一、简介
作为一名安全从业者,网络安全事件的应急响应工作是必不可少的,那么在应急支撑时,针对大量的日志数据便需要借助自动化工具实现快速的归类检测,并提取出所需的关键日志数据。本篇文章主要通过利用python语言编写一款web日志的分析工具。
代码地址:https://github.com/get0shell/ALogFry
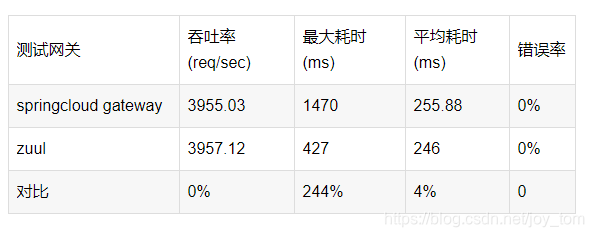
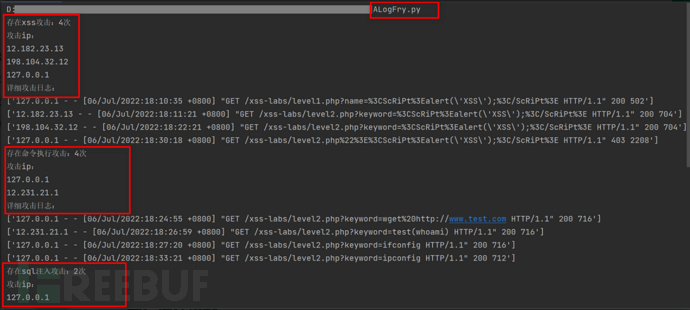
工具运行效果:
python3 ALogFry.py
二、设计模式
该web日志分析工具的整个流程包括以下环节:
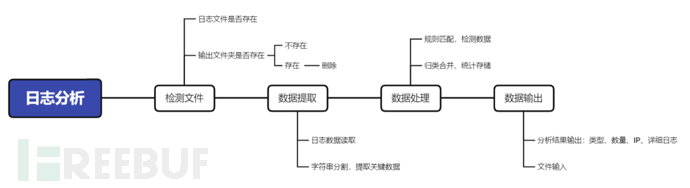
检测文件: 用来检测是否有日志文件,以及输出文件是否存在
数据提取: 用来提取日志数据中的IP、时间以及uri等关键数据
数据处理: 基于规则提取攻击日志,并对攻击日志中关键数据做合并统计
数据输出: 输出数据处理后的数据,并存储于输出文件
三、开发实战
3.1 检测文件
该模块功能主要作用为日志分析前的文件检测,该工具相关涉及两个文件夹,分别为logs和log。
log目录下主要存储检测输出的数据结果,工具运行后先会检测log目录是否存在,
1)如果存在则检测目录下是否存在文件,如果存在文件则为上一次检测生成的结果文件,进行删除
2)如果不存在该目录,则新建一个log目录
if os.path.exists('./log'):
pathDir = os.listdir('./log/')
for allDir in pathDir:
p = os.path.join('./log/' + allDir)
os.remove(p)
else:
os.mkdir('./log')
logs目录必须存在,用来存放需要分析的日志文件,工具运行后会检测该目录下的文件,如果无文件则会提示
lpathDir = os.listdir('./logs')
if len(lpathDir) < 1:
print("logs目录下无日志文件!!!")
else:
pass
3.2 数据提取
检测文件完成后会对logs目录下的日志文件进行遍历提取,提取出每行日志后,利用split()方法对字符串进行分割,分割后以列表的形式进行存在,因为本次工具主要针对web日志中get请求的日志进行分析,以此IP为列表第0个成员,时间为列表第3和第4个成员组成,请求方法为第5个成员,而url为第6个成员。当然,如果日志中接入了post的数据体,可以针对所在的列表位数进行获取,本次工具中不再赘述。

具体代码如下:
for lallDir in lpathDir:
h = os.path.join('./logs/' + lallDir)
with open(h, 'rt', encoding='utf-8') as f:
for i in f:
# 对字符串进行分割,分割之后以列表形式存在
n = i.split()
ip = n[0]
time = n[3] + n[4]
method = n[5]
uri = n[6]
3.3 数据处理
针对提取出的日志数据需要进行恶意攻击日志的检测,那么开始之前,需要提前准备好检测工具所具有的功能对应的规则语句。本次工具编写主要针对xss攻击、命令执行、SQL注入、敏感文件以及webshell连接进行检测,因此首先准备对应的正则匹配规则。具体详细规则根据需要可以细化。
xss = "script<alert|script.*alert|img.*src=|document.domain"
comm = "whoami|ifconfig|ipconfig|wget.*http|dir|curl.*ifs|wget.*ifs|uname|think.*invokefunction|echo|net%20user|net user|phpinfo"
sqlinj = "select.*count|select.*limit|select.*regexp|select.*master|group%20by|group by|union.*select|select.*xp_cmdshell|select.*from"
file = "web.xml|database.properties|config.xml|web_config.xml|known_hosts|htpasswd|DS_Store|boot.ini|win.ini|my.ini|etc/passwd|etc/shadow|httpd.conf|.sql|.svn|.bak"
webshell = "shell.jsp|ant.jsp|server.jsp|i.jsp|shell.php|ant.php|server.php|i.php|shell.asp|ant.asp|server.asp|i.asp"
同时再申明几个int类型变量,初始值为0,用来统计不同类型的攻击数量
x = c = s = e = w = 0
上述完成之后开始对攻击语句进行检测,利用正则re.search()方法实现,这块需要注意使用re.I,可以忽略大小写,将匹配到的日志继续存放在log下对应的txt文档中,同时每检测出一次x变量+1次
# XSS攻击检测
if re.search(xss, uri, re.I):
with open('./log/xss.txt', 'at', encoding='utf-8') as f:
f.writelines(i)
x += 1
检测完成之后,如果申明的统计变量x大于0,则证明存在该攻击日志,则需要对该类攻击下的攻击IP进行处理
1)申明一个空列表,用来存放攻击IP
2)查询该类攻击日志的文档,提取其中的攻击IP并添加到列表
3)对攻击IP列表进行去重处理
if x > 0:
ip_list = []
print('存在xss攻击:' + str(x) + '次')
with open('./log/xss.txt', 'rt', encoding='utf-8') as f:
for i in f:
n = i.split()
ip = n[0]
ip_list.append(ip)
ip_new = list(set(ip_list))
3.4 数据输出
通过数据处理操作后,则对结果进行输出,那么上面数据处理代码中可以看到对于存在该类型攻击以及攻击次数会进行打印输入,同时对于统计去重后的攻击IP也会进行输出。完成之后将该类型攻击日志进行遍历打印输出,方便直接查看。
print("攻击ip:")
for i in range(len(ip_new)):
print(ip_new[i])
with open('./log/xss.txt', 'rt', encoding='utf-8') as f:
print("详细攻击日志:")
for i in f:
# 利用splitlines()去除换行符
print(i.splitlines())
除了打印出输出的数据以外,每种攻击类型的详细日志数据也可以直接在txt文档中查看。
3.5 工具实现
通过上述四个模块的编写,基于python实现的web日志分析工具便完成了,当然以上整体实现只是通过xss攻击检测进行演示,其他类型攻击检测效果同理。具体代码如下:
# @Author : alan
# @File : ALogFry.py
import re
import os
xss = "script<alert|script%3Ealert|img src=|img%20src=|document.domain"
comm = "whoami|ifconfig|ipconfig|wget.*http|dir|curl.*ifs|wget.*ifs|uname|think.*invokefunction|echo|net%20user|net user|phpinfo"
sqlinj = "select.*count|select.*limit|select.*regexp|select.*master|group%20by|group by|union.*select|select.*xp_cmdshell|select.*from"
file = "web.xml|database.properties|config.xml|web_config.xml|known_hosts|htpasswd|DS_Store|boot.ini|win.ini|my.ini|etc/passwd|etc/shadow|httpd.conf|.sql|.svn|.bak"
webshell = "shell.jsp|ant.jsp|server.jsp|i.jsp|shell.php|ant.php|server.php|i.php|shell.asp|ant.asp|server.asp|i.asp"
x = c = s = e = w = 0
if os.path.exists('./log'):
pathDir = os.listdir('./log/')
for allDir in pathDir:
p = os.path.join('./log/' + allDir)
os.remove(p)
else:
os.mkdir('./log')
pathDir = os.listdir('./log/')
for allDir in pathDir:
p = os.path.join('./log/' + allDir)
os.remove(p)
lpathDir = os.listdir('./logs')
if len(lpathDir) < 1:
print("logs目录下无日志文件!!!")
else:
for lallDir in lpathDir:
h = os.path.join('./logs/' + lallDir)
with open(h, 'rt', encoding='utf-8') as f:
for i in f:
# 对字符串进行分割,分割之后以列表形式存在
n = i.split()
ip = n[0]
time = n[3] + n[4]
method = n[5]
uri = n[6]
# XSS攻击检测
if re.search(xss, uri, re.I):
with open('./log/xss.txt', 'at', encoding='utf-8') as f:
f.writelines(i)
x += 1
# 命令执行攻击检测
if re.search(comm, uri, re.I):
with open('./log/comm.txt', 'at', encoding='utf-8') as f:
f.writelines(i)
c += 1
# sql注入攻击检测
if re.search(sqlinj, uri, re.I):
with open('./log/sqlinj.txt', 'at', encoding='utf-8') as f:
f.writelines(i)
s += 1
# 敏感文件攻击检测
if re.search(file, uri, re.I):
with open('./log/file.txt', 'at', encoding='utf-8') as f:
f.writelines(i)
e += 1
# webshell连接攻击检测
if re.search(webshell, uri, re.I):
with open('./log/webs.txt', 'at', encoding='utf-8') as f:
f.writelines(i)
w += 1
if x > 0:
ip_list = []
print('存在xss攻击:' + str(x) + '次')
with open('./log/xss.txt', 'rt', encoding='utf-8') as f:
for i in f:
n = i.split()
ip = n[0]
ip_list.append(ip)
# print(ip_list)
ip_new = list(set(ip_list))
print("攻击ip:")
for i in range(len(ip_new)):
print(ip_new[i])
with open('./log/xss.txt', 'rt', encoding='utf-8') as f:
print("详细攻击日志:")
for i in f:
# 利用splitlines()去除换行符
print(i.splitlines())
# os.remove(r'../plug/logs/log/xss.txt')
if c > 0:
ip_list = []
print('存在命令执行攻击:' + str(c) + '次')
with open('./log/comm.txt', 'rt', encoding='utf-8') as f:
for i in f:
n = i.split()
ip = n[0]
ip_list.append(ip)
# print(ip_list)
ip_new = list(set(ip_list))
print("攻击ip:")
for i in range(len(ip_new)):
print(ip_new[i])
with open('./log/comm.txt', 'rt', encoding='utf-8') as f:
print("详细攻击日志:")
for i in f:
print(i.splitlines())
if s > 0:
ip_list = []
print('存在sql注入攻击:' + str(s) + '次')
with open('./log/sqlinj.txt', 'rt', encoding='utf-8') as f:
for i in f:
n = i.split()
ip = n[0]
ip_list.append(ip)
ip_new = list(set(ip_list))
print("攻击ip:")
for i in range(len(ip_new)):
print(ip_new[i])
with open('./log/sqlinj.txt', 'rt', encoding='utf-8') as f:
print("详细攻击日志:")
for i in f:
print(i.splitlines())
if e > 0:
ip_list = []
print('存在敏感文件攻击:' + str(e) + '次')
with open('./log/file.txt', 'rt', encoding='utf-8') as f:
for i in f:
n = i.split()
ip = n[0]
ip_list.append(ip)
ip_new = list(set(ip_list))
print("攻击ip:")
for i in range(len(ip_new)):
print(ip_new[i])
with open('./log/file.txt', 'rt', encoding='utf-8') as f:
print("详细攻击日志:")
for i in f:
print(i.splitlines())
if w > 0:
ip_list = []
print('存在webshell连接攻击:' + str(w) + '次')
with open('./log/webs.txt', 'rt', encoding='utf-8') as f:
for i in f:
n = i.split()
ip = n[0]
ip_list.append(ip)
ip_new = list(set(ip_list))
print("攻击ip:")
for i in range(len(ip_new)):
print(ip_new[i])
with open('./log/webs.txt', 'rt', encoding='utf-8') as f:
print("详细攻击日志:")
for i in f:
print(i.splitlines())
四、结语
以上便是一个基于python实现的web日志分析工具的逻辑和代码,当然代码还是可以优化的,本次编写为了方便使用全都写到一个py脚本中了。具体检测规则可以根据个人需要进行新增和优化完善,也希望能够在应急分析中有作用,后续代码会慢慢优化更新。
‘rt’, encoding=‘utf-8’) as f:
print(“详细攻击日志:”)
for i in f:
print(i.splitlines())
最后
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

因篇幅有限,仅展示部分资料,有需要的小伙伴,可以【扫下方二维码】免费领取: