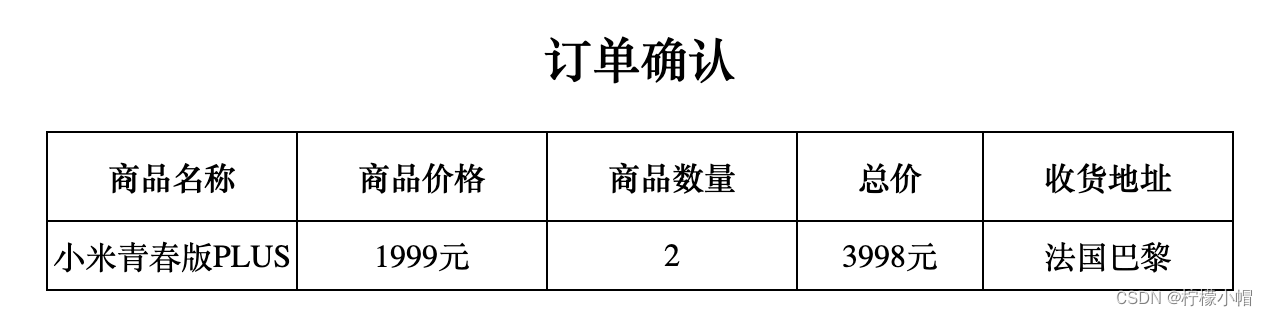
自然语言处理(Natural Language Processing, NLP)是AI里的一个非常重要的领域,比如现在很火爆的ChatGPT,首先就需要很好的理解输入内容的意思才能够做出合理的回复。
自然语言处理应用非常广泛,比如机器翻译、问题回答、文本语义对比、语音识别、自动文摘、写论文与判断论文是否抄袭等等,为了将这些应用做好,很关键的就是数学在其中的作用。
这节重点是讲解数学公式在损失函数中的推导,主要是掌握一些概率与微积分的相关知识,比如求导数与偏导数(梯度)。
NLP基本术语
在介绍模型之前,先熟悉一些常见的基本术语,这样在后续的实操中更清楚其中代表着的是什么。
1、自然语言:一套用来表达含义的复杂系统
2、词:自然语言中表达意思的基本单元
3、词向量:表示词的向量或说是词的表征,类似卷积神经网络中的特征值,也可说成词的特征向量,这个是很关键的东西,是计算机能够识别词的关键
4、词嵌入:将词映射成为实数域向量的技术(这个是为了解决独热编码存在的问题而提出的)
5、似然函数:描述样本数据出现的可能性的函数,是用来衡量模型参数的可能性,这个要跟“概率”区分开来,看起来比较像,其实是 截然不同的两个概念。概率是一种描述某件事情发生的可能性的概念,是用来衡量某件事情发生的可能性。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后求出变量X的概率:L(θ|x)=P(X=x|θ)。如果从深度学习领域来看,由公式我们可以给出更贴合的解释为, 概率是参数已知,求出的随机变量的结果。似然函数则相反,已知随机变量的输出结果,求参数的可能取值。
为什么不使用独热编码
那在NLP中一般都不会选择使用独热码(One-Hot)向量,这是什么原因呢?
独热码就是长度为N的向量中,这个词的索引为i,在i位置为1,其余位置都为0的表达形式,这种结构我们最开始是在 MNIST数据集手写数字识别(一) 文章中介绍并应用过,对于这种分类任务没有问题,但用在NLP中,就有缺陷了,因为这样的编码方式不能表达出不同词之间的相似度。
为了解决上述的问题,就提出了词嵌入(word embedding),这节的两个模型就是来自word2vec工具,我们分别来介绍它
跳字模型(跳元模型)<skip-gram>
也有人叫做“跳字元模型”,当然意思都是一样,把词当作是元或字元,这个模型是通过基于某个词来生成它在文本序列周围的词。
举个例子:"the" "man" "loves" "his" "son",以"loves"为中心词,设背景窗口大小为2,生成与它距离不超过2个词的背景词"the" "man" "his" "son"的条件概率:
P("the","man","his","son" | "loves")
由于这些背景词的生成是相互独立的,所以可以改写成:
P("the" | "loves")*P("man" | "loves")*P("his" | "loves")*P("son" | "loves")
设中心词 在词典中的索引为c,背景词
在词典中的索引为c,背景词 在词典中的索引为o,给定中心词生成背景词的条件概率可以通过对向量做内积然后softmax运算得到:
在词典中的索引为o,给定中心词生成背景词的条件概率可以通过对向量做内积然后softmax运算得到:
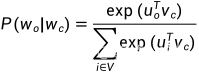
假设给定一个长度为T的文本序列,时间步为t的词为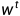 ,背景窗口大小为m,那么这个跳字模型的似然函数如下(给定任意中心词生成所有背景词的概率):
,背景窗口大小为m,那么这个跳字模型的似然函数如下(给定任意中心词生成所有背景词的概率):

跳字模型的参数是每个词所对应的中心词向量和背景词向量。训练中我们通过最大似然函数来学习模型参数,或叫最大似然估计。等价于最小化下面这个损失函数:

如果使用随机梯度下降,那么每次迭代我们随机采样一个较短的子序列来计算有关该子序列的损失,然后计算梯度来更新模型参数。
梯度计算的关键是条件概率两边取自然对数,中心词向量与背景词向量的梯度如下推导:
两边取自然对数log

下面是对 求梯度(偏导数)的推导过程,其中的一些详细细节步骤来自Aston Zhang大神的手写推导:
求梯度(偏导数)的推导过程,其中的一些详细细节步骤来自Aston Zhang大神的手写推导:
先将log整个那块用h(g(f(x)))来代替:



这三个组合起来就是 即
即 
然后开始求梯度(其中索引i修改成j,防止分子分母约掉):


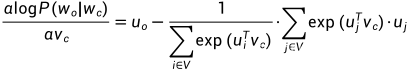


上述推导过程,涉及到常见的两种求导的结果(log在我们计算机中一般都表示自然对数,e为底):
logx的导数是1/x,e^x的导数不变,依然是e^x
它的计算需要词典中所有词以为中心词的条件概率。求其他词向量的梯度同理可得。
训练结束后,对于词典中的任意索引为i的词,我们均得到该词作为中心词和背景词的两组向量 和
和
在自然语言处理的应用中,跳字模型的中心词向量作为词的表征向量。
连续词袋模型<continuous bag of words>(CBOW)
连续词袋模型跟跳字模型很像,不同点在于连续词袋模型是基于某个中心词在文本序列前后的背景词来生成的该中心词,比如上面例子中的"loves"为中心词生成背景词"the" "man" "his" "son",这里就是通过背景词"the" "man" "his" "son"来生成 "loves"这个中心词。
那这里的条件概率就跟上面跳字模型相反
P("loves"|"the","man","his","son")
由于背景词有多个,所以将这些背景词向量取平均,然后后面的推导就跟跳字模型一样。
假定中心词在词典中索引是c,背景词是 ,在词典中索引为
,在词典中索引为 ,那么给定这些背景词生成中心词的条件概率为:
,那么给定这些背景词生成中心词的条件概率为:

其中这里的两组向量和分别是背景词和中心词,跟跳字模型相反。
我们简化下公式,设定 ,且
,且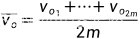 ,简写成:
,简写成:

给定一个长度为T的文本序列,设时间步t的词为 ,背景窗口大小为m,连续词袋模型的似然函数是由背景词生成任一中心词的概率:
,背景窗口大小为m,连续词袋模型的似然函数是由背景词生成任一中心词的概率:

训练连续词袋模型跟跳字模型基本是一样的,这里的连续词袋模型的最大似然估计等价于最小化损失函数:

然后跟跳字模型一样的公式推导,我们最终可以得到有关任一背景词向量 的梯度:
的梯度:
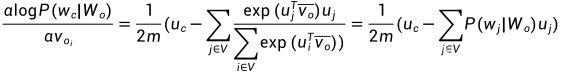
有关其的词向量的梯度同理可得,跟跳字模型不一样的地方就是,一般都使用连续词袋模型的背景词向量作为词的表征向量。
小结:需要明白公式的意义与推导,两个模型之间的共同点与不同点,以及对术语的熟悉,为后面的NLP打好基础。LaTeX公式的输入还是比较繁琐,比较耗时,不过呈现的效果还是很不错的,值得。