1、前提
提示:只适用于InnoDB引擎
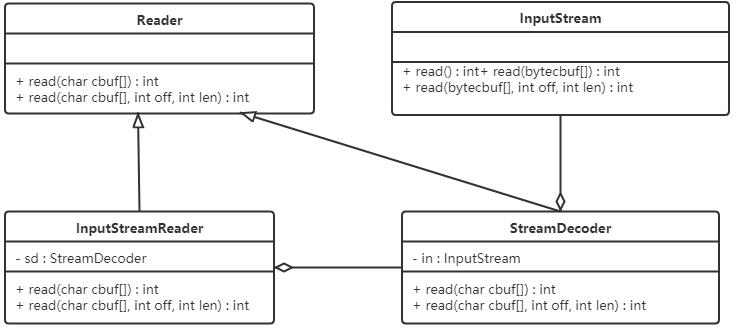
2、InnoDB存储特点
- 它把索引和数据放在了一个文件中,就是聚集索引。这与MyISAM引擎是不一样的。
3、SQL示例
-- 给cve字段建立索引
select * from cnnvd where cve='CVE-2022-24808' limit 300000,10;
- 由于MySQL内部的执行顺序以及B+树的特性,就导致SQL会先查询300010次普通索引节点,然后拿到300010个聚集索引的指针地址,进而再查询300010次聚集索引,接着得到300010条数据,最终还要舍去前300000条数据,从而得到10条数据。相当于前300000条数据都是没用的,浪费了好多IO。
4、优化
- 我们可以做以下改变:利用子查询或者关联查询,先得到这10条数据的聚集索引指针地址,然后就只需要查询10次聚集索引就行了,几乎减少了一半的磁盘IO,并且如果limit的第一个参数越大,效率改善就越明显。
select * from cnnvd a join (select id from cnnvd where cve='CVE-2022-24808' limit 300000,10) b on a.id = b.id;
5、校验
- 怎么才能证实MYSQL底层就是这样处理的呢?我们可以在执行完每条SQL后,分别输出下
buffer pool中的数据页的大小(第一条SQL完成后要重启MySQL,清空缓存,不然没什么变化),一比就看出来了。
-- 对于第一条SQL的输出结果:
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('cve_name','primary') and TABLE_NAME like '%cnnvd%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| cve_name | 663 |
| PRIMARY | 5451 |
+------------+----------+
2 rows in set (0.34 sec)
-- 对于第二条SQL的输出结果:
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('cve_name','primary') and TABLE_NAME like '%cnnvd%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| cve_name | 663 |
| PRIMARY | 14 |
+------------+----------+
2 rows in set (0.34 sec)
很明显
PRIMARY的数据页的大小变小了好多,因为在查询聚集索引的时候少了很多次查询操作。
其实不用看这个输出,你只要弄一张数据量很大的表测一下,就能很直观的感受到查询效率差别很大,前提是limit的第一个参数特别大的时候越明显。