1 Mybatis流程解析概述
Mybatis框架在执行增伤改的流程基本相同, 很简单,这个大家只要自己写个测试demo跟一下源码,基本就能明白是怎么回事,查询操作略有不同, 这里主要通过查询操作来解析一下整个框架的流程设计实现。
2 Mybatis查询操作的基本流程
2.1 Mapper代理对象MapperProxy的创建流程

Mapper(实际上是一个代理对象)是从SqlSession中获取的, 因为SqlSession的实现类DefaultSqlSession类中存在Configuration类对象, 而我们在创建sqlSession对象的操作完成之后, configuration对象中已经存储了所有的mapper及其对应的代理对象之间的映射关系,如下图:
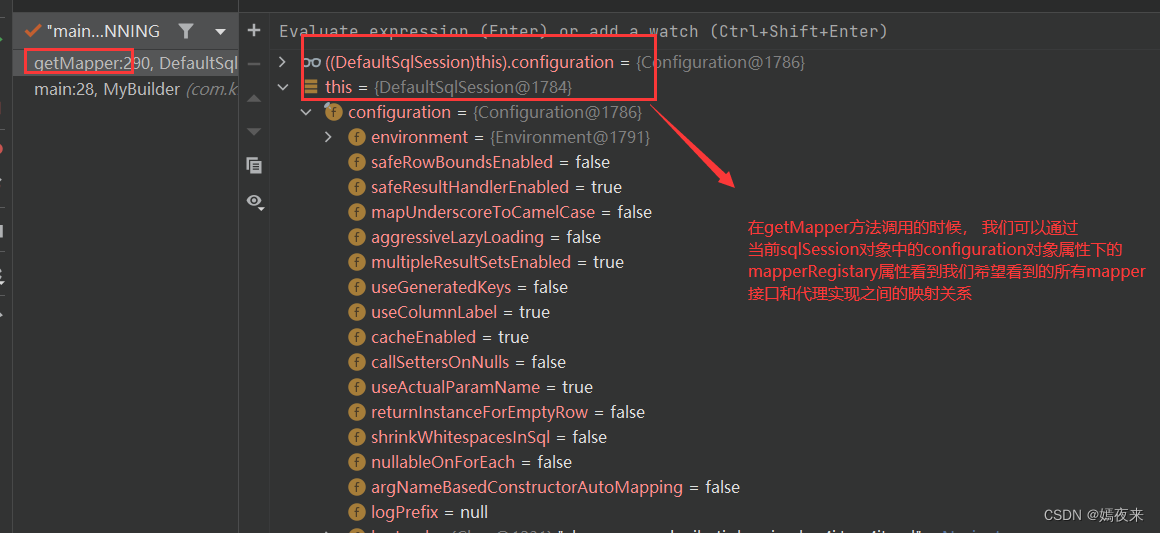
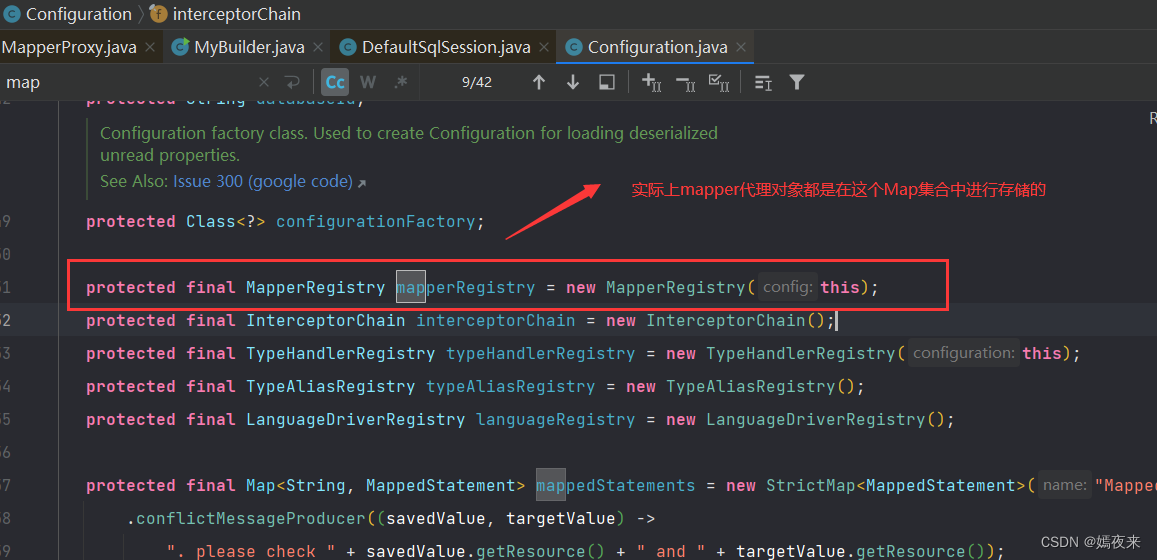
看看mapperRegistry如下图:
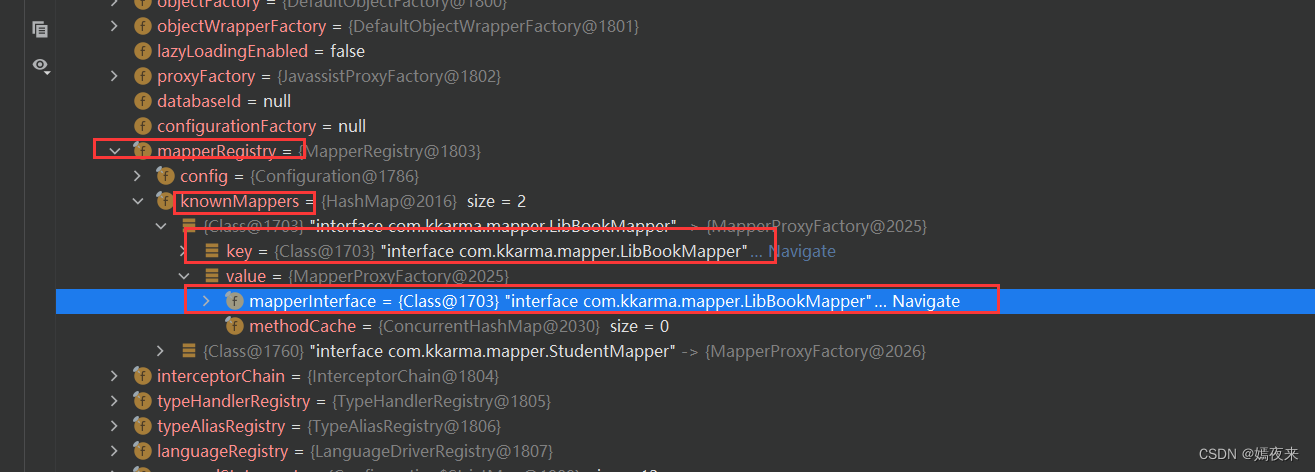
MapperRegistry类中创建代理对象的核心步骤如下
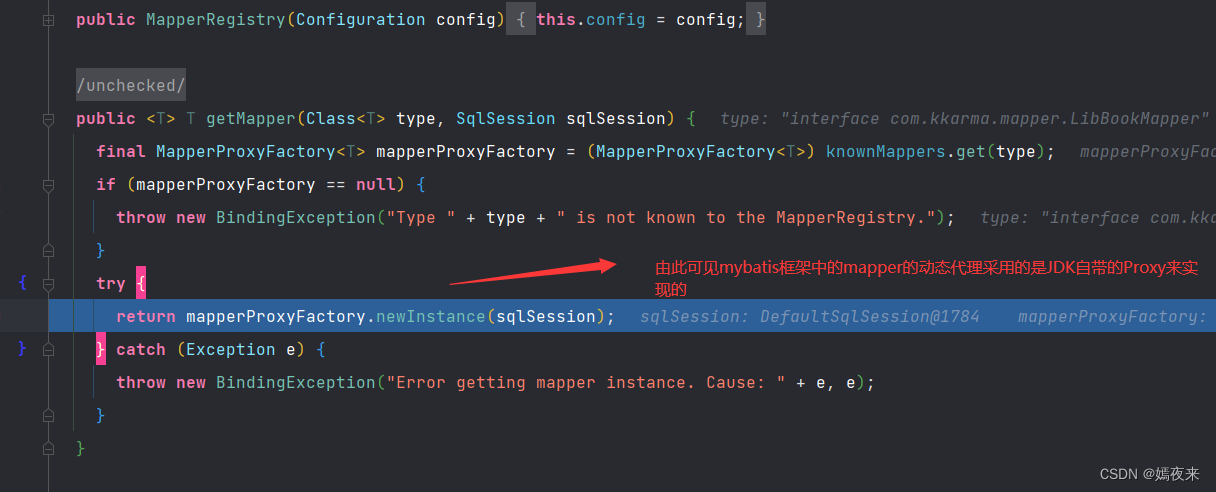
MapperProxyFactory类中的newInstance方法的调用
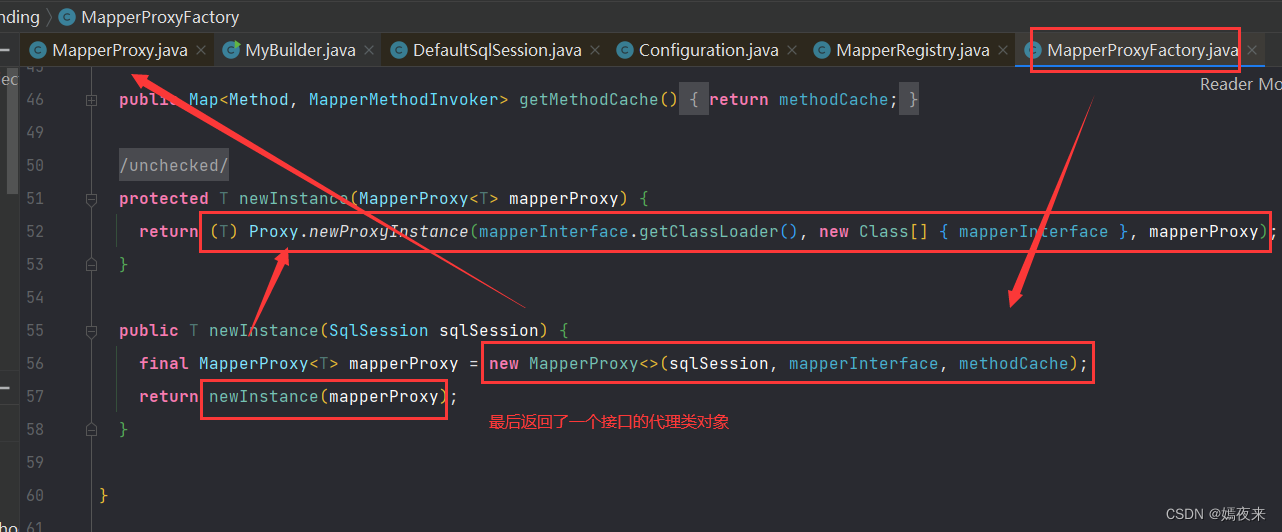
这里通过动态代理创建出目标mapper层的代理类对象并返回。
2.2 创建Mapper代理对象MapperProxy的调用流程
总结getMapper(Class clazz)方法创建动态代理对象的调用逻辑如下图:
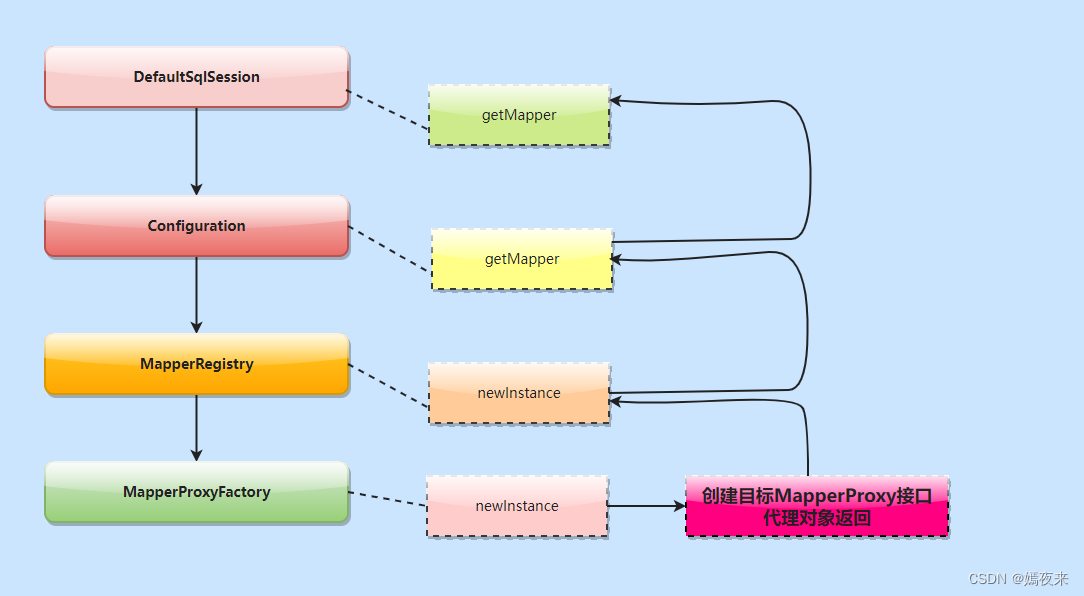
2.3 动态代理对象执行增删改查的核心流程
这里我们使用查询接口来进行流程剖析
在应用层, 我们会调用下面这行代码来实现查询, 现在我们来分析一下这行代码在Mybatis的源码中是如何执行的, 它究竟是如何实现查询我们想要的数据的功能的
List<LibBook> libBooks = mapper.selectBooksByCondition("T311.5/3-1", null, null, null);
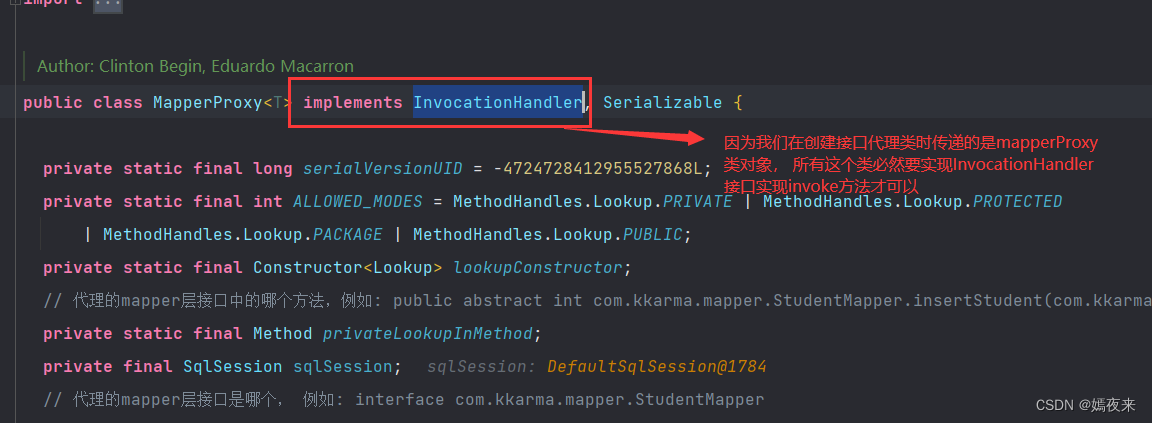
动态代理大家肯定都熟悉, 如果你要看源码, 连这点儿基础都没有, 建议不要硬看, 把java基础夯实了再来研究源码吧, 我们在使用Proxy创建动态对象时,比然要传递一个InvocationHandler接口的实现类或者匿名内部类对象,
2.1章节我们在创建动态代理类的时候,在MapperProxyFactory类中的newInstance方法中, 我们传递的InvocationHandler得实现类就是我们的MapperProxy类对象, 所以这个MapperProxy类必然实现了InvocationHandler接口, 我们验证一下是不是:
果然MapperProxy类实现了InvocationHandler接口并实现了invoke方法
下面我们调用Mapper接口中的方法selectBooksByCondition, 实际上都是通过MapperProxy.invoke()方法去执行的。
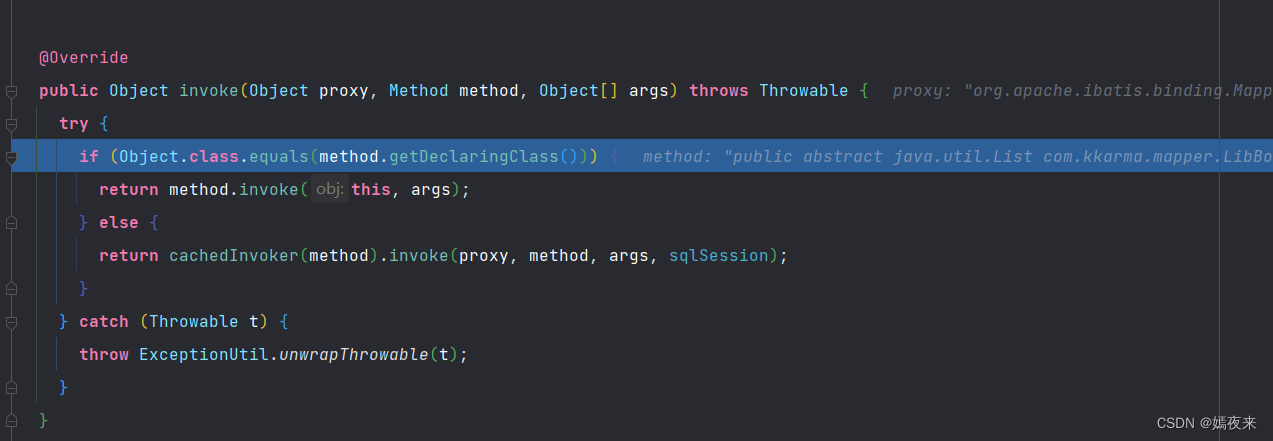
2.3.1 MapperProxy.invoke()方法调用解析
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
/**
* 这里给大家解释一下这个invoke判断里面加这个判断的原因:
* 大家都知道Object对象默认已经实现了很多方法, 我们的Mapper接口在进行定义的时候, 可能定义了静态方法、 默认方法以及抽象方法
* 因此在创建了动态代理对象的时候, 这个动态代理类肯定也包含了很多的方法, 从Object类继承的方法, 从接口继承的默认方法,
* 以及从接口继承抽象方法需要实现取执行SQL语句的方法
*
* 这个if分值判断的只要目的在将无需走SQL执行流程的方法如(toString/equals/hashCode)等先过滤掉
* 然后再抽象方法及默认方法中通过一个接口MapperMethodInvoker再进行一次判断,找到所有需要执行SQL的方法通过PlainMethodInvoker的invoke
* 方法取执行SQL语句获取结果,能够加快获取 mapperMethod 的效率
*/
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
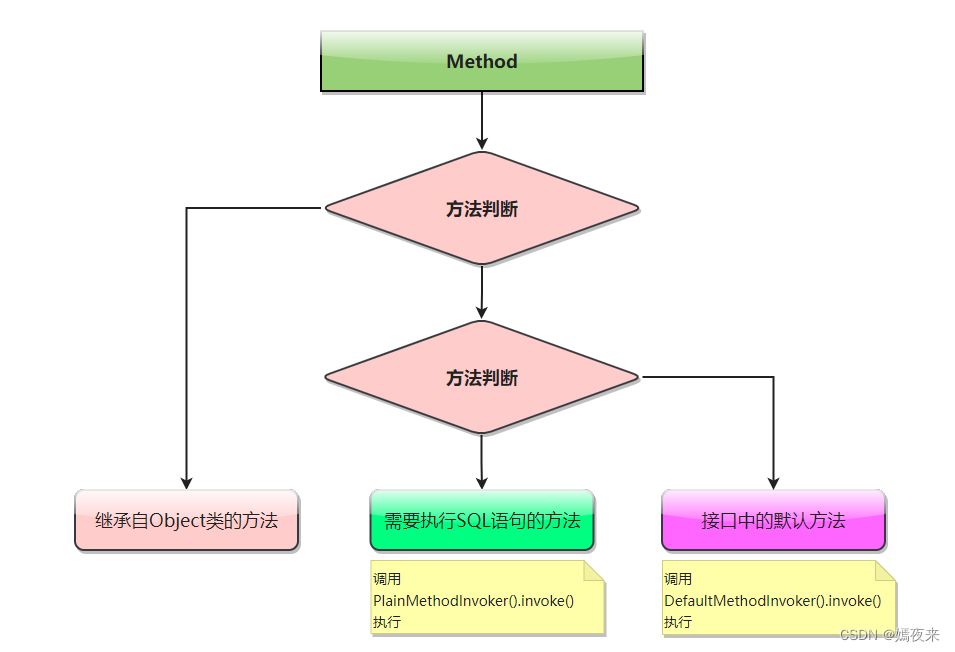
PlainMethodInvoker().invoke()方法会调用MapperMethod类中的execute()方法
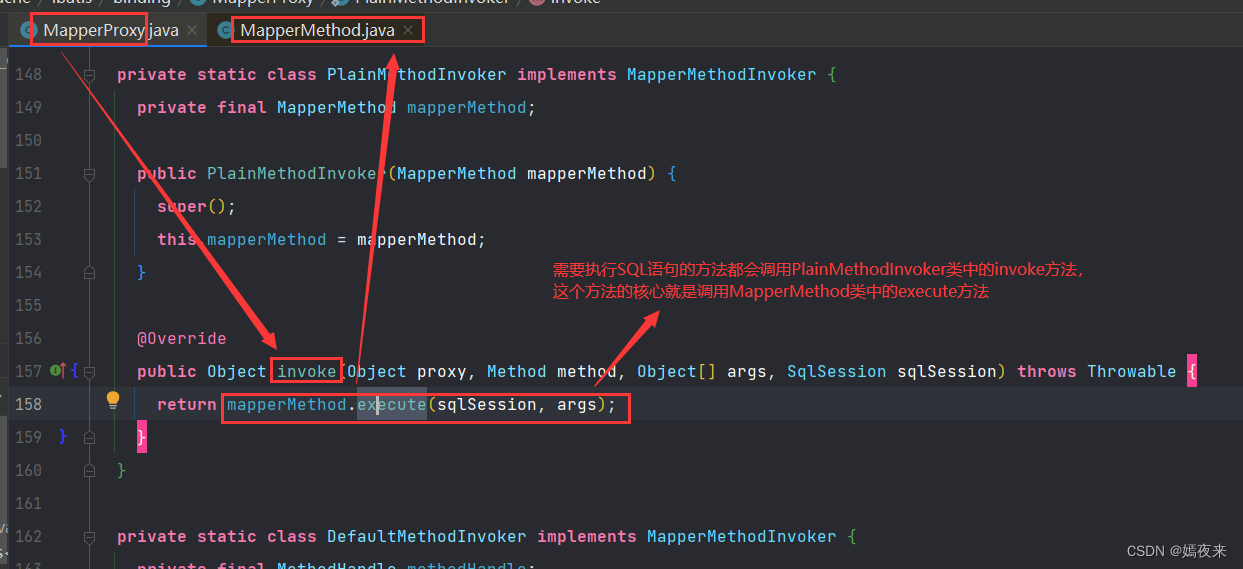
2.3.2 MapperMethod.execute()方法调用解析
MapperMethod类中的execute()方法具体执行逻辑如下
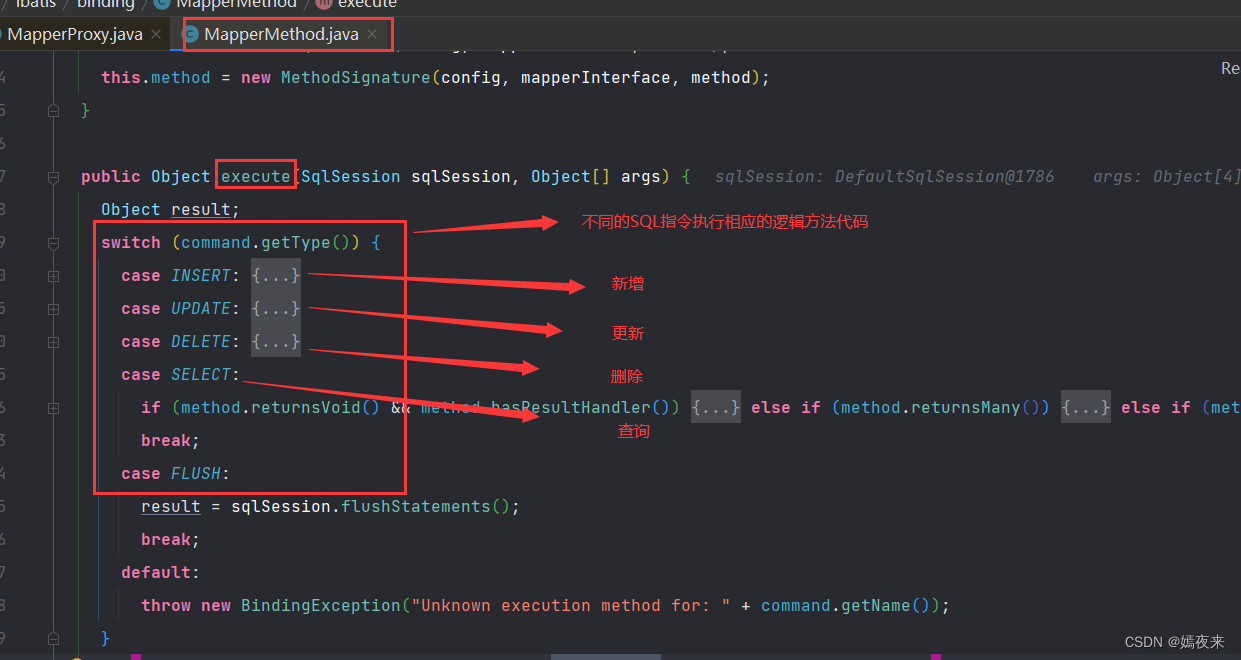
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
// 插入操作
case INSERT: {
// 如果你用过Mybatis的话, 你一定清楚, Mybatis的中参数传递的方式有以下几种
// 第一种: [arg0,arg1,...]
// 第二种: [param1,param2,...]
// convertArgsToSqlCommandParam(args)方法就是实现这种映射
// 举例说明:我之前传递的参数是一个Book对象{"bookId": "val1", "bookIndexNo":"val2", "bookName":"val3"}
// 经过convertArgsToSqlCommandParam()方法处理之后得到{"bookId": "val1", "bookIndexNo":"val2", "bookName":"val3", "param1": "val1", "param2":"val2", "param3":"val3"}
Object param = method.convertArgsToSqlCommandParam(args);
// 执行SQL操作并对返回结果进行封装处理
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
// 更新操作
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
// 执行SQL操作并对返回结果进行封装处理
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
// 删除操作
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
// 执行SQL操作并对返回结果进行封装处理
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
// 查询操作的情况比较复杂, 需要分情况逐一处理
if (method.returnsVoid() && method.hasResultHandler()) {
// 如果查询操作的返回为空并且方法已经指定了结果处理器时,执行以下语句
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
// 如果查询操作的返回返回结果为List集合, 执行以下语句
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
// 如果查询操作的返回返回结果为Map集合, 执行以下语句
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
// 如果查询操作的返回返回结果为Cursor, 执行以下语句
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
// 如果查询操作的返回返回结果为单个对象并且指定返回类型为Optional, 则将返回结果封装成Optional对象返回
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
当前我们执行的查询语句, 返回的结果列表是一个List, 所以调用的是executeForMany(sqlSession, args);
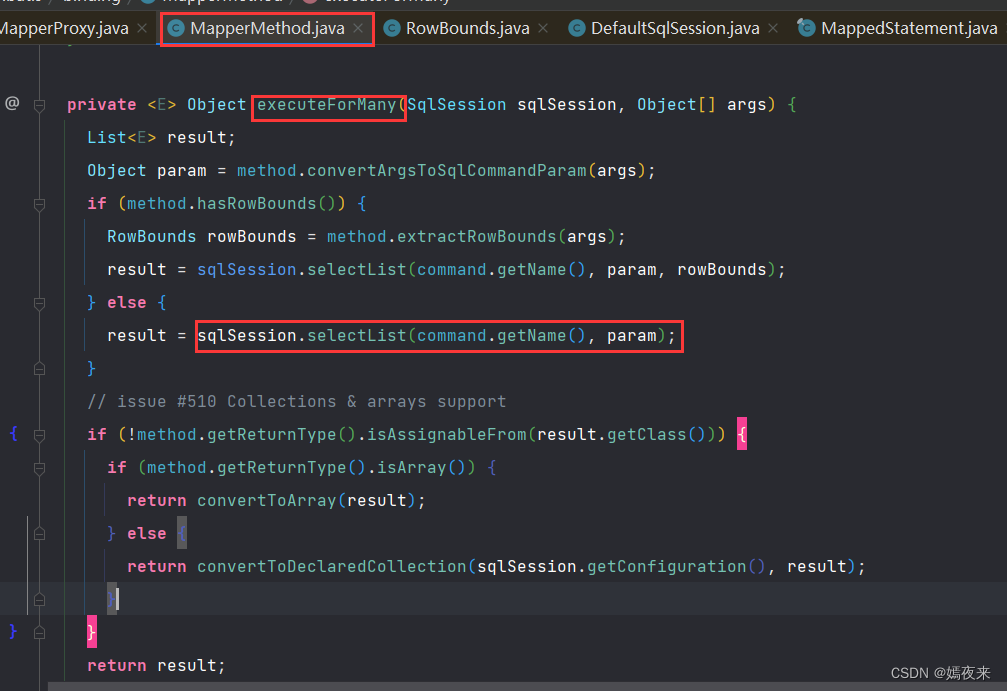
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {
List<E> result;
Object param = method.convertArgsToSqlCommandParam(args);
// 这里是判断你的mapper层接口方法是否传递了RowBounds对象,根据是否传递了RowBounds对象来调用sqlSession对象的selectList的不同传参的重载方法
// 这个RowBounds对象主要是来进行分页功能,会将所有符合条件的数据全都查询出来加载到内存中,然后在内存中再对数据进行分页(当数据量非常大的时候, 就会发生OOM, 一般不推荐使用)
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.selectList(command.getName(), param, rowBounds);
} else {
// 我们这里没有传递RowBounds对象, 所以调用的是这个方法
result = sqlSession.selectList(command.getName(), param);
}
// issue #510 Collections & arrays support
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
if (method.getReturnType().isArray()) {
return convertToArray(result);
} else {
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
}
return result;
}
2.3.3 executor.query()执行器执行查询的逻辑流程解析
2.3.3.1 创建PreparedStatement对象
我们在创建configuration类对象的时候,已经设置过默认的executor对象类型就是Simple
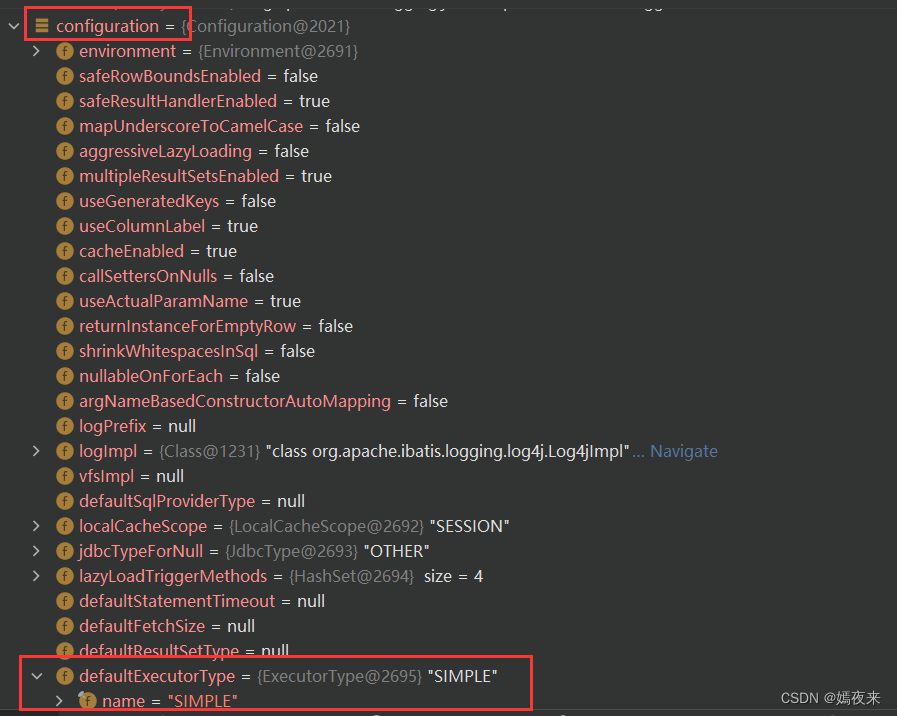
那么这里的executor应该是SimpleExecutor对象啊, 但是实际上并不是, 这里的executor对象是CachingExecutor对象 这里大家肯定会有疑问, 在debug的过程中, 我明明没有看到有创建CachingExecutor对象啊, 这个对象是啥时候创建的? 为啥不是SimpleExecutor对象对象啊?
这里解答一下, 下面这两行代码,只要你使用过Mybatis框架, 肯定不陌生
SqlSessionFactory factory = factoryBuilder.build(ins);
SqlSession sqlSession = factory.openSession(true);
factory.openSession(true)这个方法调用我们跟进去看看
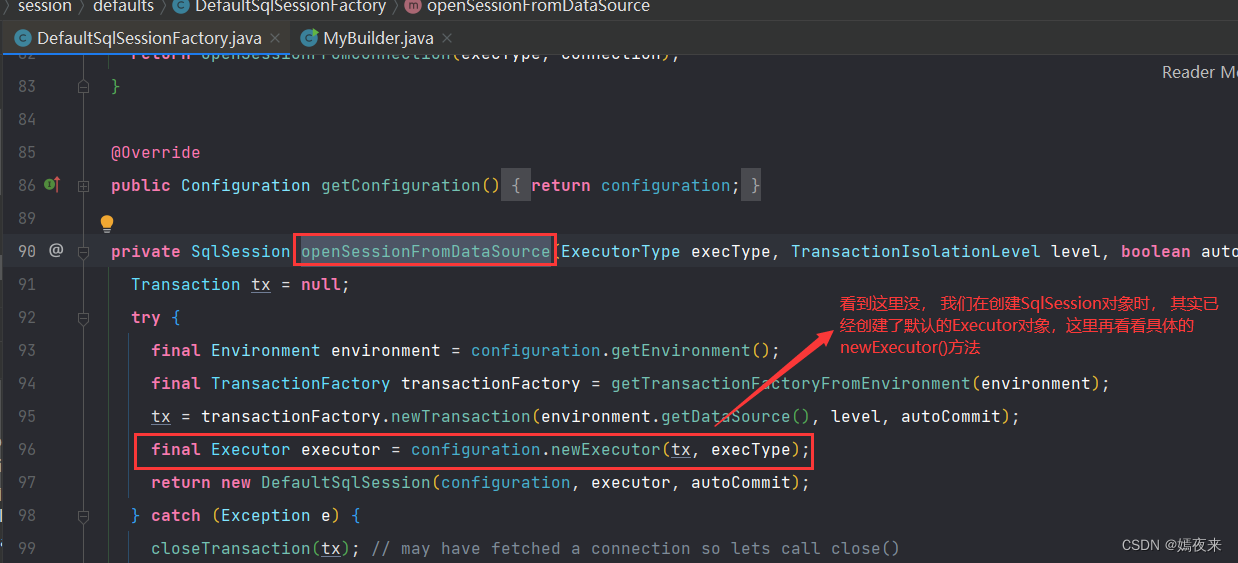
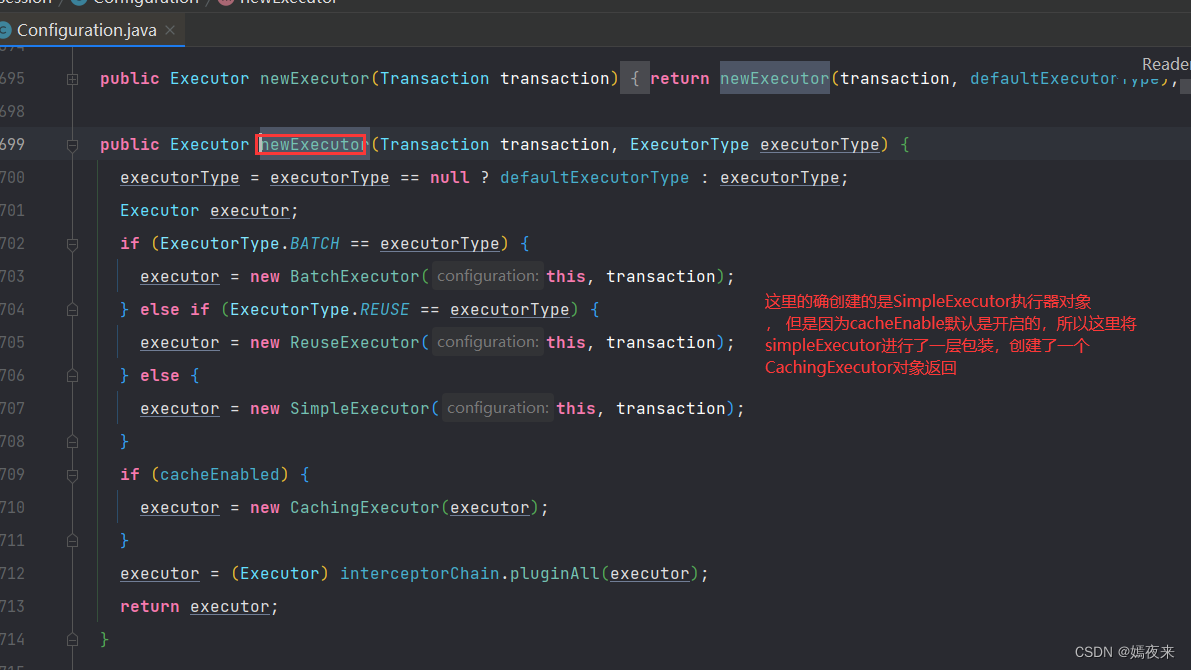
好了以上就是executor是什么时候创建的以及为什么明明应该是simpleExecutor,但是实际却是cachingExecutor对象的原因。
下面接着说查询方法的执行过程
sqlsession对象会调用执行器的查询方法开始查询
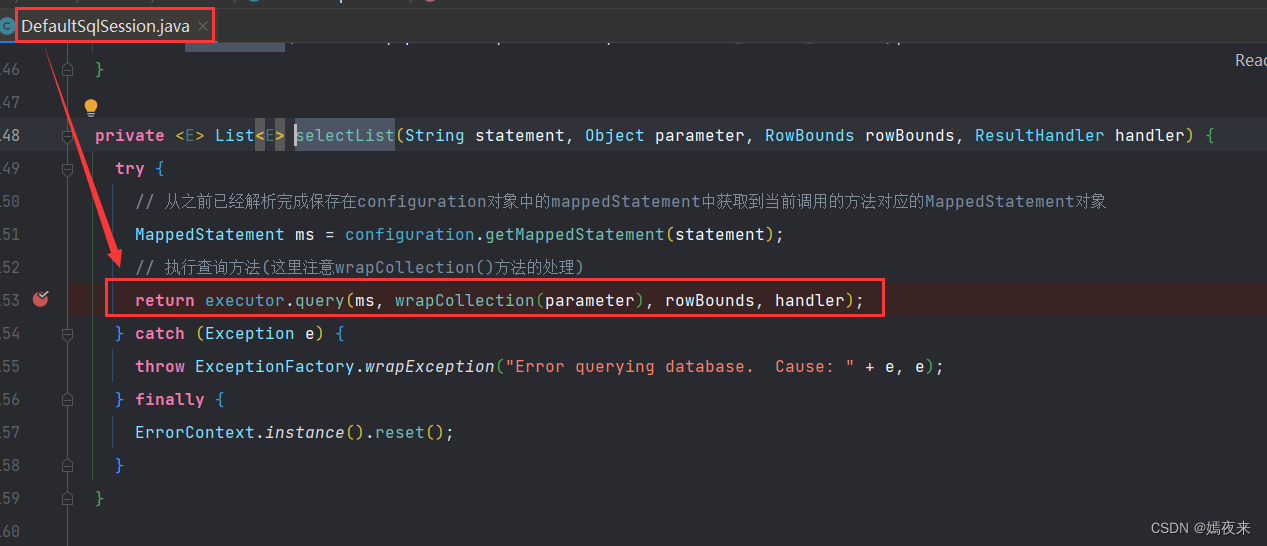
这里调用了委托者SimpleExecutor对象的query()方法,但是SimpleExecutor对象没有query方法, 就调用了父类BaseExecutor里面query()方法
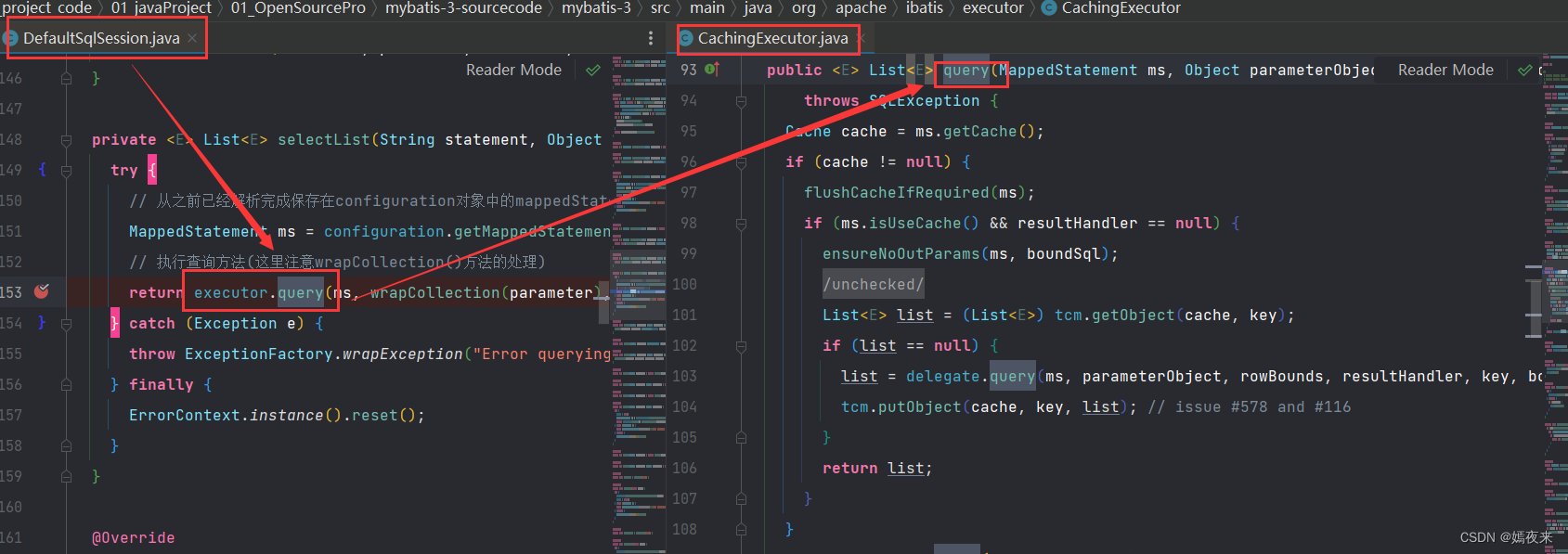
query()方法中又调用了父类BaseExecutor里面queryFromDatabase()方法
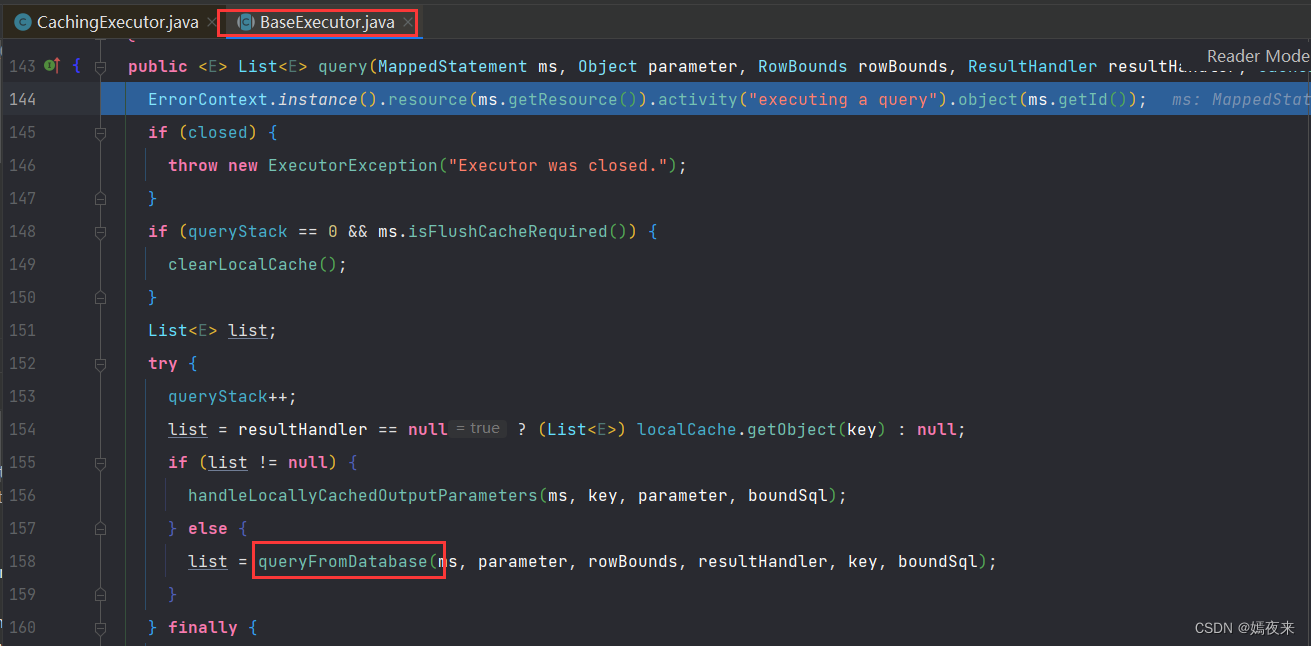
queryFromDatabase()()方法中又调用了父类BaseExecutor的抽象方法doQuery()方法,父类中没有实现该方法,但是子类SimpleExecutor对该方法进行了重写, 调用子类SimpleExecutor中的doQuery()方法执行
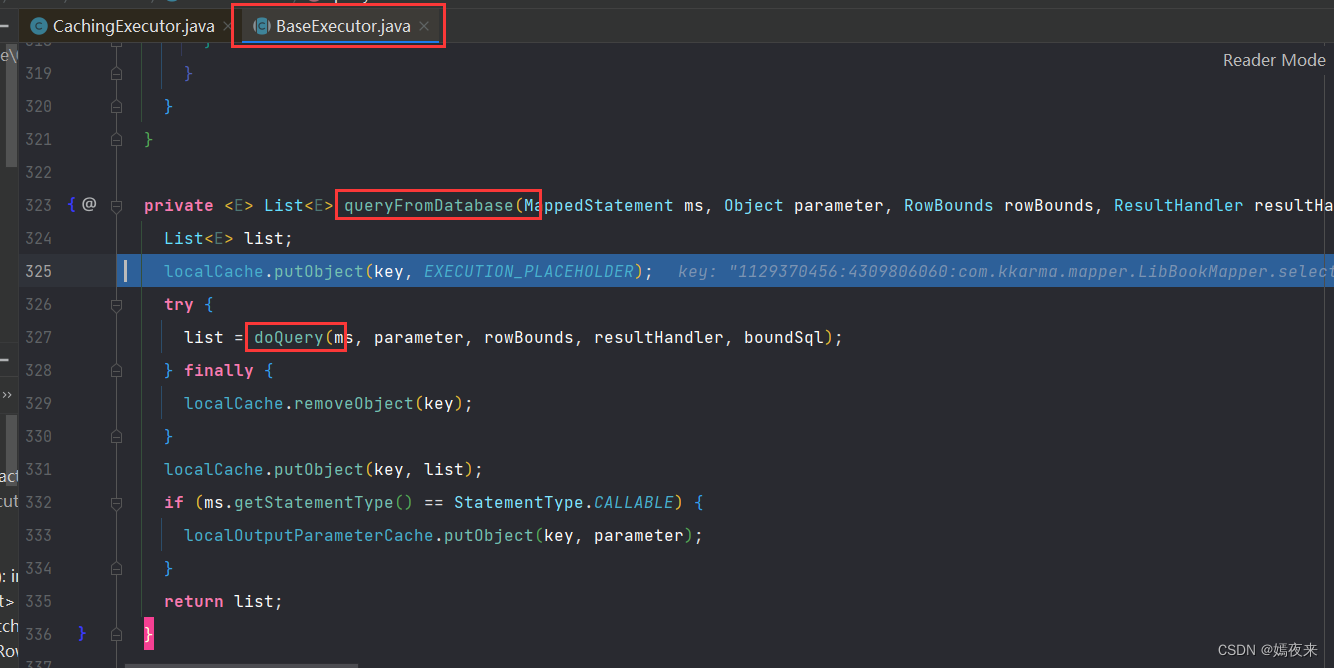
子类SimpleExecutor中的doQuery()方法如下图:
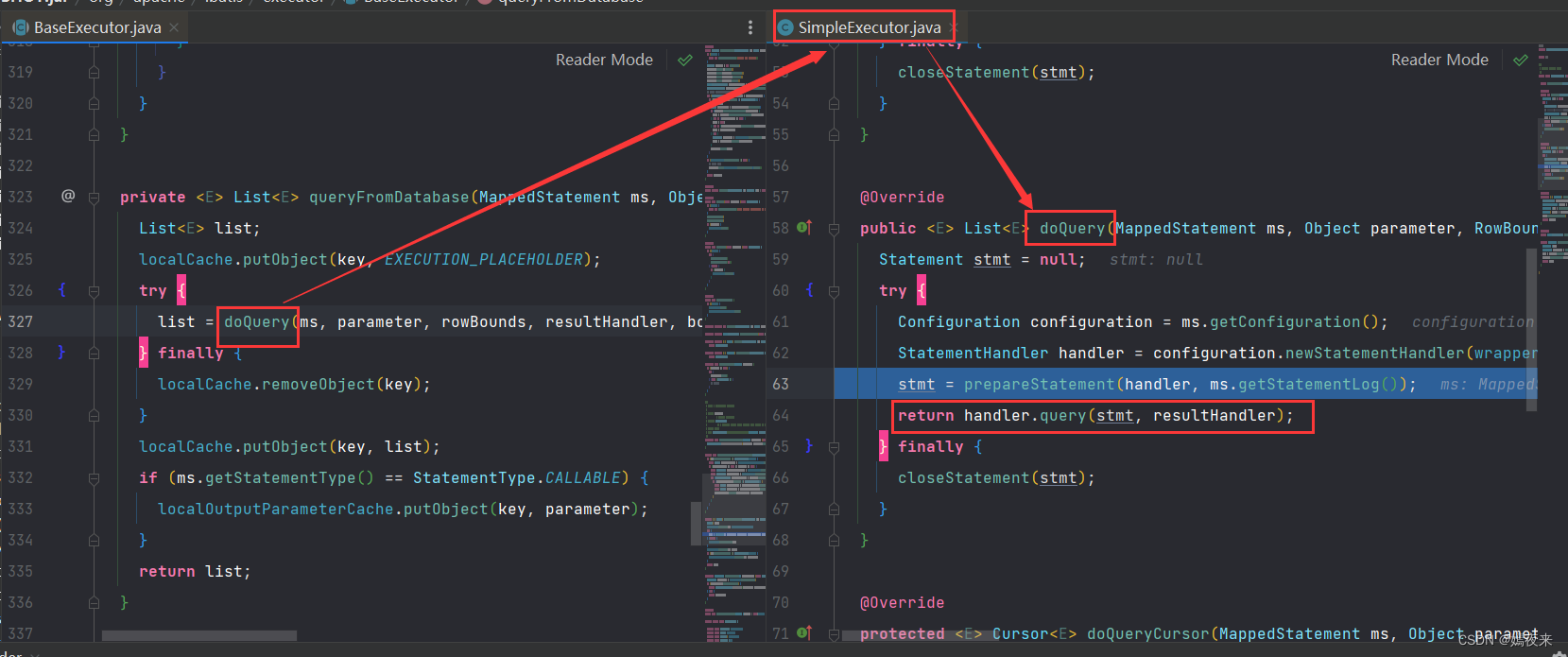
在SimpleExecutor类中的doQuery()方法中StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);这行代码执行完成的时候,当前代理方法的ParameterHandler对象和ResultSetHandler对象也会创建并扩展完成,如果我们又在配置文件中自定义ParameterHandler、ResultSetHandler、StatementHandler在这个过程都会被通过拦截器注册并依次调用。
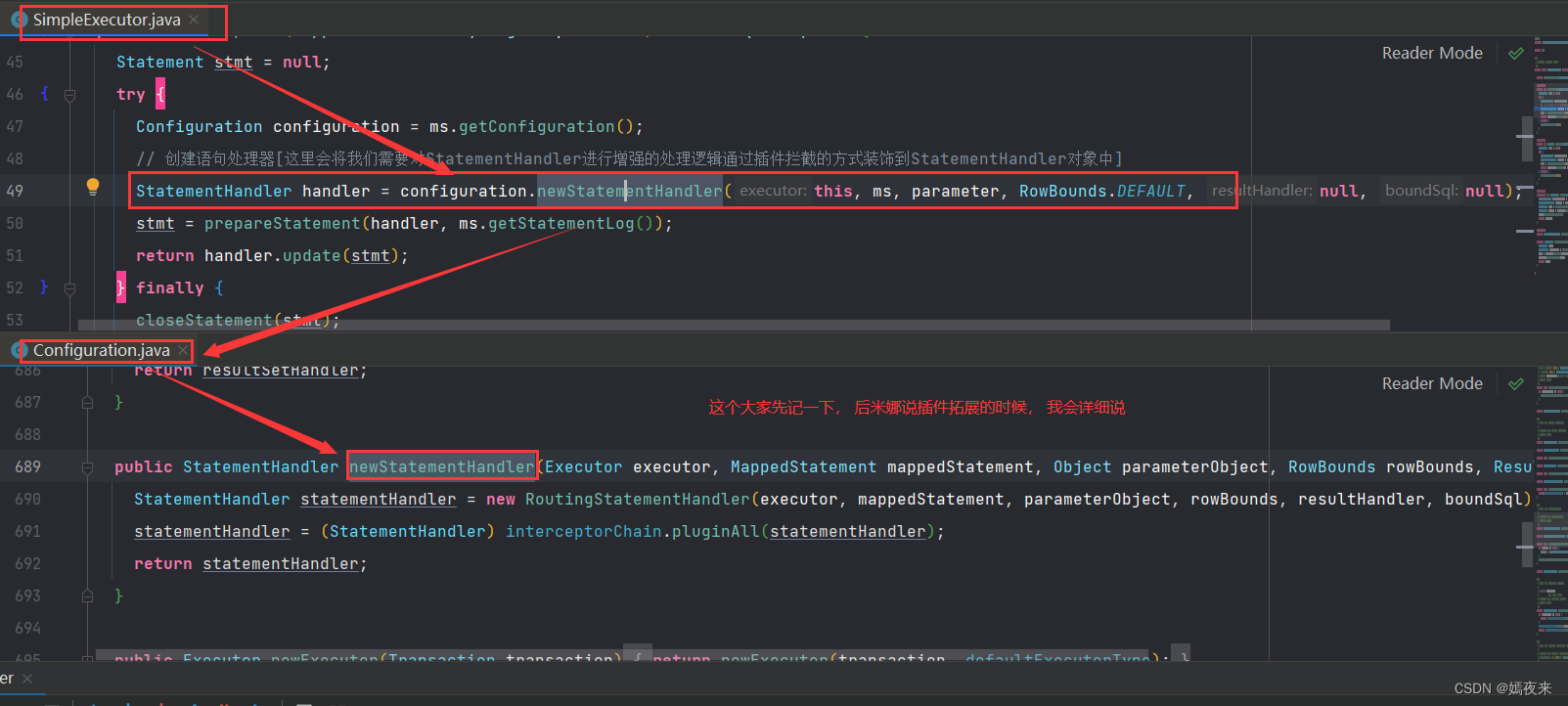
RoutingStatementHandler里面没有任何的实现,是用来创建基本的StatementHandler的。这里会根据MappedStatement里面的statementType(一共有三种:STATEMENT、PREPARED、CALLABLE))决定StatementHandler的类型,MappedStatement对象默认是PREPARED。
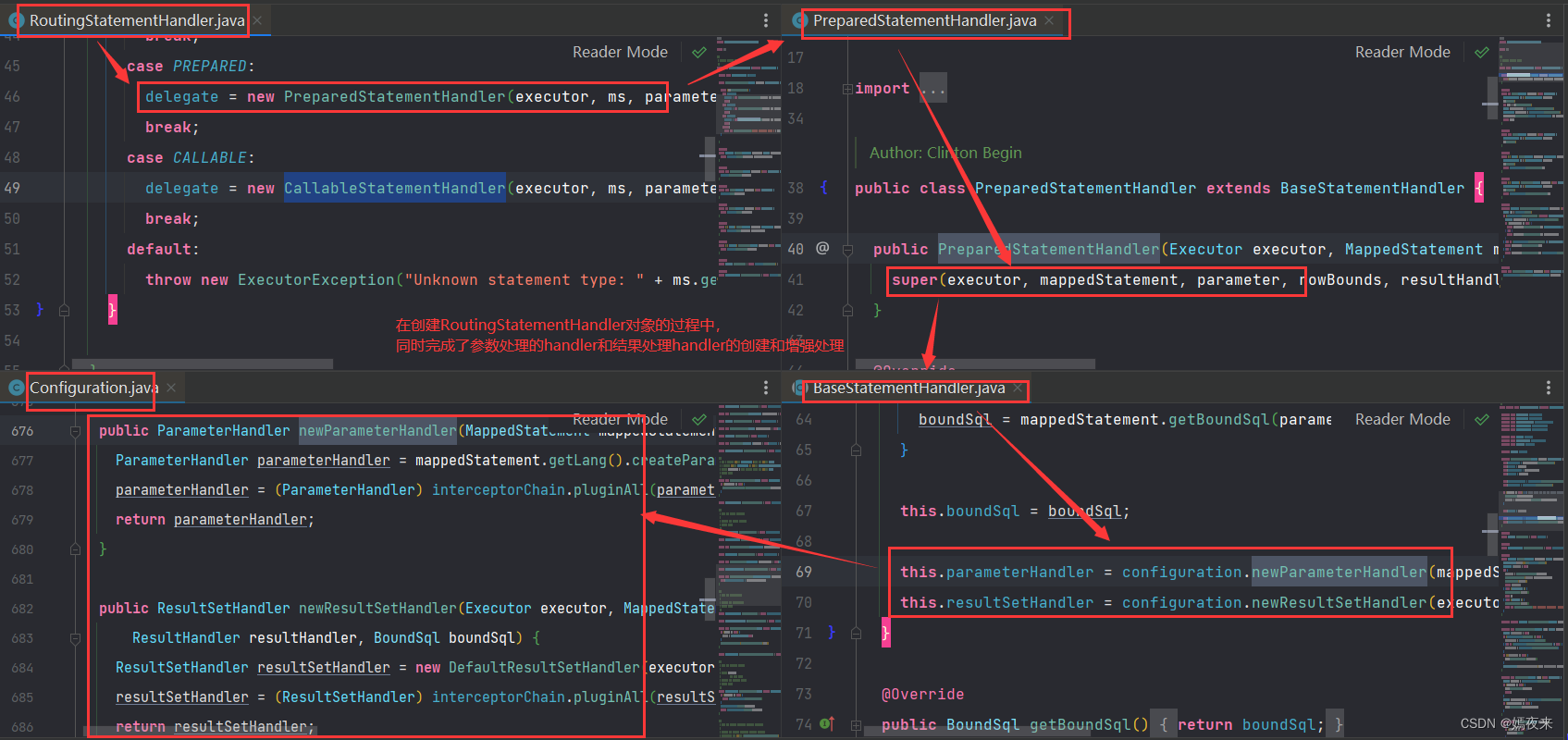
在SimpleExecutor类中的doQuery()方法中StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);Configuration类中的如下方法将被调用
/** 拦截参数处理器:通过拦截器拓展插件功能对ParameterHandler的基础功能进行增强 */
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
/** 拦截结果映射处理器:通过拦截器拓展插件功能对ResultSetHandler的基础功能进行增强 */
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
/** 拦截SQL语句处理器:通过拦截器拓展插件功能对StatementHandler的基础功能进行增强 */
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
RoutingStatementHandler对象创建完成之后会调用prepareStatement()方法创建Statement对象
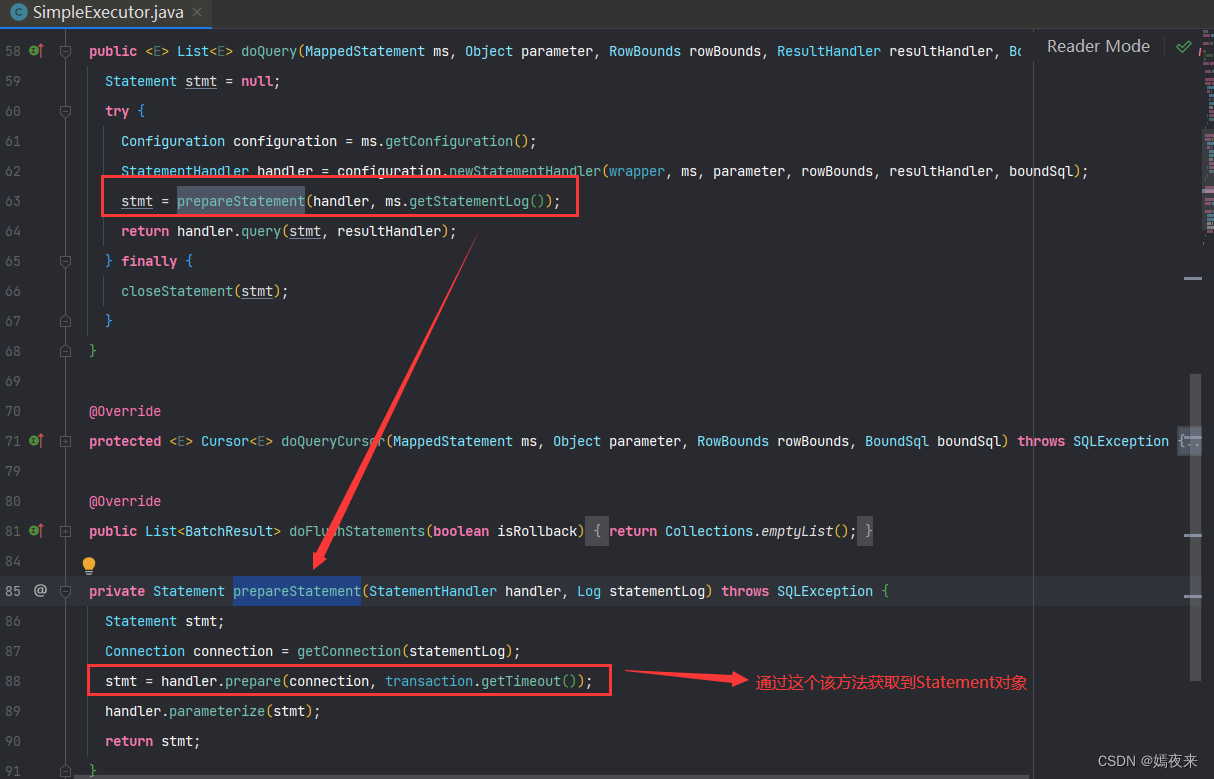
2.3.3.2 Statement中的入参处理
在SimpleExecutor对象中再创建出最终要执行的Statement对象之后, 就是处理入库真实替换SQL语句中的占位符了,主要是通过statementHandler.parameterize(stmt)来实现的, 具体的还是调用了PreparedStatementHandler类中的.parameterize(stmt)方法来处理
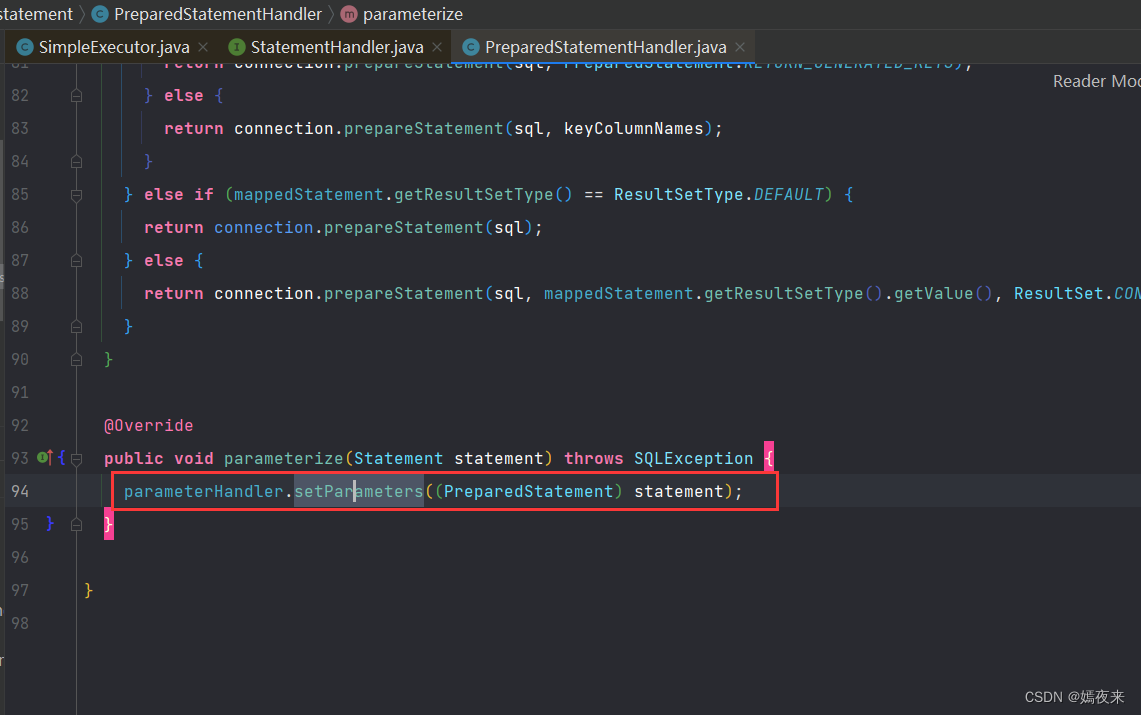
这里就用到了我们的ParameterHandler对象了, 通过setParameters()方法完成参数替换。
具体的方法实现有兴趣可以自行研究
2.3.3.3 ResultSet结果及处理
SimpleExecutor类的handler.query(stmt, resultHandler)方法最终会调用PreparedStatementHandler的query方法执行SQL语句并返回结果
PreparedStatementHandler的query方法会调用PreparedStatement.execute()执行SQL语句,返回查询结果集
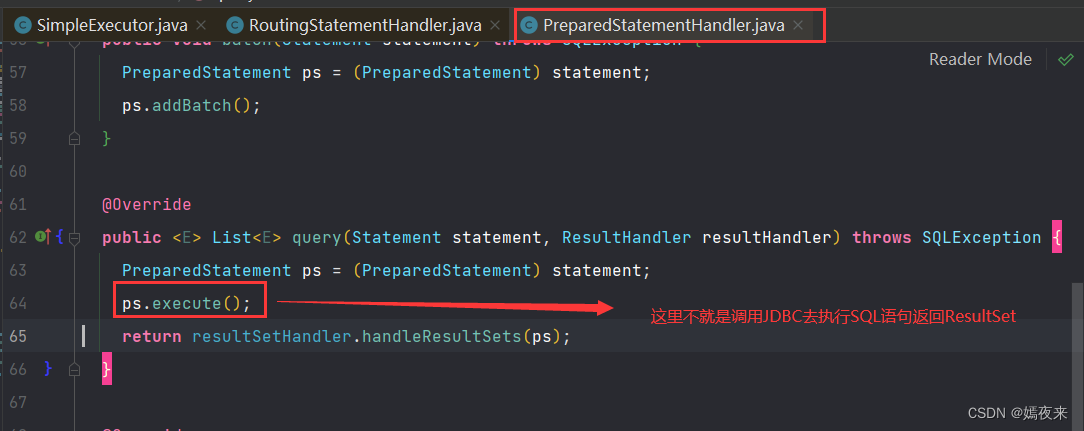
DefaultResultSetHandler.handleResultSets()方法会将查询结果集处理成Java中的List对象返回。
3 查询方法的调用逻辑图

4 源码阅读过程中的笔记
MapperProxy
invoke
MapperMethod
execute()
executeForMany()
DefaultSqlSession
selectList()
CachingExecutor
query()
1、生成二级缓存KEY
createCacheKey()
1、将缓存KEY作为参数传递,调用重载query()方法
query()
1、从MappedStatement对象中获取Cache对象
2、如果Cache对象不是null, 说明有二级缓存
2.1、判断MappedStatement对象的isFlushCacheRequired属性是为true, 如果为true,刷新缓存
2.2、判断MappedStatement对象是否使用缓存(isUseCache属性是否为true),并且resultHandler属性默认为null, 如果两者都满足, 直接从Cache对象中通过缓存KEY查询结果数据list
2.3、判断结果数据list是否为空,如果为空,从数据库中查询出结果,然后将查询结果放置到Cache对象中的缓存KEY下,最后把查询结果list返回
3、如果Cache对象是null, 直接从数据库中查询出结果(调用BaseExecutor.query())
BaseExecutor
createCacheKey()
query()
1、判断当前的queryStack是否为0,并且MappedStatement对象的isFlushCacheRequired属性是为true,满足条件就清空一级缓存,否则跳过
2、判断MappedStatement对象的resultHandler属性是否为null,满足条件就直接从一级缓存中通过缓存KEY查询结果数据list
2.1、如果结果数据list不为空,调用handleLocallyCachedOutputParameters()方法对结果进行处理(主要是因为如果调用的是存储过程,执行的结果需要接受并处理)
2.2、如果结果数据list为空,调用queryFromDatabase()直接从数据库中进行查询结果
3、处理嵌套查询
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 嵌套查询会借助一级缓存,所以一级缓存不能关闭
// 嵌套查询是肯定会延迟加载的,存入DeferredLoad类,避免重复的查询执行
// 执行嵌套查询时,当有结果值就直接存入,没有就存入一个占位符,这样相同的嵌套查询,在一级缓存中只会存在一个,当所有的都处理完成以后,然后再最终处理所有的延迟加载
4、返回最终结果
queryFromDatabase()
1、首先通过缓存KEY在缓存对象中先开辟空间,因为缓存结果还没有从数据库中查询,先设置一个占位符告诉其他人这个坑已经有人占了
2、调用doQuery()方法查询数据
3、将第一步的缓存对象清除(因为它没有真正的保存数据对象,只是在我查询数据还没有返回数据结果的这段时间假装已经有缓存了)
4、将真正从数据中查询出来的数据对象放入一级缓存,然后然后结果list
SimpleExecutor
doQuery()
1、创建StatementHandler对象
1.1 MappedStatement对象中默认的statementType对象是"PREPARED", 这里会执行new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
1.2 new PreparedStatementHandler的构造方法中调用了父类BaseStatementHandler的构造方法
1.3 父类BaseStatementHandler的构造方法中做了parameterHandler和resultSetHandler的初始化操作,调用了configuration.newParameterHandler()和configuration.newResultSetHandler()
方法进行对象创建,这里默认都是创建的DefaultParameterHandler和DefaultResultSetHandler对象
2、prepareStatement()
2.1 创建Connection连接对象
2.2 执行statementHandler对象的prepare()方法,返回Statement对象
// 2.2.1 调用RoutingStatementHandler类下的prepare()方法,返回Statement对象
// 2.2.2 调用BaseStatementHandler类下的prepare()方法,返回Statement对象
2.3 执行statementHandler对象的parameterize()方法
// 2.3.1 调用RoutingStatementHandler类下的parameterize()方法
// 2.3.2 调用PreparedStatementHandler类下的parameterize()方法
2.4 返回Statement对象
3、调用StatementHandler的query()方法
3.1 调用RoutingStatementHandler类的query()方法
3.2 调用PreparedStatementHandler类的query()方法
BaseStatementHandler
这个方法在创建
prepare()
1、调用instantiateStatement()创建Statement对象
1.1 调用PreparedStatementHandler类下的instantiateStatement()方法创建Statement对象
2、调用setStatementTimeout()设置执行和事务的超时时间
3、调用setFetchSize()设置驱动的结果集获取数量(fetchSize)
4、最后返回Statement对象
PreparedStatementHandler
instantiateStatement()
1、调用JDBC的connection.prepareStatement(sql)方法创建出一个PreparedStatement对象返回
parameterize()
1、调用parameterHandler对象的setParameters()方法将PrepareStatement对象中的SQL语句中的参数占位符都替换成传入的参数值
1.1 调用DefaultParameterHandler类的setParameters()方法
1.2 遍历所有的ParameterMapping对象,依次替换所有的占位符为实际的传入的参数值
query()
1、获取到PreparedStatement对象
2、调用PreparedStatement。execute()执行SQL语句
3、调用DefaultResultSetHandler类的handleResultSets()方法处理查询结果集
DefaultResultSetHandler
handleResultSets()
handleResultSet()
handleRowValues()
handleRowValuesForSimpleResultMap
getRowValue()
applyPropertyMappings()方法完成从ResultSet结果集中的每一个行数据和Java对象之间的映射
storeObject() 将getRowValue()处理完成的Objcet数据添加到List集合