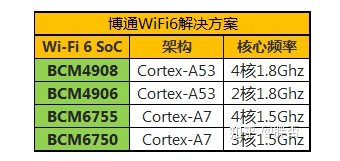
Stable Diffusion 是一种文本到图像的潜在扩散模型,由来自 CompVis、Stability AI 和 LAION 的研究人员和工程师创建。 它使用来自 LAION-5B 数据库子集的 512x512 图像进行训练。 稳定扩散,生成人脸,也可以在自己的机器上运行,如下图所示:

推荐:将 NSDT场景编辑器 加入你的3D开发工具链。
如果你足够聪明和有创意,你可以创建一系列图像,然后形成视频。 例如,Xander Steenbrugge 使用稳定扩散和图 1 所示的输入提示创建了令人惊叹的 Voyage through Time 视频:

以下是他用来创作这幅创意作品的提示和种子:
在本文中,我们将首先介绍什么是Stable Diffusion并讨论其主要组成部分。 然后我们将使用稳定扩散以三种不同的方式创建图像,从简单到复杂。
1、稳定扩散模型
扩散模型是机器学习模型,经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的样本,例如图像。
扩散模型有一个主要的缺点,因为去噪过程的时间和内存消耗都非常昂贵。 这会使进程变慢并消耗大量内存。 这样做的主要原因是它们在像素空间中运行,这变得非常昂贵,尤其是在生成高分辨率图像时。
引入稳定扩散来解决这个问题,因为它依赖于潜在扩散。 潜在扩散通过在较低维度的潜在空间上应用扩散过程而不是使用实际像素空间来减少内存和计算成本。
1.1 潜在扩散的组成
潜在扩散包含三个主要组成部分:
- 变分自编码器 (VAE)
变分自编码器 (VAE) 由两个主要部分组成:编码器和解码器。 编码器会将图像转换为低维潜在表示,该表示将作为下一个组件 U_Net 的输入。 解码器将做相反的事情,将潜在表示转换回图像。
编码器用于在潜在扩散训练期间为前向扩散过程获取输入图像的潜在表示(latent)。 在推理过程中,VAE 解码器会将潜在的转换回图像。
- U-Net

U-Net 也由编码器和解码器部分组成,两者都由 ResNet 块组成。 编码器将图像表示压缩为较低分辨率的图像,解码器将较低分辨率解码回较高分辨率的图像。
为了防止 U-Net 在下采样时丢失重要信息,通常在编码器的下采样 ResNet 和解码器的上采样 ResNet 之间添加快捷连接。
此外,稳定扩散 U-Net 能够通过交叉注意层调节其在文本嵌入上的输出。 交叉注意层被添加到 U-Net 的编码器和解码器部分,通常在 ResNet 块之间。
- 文本编码器

文本编码器会将输入提示(例如,“A Pikachu fine dining with view to the Effiel tower”)转换为 U-Net 可以理解的嵌入空间。 这将是一个简单的基于转换器的编码器,它将标记序列映射到潜在文本嵌入序列。
重要的是使用一个好的提示符以获得预期的输出。 这就是为什么现在正在流行即时工程的主题。 提示工程是找到某些词的行为,这些词可以触发模型产生具有某些属性的输出。
1.2 为什么潜扩散快速高效
latent diffusion 之所以快速高效,是因为 latent diffusion 的 U-Net 在低维空间上运行。 与像素空间扩散相比,这减少了内存和计算复杂性。 例如,Stable Diffusion 中使用的自动编码器的缩减系数为 8。这意味着形状为 (3, 512, 512 ) 的图像在潜在空间中变为 (4, 64, 64 ),这需要的内存减少 64 倍。
1.3 推理中的稳定扩散
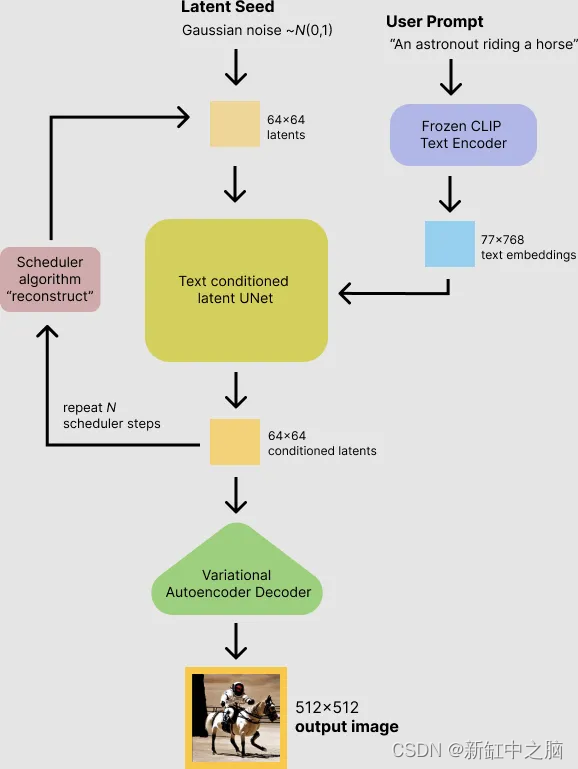
首先,稳定扩散模型将潜在种子和文本提示作为输入。 然后使用潜在种子生成大小为 64×64 的随机潜在图像表示,而文本提示通过 CLIP 的文本编码器转换为大小为 77×768 的文本嵌入。
接下来,U-Net 在以文本嵌入为条件的同时迭代地对随机潜在图像表示进行去噪。 U-Net 的输出是噪声残差,用于通过调度程序算法计算去噪的潜在图像表示。 调度器算法根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示。
许多不同的调度程序算法可用于此计算,每个算法都有其优点和缺点。 对于稳定扩散,建议使用以下之一:
- PNDM 调度程序(默认使用)
- DDIM调度器
- K-LMS调度程序
去噪过程重复大约 50 次以逐步检索更好的潜在图像表示。 完成后,潜在图像表示由变分自编码器的解码器部分解码。
2、使用HuggingFace Space
HuggingFace Space提供了一个非常简单的 API 来使用稳定扩散生成图像。 在下图中,你可以看到我使用了“Astronauts riding a horse”,可以在下图中看到输出:

有一些可用的高级选项可用于更改生成图像的质量,如下图所示:
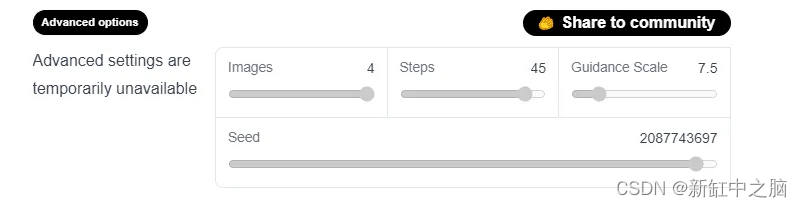
有四个选项可供使用:
- images:这个控制图片的数量,最多4张图片。
- Steps:此选项选择你想要的扩散过程的步骤数。 步骤越多,生成的图像质量就越好。 如果你想要高质量,你可以选择可用的最大步数,即 50。如果你需要更快的结果,那么可以考虑减少步数。
- Guidance Scale:指导比例是生成的图像与你的输入提示的接近程度与输入的多样性之间的权衡。 它的典型值约为 7.5。 比例增加得越多,图像的质量就越高,但输出的多样性就会降低。
- Seed:种子使你能够控制生成样本的多样性
3、使用Diffusers开发包
第二种方法是使用 Hugging Face 生成的 Diffusers 库并在 google Colab 上运行它。 diffuser 是 Hugging Face 生成的一个库,它包含了目前可用的大部分稳定的扩散模型。
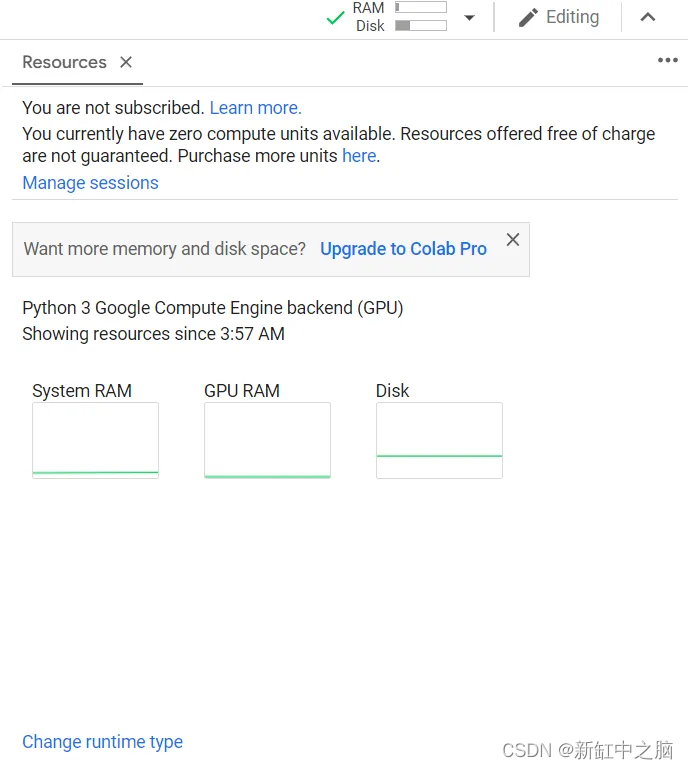
第一步是打开google collab,然后按connect。 之后,要检查它是否连接到GPU,可以从资源按钮中检查它,如下图所示:
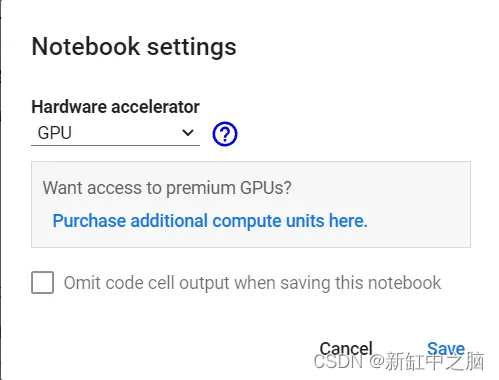
另一个选项是从 Runtime 菜单中选择 change run-time type,然后你应该会发现硬件加速器被选择为 GPU:
首先,让我们确保使用 GPU 运行时来使用下面的代码运行此笔记本,以便推理速度更快。 如果以下命令失败,请使用运行时菜单并选择更改运行时类型,如上图所示:
!nvidia-smi
如果它正在工作并被检测到,你将收到类似的消息:
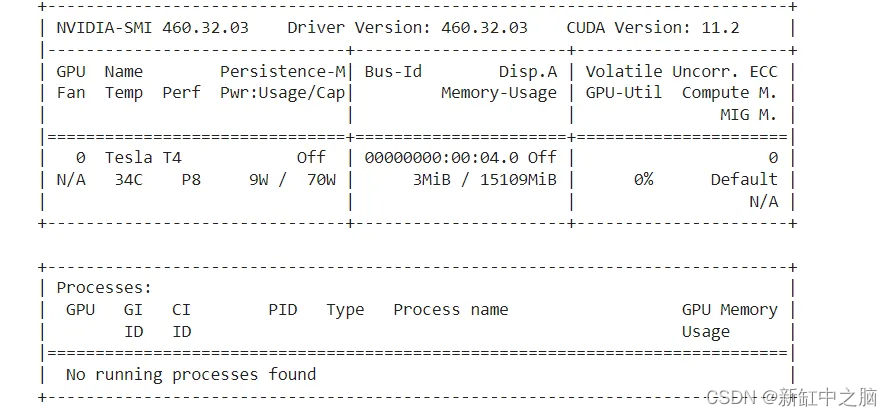
接下来,应该安装diffusers、 scipy、ftfy 和 transformer:
!pip install diffusers==0.4.0
!pip install transformers scipy ftfy
!pip install "ipywidgets>=7,<8"
还需要通过勾选此处的复选框来接受示范许可。 你必须在 hugging face 上注册并获得访问令牌才能使用这些模型。
由于 google collab 已经禁用了外部小部件,我们需要启用它。 为此,请运行以下代码以使用 notebook_login :
from google.colab import output
output.enable_custom_widget_manager()
现在可以使用从你的帐户获得的访问令牌登录到你的Huggingface帐户:
from huggingface_hub import notebook_login
notebook_login()
接下来,我们将从扩散器库中加载 StableDiffusionPipeline。 StableDiffusionPipeline 是一个端到端推理管道,可用于从文本生成图像。
我们将加载预训练模型的权重。 模型 ID 将是 CompVis/stable-diffusion-v1–4,我们还将对函数使用特定类型的修订版和 torch_dtype。 我们将设置 revision = “fp16” 以从半精度分支加载权重,并设置 torch_dtype = “torch.float16” 以告知扩散器期望权重为 float 16 精度。
像这样设置变量以便能够在免费版的 google CoLab 上运行模型非常重要。
import torch
from diffusers import StableDiffusionPipeline
# make sure you're logged in with `huggingface-cli login`
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
现在让我们将管道移动到 GPU 以进行更快的推理:
pipe = pipe.to("cuda")
现在是生成图片的时候了。 我们将编写一个提示并将其提供给管道并打印输出。 这里的输入提示是一张宇航员骑马的照片:
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0] # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
# Now to display an image you can do either save it such as:
image.save(f"astronaut_rides_horse.png")
我们看一下输出:

每次你运行上面的代码,你都会得到不同的图像。 要每次都获得相同的结果,可以将随机种子传递给管道,如下面的代码所示:
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, generator=generator).images[0]
image
还可以使用 num_inference_steps 参数更改推理步骤的数量。 一般来说,推理步骤越多,生成的图像质量越高,但生成结果的时间也会越长。 如果想要更快的结果,你可以使用更少的步骤。
以下单元格使用与之前相同的种子,但步骤更少:
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, num_inference_steps=15, generator=generator).images[0]
image
请注意一些细节,例如马的头部或头盔,比上一张图像中的定义更少:

管道调用中的另一个参数是指导比例。 这是一种提高对条件信号的依从性的方法,在这种情况下,条件信号是文本以及整体样本质量。
简单来说,无分类器指导迫使生成更好地匹配提示。 像 7 或 8.5 这样的数字给出了很好的结果。 如果您使用非常大的数字,图像可能看起来不错,但多样性会降低。
要为同一个提示生成多个图像,我们只需使用一个包含重复多次相同提示的列表。 我们会将列表而不是我们之前使用的字符串发送到管道。
让我们首先编写一个辅助函数来显示图像网格。 只需运行以下单元格即可创建 image_grid 函数:
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
现在,我们可以在运行带有 3 个提示列表的管道后生成网格图像。
num_images = 3
prompt = ["a photograph of an astronaut riding a horse"] * num_images
images = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
grid
结果如下:

我们还可以生成 n*m 图像的网格:
num_cols = 3
num_rows = 4
prompt = ["a photograph of an astronaut riding a horse"] * num_cols
all_images = []
for i in range(num_rows):
images = pipe(prompt).images
all_images.extend(images)
grid = image_grid(all_images, rows=num_rows, cols=num_cols)
grid
结果如下:

稳定扩散生成的图像的默认大小为 512*512 像素。 但是,使用高度和宽度参数更改生成图像的高度和宽度非常容易。 以下是选择合适图像尺寸的一些提示:
- 将高度和宽度参数都选择为 8 的倍数。
- 在较低质量下将任何高度和宽度设置为小于 512。
- 将两个方向设置为大于 512 将导致列出全局一致性并导致准备图像区域。
- 最好选择的值是一个方向为 512,而另一个方向大于 512。
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
image
结果如下:

4、用扩散器建立你自己的管道
最后,是时候使用扩散器创建自定义扩散管道了。 我们将演示如何将 Stable Diffusion 与不同的调度程序一起使用,即 Katherine Crowson 的 K-LMS 调度程序。
让我们逐步了解 StableDiffusionPipeline,看看我们如何自己编写它。 我们将从加载涉及的各个模型开始:
import torch
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
预训练扩散模型包括建立完整扩散管道所需的所有组件。 它们存储在以下文件夹中:
- text_encoder:Stable Diffusion使用CLIP,但其他diffusion模型可能使用其他编码器如BERT。
- tokenizer:它必须与 text_encoder 模型使用的匹配。
- scheduler:用于在训练期间逐步向图像添加噪声的调度算法。
- U-Net:用于生成输入的潜在表示的模型。
- VAE:变分自编码器模块,我们将使用它来将潜在表示解码为真实图像。
我们可以通过引用保存组件的文件夹来加载组件,使用 from_pretrained 的子文件夹参数。
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
现在我们不加载预定义的调度程序,而是加载 K-LMS 调度程序。
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
接下来,我们将模型移至 GPU。
vae = vae.to(torch_device)
text_encoder = text_encoder.to(torch_device)
unet = unet.to(torch_device)
我们现在定义将用于生成图像的参数。 请注意,与前面的示例相比,我们设置 num_inference_steps = 100 以获得更清晰的图像。
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(32) # Seed generator to create the inital latent noise
batch_size = 1
接下来,我们获取提示的 text_embeddings。 这些嵌入将用于调节 U-Net 模型。
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
我们还将获得用于无分类器指导的无条件文本嵌入,它们只是填充标记(空文本)的嵌入。 它们需要与条件 text_embeddings(batch_size 和 seq_length)具有相同的形状:
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
with torch.no_grad():
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
对于无分类器指导,我们需要进行两次前向传递。 第一个是条件输入 (text_embeddings),第二个是无条件嵌入 (uncond_embeddings)。 因此,我们会将两者连接成一个批次,以避免进行两次前向传递:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
让我们生成初始随机噪声:
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
生成的 latent 的形状是 64 * 64。之后模型会将这个 latent representation(纯噪声)转换为 512 * 512 的图像。
现在我们将使用选定的 num_inference_steps 初始化调度程序。 这将计算将在去噪过程中使用的西格玛和确切的步长值:
scheduler.set_timesteps(num_inference_steps)
K-LMS 调度器需要将潜伏量乘以它的西格玛值。 让我们在这里这样做:
latents = latents * scheduler.init_noise_sigma
最后,我们现在准备编写去噪循环:
from tqdm.auto import tqdm
from torch import autocast
for t in tqdm(scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
我们现在可以使用 vae 将生成的潜在解码回图像:
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
最后,让我们将图像转换为 PIL,以便我们可以显示或保存它。
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]

原文链接:稳定扩散模型应用指南 — BimAnt