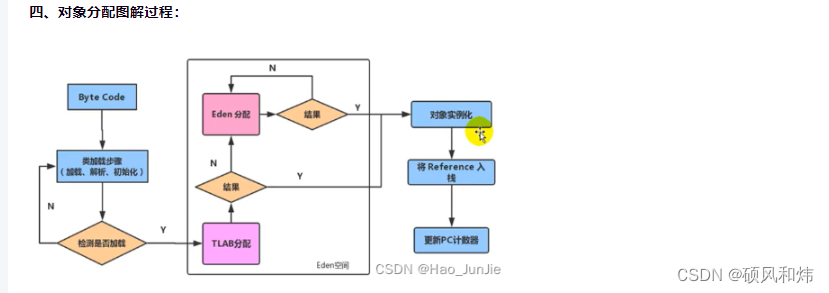
定义
ICache和DCache是一种内存,虽然目前接触了好几种内存,寄存器,DDR等,它们在物理上的工作原理虽然不同,但是访问属性却很像。
在速度上
CPU > 寄存器 > Cache > SRAM >PSRAM
在容量上
CPU < 寄存器 < Cache < DDR
CPU和主存之间也存在多级高速缓存,一般分为3级,分别是L1, L2和L3。另外,我们的代码都是由2部分组成:指令和数据。L1 Cache比较特殊,每个CPU会有2个L1 Cache。分别为:
指令高速缓存(Instruction Cache,简称iCache)
数据高速缓存(Data Cache,简称dCache)
L2和L3一般不区分指令和数据,可以同时缓存指令和数据。
下图举例一个只有L1 Cache的系统。我们可以看到每个CPU都有自己私有的L1 iCache和L1 dCache。
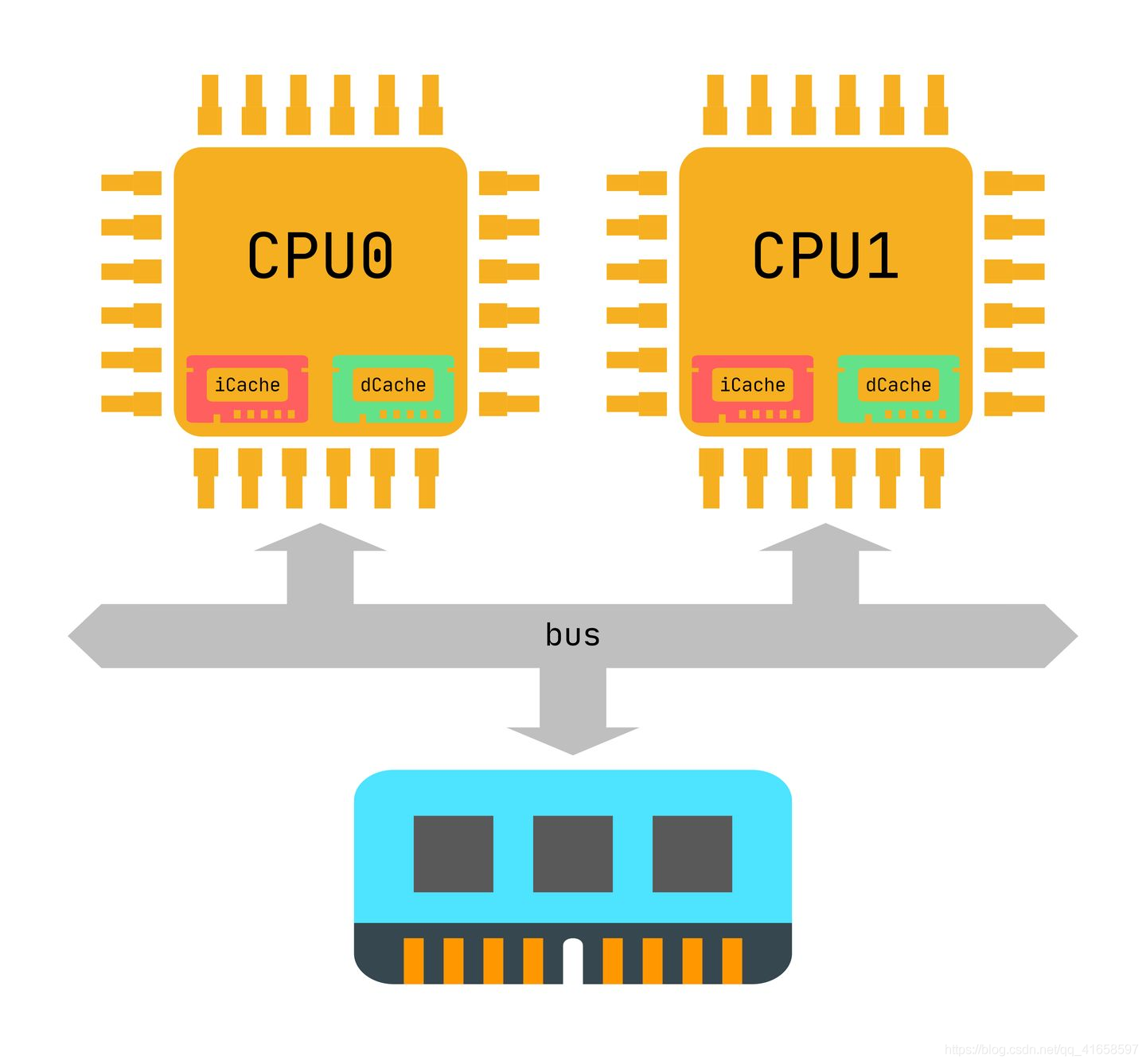
为什么要区分指令和数据?
iCache的作用是缓存指令,dCache是缓存数据。为什么我们需要区分数据和指令呢?原因之一是出于性能的考量。CPU在执行程序时,可以同时获取指令和数据,做到硬件上的并行,提升性能。另外,指令和数据有很大的不同。例如,指令一般不会被修改,所以iCache在硬件设计上是可以是只读的,这在一定程度上降低硬件设计的成本。所以硬件设计上,系统中一般存在L1 dCache和L1 iCache,L2
Cache和L3 Cache。
iCache歧义和别名
只要是Cache,就不能不提歧义和别名的问题。歧义问题一直是软件最难维护的,所以现在的硬件设计一般都采用物理地址作为tag。这就避免了歧义问题。别名问题是否存在呢?我们知道VIPT的cache是可能存在别名的情况。但是针对iCache的特殊情况(readonly),又会产生什么特殊的结果呢?其实我们之所以需要考虑别名问题,就是因为需要我们维护别名之间的一致性。因为可能在不同的cacheline看到不同的结果。那么iCache会存在别名,但是不是问题。因为iCache是只读的,所以即使两个cacheline缓存一个物理地址上的指令,也不存在问题。因为他的值永远是一致的,没有修改的机会。既然选用VIPT iCache即不存在歧义问题,别名也不是问题。那么我们是不是就不用操心了呢?并不是,我们最后需要考虑的问题是iCache和dCache之间的一致性问题。
iCache和dCache一致性
我们的程序在执行的时候,指令一般是不会修改的。这就不会存在任何一致性问题。但是,总有些特殊情况。例如某些self-modifying code,这些代码在执行的时候会修改自己的指令。例如gcc调试打断点的时候就需要修改指令。当我们修改指令的步骤如下:
1.将需要修改的指令数据加载到dCache中。
2.修改成新指令,写回dCache。
我们现在面临2个问题:
1.如果旧指令已经缓存在iCache中。那么对于程序执行来说依然会命中iCache。这不是我们想要的结果。
2.如果旧指令没有缓存iCache,那么指令会从主存中缓存到iCache中。如果dCache使用的是写回策略,那么新指令依然缓存在dCache中。这种情况也不是我们想要的。
解决一致性问题既可以采用硬件方案也可以采用软件方案。
硬件维护一致性
硬件上可以让iCache和dCache之间通信,每一次修改dCache数据的时候,硬件负责查找iCache是否命中,如果命中,也更新iCache。当加载指令的时候,先查找iCache,如果iCache没有命中,再去查找dCache是否命中,如果dCache没有命中,从主存中读取。这确实解决了问题,软件基本不用维护两者一致性。但是self-modifying code是少数,为了解决少数的情况,却给硬件带来了很大的负担,得不偿失。因此,大多数情况下由软件维护一致性。
软件维护一致性
当操作系统发现修改的数据可能是代码时,可以采取下面的步骤维护一致性。
1.将需要修改的指令数据加载到dCache中。
2.修改成新指令,写回dCache。
3.clean dCache中修改的指令对应的cacheline,保证dCache中新指令写回主存。
4.invalid iCache中修改的指令对应的cacheline,保证从主存中读取新指令。
操作系统如何知道修改的数据可能是指令呢?程序经过编译后,指令应该存储在代码段,而代码段所在的页在操作系统中具有可执行权限的。不可信执行的数据一般只有读写权限。因此,我们可以根据这个信息知道可能修改了指令,进而采取以上措施保证一致性。

![Melis4.0[D1s]:2.启动流程(GUI桌面加载部分)跟踪笔记](https://img-blog.csdnimg.cn/d389a0cf179f48b1a6cb5f951a9b19e4.png)