Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark基础入门3
#博学谷IT学习技术支持
文章目录
- Pyspark
- 前言
- 一、RDD算子的分类
- 二、转换算子
- 1.map算子
- 2.groupBy算子
- 3.filter算子
- 4.flatMap算子
- 5.union(并集) 和 intersection(交集)算子
- 6.groupByKey算子
- 7.reduceByKey算子
- 8.sortByKey算子
- 9.countByKey和 countByValue算子
- 三、动作算子
- 1.reduce算子
- 2.first算子
- 3.take算子
- 4.top算子
- 5.count算子
- 6.foreach算子
- 7.takeSample算子
- 总结
前言
今天和大家分享的是Spark RDD算子相关的操作。
RDD算子: 指的是RDD对象中提供了非常多的具有特殊功能的函数, 我们一般将这样的函数称为算子(大白话: 指的RDD的API)
一、RDD算子的分类
整个RDD算子, 共分为二大类: Transformation(转换算子) 和 Action(动作算子)
转换算子:
1- 所有的转换算子在执行完成后, 都会返回一个新的RDD
2- 所有的转换算子都是LAZY(惰性),并不会立即执行, 此时可以认为通过转换算子来定义RDD的计算规则
3- 转换算子必须遇到Action算子才会触发执行
动作算子:
1- 动作算子在执行后, 不会返回一个RDD, 要不然没有返回值, 要不就返回其他的
2- 动作算子都是立即执行, 一个动作算子就会产生一个Job执行任务,运行这个动作算子所依赖的所有的RDD
二、转换算子
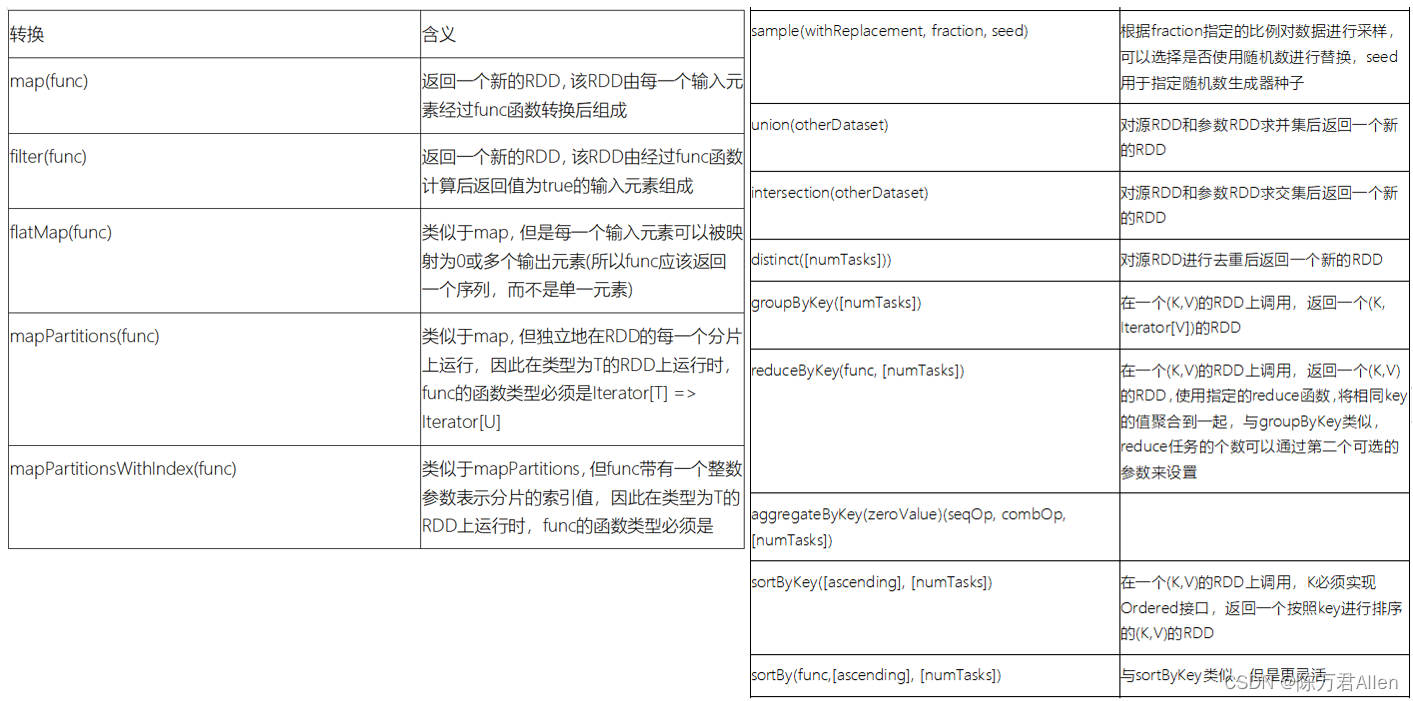
1.map算子
- 格式: rdd.map(fn)
- 说明: 根据传入的函数, 对数据进行一对一的转换操作, 传入一行, 返回一行
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo1").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_map = rdd_init.map(lambda num: num + 1)
rdd_res = rdd_map.collect()
print(rdd_res)
sc.stop()
2.groupBy算子
- 格式: groupBy(fn)
- 说明: 根据传入的函数对数据进行分组操作
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo2").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# def jo(num):
# if num % 2 == 0:
# return 'o'
# else:
# return 'j'
rdd_group_by = rdd_init.groupBy(lambda num: 'o' if num % 2 == 0 else 'j')
rdd_res = rdd_group_by.mapValues(list).collect()
print(rdd_res)
sc.stop()
3.filter算子
- 格式: filter(fn)
- 说明: 过滤算子, 可以根据函数中指定的过滤条件, 对数据进行过滤操作, 条件返回True表示保留, 返回False表示过滤掉
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo3").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_res = rdd_init.filter(lambda num: num > 3).collect()
print(rdd_res)
sc.stop()
4.flatMap算子
- 格式: flatMap(fn)
- 说明: 在map算子的基础上, 在加入一个压扁的操作, 主要适用于一行中包含多个内容的操作, 实现一转多的操作
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo4").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize(['张三 李四 王五 赵六', '田七 周八 李九'])
rdd_res = rdd_init.flatMap(lambda line: line.split(' ')).collect()
print(rdd_res)
sc.stop()
5.union(并集) 和 intersection(交集)算子
格式: rdd1.union|intersection(rdd2)
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo5").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([3, 1, 5, 7, 9])
rdd2 = sc.parallelize([5, 8, 2, 4, 0])
# rdd_res = rdd1.union(rdd2).collect()
# rdd_res = rdd1.union(rdd2).distinct().collect()
rdd_res = rdd1.intersection(rdd2).collect()
print(rdd_res)
sc.stop()
6.groupByKey算子
- 格式: groupByKey()
- 说明: 根据key进行分组操作
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo6").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([('c01', '张三'), ('c02', '李四'), ('c02', '王五'),
('c02', '赵六'), ('c03', '田七'), ('c03', '周八')])
rdd_res = rdd_init.groupByKey().mapValues(list).collect()
print(rdd_res)
sc.stop()
7.reduceByKey算子
- 格式: reduceByKey(fn)
- 说明: 根据key进行分组, 将一个组内的value数据放置到一个列表中, 对这个列表基于 传入函数进行聚合计算操作
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo7").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([('c01', '张三'), ('c02', '李四'), ('c02', '王五'),
('c02', '赵六'), ('c03', '田七'), ('c03', '周八')])
rdd_res = rdd_init.map(lambda kv: (kv[0], 1)).reduceByKey(lambda arr, curr: arr + curr).collect()
print(rdd_res)
sc.stop()
8.sortByKey算子
- 格式: sortByKey(ascending = True|False)
- 说明: 根据key进行排序操作, 默认按照key进行升序排序, 如果需要倒序, 设置 ascending 为False
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo8").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([('c03', '张三'), ('c04', '李四'), ('c05', '王五'),
('c01', '赵六'), ('c07', '田七'), ('c08', '周八')])
rdd_res = rdd_init.sortByKey(ascending=False).collect()
print(rdd_res)
sc.stop()
9.countByKey和 countByValue算子
- countByKey() 根据key进行分组 统计每个分组下有多少个元素
- countByValue() 根据value进行分组, 统计相同value有多少个
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo9").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([('c01', '张三'), ('c02', '李四'), ('c02', '王五'),
('c02', '赵六'), ('c03', '田七'), ('c03', '周八'), ('c01', '张三')
])
rdd_res0 = rdd_init.countByKey()
rdd_res1 = rdd_init.countByValue()
print(rdd_res0)
print(rdd_res1)
sc.stop()
三、动作算子

1.reduce算子
- 格式: reduce(fn)
- 作用: 根据传入的函数对数据进行聚合操作
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo1").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_res = rdd_init.reduce(lambda agg, curr: agg + curr)
print(rdd_res)
sc.stop()
2.first算子
- 格式: first()
- 说明: 获取第一个元素
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo2").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_res = rdd_init.first()
print(rdd_res)
sc.stop()
3.take算子
- 格式: take(N)
- 说明: 获取前N个元素, 类似于limit操作
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo3").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_res = rdd_init.take(3)
print(rdd_res)
sc.stop()
4.top算子
- 格式: top(N, [fn])
- 说明: 对数据集进行倒序排序操作, 如果是kv类型, 默认是针对key进行排序, 获取前N个元素
- fn: 可以自定义排序, 根据谁来排序
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo4").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([('c03', 10), ('c04', 30), ('c05', 20),
('c01', 20), ('c07', 80), ('c08', 5)])
rdd_res = rdd_init.top(3, lambda kv: kv[1])
print(rdd_res)
sc.stop()
5.count算子
- 格式: count()
- 说明: 统计多少个
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo5").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_res = rdd_init.count()
print(rdd_res)
sc.stop()
6.foreach算子
- 格式: foreach(fn)
- 说明: 对数据集进行遍历操作, 遍历后做什么, 取决于传入的函数
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo6").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([('c03', 10), ('c04', 30), ('c05', 20),
('c01', 20), ('c07', 80), ('c08', 5)])
rdd_res = rdd_init.foreach(lambda kv : print(kv))
print(rdd_res)
sc.stop()
7.takeSample算子
-
格式: takeSample(True|False, N,seed(种子值))
- 参数1: 是否允许重复采样
- 参数2: 采样多少个, 如果允许重复采样, 采样个数不限制, 否则最多等于本身数量个数
- 参数3: 设置种子值, 值可以随便写, 一旦写死了, 表示每次采样的内容也是固定的(可选的) 如果没有特殊需要, 一般不设置
-
作用: 数据抽样
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("demo6").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
rdd_res = rdd_init.takeSample(withReplacement=True, num=5, seed=1)
print(rdd_res)
sc.stop()
总结
今天主要分享了RDD的转换算子和动作算子,下次继续分享RDD的一些其他重要算子。