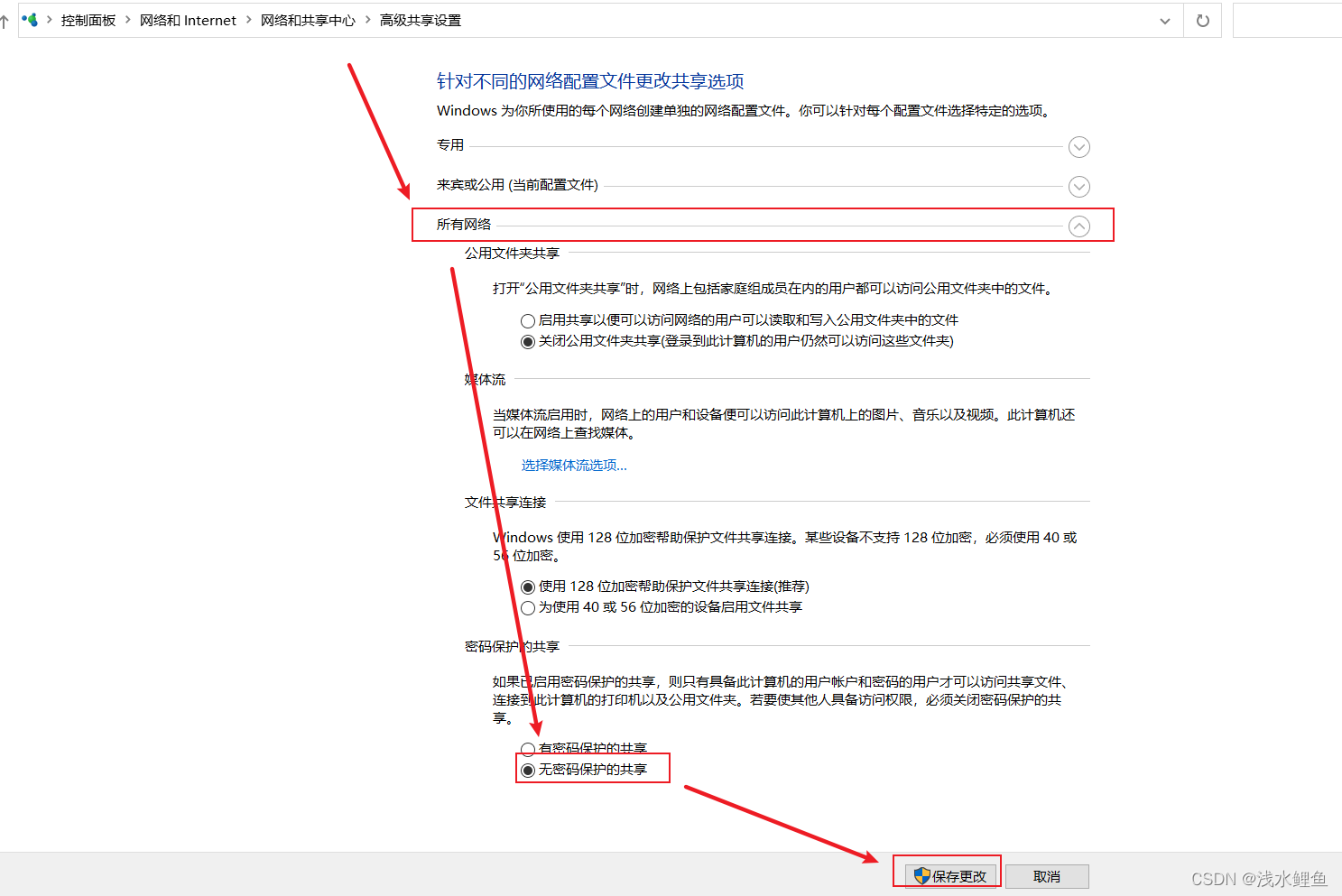
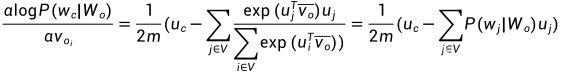一、损失函数
计算实际输出和目标之间的差距
为我们更新输出提供一定的依据(反向传播)
1.nn.L1Loss

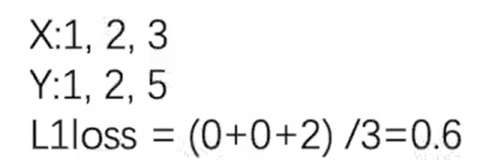

import torch
from torch.nn import L1Loss
inputs = torch.tensor([1,2,3],dtype=torch.float)
targets = torch.tensor([1,2,5],dtype=torch.float)
# reshape是为了添加维度,原来的tensor是二维的
inputs = torch.reshape(inputs,(1,1,1,3)) # 1batch 1channel 1行3列
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss(reduction='sum') #reduction默认为mean,即求平均
result = loss(inputs,targets)
print(result)2 .nn.L1Loss

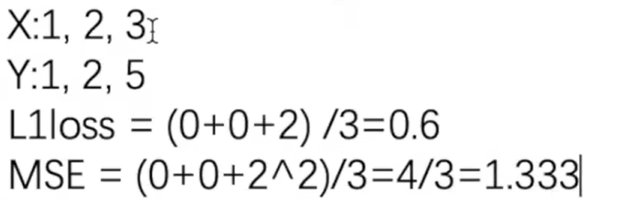
import torch
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1,2,3],dtype=torch.float)
targets = torch.tensor([1,2,5],dtype=torch.float)
# reshape是为了添加维度,原来的tensor是二维的
inputs = torch.reshape(inputs,(1,1,1,3)) # 1batch 1channel 1行3列
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss(reduction='sum')
result = loss(inputs,targets)
loss_mse = MSELoss()
result_mse = loss_mse(inputs,targets)
print(result)
print(result_mse)3.交叉熵
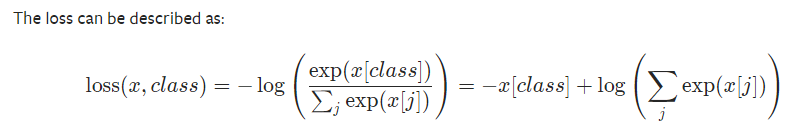
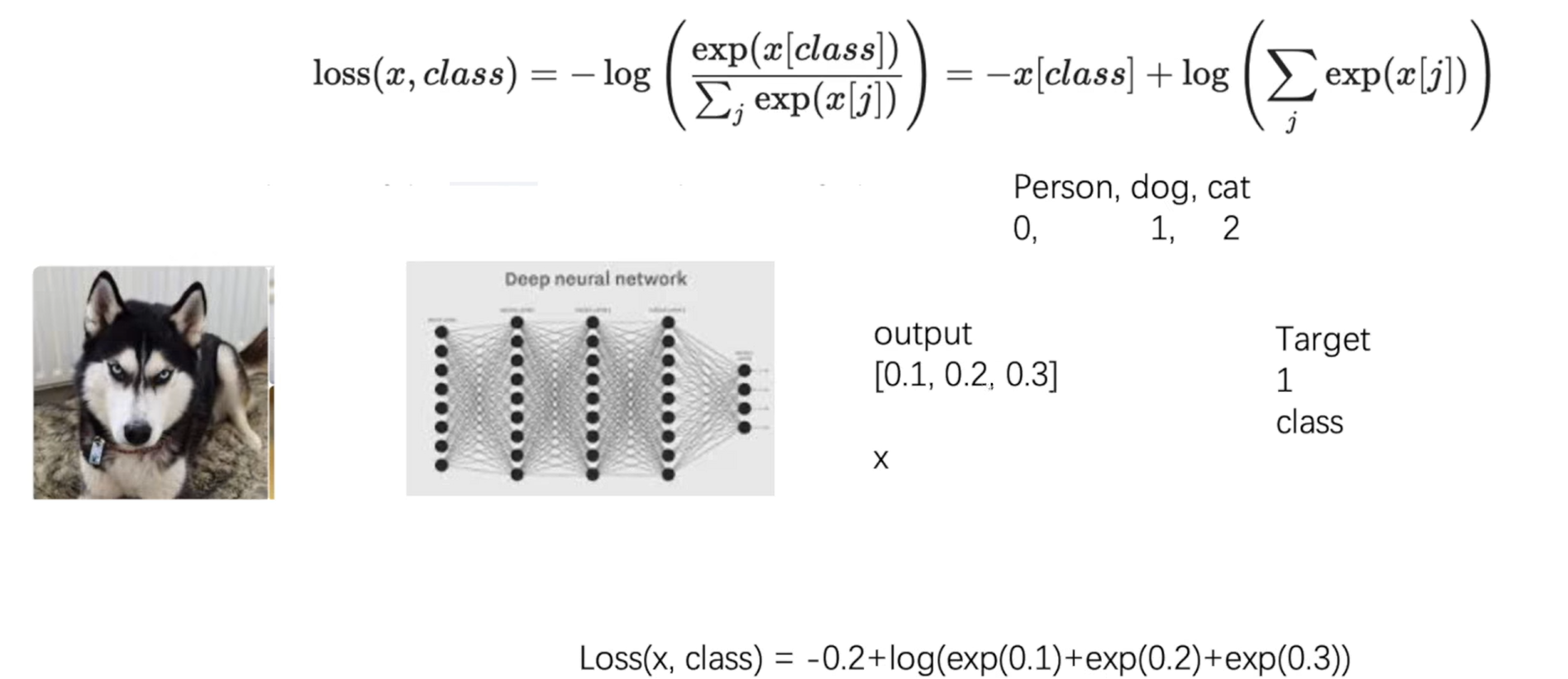
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)二、反向传播
尝试如何调整网络过程中的参数使得loss越来越小(反向传播grad)
梯度下降法:进行参数更新,使得loss降低
for data in dataloader:
imgs, targets = data
outputs = lemon(imgs)
result_loss = loss(outputs,targets)
result_loss.backward()
print("ok")三、优化器
for input, target in dataset:
optimizer.zero_grad() #清空梯度
output = model(input)
loss = loss_fn(output, target)
loss.backward() # 获取每个参数的梯度
optimizer.step() # 对参数进行优化torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
【入门阶段只需要设置params和lr学习率 其他的参数对应各种特定的算法】params (iterable) – iterable of parameters to optimize or dicts defining parameter groups 参数
rho (float, optional) – coefficient used for computing a running average of squared gradients (default: 0.9)
eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-6)
lr (float, optional) – coefficient that scale delta before it is applied to the parameters (default: 1.0) 学习率
weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
import torch
from torch import nn
from torch.nn import Conv2d, Flatten, Linear, Sequential
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
class Lemon(nn.Module):
def __init__(self):
super(Lemon, self).__init__()
self.model = Sequential(
Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024, out_features=64),
Linear(in_features=64, out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
lemon = Lemon()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(lemon.parameters(),lr=0.001) #定义优化器
for epoch in range(20): # 一共对数据进行20轮循环
running_loss = 0.0
#for data in dataloader相当于只对数据进行了一轮的学习
for data in dataloader:
imgs, targets = data
outputs = lemon(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad() #梯度清零
result_loss.backward() #得到每个参数的梯度
optim.step() #优化参数
running_loss = running_loss + result_loss
print(running_loss)