环境变量与进程地址空间
- 环境变量
- 什么是环境变量
- 常见环境变量
- 环境变量相关命令
- 环境变量的全局属性
- PWD
- main函数的三个参数
- 进程地址空间
- 什么是进程地址空间
- 进程地址空间,页表,内存的关系
- 为什么存在进程地址空间
环境变量
什么是环境变量
我们所有写的程序都需要指定路径才能运行,就像这样:(程序里面是打印DLC循环)
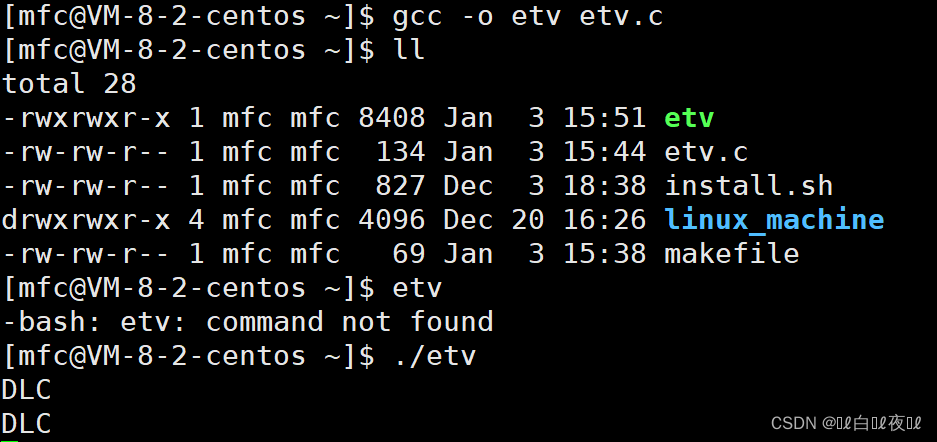


生成的etv是一个可执行程序,但是我们平时使用的指令比如 ls 等等也都是可执行程序,但是并不需要指定目录在哪里才可以使用。
如果将刚才写的etv程序拷贝到/usr/bin 会不会与ls一样可以直接使用?

这样是可以的,但是非常不建议,因为这个程序相当于安装到了系统中,Linux下拷贝就是安装。
那么系统是如何找到的,是因为有一个环境变量——PATH,他在全局都是有效的,是系统默认的指令搜索路径(想查看前面加$):

这是查看PATH环境变量中的内容,用 : 隔开的是不同路径。
添加路径:
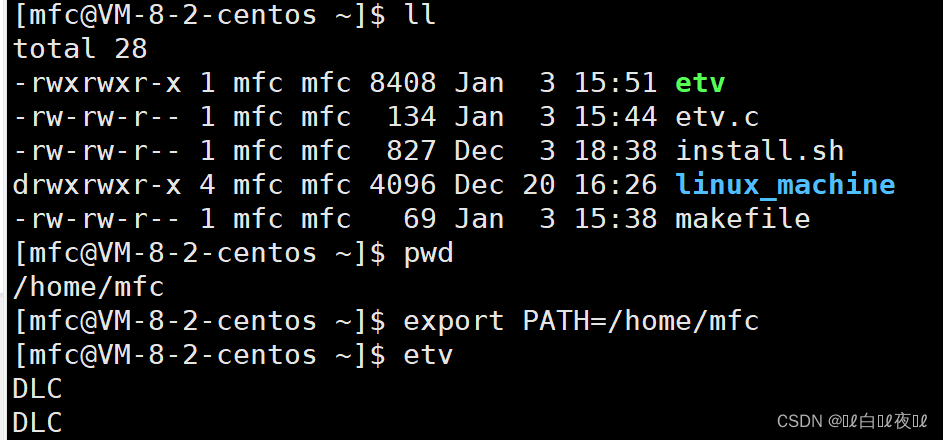
只不过这样也就等于把原来的路径覆盖了,只剩下的/home/mfc这个目录了,也就等于在想执行 sl 这种就需要取指定目录才可以。
不过不用担心,重新登陆Linux就可以了,因为这是内存上的改变。
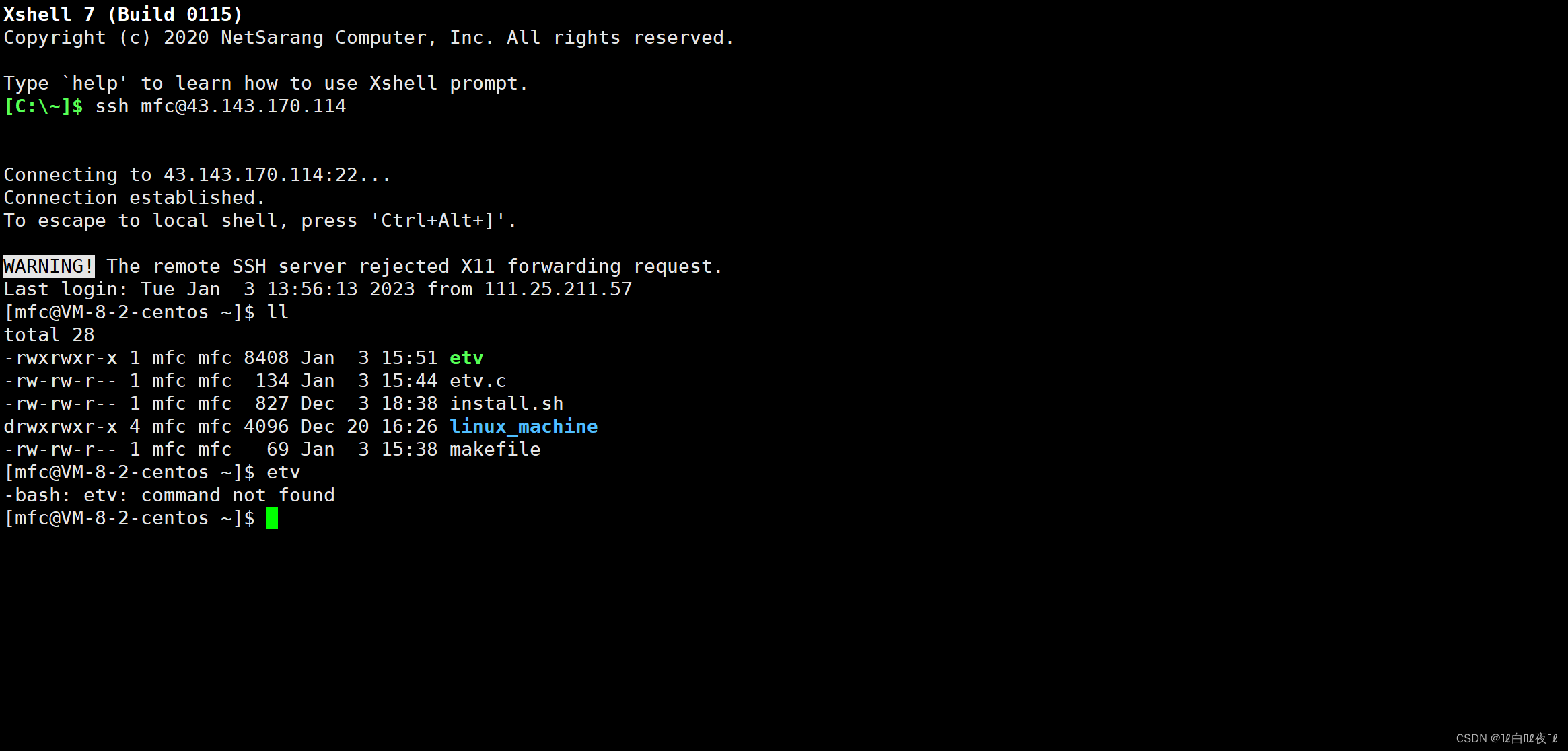
那么我们需要保留原来的并且再添加新的:
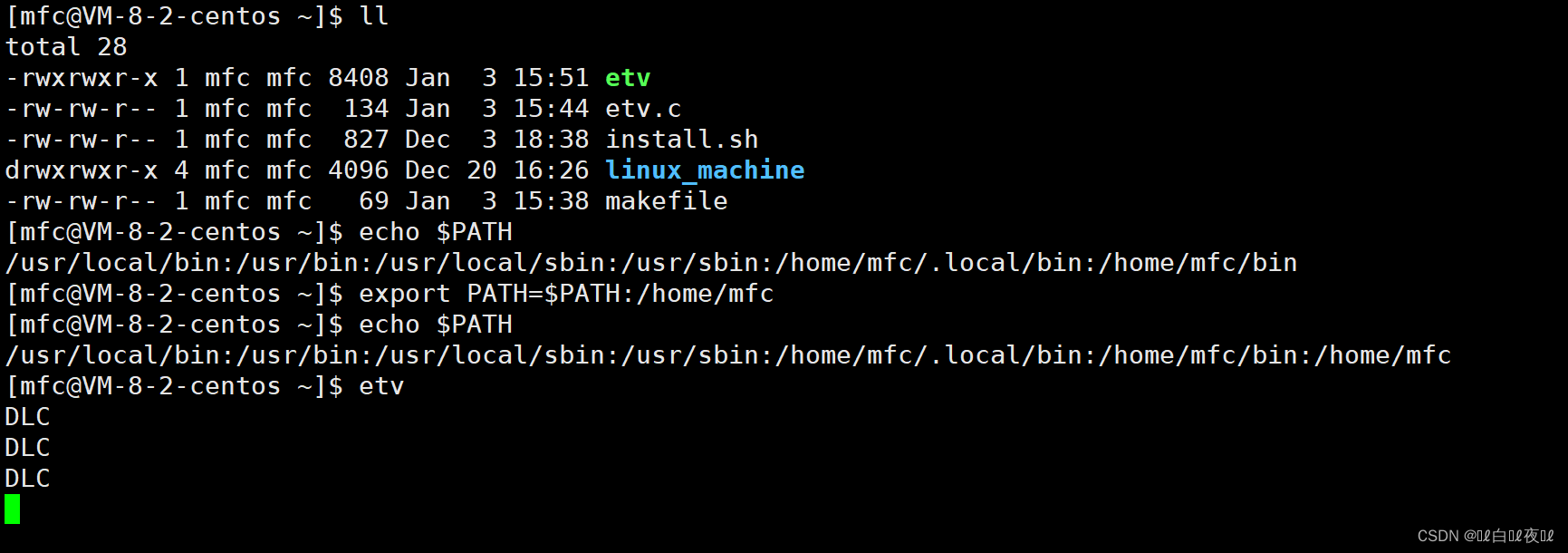
这样也不会影响原来的sl等。
在打开Linux的时候bash因为要处理用户的命令,这些命令也是程序,运行程序需要指定路径,所以操作系统就提前将这些指令的路径放在了专属的配置文件,在启动操作系统时将这个文件导入内存中形成一个内存级变量,这就是环境变量。
那么最开始的环境变量是怎么来的呢?
这两个文件里面内容是脚本,内容就是将环境变量导入当前的shell中(这个环境变量是内存级的)。
常见环境变量
HOME 当前用户的工作目录
HOSTNAME 当前主机名
LOGNAME 当前用户名
HISTSIZE 显示储存多少命令内容(历史输入的命令,有一个命令可以查看历史输入的命令,history)

环境变量相关命令
echo: 显示某个环境变量值(记得加$)
export: 设置一个新的环境变量
env: 显示所有环境变量
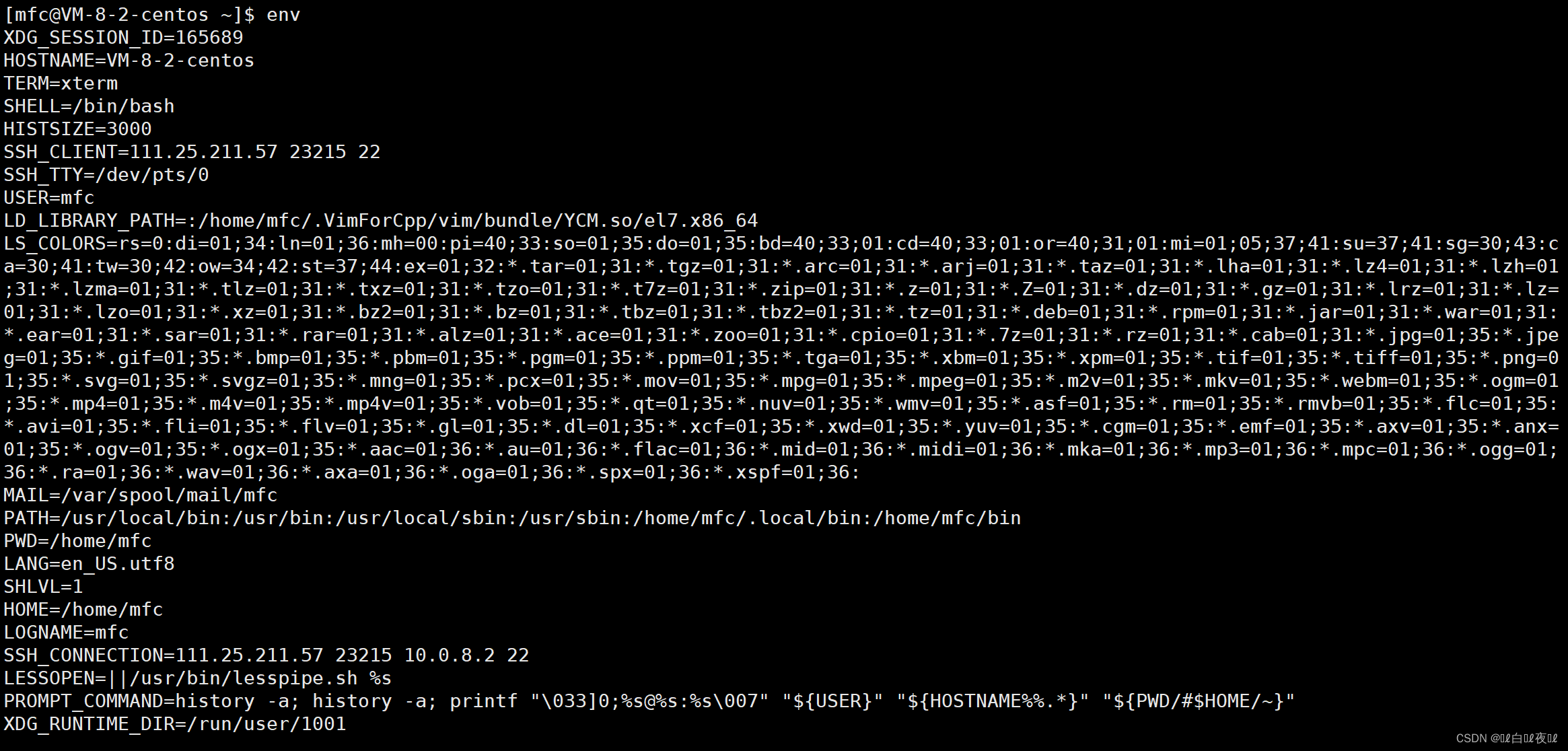
unset: 清除环境变量
set: 显示本地定义的shell变量和环境变量
环境变量的全局属性
我们也可以定义本地变量:

但是本地变量是无法被子进程继承,我们用一段代码来验证:
参数是定义的变量,如果有这个环境变量就返回一个数值,没有就返回空指针。
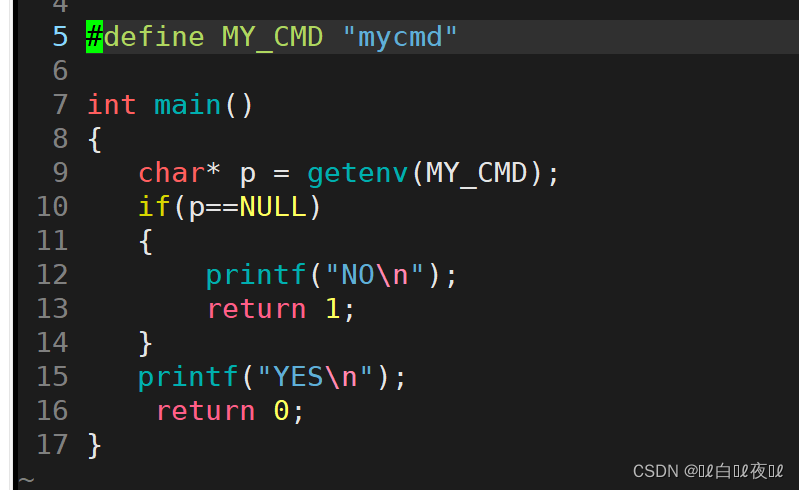
这是因为我们刚才定义的变量是在bash上的,bash是一个系统进程,我们的etv是一个可执行文件,运行起来也是一个进程,就是bash的子进程,刚才定义的变量也叫本地变量,不具有全局属性,所以没有传到etv进程里面,就像C语言当中的全局变量和局部变量一样。

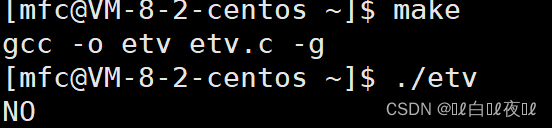
这里将本地变量变成环境变量。
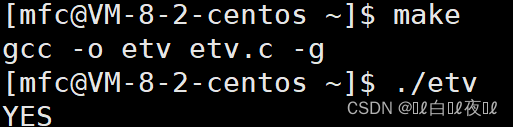
环境变量是具有全局属性的,会被子进程继承下去。
PWD
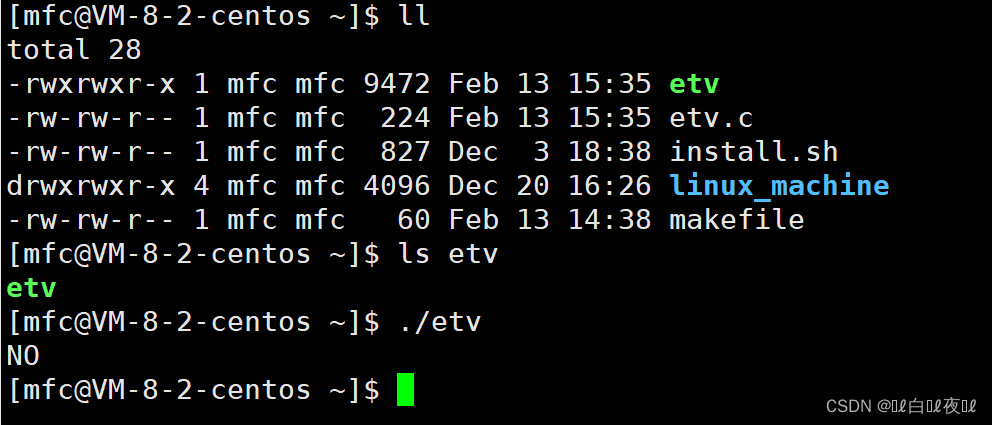
执行可执行程序在当前路径是需要带路径的,但是ls并不需要,这是为什么呢?
因为有一个环境变量PWD是当前路径:
 上面我们知道了环境变量会被子进程继承,ls是bash的子进程,所以继承了这个环境变量,就知道了当前路径,所以可以这样执行命令:
上面我们知道了环境变量会被子进程继承,ls是bash的子进程,所以继承了这个环境变量,就知道了当前路径,所以可以这样执行命令:
main函数的三个参数
在调用某个程序的时候是调用main函数然后才开始运行,那么我们在调用某个程序的时候会带选项,其实这些选项就是前两个参数,第三个参数就是环境变量的参数。
argc是代表有多少个选项,argv[]是一个指针数组,里面是char*,储存的就是程序名与选项,env[]是储存环境变量的指针数组。
先来看看argv与argv[]:
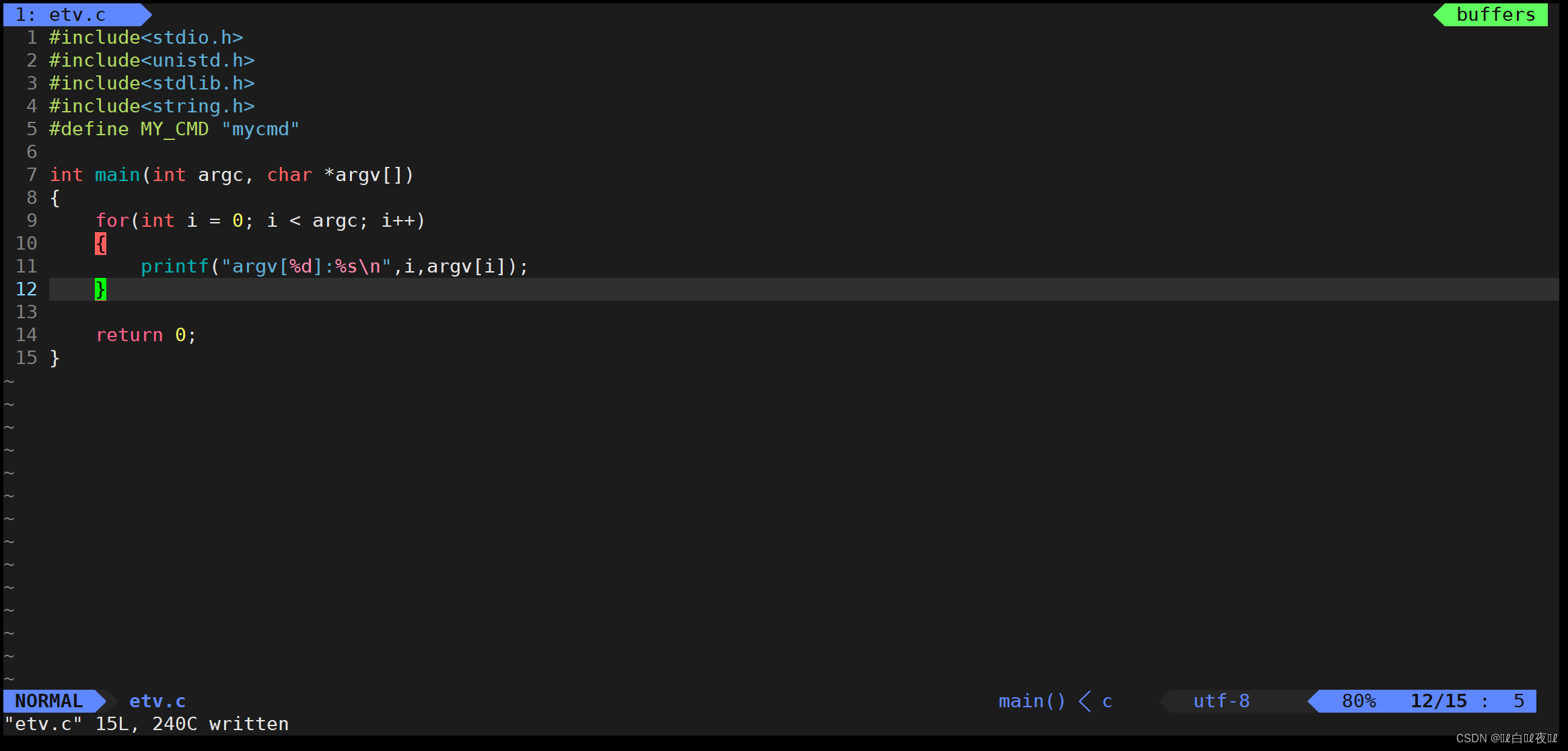
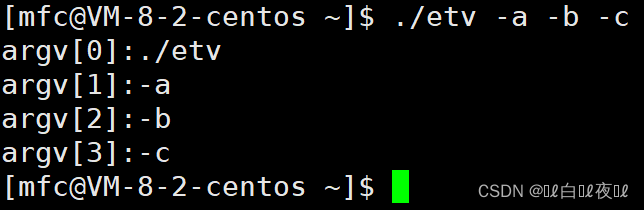
对着这段命令行解析是这样的:
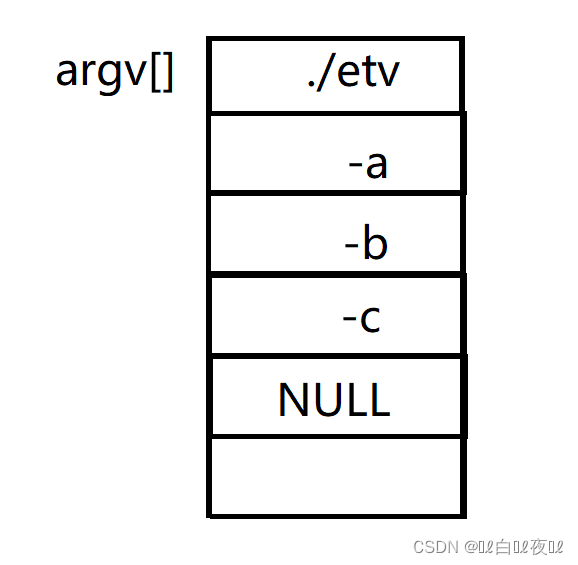
这个过程是由shell和系统来完成的。
这时就平时带选项程序是如何完成各个功能的原因。
然后来看看第三个参数:
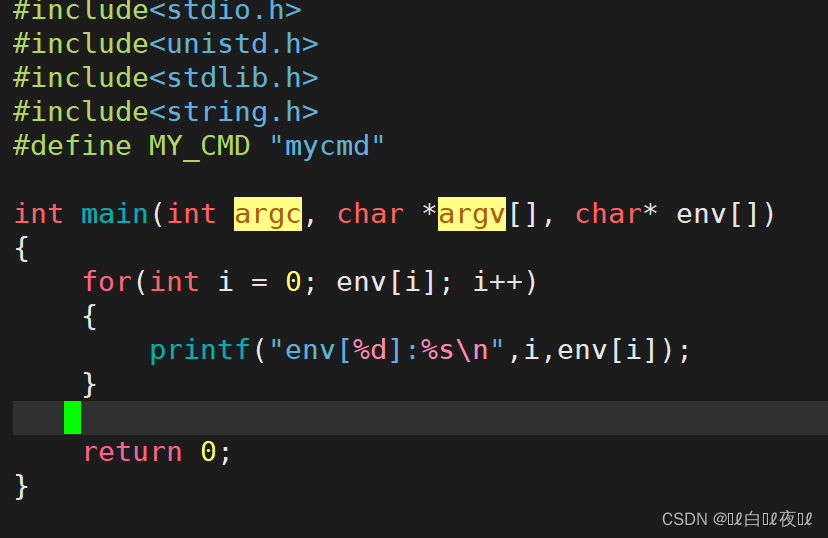
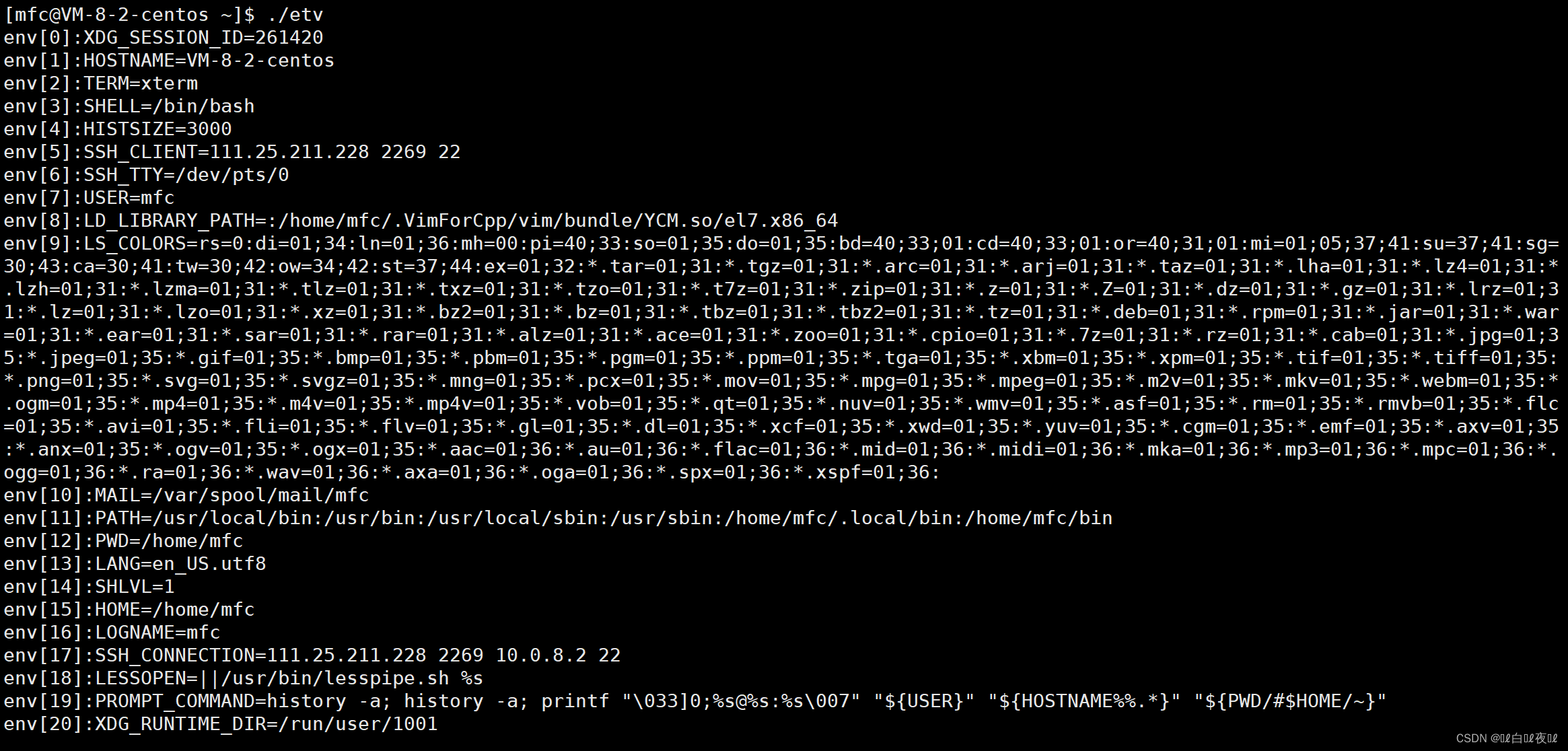
这里就是环境变量了。
当然获取环境变量还有一种方法,C语言提供了一个第三方的变量:
这个是全局环境变量的指针,也就是指向env[]那个表,这样main函数不用传参也可以获取环境变量。
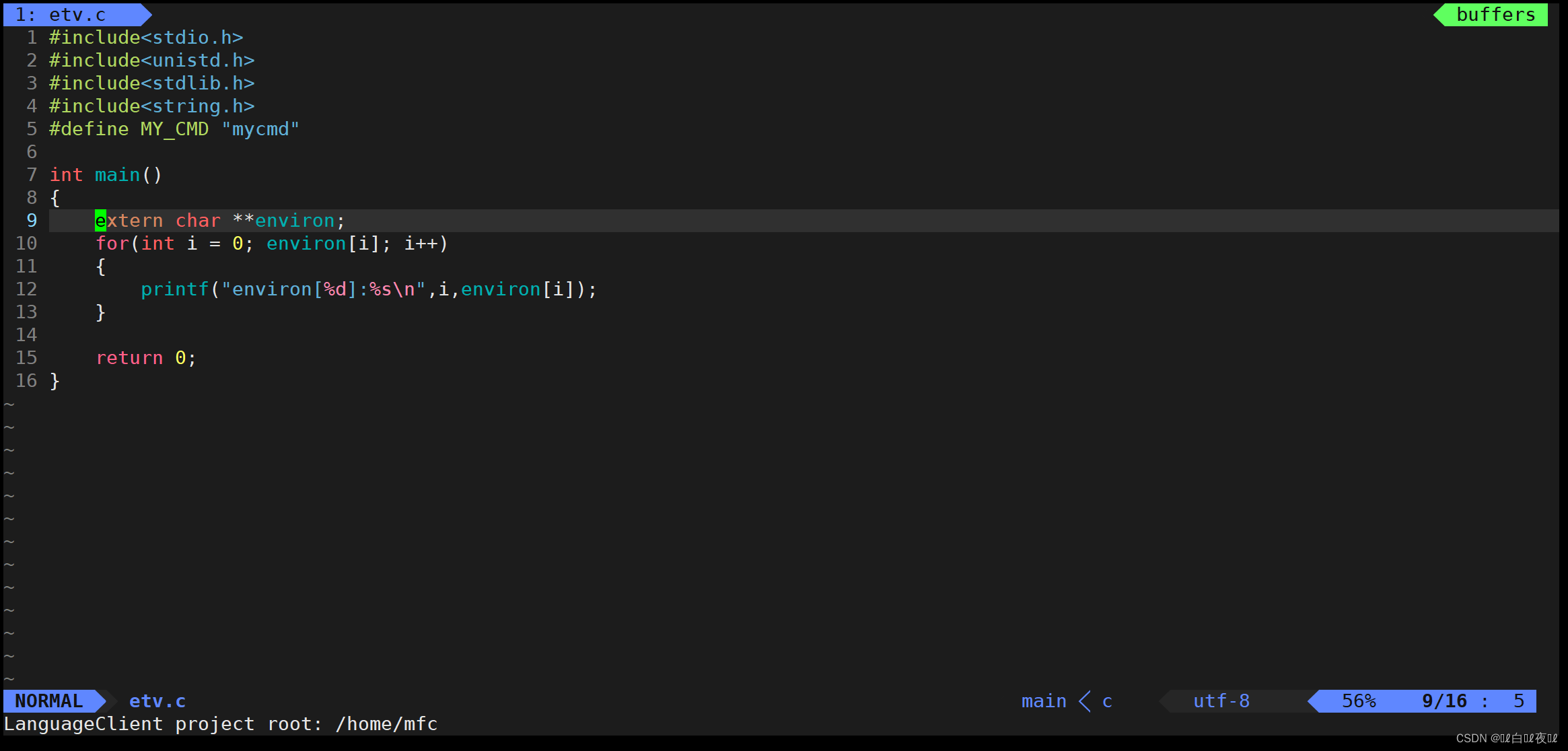
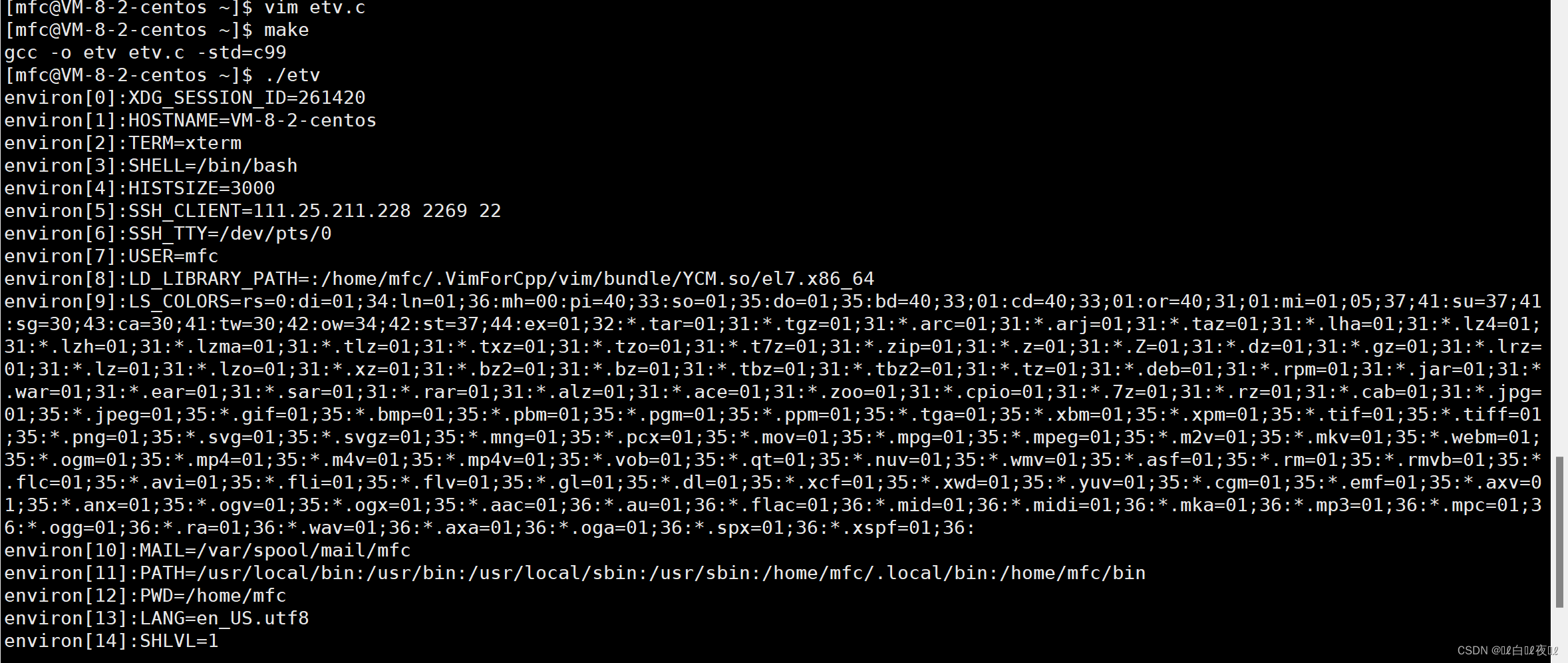
使用之前必须声明一下自己要用environ变量。
进程地址空间
之前有过一张在C/C++语言层面上的地址空间图:
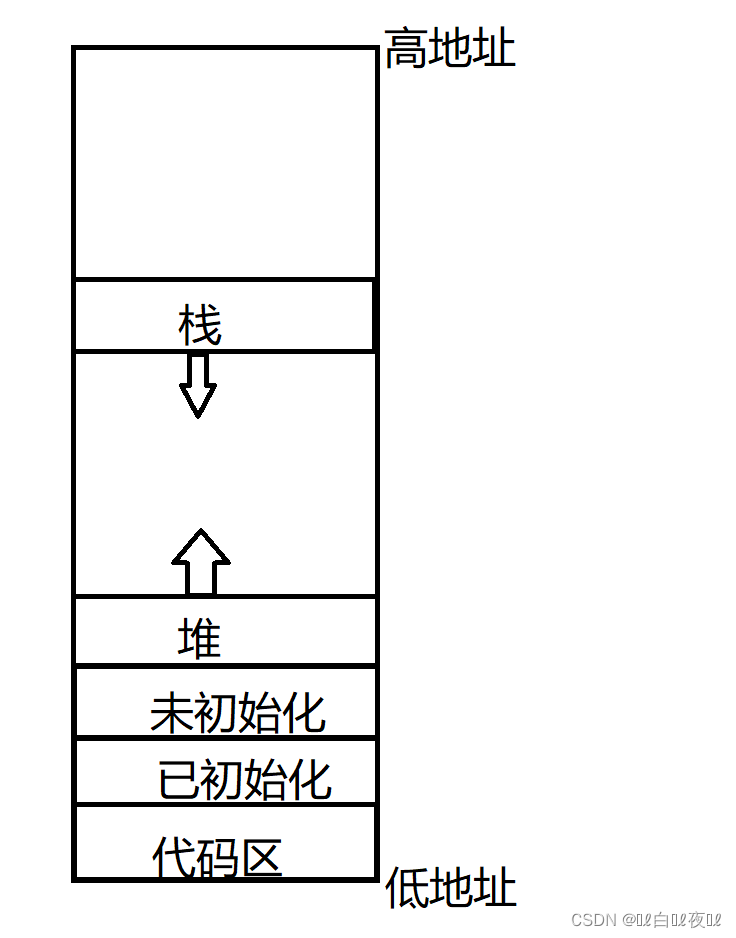
磁盘上面写的程序都是需要先加载到内存里才能运行的,那么这张图是物理方面的内存嘛?并不是,来看这段代码:
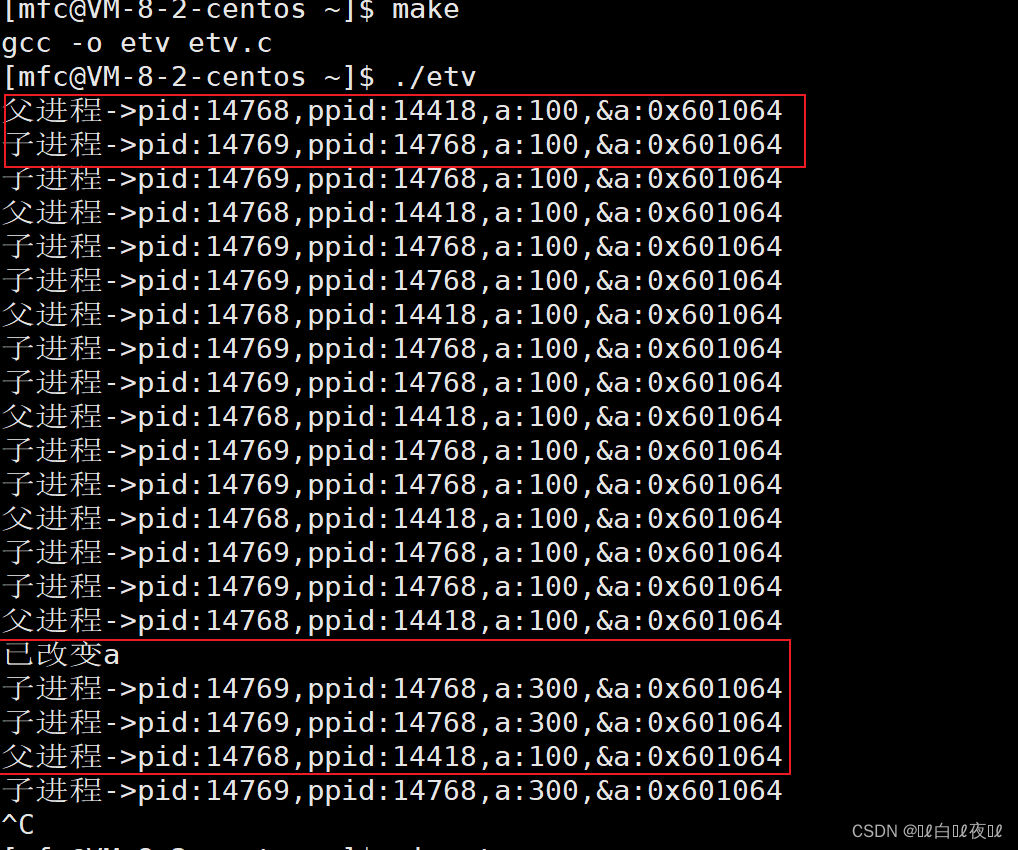
每个进程都是有独立性的,按理来说应该是都有单独的空间,可是在两个进程运行中,全局变量a的地址竟然是一样的,这难道说明a是被两个进程公用的吗?但是a在子进程当中又被改掉了,可是父进程当中的却没有改变,地址也完全相同。
这是因为当前显示a的地址是虚拟地址。
我们之前在用VS编译器调试的时候看到的地址都是虚拟地址,物理地址普通用户看不到,这些都由操作系统来管理。
什么是进程地址空间
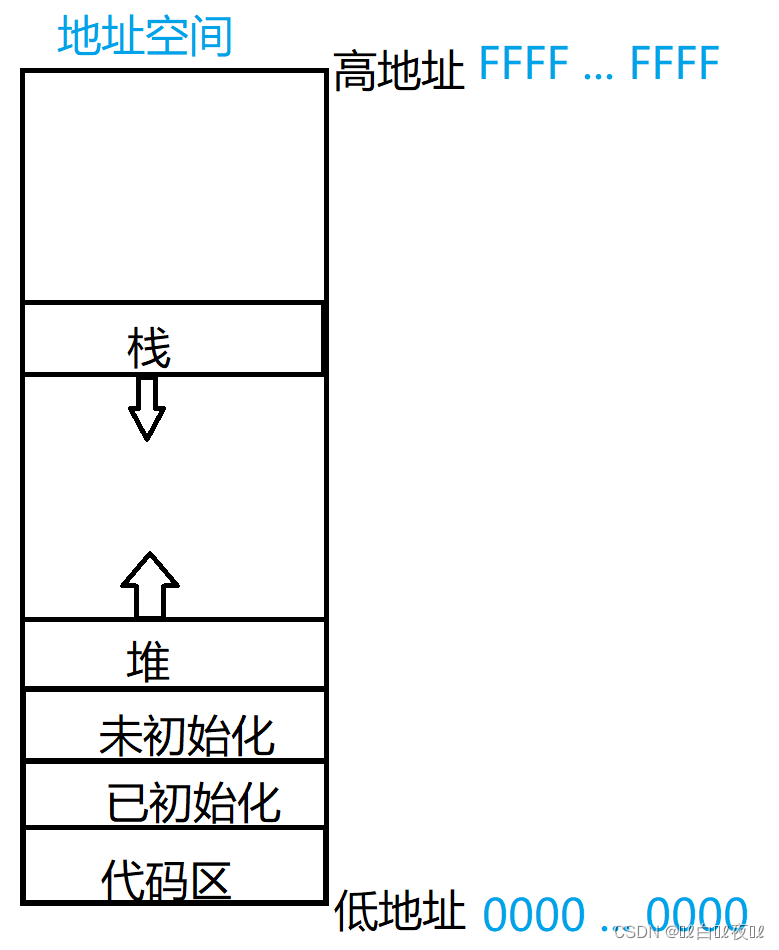
下面我用32位机器举例子。
那么既然地址空间是虚拟空间,到底有什么用处,到底是怎么实现的呢?
虚拟空间是操作系统防止用户把物理内存给玩坏所弄出来的空间,是通过页表来进行映射和管理的:
在32位的机器中,操作系统会给每个进程“画个大饼”,说你们每个进程都可以分配到2^32字节(约等于4GB)的空间大小,并且每个地址都是独立不冲突的。
普通进程当然不可能一下子全都使用掉,所以理论上来说每个进程都可以有4GB的空间,但是如果某个进程需要的不是特别多或者是需要的特别多,这个时候操作系统就会调整大小了。
首先来看看进程地址空间是什么原理:
在linux源码当中,地址空间是一个mm_struct的数据结构,大概是这样的
struct mm_struct
{
uint32_t code_start,code_end;
uint32_t data_start,data_end;
uint32_t heap_start,heap_end;
uint32_t stack_start,stack_end;
};
不同区域分别赋值不同的地址就好了,如果有需要再去调整就好了,毕竟这是虚拟地址,怎么搞都搞不坏。
也就是说虚拟空间的本质就是控制这些数据而已。
进程地址空间,页表,内存的关系
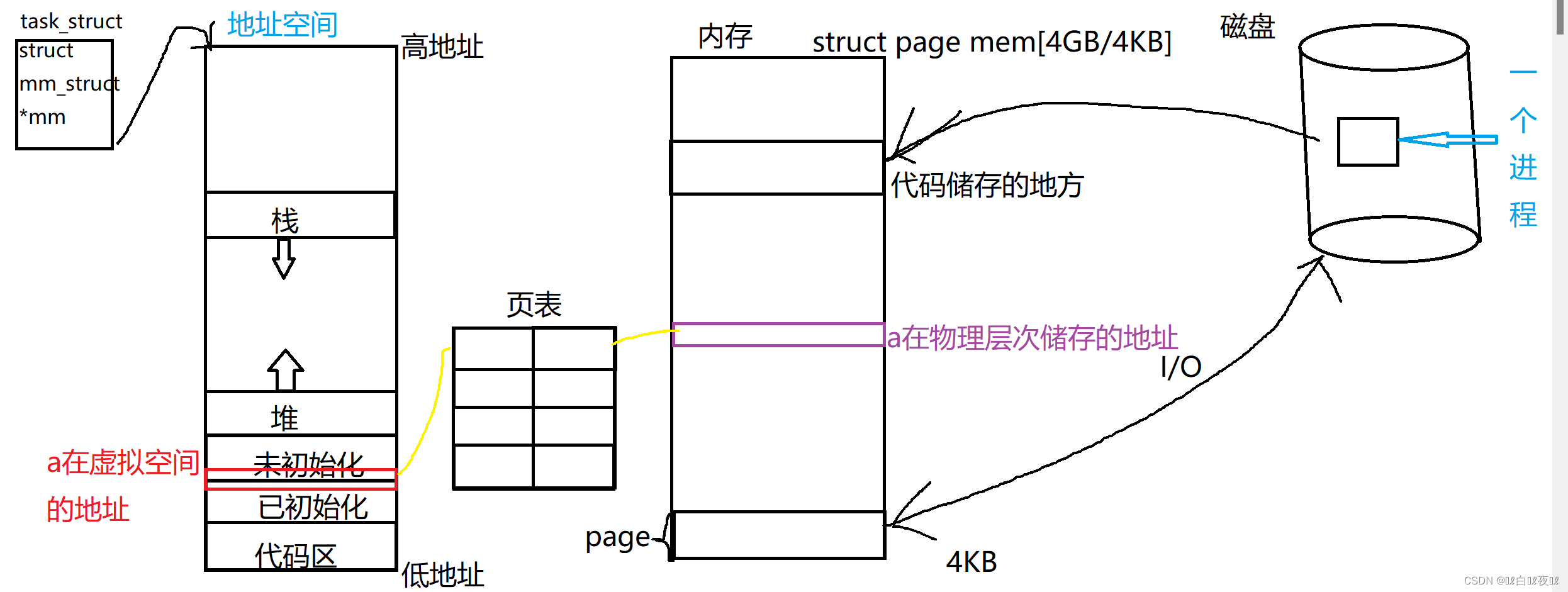
一个程序在磁盘里,先放入内存中,然后代码跑起来,代码也是需要储存在内存上的,并且内存当中是类似于数组形式的,一个page位4kb大小。
进程在运行的时候有自己的虚拟地址空间,然后通过页表来映射到物理内存上的。
这些都是由操作系统完成的。
这也就能解释刚开始代码为什么是显示的是同一个地址,子进程改变了数值父进程却没有改变。
因为每个进程都有独立的进程地址空间和页表:
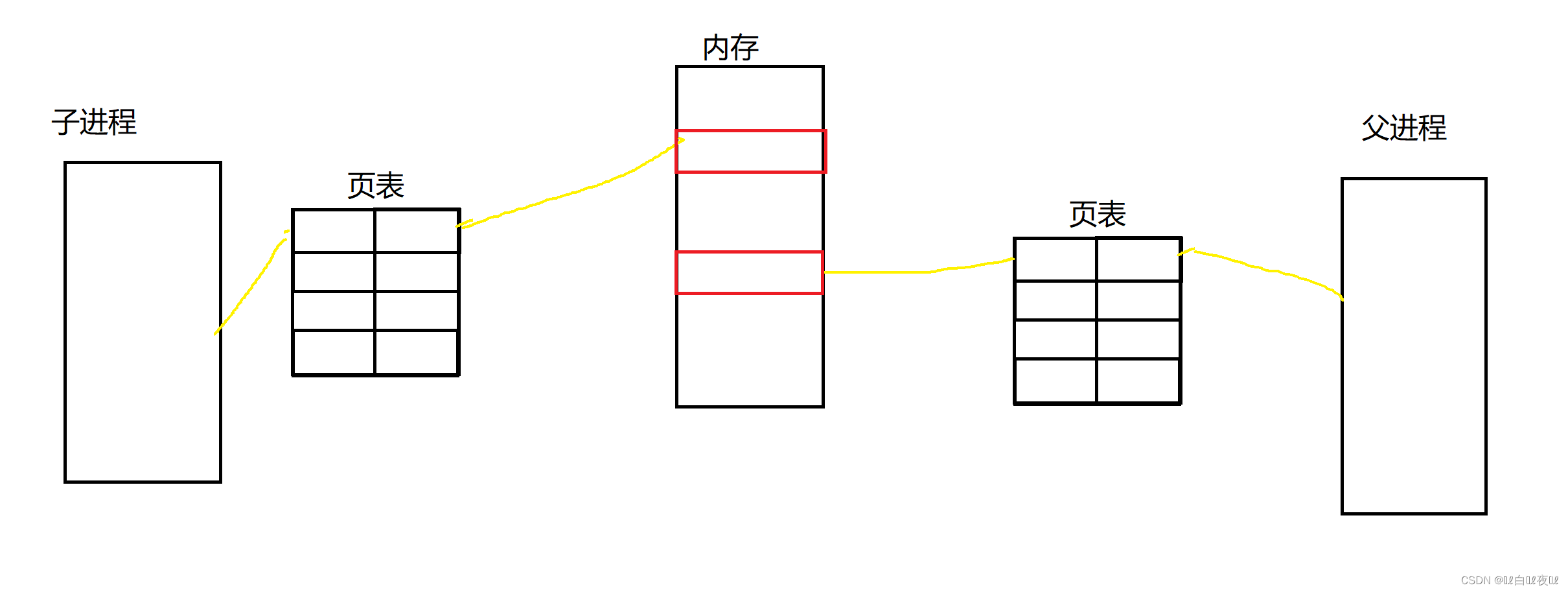
页表不单单只是映射,并且还会去判断,拦截(所有进程都不例外)像刚开始写的那段代码,因为子进程是父进程创建的,那么子进程的地址空间内容是从父进程拷贝而来的,但是页表会发现原本映射出来的位置已经被占有了,这个时候就会在另一处先开辟空间,然后拷贝父进程在内存中的内容到新开辟的空间当中,然后更改页表的映射,这个叫做写时拷贝,这样父进程和子进程就是两个完全独立的空间。
为什么存在进程地址空间
1.防止进程在物理内存当中进行越界的非法操作。(上面的例子已证明)
2.更方便进程和进程的数据代码解耦,保证了进程独立性的特征。(上面的例子已证明)
3.
遵守进程地址空间的不仅仅是操作系统还有编译器!
假设我写了一个程序my.exe。

程序在磁盘的时候是有地址的,逻辑地址(在linux当中也可以称为虚拟地址)
在进程指向进程地址空间的时候,CPU去读取指令,main函数,因为每一条指令都是有虚拟地址的,所以就能找到fun函数,还有a的位置。
CPU的寄存器中储存的就是虚拟地址,通过main函数的虚拟地址然后找到内存中的main然后解析代码,然后调用fun的时候又通过页表映射到了进程地址空间当中,CPU又拿到了fun函数的虚拟地址,然后再映射到物理内存当中,这就是我们调试代码中看到的内存地址编号就是虚拟地址空间。
上面的运行模式也说明了CPU从头到尾都没有见到过物理内存地址,就算是内存中代码的内部使用的也全都是虚拟地址。
至于逻辑地址和虚拟地址的区别,现在用的逻辑地址也是划分区域,代码区,数据区等等,恰好与虚拟地址的编号差不多,所以加载到内存当中使用的就是虚拟地址了。
旧版的逻辑地址就比较繁琐了,是靠偏移量来找到物理内存中数据的地址。
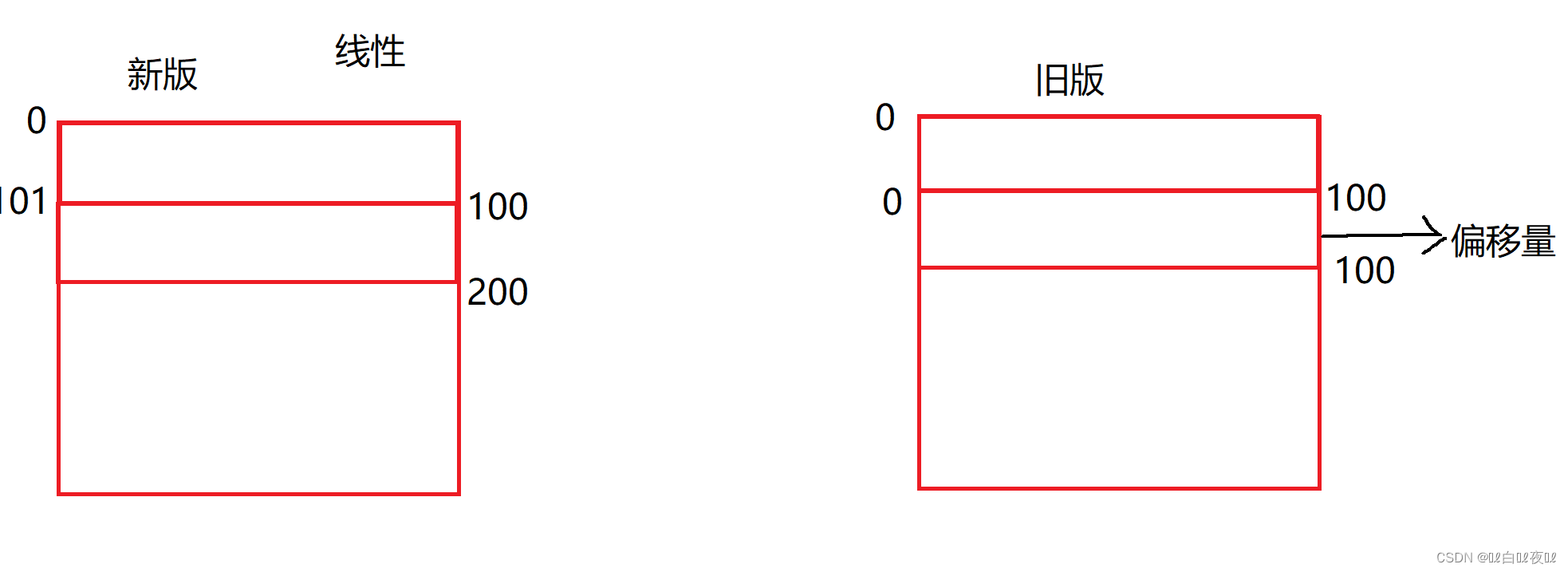
这说明进程地址空间方便了进程以统一视角来看到对应的代码,数据等各个区域,也方便编译器用同一个规则进行编译。(规则是一样的,编译完即可使用)
最后说明:
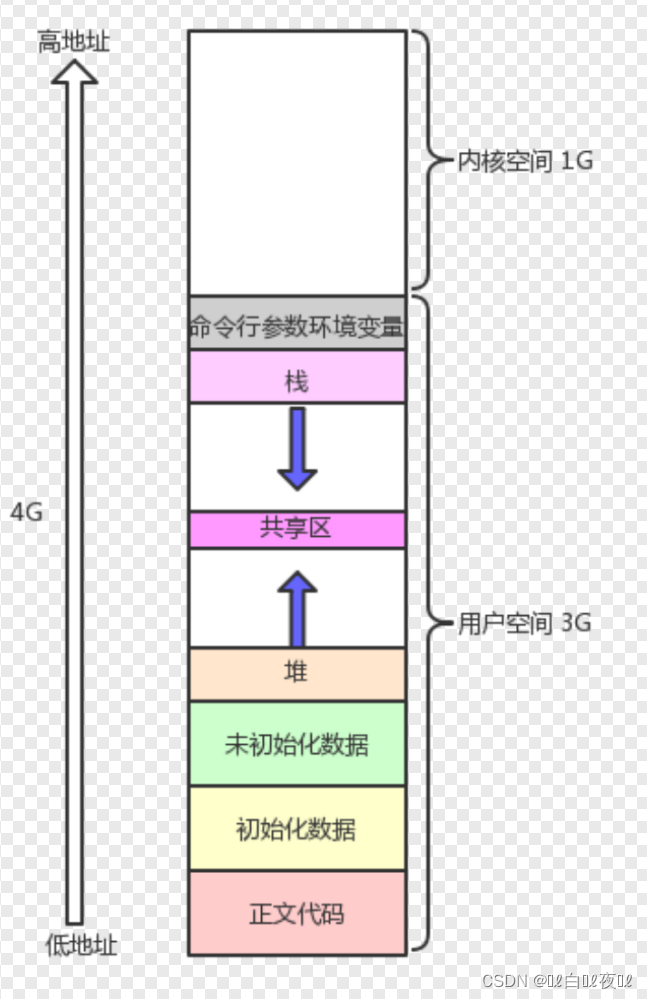
命令行参数环境变量就是那个environ。