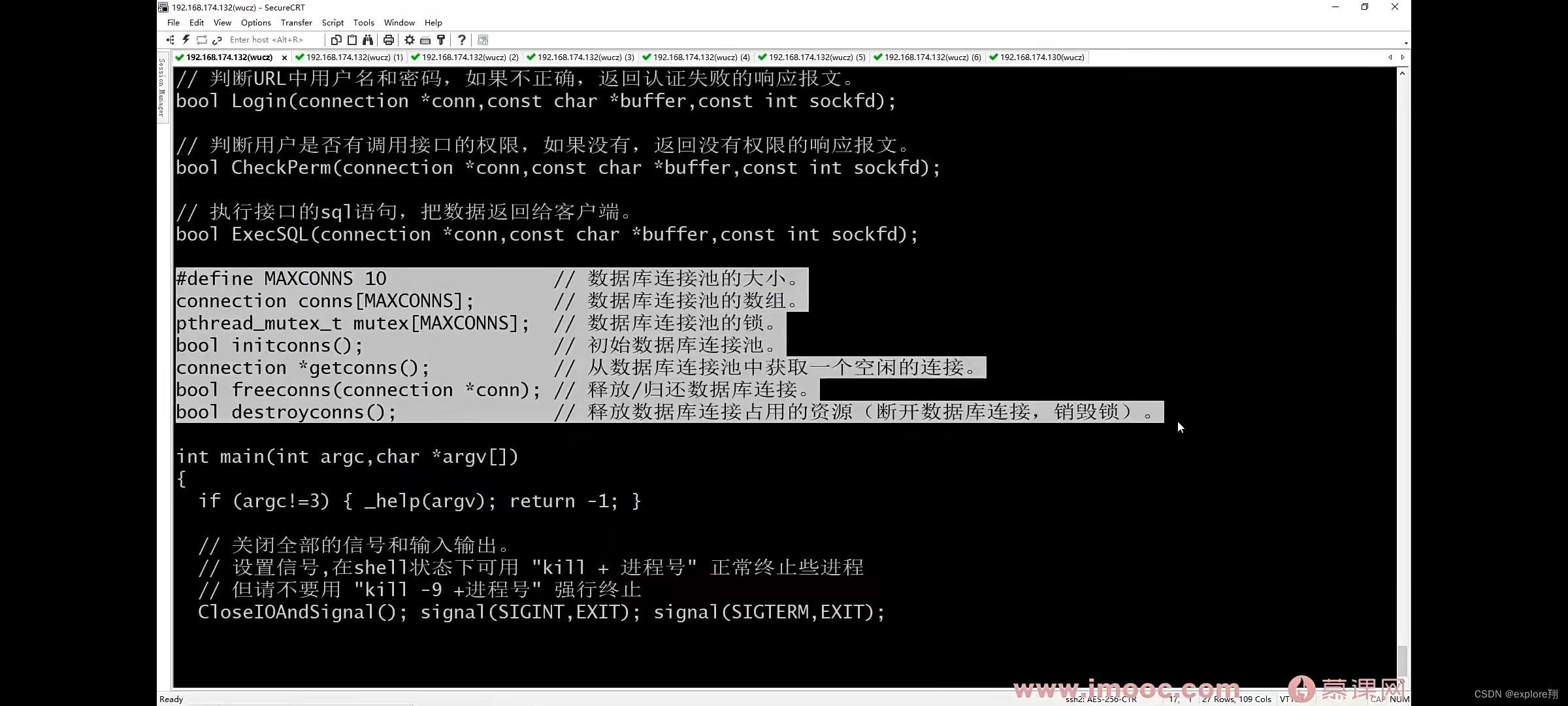
连接10个数据库,并初始化锁。
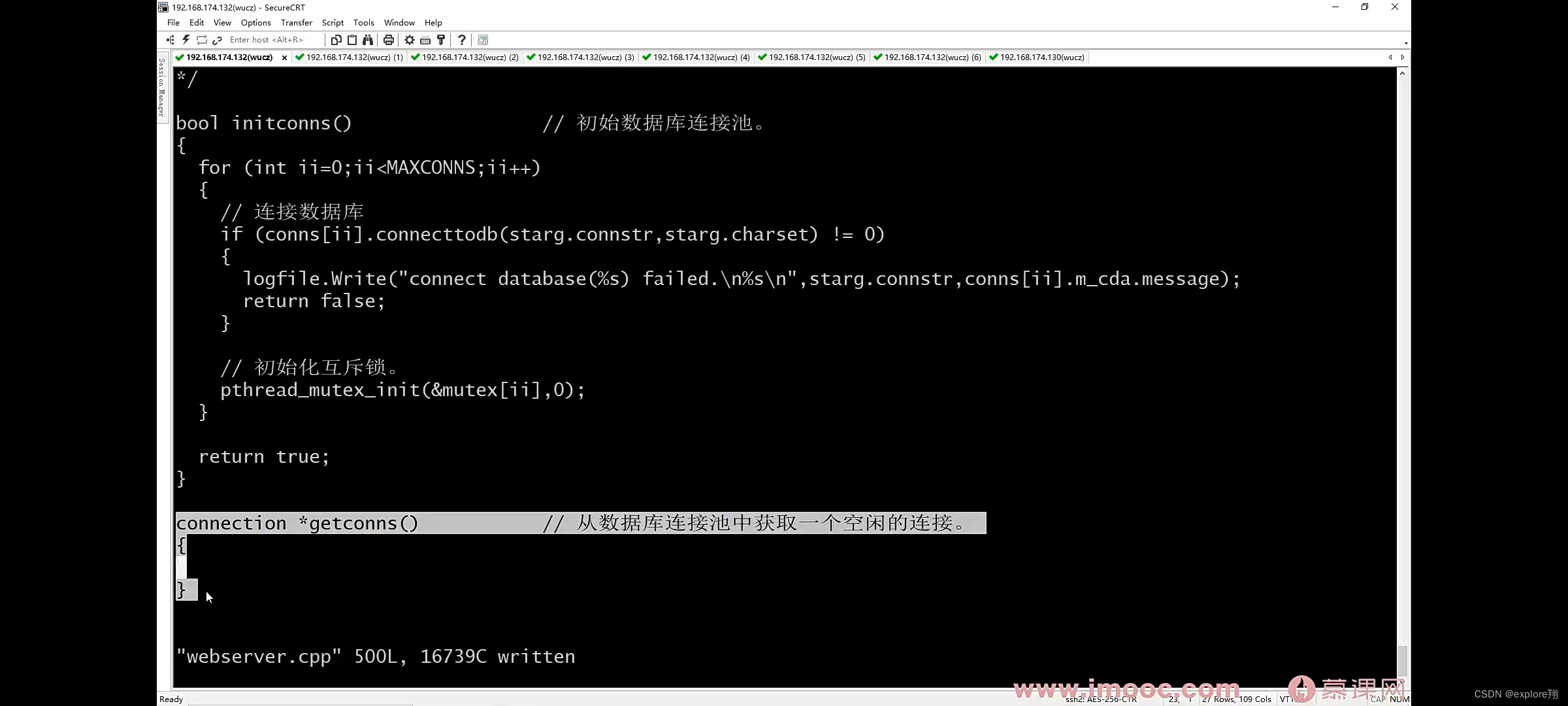
轮询,trylock,空闲的就上锁,返回该连接的地址
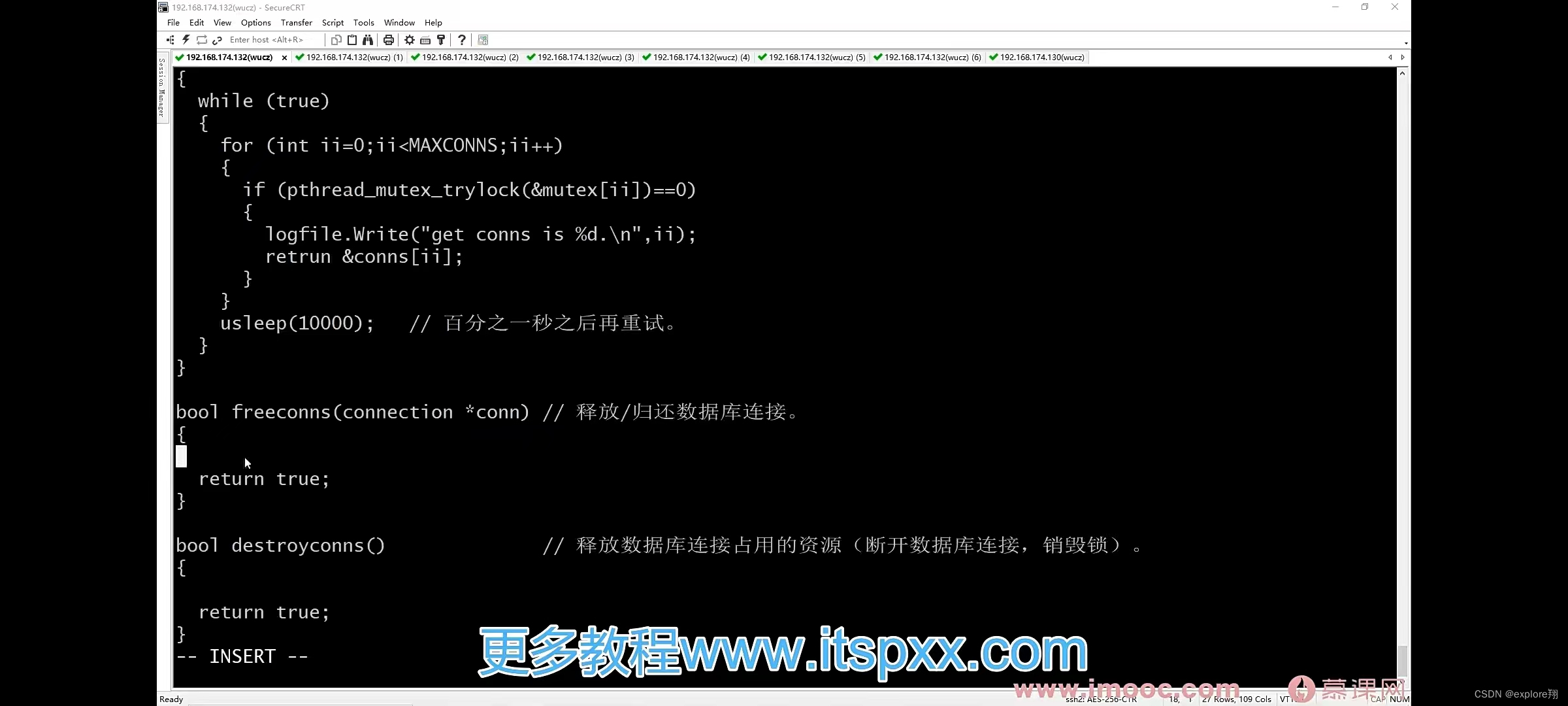
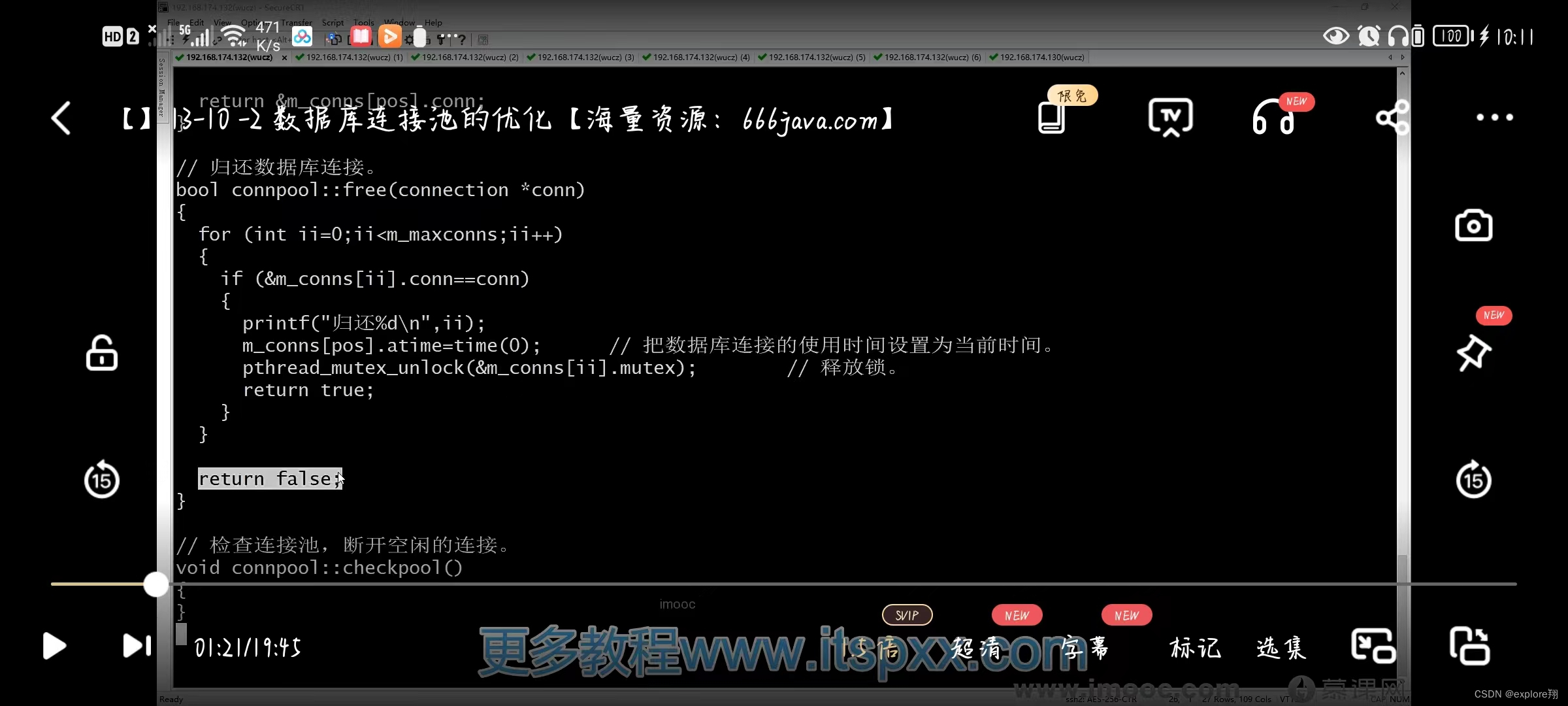
归还时,解锁。
1核2G的CPU 2000个连接只要18秒就可以了。而且还跑了数据库。用shell脚本测试的。

数据库连接池的优化:
1 **把前面的函数封装成类。**体现RAAI的思想,(使用局部对象来管理资源的技术称为资源获取即初始化,局部对象是指存储在栈的对象.资源的使用一般经历三个步骤a.获取资源 b.使用资源 c.销毁资源,但是资源的销毁往往是程序员经常忘记的一个环节,所以程序界就想如何在程序员中让资源自动销毁呢?c++之父给出了解决问题的方案:RAII,它充分的利用了C++语言局部对象自动销毁的特性来控制资源的生命周期。)
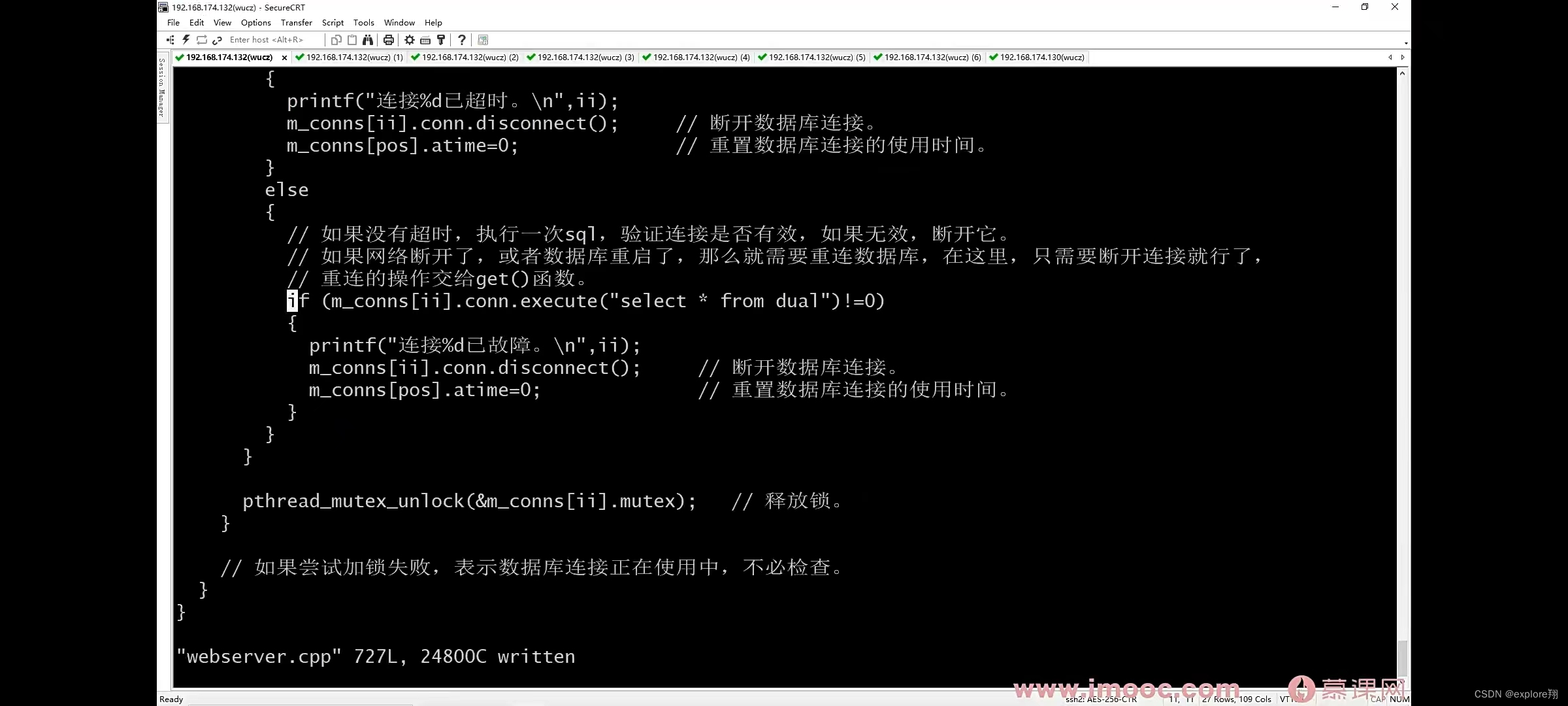
2 **设定最大连接数;链接不够自动扩展,连接空闲(n秒未使用)自动断开,释放资源。**其中检查空闲连接用一个子线程来做。
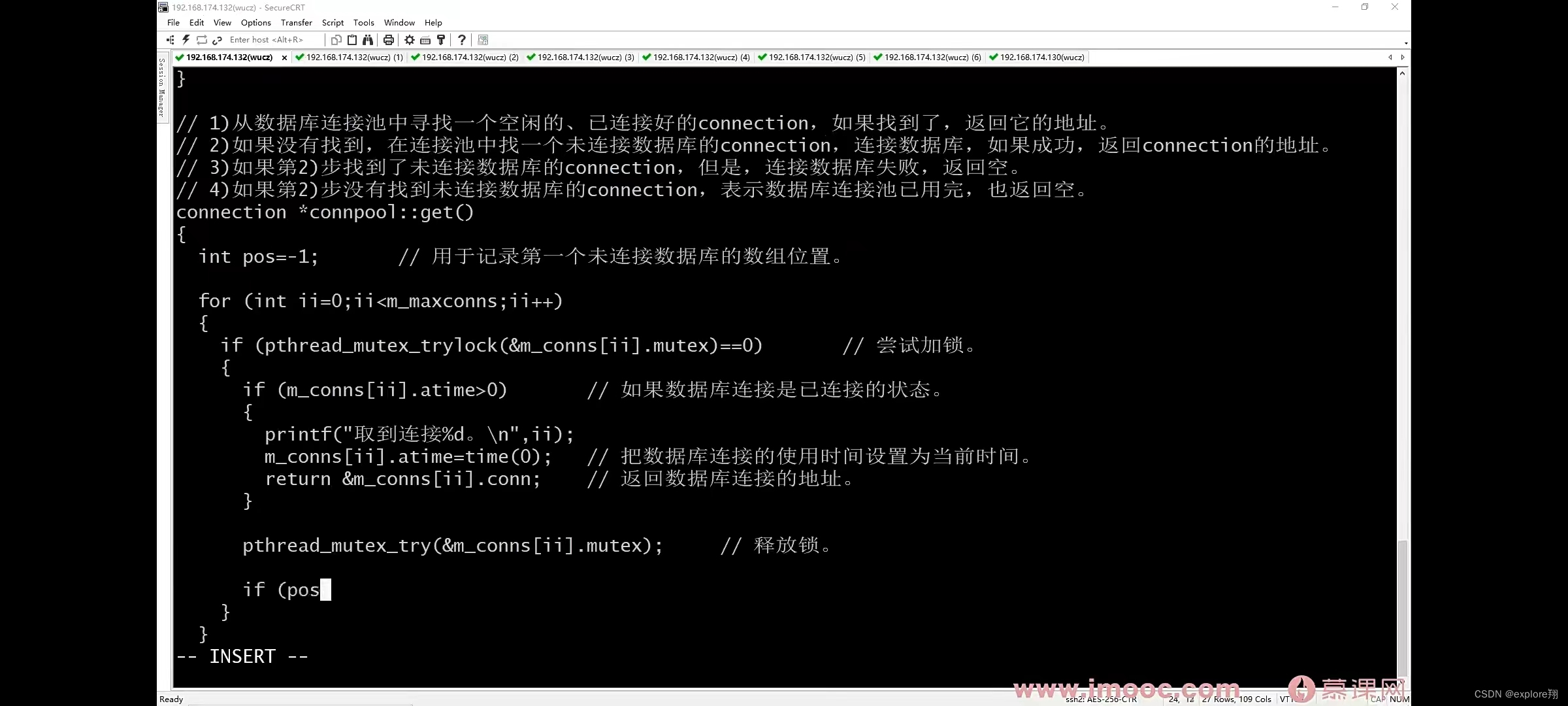
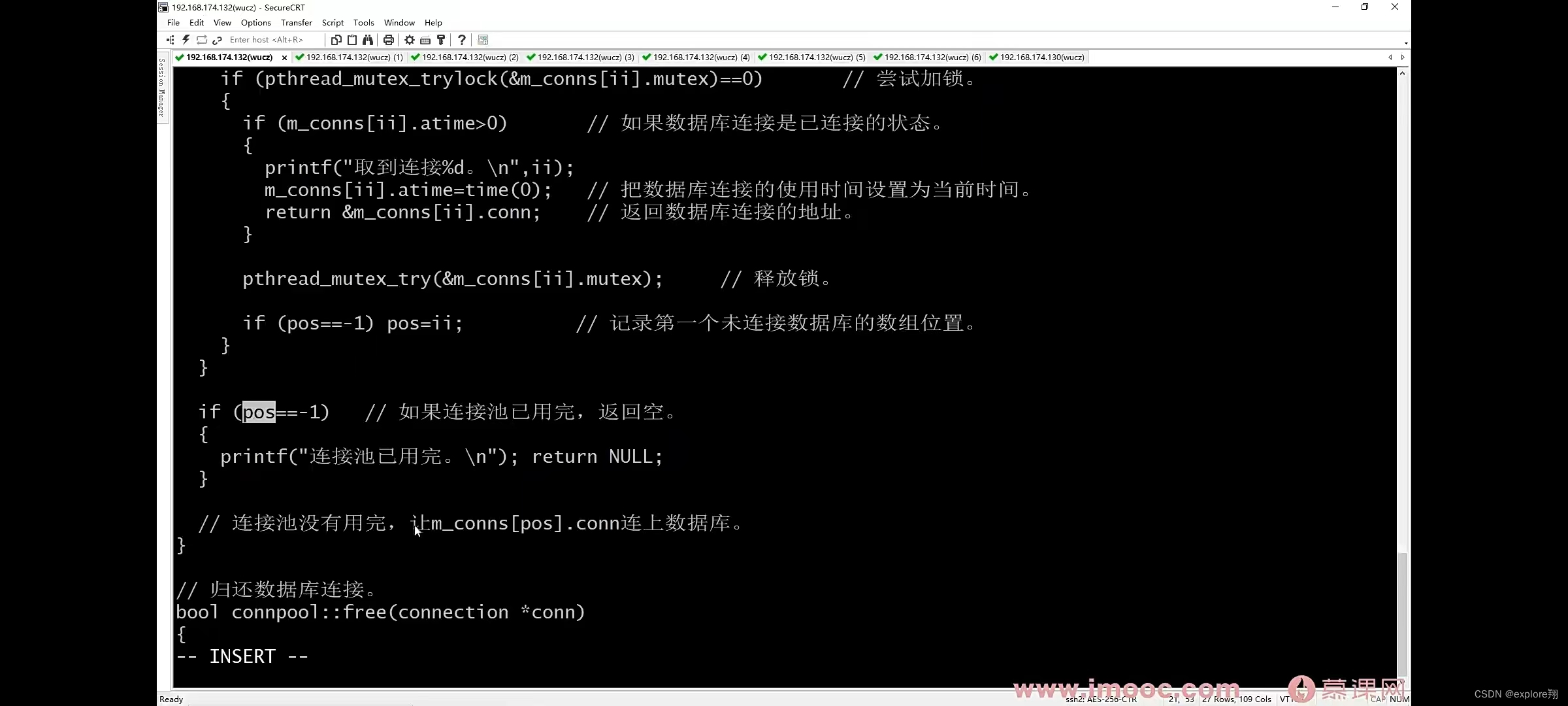
3 细化获取连接池中连接的方式:
先找一个空闲的,已经连接好的连接,如果找到,返回他的地址;2、如果没有找到,在连接池中找一个未连接的connecttion,连接数据库,如果成功,返回连接的地。一个临时变量,把第一个未连接的位置记录下来。
防止线程退出太快造成段错误:因为主线程创建一个新线程就把该线程放入容器中,但是由于线程可能退出很快,主程序还没来得及把线程id放入容器,线程清理函数没找到id,直接退出。而进程退出会取消全部线程,用循环从容器中删除,pthread_cancel(thid),这个id早就没了,所以出现错误。
正常不会这么快退出,因为当数据库连接池用完,取数据库连接地址为NULL,直接退出了,就很快。所以可以在直接退出休眠一点时间。usleep(100000);
先说之前的那部分:线程退出时的线程清理函数是关闭客户端socket,再把本线程的id从存放线程id的容器中删除,用循环。这段代码要加锁,因为容器只有一个是互斥资源(vector)。如果另一个线程先删除,那么数组大小就小了,出现段错误。这点还好理解。
注意的是进程主函数退出时,会取消全部线程,用循环从容器中删除,pthread_cancel(thid)。所以这段代码也要加锁。
线程池的实现:
主线程预先创建n个工作线程,监听客户端连接,有新连接放入待处理队列;工作线程从客户端连接中取出连接,处理请求。
细节:队列中存放的是客户端的socket; 用条件变量加互斥锁实现消息队列(生产者消费者)
其中线程总数比CPU核数略多就行。为什么不是相等,因为不是一直在跑,可能阻塞,可以让其他线程跑。太多的话没有cpu跑,切换线程浪费时间。
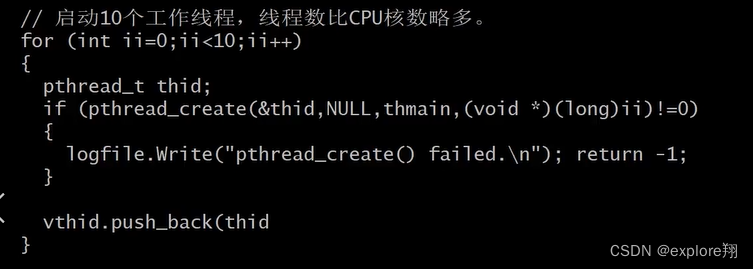
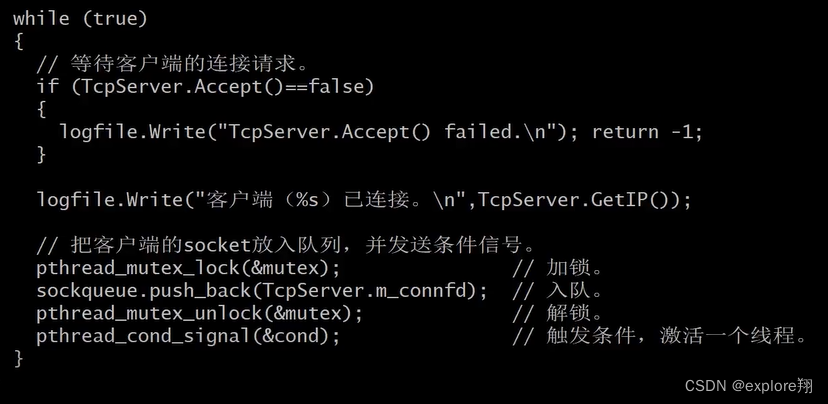
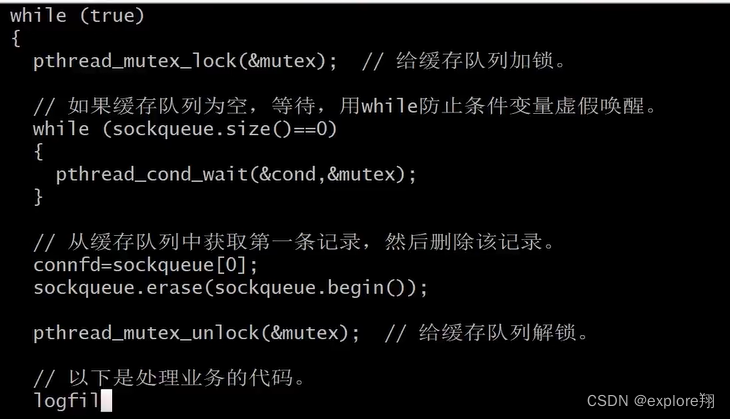
上面这一段是线程函数tmain.
线程池的监控

线程信息包括线程id和最近一次活动的时间,声明一个vector存放所有线程的信息。
然后工作线程写心跳信息。工作线程只有在cond_wait会阻塞,即缓存队列为空,修改这个wait,加上超时时间,比如20秒,20秒就会超时返回进入下一行,把自己的心跳信息改为当前时间。
监控线程:死循环不断监控,里面for循环遍历线程,如果当前时间减去线程心跳时间大于20,超时。
pthread_cancel()取消该线程,再重新创建一个工作线程,设置活动时间。