一、模型参数量
参数量的单位
参数量指的是模型中所有权重和偏置的数量总和。在大模型中,参数量的单位通常以“百万”(M)或“亿”(B,也常说十亿)来表示。
百万(M):表示一百万个参数。例如,如果一个模型有110M个参数,那么它实际上有110,000,000(即1.1亿)个参数。
亿(B):表示十亿个参数。例如,GPT-3模型有175B个参数,即175,000,000,000(即1750亿)个参数。
二、内存数据量的单位
在大数据和机器学习的语境下,数据量通常指的是用于训练或测试模型的数据的大小。数据量的单位可以是字节(Byte)、千字节(KB)、兆字节(MB)、吉字节(GB)等。
字节(Byte):是数据存储的基本单位。一个字节由8个比特(bit)组成。
千字节(KB):等于1024个字节。
兆字节(MB):等于1024个千字节,也常用于表示文件或数据的大小。
吉字节(GB):等于1024个兆字节,是较大的数据存储单位。
在大模型中,由于模型参数通常是以浮点数(如float32)存储的,因此可以通过模型参数量来计算模型所需的存储空间大小。例如,如果一个模型有1.1亿个参数,并且每个参数用float32表示(即每个参数占4个字节),那么该模型所需的存储空间大约为44MB(1.1亿×4字节/1024/1024)。
bit(比特):bit是二进制数字中的位,是信息量的最小单位。在二进制数系统中,每个0或1就是一个bit。bit是计算机内部数据存储和传输的基本单位。在数据传输过程中,通常以bit为单位来表示数据的传输速率或带宽。
字节(Byte)定义:字节是计算机信息技术用于计量存储容量的一种单位,也表示一些计算机编程语言中的数据类型和语言字符。字节通常由8个bit组成。字节是计算机中数据处理的基本单位。在存储数据时,通常以字节为单位来表示数据的大小或容量。
bit和字节的关系:1字节(Byte)等于8比特(bit)。在计算机科学中,经常需要将数据的大小从字节转换为比特,或者从比特转换为字节。例如,在数据传输过程中,如果知道数据的传输速率是以比特每秒(bps)为单位的,那么可以通过除以8来将其转换为字节每秒(Bps)的单位。

三、模型参数精度
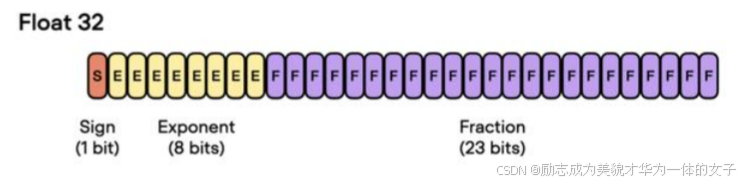
单精度浮点数 (32位) - float32:
含义:单精度浮点数用于表示实数,具有较高的精度,适用于大多数深度学习应用。
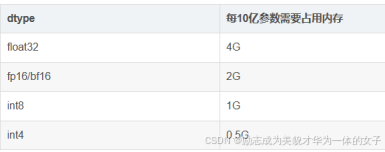
字节数:4字节(32位)
半精度浮点数 (16位) - float16:
含义:半精度浮点数用于表示实数,但相对于单精度浮点数,它的位数较少,因此精度稍低。然而,它可以在某些情况下显著减少内存占用并加速计算。
字节数:2字节(16位)
双精度浮点数 (64位) - float64:
含义:双精度浮点数提供更高的精度,适用于需要更高数值精度的应用,但会占用更多的内存。
字节数:8字节(64位)
整数 (通常为32位或64位) - int32, int64:
含义:整数用于表示离散的数值,可以是有符号或无符号的。在某些情况下,例如分类问题中的标签,可以使用整数数据类型来表示类别。
字节数:通常为4字节(32位)或8字节(64位)
int4 (4位整数):
含义:int4使用4位二进制来表示整数。在量化过程中,浮点数参数将被映射到一个有限的范围内的整数,然后使用4位来存储这些整数。
字节数:由于一个字节是8位,具体占用位数而非字节数,通常使用位操作存储。
int8 (8位整数):
含义:int8使用8位二进制来表示整数。在量化过程中,浮点数参数将被映射到一个有限的范围内的整数,然后使用8位来存储这些整数。
字节数:1字节(8位)
量化:在量化过程中,模型参数的值被量化为最接近的可表示整数,这可能会导致一些信息损失。因此,在使用量化技术时,需要平衡压缩效果和模型性能之间的权衡,并根据具体任务的需求来选择合适的量化精度。
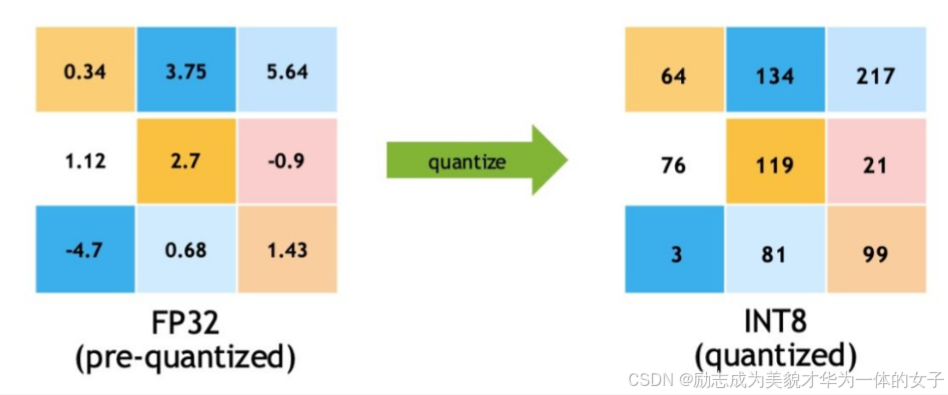
1B int8的存储需要1GB的显存
四、训练显存
模型参数
梯度
存储梯度所需的内存等于参数本身所需的内存。由于每个参数都有相应的梯度,因此它们的内存要求相同。
梯度内存 = 参数内存
优化器
优化器状态是某些优化算法(如 Adam、RMSprop)维护的附加变量,用于提高训练效率。这些状态有助于根据过去的梯度更新模型参数。
不同的优化器维护不同类型的状态。例如:
SGD(随机梯度下降):没有附加状态;仅使用梯度来更新参数。
Adam:为每个参数维护两个状态:一阶矩(梯度平均值)和二阶矩(梯度平方平均值)。这有助于动态调整每个参数的学习率。对于具有 100 万个参数的模型,Adam 需要为每个参数维护 2 个附加值(一阶矩和二阶矩),从而产生 200 万个附加状态。
优化器状态的内存 = 参数数量 x 精度大小 x 优化器乘数
激活
激活指的是什么
前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。激活值大小与批次大小和序列长度有关。
输入数据和标签:
训练模型需要将输入数据和相应的标签加载到显存中。这些数据的大小取决于每个批次的样本数量以及每个样本的维度。
中间计算:
在前向传播和反向传播过程中,可能需要存储一些中间计算结果,例如激活函数的输出、损失值等。
临时缓冲区:
在计算过程中,可能需要一些临时缓冲区来存储临时数据,例如中间梯度计算结果等。减少中间变量也可以节省显存,这就体现出函数式编程语言的优势了。
没有固定的公式来计算激活的 GPU 内存。
以llama int 8 7B为例:
-
数据类型:Int8
-
模型参数: 7B * 1 bytes = 7GB
-
梯度:同上7GB
-
优化器参数: AdamW 2倍模型参数 7GB * 2 = 14GB
-
LLaMA的架构(hidden_size= 4096, intermediate_size(前馈网络神经元的个数)=11008, num_hidden_lavers= 32, context.length = 2048),所以每个样本大小:(4096 + 11008) * 2048 * 32 * 1byte = 990MB
-
A100 (80GB RAM)大概可以在int8精度下BatchSize设置为50
-
综上总现存大小:7GB + 7GB + 14GB + 990M * 50/1024 ~= 77GB
五、推理显存
-
模型加载: 计算模型中所有参数的大小,包括权重和偏差。
-
确定输入数据尺寸: 根据模型结构和输入数据大小,计算推理过程中每个中间计算结果的大小。
-
选择批次大小: 考虑批处理大小和数据类型对显存的影响。
大概是1.2倍的模型参数权重。
六、显卡以及zero优化显存
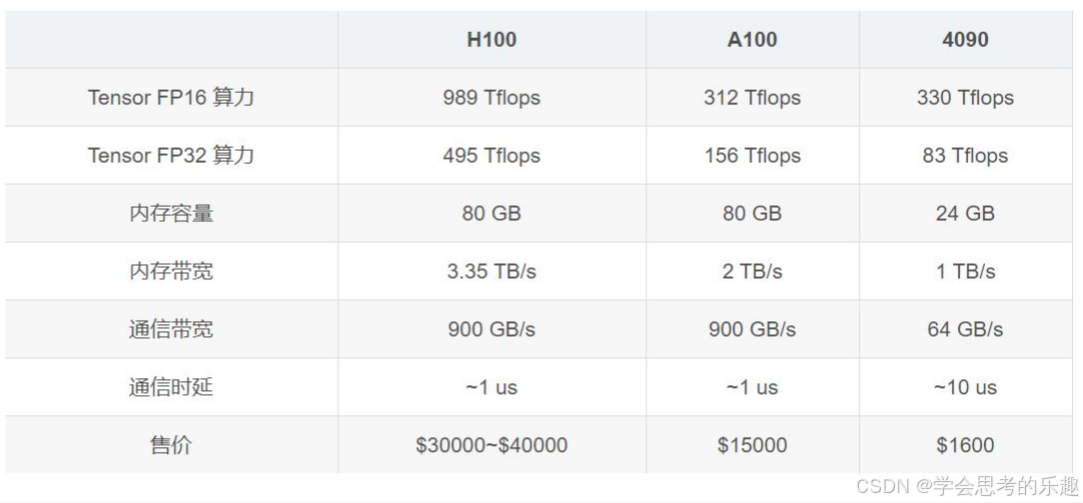
大模型在训练或者微调时需要的显卡个数其实与选择的分布式训练方法和微调方法有关。
比如大概120GB的内存如果单卡训练需要两张A100的显卡。
如果我们采用多卡训练同时运用zero的思想。那么显存变化情况可以参考下图:
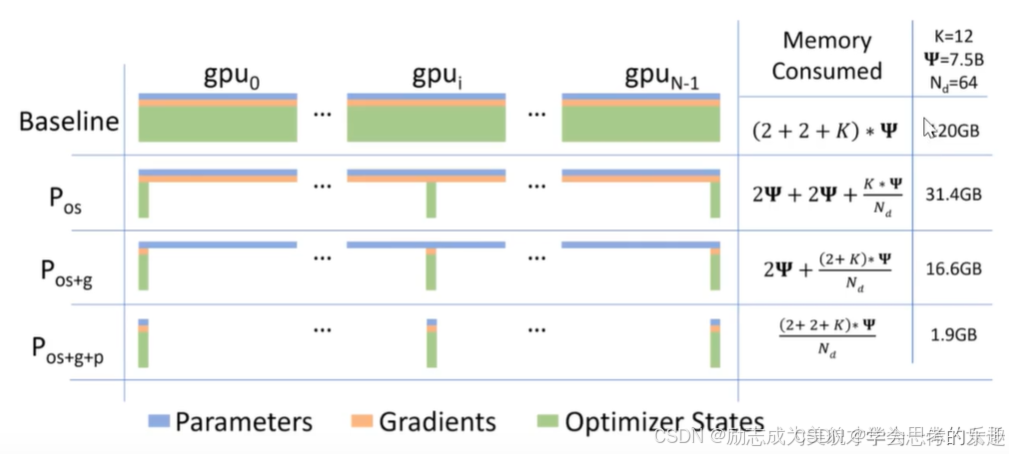
如果采用数据并行。模型并行:如果模型被均匀分割,那么可能需要与模型层数成比例的显卡数量。
参考说明
开源大模型训练及推理所需显卡成本必读:也看大模型参数与显卡大小的大致映射策略_大模型 6b 13b是指什么-CSDN博客
大模型训练时的激活值显存占用 - 知乎






![[王阳明代数讲义]具身智能才气等级分评价排位系统领域投射模型讲义](https://i-blog.csdnimg.cn/direct/5593a120ff514d058e96f601782d6d1c.jpeg#pic_center)