目录
1.hash code
2.数据结构
3.初始化
4.存取
4.1.put
4.2.get
5.迭代
6.扩容
7.JDK1.7版本存在的问题
7.1.性能跌落
7.2.循环链表
8.散列运算
9.扰动函数
1.hash code
hash code是使用hash函数运算得到的一个值,是对象的身份证号码,用于对象的辨重。在同一运行周期,对同一个对象多次调用hashcode(),只要是用于equals()的内容未变,那么每次得到的hash码也应该不变。,但不同运行周期间hash码可能会不同。
hash函数是将任意长度的输入通过散列算法变换成固定长度的输出的一个处理过程,hash函数只是个概念,其具体的实现各有不同。如果不同的输入产生了相同的输出,称为产生了“hash碰撞”,而优质的hash函数力求的就是不同的输入产生不同的输出,即减少碰撞。
2.数据结构
HashMap是个无序不可重复的键值映射,线程不安全
底层维护一个内部类——node(1.7叫Entry,1.8叫Node):
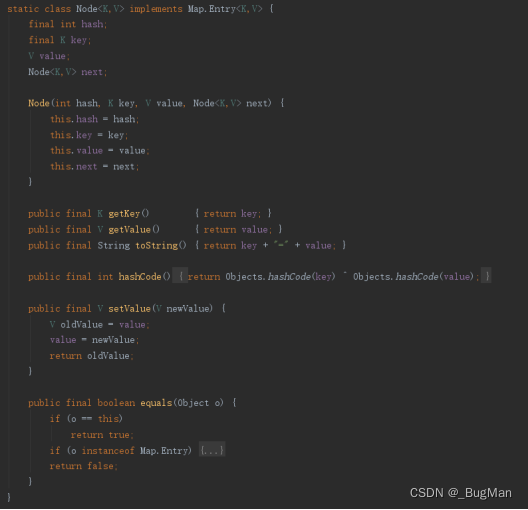
1.7及其以前版本,底层为数组+链表。1.8及其以后版本底层为数组+链表/红黑树。
允许key或者value为null,构造函数被调用的时候默认产生一个底层长度为16的Node类型的数组元素。
3.初始化
调用默认构造,不会实例化出数组,首次put操作时会开辟出一个长度为16的数组,也就是说hashmap的数组默认初始长度为16。
可以调用相应构造函数在实例化的时候指定为其他值,官方要求值为2的N次方,如果传入的值不是2的N次方,会就该值向上取一个2的N次方数。
4.存取
4.1.put
kv对存放进来的时候会被封装成Node类型,然后调用key的hashcode方法得到哈希码,
将这个hash码传到内置hash()中进行散列运算,得到一个散列值,然后将散列值与数组length进行运算最终得到该Node存放在位置的下标。
然后可能有两种情况:
1.如果该位置为null,直接放入。
2.如果该位置有node了,key不同,就直接挂在该node的后面,如果key相同,直接替换掉(map辨重的核心操作)
注意:
key相同,hashcode肯定相同,运算出的下标肯定也相同
key不同,hash函数可能产生碰撞,hashcode也可能相同,运算出来的下标可能也相同,
元素放入的顺序,在哈希表中被读出的顺序不一定相同。
4.2.get
根据传进来的key的hashcode方法产生的hash码做和put流程一样的散列运算然后和数组长度运算,得到该key应该所在的数组下标位置。实现了快速查找。
5.迭代
hashmap实现两种遍历方法:
1.keyset,返回值会封装在set里面,内含所有key。

2.entryset,所有entry会封装在set里面


6.扩容
触发扩容的前提是达到负载因子,即触发扩容的阈值,默认为0.75,即数组达到3/4的空间被使用就会触发扩容。hash桶(数组)会被扩容为原来的2倍。

扩容采用复制迁移的手段实现:
- 开辟出一个新数组。
- 将老数组上的所有元素rehash(),计算出一个新的hash值,然后对新数组length取模,计算出该元素应该在新数组上的存放位置。
- 迁移至新数组,迁移工作由transfer()方法完成。
7.JDK1.7版本存在的问题
7.1.性能跌落
当挂在一个位置上的节点过多,链表过长时会造成性能跌落。
7.2.循环链表
JDK1.7版本在扩容迁移时采用头插法,在并发的环境下会造成循环链表。
头插法:
从头开始取老数组上挂的链表,向新数组上挂时每次都挂在新数组链表的头部。
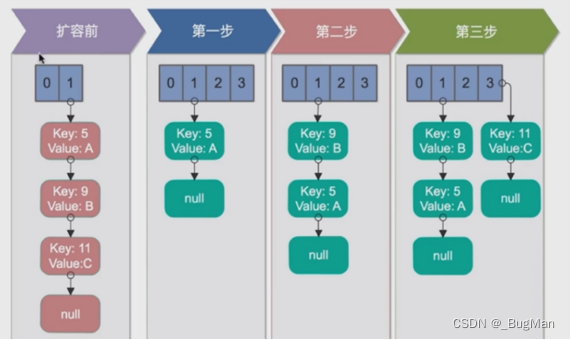
并发:
几个线程并发的访问同一个HashMap时,在几乎同一时间发现HashMap需要扩容,于是几个线程对同一个HashMap进行扩容迁移操作。
过程:
1.7的transfer方法,遍历原来table中每个位置的链表,并对每个元素进行重新hash,在新的newTable找到归宿,并插入。

整个循环链表产生的过程如下:
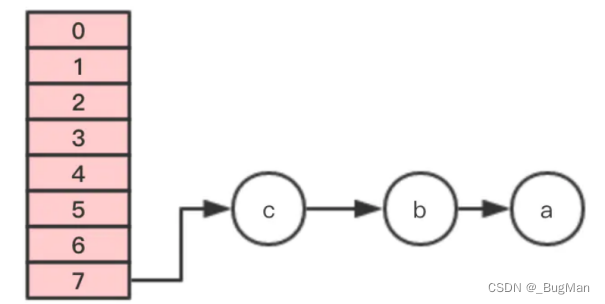
原table:
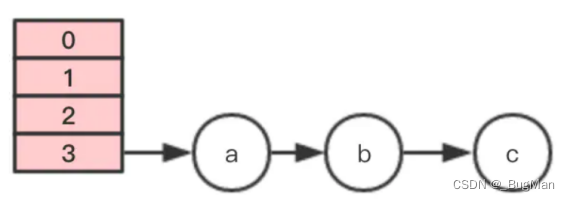
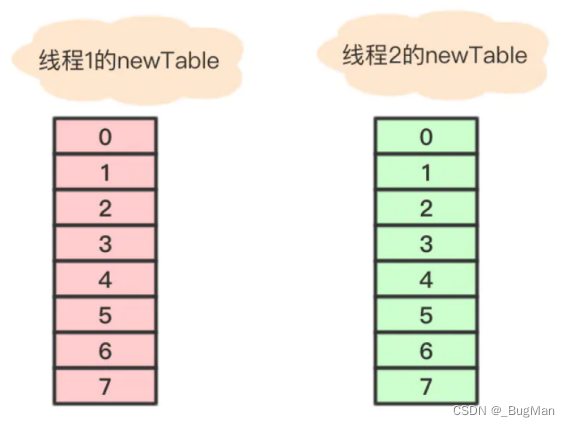
假设 线程2 刚刚执行到遍历指针e指向节点a, next指向节点b,时间片就用完了。
线程1继续执行,很不巧,a、b、c节点rehash之后又是在同一个位置7,开始移动节点、
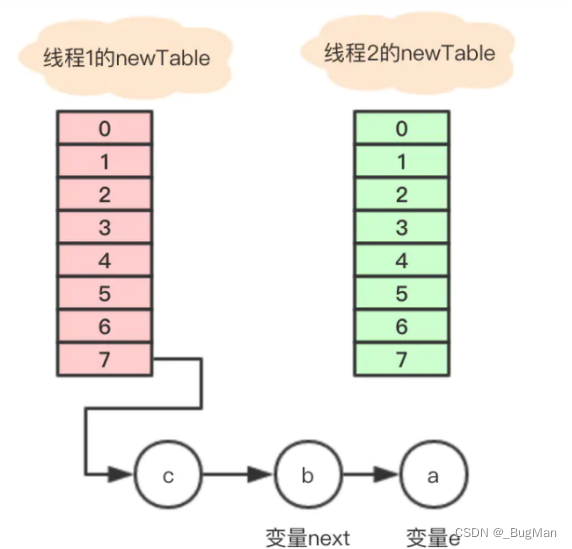
线程1完成工作后,线程2继续工作:
之前线程2的e指针记录到的应该迁移的节点为a,下一个应该迁移的节点为b。
于是执行迁移后:
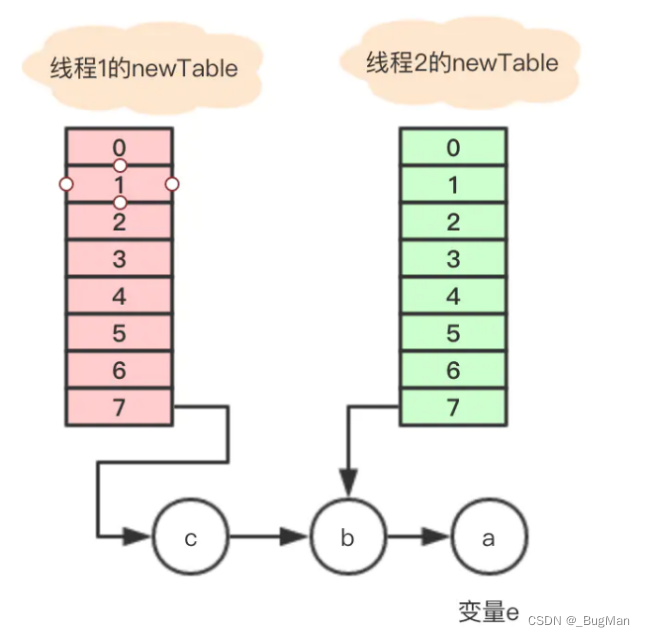
再往下执行,这时候头插法就会惹祸:
变量e又重新指回节点a,只能继续执行循环体,这里仔细分析下:
1、执行完Entry<K,V> next = e.next;,目前节点a没有next,所以变量next指向null;
2、e.next = newTable[i]; 其中 newTable[i] 指向节点b,那就是把a的next指向了节点b,这样a和b就相互引用了,形成了一个环;
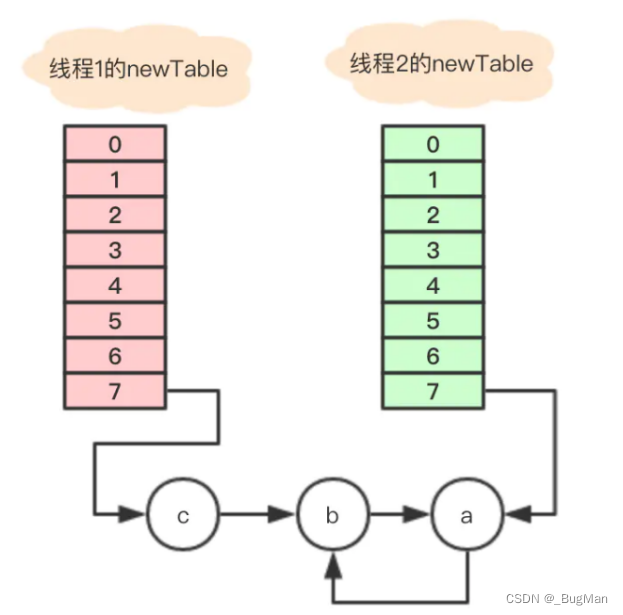
解决办法:
JDK1.8版本,扩容迁移时采用尾插法避免循环链表。底层数据结构为数组+链表,链表节点数超过(包含)8时,链表转化为红黑树,回落到8以下时候,红黑树转化回链表。
8.散列运算
散列运算本身是指hash运算,一般hash运算过后对数组长度取余,得到存储位置,就是个完整的存储过程。计算机中直接求余效率不如位移运算,因此hashmap中用按位与代替了求余运算,整个过程如下:
hashmap中key自身调用hashcode(),生成hashcode,hashcode与数组的length-1展开成二进制做按位与运算。

hash%length==hash&(length-1)的前提是length是2的n次方,这也就是为什么要求hashmap数组的长度必须是2的N次幂。
因为2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1,所以使用2的n次方减1能尽可能的保留到更多位数的特质,可以更加保证均匀分布减少碰撞。
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;
9.扰动函数
扰动函数的作用是使计算得到的hashCode值更加随机和分布均匀,减少哈希冲突的可能性,提高HashMap的查询效率。其中,^表示按位异或运算,>>>表示无符号右移运算。
在JDK1.7中散列函数的实现是:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}在JDK1.8中散列函数的实现是:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}