3.3.1Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。

3.3.2Partition分区
1、问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
2、默认Partitioner分区
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
默认分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
3、自定义Partitioner步骤
(1)自定义类继承Partitioner,重写getPartition()方法
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
//控制分区代码逻辑
...
return partition;
}
}
(2)在Job驱动中,设置自定义Partitioner
job.setPartitionerClass(ProvincePartitioner.class);
(3)自定义Parttition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
// 9 同时指定相应数量的reduce task
job.setNumReduceTasks(5);
4、分区总结
(1)如果ReduceTask的数量>getPartition的结果数,则会多昌盛几个空的输出文件part-r000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000;
(4)分区号必须从零开始,逐一累加。
5、案例分析
例如:假设自定义分区数为5,则
(1)job.setNumReduceTasks(1);会正常运行,只产生一个输出文件
(2)job.setNumReduceTasks(2); 会报错
(3)job.setNumReduceTasks(6); 大于5,程序会正常运行,会产生空文件
3.3.3Partition分区案例实操
1、需求
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
(1)输入数据
1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.atguigu.com 1527 2106 200
6 84188413 192.168.100.3 www.atguigu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.atguigu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
(2)期望输出数据
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
2、需求分析

3、在案例2.4的基础上,增加一个分区类
package com.cuiyf41.flowsum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 1 获取电话号码的前三位
String preNum = key.toString().substring(0, 3);
int partition = 4;
// 2 判断是哪个省
if ("136".equals(preNum)){
partition = 0;
}else if ("137".equals(preNum)){
partition = 1;
}else if ("138".equals(preNum)){
partition = 2;
}else if ("139".equals(preNum)){
partition = 3;
}
return partition;
}
}
4、在驱动函数中增加自定义数据分区设置和ReduceTask设置
// 8 指定自定义数据分区
job.setPartitionerClass(ProvincePartitioner.class);
// 9 同时指定相应数量的reduce task
job.setNumReduceTasks(5);
package com.cuiyf41.flowsum;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/phone_data.txt", "e:/output" };
// 1 获取配置信息,或者job对象实例
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 6 指定本程序的jar包所在的本地路径
job.setJarByClass(FlowsumDriver.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 5 指定job的输入原始文件所在目录
Path input = new Path(args[0]);
Path output = new Path(args[1]);
// 如果输出路径存在,则进行删除
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output,true);
}
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, output);
// 8 指定自定义数据分区
job.setPartitionerClass(ProvincePartitioner.class);
// 9 同时指定相应数量的reduce task
job.setNumReduceTasks(5);
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.3.4WritableComparable排序
1、概述
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值时,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定的阈值,则溢写到磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大的文件;如果内存中文件大小或者数量超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
2、排序的分类
(1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
(3)辅助排序(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
(4)二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
3、自定义排序WritableComparable
(1)原理分析
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
@Override
public int compareTo(FlowBean o) {
int result;
// 按照总流量大小,倒序排列
if (sumFlow > bean.getSumFlow()) {
result = -1;
}else if (sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
3.3.5WritableComparable排序案例实操(全排序)
1、需求
根据案例2.3产生的结果再次对总流量进行排序。
(1)输入数据
原始数据 第一次处理后的数据
(2)期望输出数据
13509468723 7335 110349 117684
13736230513 2481 24681 27162
13956435636 132 1512 1644
13846544121 264 0 264
。。。 。。。
2、需求分析

3、代码实现
(1)FlowBean对象在在需求1基础上增加了比较功能
package com.cuiyf41.sort;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
// 反序列化时,需要反射调用空参构造函数,所以必须有
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
/**
* 序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化方法 注意反序列化的顺序和序列化的顺序完全一致
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public int compareTo(FlowBean o) {
int result;
// 按照总流量大小,倒序排列
if (this.sumFlow > o.getSumFlow()) {
result = -1;
}else if (this.sumFlow < o.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
}
(2)编写Mapper类
package com.cuiyf41.sort;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
FlowBean k = new FlowBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, FlowBean, Text>.Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\t");
// 3 封装对象
String phoneNum = fields[0];
long upFlow = Long.parseLong(fields[1]);
long downFlow = Long.parseLong(fields[2]);
k.set(upFlow, downFlow);
v.set(phoneNum);
// 4 输出
context.write(k, v);
}
}
(3)编写Reducer类
package com.cuiyf41.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountSortReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Reducer<FlowBean, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
// 循环输出,避免总流量相同情况
for(Text value: values){
context.write(value, key);
}
}
}
(4)编写Driver类
package com.cuiyf41.flowsum;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
FlowBean v = new FlowBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割字段
String[] fields = line.split("\t");
// 3 封装对象
// 取出手机号码
String phoneNum = fields[1];
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum);
// FlowBean v = new FlowBean(upFlow, downFlow);
v.set(upFlow, downFlow);
// 4 写出
context.write(k, v);
}
}
3.3.6WritableComparable排序案例实操(区内排序)
1.需求
要求每个省份手机号输出的文件中按照总流量内部排序。
2.需求分析
基于前一个需求,增加自定义分区类,分区按照省份手机号设置。

3.案例实操
(1)增加自定义分区类
package com.cuiyf41.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<FlowBean, Text> {
@Override
public int getPartition(FlowBean key, Text value, int numPartitions) {
// 1 获取手机号码前三位
String preNum = value.toString().substring(0, 3);
int partition = 4;
// 2 根据手机号归属地设置分区
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
(2)在驱动类中添加分区类
// 加载自定义分区类
job.setPartitionerClass(ProvincePartitioner.class);
// 设置Reducetask个数
job.setNumReduceTasks(5);
3.3.7Combiner合并
1)概述
(1)Combiner是MR程序中Mapper和Reducer之外的一个组件。
(2)Combiner组件的父类就是Reducer。
(3)Combiner和Reducer的区别在于运行的维值
Combiner是在每个MapTask所在的节点运行;
Reducer是接收全局所有Mapper的输出结果;
(4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv应该跟Reducer的输入kv类型保持一致。
Mapper Reducer
3 5 7 →(3+5+7)/3 = 5 (3+5+7+2+6)/5 = 23/5 等于(5+4)/2 = 9/2
2 6 →(2+6)/2 = 4
2)自定义Combiner实现步骤
(a)自定义一个Combiner继承Reducer,重写Reduce方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 汇总操作
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 写出
context.write(key, new IntWritable(count));
}
}
(b)在Job驱动类中设置:
job.setCombinerClass(WordcountCombiner.class);
3.3.8Combiner合并案例实操
1、需求
统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。
(1)数据输入
(2)期望输出数据
期望:Combine输入数据多,输出时经过合并,输出数据降低。
2、需求分析

3.案例实操-方案一
1)增加一个WordcountCombiner类继承Reducer
package com.cuiyf41.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1 汇总
int sum = 0;
for(IntWritable value :values){
sum += value.get();
}
v.set(sum);
// 2 写出
context.write(key, v);
}
}
2)在WordcountDriver驱动类中指定Combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);
4.案例实操-方案二
1)将WordcountReducer作为Combiner在WordcountDriver驱动类中指定
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑
job.setCombinerClass(WordcountReducer.class);
3.3.9GroupingComparator分组(辅助排序)
1)概述
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 比较的业务逻辑
return result;
}
(3)创建一个构造将比较对象的类传给父类
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
3.3.10GroupingComparator分组案例实操
1、需求
有如下订单数据

现在需要求出每一个订单中最贵的商品。
(1)输入数据
0000001 Pdt_01 222.8
0000002 Pdt_05 722.4
0000001 Pdt_02 33.8
0000003 Pdt_06 232.8
0000003 Pdt_02 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4
(2)期望输出数据
1 222.8
2 722.4
3 232.8
2、需求分析
(1)利用“订单id和成交金额”作为key,可以将Map阶段读取到的所有订单数据按照id升序排序,如果id相同再按照金额降序排序,发送到Reduce。
(2)在Reduce端利用groupingComparator将订单id相同的kv聚合成组,然后取第一个即是该订单中最贵商品,如图4-18所示。
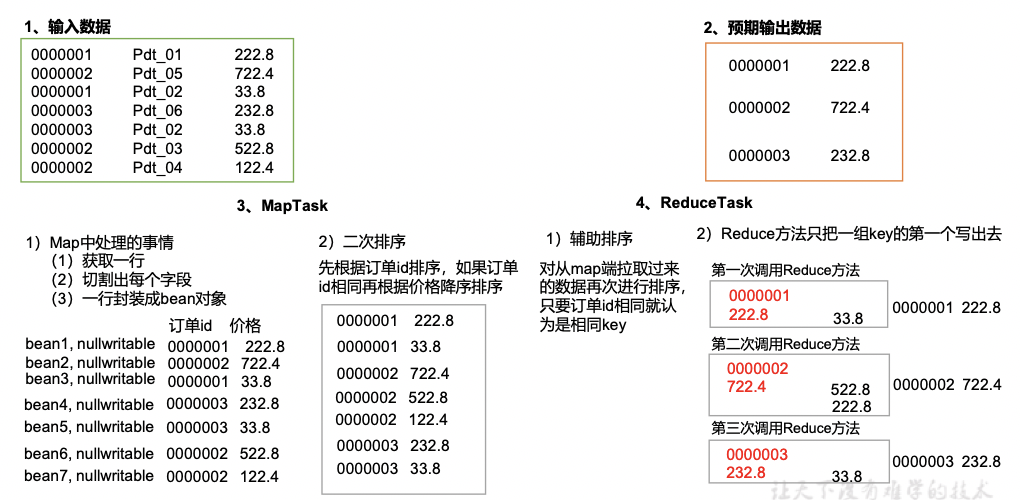
3、代码实现
(1)定义订单信息OrderBean类
package com.cuiyf41.order;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
private int order_id; // 订单id号
private double price; // 价格
public OrderBean() {
super();
}
public OrderBean(int order_id, double price) {
super();
this.order_id = order_id;
this.price = price;
}
// 二次排序
@Override
public int compareTo(OrderBean o) {
int result;
if (order_id > o.getOrder_id()) {
result = 1;
} else if (order_id < o.getOrder_id()) {
result = -1;
} else {
// 价格倒序排序
result = price > o.getPrice() ? -1 : 1;
}
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
order_id = in.readInt();
price = in.readDouble();
}
@Override
public String toString() {
return order_id + "\t" + price;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
(2)编写OrderSortMapper类
package com.cuiyf41.order;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\t");
// 3 封装对象
k.setOrder_id(Integer.parseInt(fields[0]));
k.setPrice(Double.parseDouble(fields[2]));
// 4 写出
context.write(k, NullWritable.get());
}
}
(3)编写OrderSortGroupingComparator类
package com.cuiyf41.order;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderGroupingComparator extends WritableComparator {
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
}
}
(4)编写OrderSortReducer类
package com.cuiyf41.order;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
(5)编写OrderSortDriver类
package com.cuiyf41.order;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OrderDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[]{"e:/input/inputorder" , "e:/output1"};
// 1 获取配置信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包加载路径
job.setJarByClass(OrderDriver.class);
// 3 加载map/reduce类
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// 4 设置map输出数据key和value类型
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 设置最终输出数据的key和value类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 设置输入数据和输出数据路径
Path input = new Path(args[0]);
Path output = new Path(args[1]);
// 如果输出路径存在,则进行删除
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output,true);
}
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, output);
// 8 设置reduce端的分组
job.setGroupingComparatorClass(OrderGroupingComparator.class);
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}