切面条-蓝桥杯-基础-CSDN算法技能树![]() https://edu.csdn.net/skill/algorithm/algorithm-530255df51be437b967cbc4524fe66ea?category=188
https://edu.csdn.net/skill/algorithm/algorithm-530255df51be437b967cbc4524fe66ea?category=188
目录
切面条
大衍数列
门牌制作
方阵转置
微生物增殖
成绩统计
星系炸弹
判断闰年的依据:
特别数的和
*日志统计*(双指针)
双指针
猜年龄
合并检测
排它平方数
*四平方和定理*
*大数乘法*
切面条
一根高筋拉面,中间切一刀,可以得到2根面条。
如果先对折1次,中间切一刀,可以得到3根面条。
如果连续对折2次,中间切一刀,可以得到5根面条。 那么,连续对折10次,中间切一刀,会得到多少面条呢?
想法:
找规律
1、不对折(对折零次),从中间切一刀,得到 2 根面条, 2 = 2
2、对折一次,从中间切一刀,得到 3 根面条, 3 = 2 + 2^0
3、对折两次,从中间切一刀,得到 5 根面条, 5 = 2 + 2^0 + 2^1
4、对折三次,从中间切一刀,得到 9 根面条, 9 = 2 + 2^0 + 2^1 + 2^2
…
11、对折十次,从中间切一刀,得到 2 + 2^0 + 2^1 + 2^2 + ...... + 2^9 根面条
#include <stdio.h>
int cut_noodles(int times)
{
int result = 2, t = 1;
for (int i = 0; i < times; i++)
{
result += t;
t = t * 2;
}
return result;
}
int main()
{
int result;
int times = 0;
result = cut_noodles(times);
printf( "对折 %d 次从中间切一刀得到的面条数是: %d\n", times, result);
return 0;
}大衍数列
中国古代文献中,曾记载过“大衍数列”, 主要用于解释中国传统文化中的太极衍生原理。
它的前几项是:0、2、4、8、12、18、24、32、40、50 …
其规律是:对偶数项,是序号平方再除2,奇数项,是序号平方减1再除2。
以下的代码打印出了大衍数列的前 100 项。
请填补空白处的内容。
#include <stdio.h>
int main()
{
int i;
for (i = 1; i <= 100; i++)
{
if (__________________)
printf("%d ", i * i / 2);
else
printf("%d ", (i * i - 1) / 2);
}
printf("\n");
}想法:
其规律是:对偶数项,是序号平方再除2,奇数项,是序号平方减1再除2。
i%2==0
门牌制作
小蓝要为一条街的住户制作门牌号。
这条街一共有 2020 位住户,门牌号从 1 到 2020 编号。
小蓝制作门牌的方法是先制作 0 到 9 这几个数字字符,最后根据需要将字符粘贴到门牌上,例如门牌 1017 需要依次粘贴字符 1、0、1、7,即需要 1 个字符 0,2 个字符 1,1 个字符 7。
请问要制作所有的 1 到 2020 号门牌,总共需要多少个字符 2?
#include <bits/stdc++.h>
using namespace std;
int main()
{
int ans = 0, x;
for (int i = 1; i <= 2020; i++)
{
x = i;
while (x)
{
________________;
}
}
cout << ans;
return 0;
}提示:
利用循环将当前数字的每一位求出,分别进行判断即可利用循环将当前数字的每一位求出,分别进行判断即可
#include <iostream>
using namespace std;
int ans;
void check(int n)
{
while(n)
{
int t = n % 10;
if(t == 2) ans ++;
n /= 10;
}
}
int main()
{
for (int i = 1; i <= 2020; i ++)
check(i);
cout << ans << endl;
return 0;
}
另一种比较笨拙 但比较好理解的方法:
虽然有点笨拙,但比较好理解。
let count = 0;
for (let i = 1; i <= 2020; i++) {
let x = i;
//个位符合的x, 并摘掉个位的2 = 符合的个数;
if (x % 10 == 2) {
x -= 2;
// console.log(x);
count++;
}
//十位符合的x, 并摘掉十位的2 = 符合的个数;
if (parseInt(x / 10) % 10 == 2) {
x -= 20;
// console.log(x);
count++;
}
//百位符合的x, 并摘掉百位的2 = 符合的个数;
if (parseInt(x / 100) % 10 == 2) {
x -= 200;
// console.log(x);
count++;
}
//千位符合的x, 并摘掉千位的2 = 符合的个数;
if (parseInt(x / 1000) % 10 == 2) {
x -= 2000;
// console.log(x);
count++;
}
}
console.log('符合个数:' + count);
//结果624
方阵转置
问题描述
给定一个n×m矩阵相乘,求它的转置。其中1≤n≤20,1≤m≤20,矩阵中的每个元素都在整数类型(4字节)的表示范围内。
输入格式
第一行两个整数n和m;
第二行起,每行m个整数,共n行,表示n×m的矩阵。数据之间都用一个空格分隔。
输出格式
共m行,每行n个整数,数据间用一个空格分隔,表示转置后的矩阵。
样例输入
2 4
34 76 -54 7
-4 5 23 9样例输出
34 -4
76 5
-54 23
7 9请从以下四个选项中选择正确的代码填补空白处,实现方阵转置功能。
提示:
对一个方阵转置,就是把原来的行号变列号,原来的列号变行号#include <bits/stdc++.h>
using namespace std;
int main()
{
int m, n;
int a[20][20];
int i, j;
cin >> m >> n;
for (i = 0; i < m; i++)
{
for (j = 0; j < n; j++)
{
cin >> a[j][i];
}
}
__________________;
return 0;矩阵的转置实际就是把n行m列的矩阵 转换为m行n列的矩阵 所以只需要改变 i ,j 位置即可
微生物增殖
假设有两种微生物 X 和 Y
X出生后每隔3分钟分裂一次(数目加倍),Y出生后每隔2分钟分裂一次(数目加倍)。
一个新出生的X,半分钟之后吃掉1个Y,并且,从此开始,每隔1分钟吃1个Y。
现在已知有新出生的 X=10, Y=89,求60分钟后Y的数目。
如果X=10,Y=90呢?
本题的要求就是写出这两种初始条件下,60分钟后Y的数目。
以下程序实现了这一功能,请你补全空白处内容:
提示:
分析可知,Y分别会在0.5,1.5,2.5······时被吃,所以,把60分钟分成120份,则在除以2余数为1时,Y的数目减少X个#include <iostream>
using namespace std;
int main()
{
int x = 10, y = 90;
for (int i = 1; i <= 120; i++)
{
________________;
}
cout << y << endl;
}思路:一般来说这种题都是找规律的题(在纸上笔算是不可能算出结果的),本体也不例外,只要找到x与y关于时间的对应关系即可。
计算代码:
#include<stdio.h>
#include<stdlib.h>
int main()
{
int n,m;
double x,y;
scanf("%d%lf%lf",&n,&x,&y);
m=1;
while(m<=n)
{
if(m%2!=0)
y=y-x;
if(m%2==0)
y=(y-x)*2;
if(m%3==0)
x*=2;
//printf("m=%d x=%.0lf y=%.0lf\n",m,x,y);
m++;
}
printf("x=%.0lf y=%.0lf\n",x,y);
system("pause");
return 0;
}成绩统计
问题描述
编写一个程序,建立了一条单向链表,每个结点包含姓名、学号、英语成绩、数学成绩和C++成绩,并通过链表操作平均最高的学生和平均分最低的学生并且输出。
输入格式
输入n+1行,第一行输入一个正整数n,表示学生数量;接下来的n行每行输入5个数据,分别表示姓名、学号、英语成绩、数学成绩和C++成绩。注意成绩有可能会有小数。
输出格式
输出两行,第一行输出平均成绩最高的学生姓名。第二行输出平均成绩最低的学生姓名。
样例输入
2
yx1 1 45 67 87
yx2 2 88 90 99样例输出
yx2
yx1请从以下四个选项中选择空白处的内容。
#include <bits/stdc++.h>
using namespace std;
int main()
{
struct student
{
string xm;
int xh;
double yy;
double sx;
double cpp;
};
student a[1000];
int n;
double sum = 0, min = 301, max = 0;
string mins, maxs;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> a[i].xm >> a[i].xh >> a[i].yy >> a[i].sx >> a[i].cpp;
sum = a[i].yy + a[i].sx + a[i].cpp;
__________________;
}
cout << maxs << endl
<< mins;
return 0;
}提示: 类似冒泡法求最大值最小值 如果有相同成绩的最高分和最低分,取序号小的还是取序号大的最高最低分。
if(sum>max),这是取序号小的最高分。
if(sum>=max),这是取序号大的最高分。
题解
模拟:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
int n;
cin >> n;
int a = 0, b = 0;
for (int i = 0; i < n; i ++)
{
int x;
cin >> x;
if(x >= 60) a ++;
if(x >= 85) b ++;
}
cout << round(100.0 * a / n) << '%' << endl;
cout << round(100.0 * b / n) << '%' << endl;
return 0;
}
星系炸弹
在X星系的广袤空间中漂浮着许多X星人造“炸弹”,用来作为宇宙中的路标。
每个炸弹都可以设定多少天之后爆炸。
比如:阿尔法炸弹2015年1月1日放置,定时为15天,则它在2015年1月16日爆炸。
有一个贝塔炸弹,2014年11月9日放置,定时为1000天,请你计算它爆炸的准确日期。
以下程序实现了这一功能,请你填补空白处内容:
提示: json 先判断是否为闰年,这会影响2月份是28还是29,如果是闰年,2月份是29,如果不是,就是28
#include <stdio.h>
int main()
{
int monthDays[12] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
int days = 1000;
int year = 2014, month = 11, day = 9;
int i;
for (i = 0; i < days; i++)
{
day++;
if (day > monthDays[month - 1])
{
day = 1;
month++;
if (month > 12)
{
month = 1;
year++;
____________________;
}
}
}
printf("%d-%d-%d\n", year, month, day);
getchar();
return 0;
}if ((year % 400 == 0) || (year % 4 == 0 && year % 100 != 0))
monthDays[1] = 29;
else
monthDays[1] = 28;
判断闰年的依据:
闰年的计算方法:
①、普通年能被4整除且不能被100整除的为闰年。(如2004年就是闰年,1900年不是闰年)
②、世纪年能被400整除的是闰年。(如2000年是闰年,1900年不是闰年)
③、对于数值很大的年份,这年如果能整除3200,并且能整除172800则是闰年。如172800年是闰年,86400年不是闰年(因为虽然能整除3200,但不能整除172800)
闰年怎么来
地球绕日运行周期为365天5小时48分46秒(合365.24219天),即一回归年( tropical year)。公历的平年只有365日,比回归年短约0.2422 日,每四年累积约一天,把这一天加于2月末(即2月29日),使当年时间长度变为366日,这一年就为闰年。 需要注意的是,现在的公历是根据罗马人的儒略历改编而《中华民俗万年历》得。由于当时没有了解到每年要多算出0.0078天的问题,从公元前46年,到16世纪,一共累计多出了10天。为此,当时的教皇格列高利十三世,将1582年10月5日人为规定为10月15日。并开始了新闰年规定。即规定公历年份是整百数的,必须是400的倍数才是闰年,不是400的倍数的就是平年。比如,1700年、1800年和1900年为平年,2000年为闰年。此后,平均每年长度为365.2425天,约4年出现1天的偏差。按照每四年一个闰年计算,平均每年就要多算出0.0078天,经过四百年就会多出大约3天来,因此,每四百年中要减少三个闰年。闰年的计算,归结起来就是通常说的:四年一闰;百年不闰,四百年再闰。
由于地球的自转速度逐渐降低,而公转速度则相对更加稳定,所以上述的系统经过更长的周期也会发生微小的误差。据计算,每8000年会有一天的误差,所以英国的天文学家John Herschel提议公元4000为平年,以后类推12000年,20000年亦为平年。但此提议从未被正式采纳。原因是到了4000年,地球自转的精确速度并非现在可以预测,所以届时参照真实数据方可做出判断。因此,在长远的将来,针对闰年的微小调整应该不是由预定的系统决定,而是随时不定性的。
特别数的和
题目描述
小明对数位中含有 2、0、1、9 的数字很感兴趣(不包括前导 0),在 1 到 40 中这样的数包括 1、2、9、10 至 32、39 和 40,共 28 个,他们的和是 574。
请问,在 1 到 n 中,所有这样的数的和是多少?
输入格式
共一行,包含一个整数 n。
输出格式
共一行,包含一个整数,表示满足条件的数的和。
数据范围
1≤n≤10000输入样例:
40输出样例:
574以下代码实现了这一功能,请你填补空白处的内容:
#include <iostream>
using namespace std;
int ans, n;
bool check(int n)
{
while (n)
{
int tmpn = n % 10;
if (tmpn == 2 || tmpn == 0 || tmpn == 1 || tmpn == 9)
return true;
__________________;
}
return false;
}
int main()
{
cin >> n;
for (int i = 1; i <= n; i++)
{
if (check(i))
ans += i;
}
cout << ans << endl;
return 0;
}提示:
只要利用模除找出含有2,0,1,9的数即可
#include <iostream>
using namespace std;
bool check(int x)
{
while(x)
{
int t = x % 10;
if(t == 2 || t == 0 || t == 1 || t == 9) return true;
x /= 10;
}
return false;
}
int main()
{
int n;
cin >> n;
int ans = 0;
for (int i = 1; i <= n; i ++)
if(check(i))
ans += i;
cout << ans << endl;
return 0;
}
蛇形填数
如下图所示,小明用从1 开始的正整数“蛇形”填充无限大的矩阵。
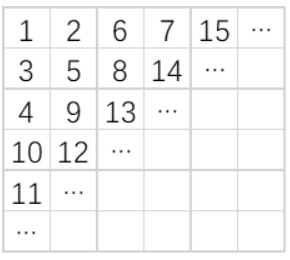
容易看出矩阵第二行第二列中的数是5。请你计算矩阵中第20 行第20 列的数是多少?
以下程序实现了这一功能,请你补全以下空白处内容:
提示:
当到达边界时,判断它应该向右走还是向下走,向右走完就直接向左下走,向下走完就直接向右上走#include <bits/stdc++.h>
using namespace std;
int main()
{
int i = 0;
int j = 0;
int cnt = 2;
int a[250][250];
a[0][0] = 1;
while (cnt < 1000)
{
j++;
while (i != -1 && j != -1)
{
a[i][j] = cnt++;
if (j == 0)
break;
i++;
j--;
}
i++;
while (i != -1 && j != -1)
{
___________;
}
}
for (int i = 0; i < 20; i++)
{
for (int j = 0; j < 20; j++)
{
cout << setw(5) << a[i][j] << ' ';
}
cout << '\n';
}
cout << a[19][19];
return 0;
}我们讨论 n n n行 n n n列位置上的数,可以发现要求这个 ( n , n ) (n,n) (n,n),可以通过求 p 1 p1 p1和 p 2 p2 p2,计算它们的平均数。 p 1 p1 p1是 n n n阶三角形的最大一个数, p 2 p2 p2是 n − 1 n-1 n−1阶三角形的最大一个数再加上1。
a n s w e r = ( f ( m ) + f ( m − 1 ) + 1 ) / 2 answer=(f(m)+f(m-1)+1)/2 answer=(f(m)+f(m−1)+1)/2
而 p 1 > p 2 p1>p2 p1>p2,且 p 1 p1 p1和 p 2 p2 p2都可通过计算三角形底边 m m m得到。从1开始累加到 m m m即可得到 n n n阶三角形中最大的数字。于是先计算底边 m m m。
f ( x ) = x ∗ ( x + 1 ) / 2 f(x)=x*(x+1)/2 f(x)=x∗(x+1)/2
不是每个三角形的底边都穿过 n n n行 n n n列,而是隔一个三角形才出现一个,由此出现线性关系 2 n 2n 2n。三角形最长的边为 m m m,代入 n = 2 n=2 n=2时, m = 5 m=5 m=5,由此有:
m = 2 n − 1 m=2n-1 m=2n−1
代码
#include<iostream>
using namespace std;
//计算从1累加到x的值
int f(int x){
return x*(x+1)/2;
}
int main(){
int n;
while(1){
cin>>n;
//计算三角形的底边
int m=2*n-1;
//大三角形+小三角形加一,两数取平均数
cout<<((f(m)+f(m-1)+1)/2)<<endl;
}
system("pause");
return 0;
}
*日志统计*(双指针)
题目描述
小明维护着一个程序员论坛。现在他收集了一份”点赞”日志,日志共有 N 行。
其中每一行的格式是:
ts id
表示在 ts 时刻编号 id 的帖子收到一个”赞”。
现在小明想统计有哪些帖子曾经是”热帖”。
如果一个帖子曾在任意一个长度为 D 的时间段内收到不少于 K 个赞,小明就认为这个帖子曾是”热帖”。
具体来说,如果存在某个时刻 T 满足该帖在 [T,T+D) 这段时间内(注意是左闭右开区间)收到不少于 K 个赞,该帖就曾是”热帖”。
给定日志,请你帮助小明统计出所有曾是”热帖”的帖子编号。
输入格式
第一行包含三个整数 N,D,K。
以下 N 行每行一条日志,包含两个整数 ts 和 id。
输出格式
按从小到大的顺序输出热帖 id。
每个 id 占一行。
数据范围
1≤K≤N≤10E5,
0≤ts,id≤10E5,
1≤D≤10000
输入样例:
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
输出样例:
1
3
下面的程序实现了这一功能,请你补全空白处的内容:
#include <bits/stdc++.h>
using namespace std;const int N = 1e5 + 10;
typedef pair<int, int> PII;
#define x first
#define y second
PII logs[N];
bool st[N];
int cnt[N];int main()
{
int n, d, k;
cin >> n >> d >> k;
for (int i = 0; i < n; i++)
cin >> logs[i].x >> logs[i].y;sort(logs, logs + n);
for (int i = 0, j = 0; i < n; i++)
{
cnt[logs[i].y]++;
while (logs[i].x - logs[j].x >= d)
__________________;
if (cnt[logs[i].y] >= k)
st[logs[i].y] = true;
}for (int i = 0; i < N; i++)
if (st[i])
cout << i << endl;
return 0;
}
提示:
尺取法
双指针
先根据时刻排序
因为序列是有序的,所以可以保证区间内的时刻是存在单调性的
所以我们只需要枚举每一个基准点,利用双指针基于该起始点右移,如果在范围内且大于等于 K K K个点赞,就存入答案
基准点右移时需要将该基准点的值减一,因为已经移除区间,不必再统计点赞个数。
O ( n l o g n ) O(nlogn) O(nlogn)
#include <iostream>
#include <algorithm>
using namespace std;
#define x first
#define y second
typedef pair<int,int> PII;
const int N = 100010;
PII w[N];
int cnt[N];
bool res[N]; // 存放答案
int n, d, k;
int main()
{
cin >> n >> d >> k;
int a, b;
for(int i = 0;i < n;i ++) {
scanf("%d%d",&a,&b);
w[i] = {a,b};
}
sort(w,w + n);
for(int i = 0,j = 0;i < n;i ++) {
while(j < n && w[j].x - w[i].x < d){
cnt[w[j].y] ++;
if(cnt[w[j].y] >= k) res[w[j].y] = true;
j ++;
}
cnt[w[i].y] --;
}
for(int i = 0;i < N;i ++)
if(res[i]) printf("%d\n",i);
return 0;
}猜年龄
【问题描述】
美国数学家维纳(N.Wiener)智力早熟,11岁就上了大学。他曾在1935~1936年应邀来中国清华大学讲学。
一次,他参加某个重要会议,年轻的脸孔引人注目。于是有人询问他的年龄,他回答说:
“我年龄的立方是个4位数。我年龄的4次方是个6位数。这10个数字正好包含了从0到9这10个数字,每个都恰好出现1次。”
请你推算一下,他当时到底有多年轻。
【问题分析】
穷举算法:对年龄进行穷举,从问题描述可以将年龄穷举范围定义在11~30之间(1~100也可以)。在穷举过程中对年龄进行检查,如果符合以下条件则输出结果
(1)年龄的立方是个4位数
(2)年龄的4次方是个6位数
(3)10个数字不重复
【程序代码】
1 public class 蓝桥杯_第四届_猜年龄
2 {
3 public static void main(String[] args) {
4 // TODO code application logic here
5 long t3=0,t4=0;
6 for(int i=11;i<30;i++)
7 {
8 String str="";
9 t3=i*i*i;
10 t4=i*i*i*i;
11 str=String.valueOf(t3) + String.valueOf(t4);
12 if(str.length()!=10)
13 continue;
14 else if(noRepeat(str))
15 {
16 System.out.print(i);
17 break;
18 }
19 }
20 }
21
22 public static boolean noRepeat(String str)
23 {
24 for(int j=0;j<str.length()-1;j++)
25 {
26 char x=str.charAt(j);
27 for(int m=j+1;m<str.length();m++)
28 {
29 char y=str.charAt(m);
30 if(y==x)
31 {
32 return false;
33 }
34 }
35 }
36 return true;
37 }
38 }【运行结果】
18
【相关知识】
数值与字符串之间的转换
字符串重复检测
【类似问题】
蓝桥杯/第五届/猜年龄
转载于:https://www.cnblogs.com/yzzdzy/p/4364675.html
合并检测
新冠疫情由新冠病毒引起,最近在 A 国蔓延,为了尽快控制疫情,A 国准 备给大量民众进病毒核酸检测。
然而,用于检测的试剂盒紧缺。为了解决这一困难,科学家想了一个办法:合并检测。即将从多个人(k 个)采集的标本放到同一个试剂盒中进行检测。如果结果为阴性,则说明这 k 个人都是阴性,用一个试剂盒完成了 k 个人的检测。如果结果为阳性,则说明 至少有一个人为阳性,需要将这 k 个人的样本全部重新独立检测(从理论上看, 如果检测前 k−1 个人都是阴性可以推断出第 k 个人是阳性,但是在实际操作中 不会利用此推断,而是将 k 个人独立检测),加上最开始的合并检测,一共使用 了 k + 1 个试剂盒完成了 k 个人的检测。
A 国估计被测的民众的感染率大概是 1%,呈均匀分布。请问 k 取多少能最节省试剂盒?
以下程序实现了这一功能,请你补全以下空白处内容:
#include <stdio.h>
int main()
{
double m = 4537;
double min = 9999999;
double k, sum, ans;
for (k = 1; k <= 100; k++)
{
sum = (m - k) / k + 0.01 * m * k + 1;
__________________;
}
printf("%d\n", (int)ans);
return 0;
}提示:
设检测人数为100人,根据概率为1%,则只有1个为阳性。k个人一组,则需要的试剂数量为:对所有分组进行合并检测所需要的试剂数100/k+其中1个分组阳性所需要的试剂数k+未分组人数所需的试剂数量。
因为感染率是百分之一
并且感染率服从均匀分布
所以结果应是1到99之间的一个数.
为了方便计算取整
我们每次假设i个人用一个试剂盒,有100 * i个人参加了检测
那么统一检测每次需要100个试剂盒
由于呈均匀分布所以每100人都会出现一个病例
一个病例需要i个试剂盒
总共有i个病例
所以总共需要need = 100 + i * i 个试剂盒
最后我们在data种添加每百人平均消耗试剂盒和当前i值
对试剂盒消耗量排序
输出最小每百人平均消耗试剂盒对应的人数 i 即可
Code
data = []
for i in range(1, 100):
need = 100 + i * i
data.append([need / i, i])
data.sort(key=lambda x: x[0])
print(data[0][1])
Answer
10
排它平方数
203879 * 203879 = 41566646641
这有什么神奇呢?仔细观察,203879 是个6位数,并且它的每个数位上的数字都是不同的,并且它平方后的所有数位上都不出现组成它自身的数字。
具有这样特点的6位数还有一个,请你找出它!
再归纳一下筛选要求:
- 6位正整数
- 每个数位上的数字不同
- 其平方数的每个数位不含原数字的任何组成数位
以下程序实现了这一功能,请你补全以下空白处内容:
#include <iostream>
using namespace std;
int main()
{
int num[10], flag;
for (long long i = 123456; i <= 987654; i++)
{
long long a = i;
long long b = i * i;
memset(num, 0, sizeof(num));
flag = 1;
while (a)
{
_________________;
}
if (flag)
{
while (b)
{
if (num[b % 10])
{
flag = 0;
break;
}
b /= 10;
}
if (flag)
cout << i << endl;
}
}
return 0;
}提示:
0的平方为0
1的平方为1
5的平方为5
6的平方为6
以上这4个数字都不能作为原数字的最后一位,可以在最后一位排除
且第一位不能为0#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <unordered_map>
#define x first
#define y second
using namespace std;
typedef pair<int, int> PII;
int main()
{
int n;
cin >> n;
unordered_map<int, PII> ans;
for(int c = 0; c * c <= n; c ++ )//枚举C和D
for(int d = c; d * d + c * c <= n; d ++ )
{
int t = c * c + d * d; //存下来这两个数的平方和
if(ans.count(t) == 0) ans[t] = {c, d};
}
for(int a = 0; a * a <= n; a ++ )
for(int b = a; b * b + a * a <= n; b ++ )
{
int t = n - a * a - b * b;//看A和B的平方和还和目标差多少,看看之前存的有没有这个数
if(ans.count(t) != 0)
{
printf("%d %d %d %d\n", a, b, ans[t].x, ans[t].y);
return 0;
}
}
return 0;
}
问题解决的中心思想是: 通过数组num[10], 初始化后全0状态,a的每位取数后置非0(考虑重复),然后再后面b取位时看a[X]的非零状态,如果取到是非零那就是重复了,如果是零,那就是之前没有置,表示不重复,flag直到B取尽后才能保证true.才证明这个数字符合要求。
所以上述代码,穷尽法做num[a%10]++运算就行了,没有必要考虑位数值是0情况,当然,考虑0,1,5,6就是条件规避,场景更细致些。
题目合理利用数值置位方式表示是否取到过,这个做法不错
*四平方和定理*
四平方和定理,又称为拉格朗日定理:
每个正整数都可以表示为至多 4 个正整数的平方和。
如果把 0 包括进去,就正好可以表示为 4 个数的平方和。
比如:
5=02+02+12+22
7=12+12+12+22
对于一个给定的正整数,可能存在多种平方和的表示法。
要求你对 4 个数排序:
0≤a≤b≤c≤d
并对所有的可能表示法按 a,b,c,d 为联合主键升序排列,最后输出第一个表示法。
输入格式
输入一个正整数 N。
输出格式
输出4个非负整数,按从小到大排序,中间用空格分开。
数据范围
0<N<5∗106
输入样例:
5
输出样例:
0 0 1 2
题解:
首先,三重循环枚举a,b,c最后确定出来d,O(N3)的复杂度,大概率通过不了
这时候就用空间来换取时间
1:首先我们先枚举C和D,将所有组合的平方和进行一个记录
2:然后枚举A和B,算出来跟输入的数字差了几,然后看之前存放的有没有这一项
3:找到这一个然后进行输出
这里又要求到了按字典序排序的问题,首先我们的A和B的枚举方法肯定是没有问题的,一定是A<B的,那么看C和D;C和D用的哈希表存放,也是在枚举的时候确定了一个字典序的,如果这个数字存在了,在找到相同数字的时候是不会进行更新操作的,所以字典序也一定是成立的。代码如下:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <unordered_map>
#define x first
#define y second
using namespace std;
typedef pair<int, int> PII;
int main()
{
int n;
cin >> n;
unordered_map<int, PII> ans;
for(int c = 0; c * c <= n; c ++ )//枚举C和D
for(int d = c; d * d + c * c <= n; d ++ )
{
int t = c * c + d * d; //存下来这两个数的平方和
if(ans.count(t) == 0) ans[t] = {c, d};
}
for(int a = 0; a * a <= n; a ++ )
for(int b = a; b * b + a * a <= n; b ++ )
{
int t = n - a * a - b * b;//看A和B的平方和还和目标差多少,看看之前存的有没有这个数
if(ans.count(t) != 0)
{
printf("%d %d %d %d\n", a, b, ans[t].x, ans[t].y);
return 0;
}
}
return 0;
}*大数乘法*
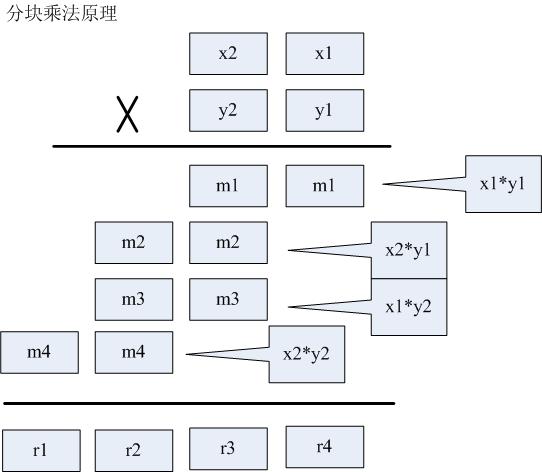
对于32位字长的机器,大约超过20亿,用int类型就无法表示了,我们可以选择int64类型,但无论怎样扩展,固定的整数类型总是有表达的极限!如果对超级大整数进行精确运算呢?一个简单的办法是:仅仅使用现有类型,但是把大整数的运算化解为若干小整数的运算,即所谓:“分块法”。
上图表示了分块乘法的原理。可以把大数分成多段(此处为2段)小数,然后用小数的多次运算组合表示一个大数。可以根据int的承载能力规定小块的大小,比如要把int分成2段,则小块可取10000为上限值。注意,小块在进行纵向累加后,需要进行进位校正。
请从以下四个选项中选择正确答案,填补在空白处,使得代码能运行后能产生正确的结果。
提示:
十进制数的进位问题#include <bits/stdc++.h>
using namespace std;
void bigmul(int x, int y, int r[])
{
int base = 10000;
int x2 = x / base;
int x1 = x % base;
int y2 = y / base;
int y1 = y % base;
int n1 = x1 * y1;
int n2 = x1 * y2;
int n3 = x2 * y1;
int n4 = x2 * y2;
r[3] = n1 % base;
r[2] = n1 / base + n2 % base + n3 % base;
r[1] = __________________;
r[0] = n4 / base;
r[1] += r[2] / base;
r[2] = r[2] % base;
r[0] += r[1] / base;
r[1] = r[1] % base;
}
int main(int argc, char *argv[])
{
int x[] = {0, 0, 0, 0};
bigmul(87654321, 12345678, x);
printf("%d%d%d%d\n", x[0], x[1], x[2], x[3]);
return 0;
}