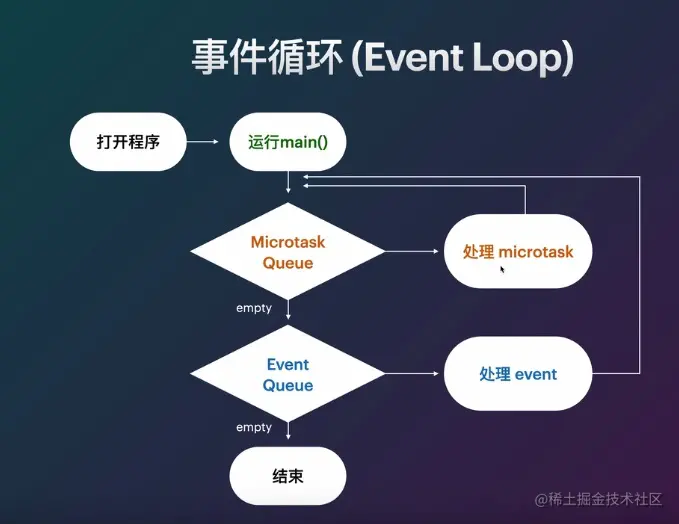
文章目录
- 基本原理
- PCA类
- 图像降维与恢复
基本原理
PCA,即主成分分析(Principal components analysis),顾名思义就是把矩阵分解成简单的组分进行研究,而拆解矩阵的主要工具是线性变换,具体形式则是奇异值分解。
设有 m m m个 n n n维样本 X = ( x 1 , x 2 , ⋯ , x m ) X=(x_1, x_2,\cdots,x_m) X=(x1,x2,⋯,xm),但这 n n n个维度彼此并不完全独立,所以想试试有没有办法将其降低到 k k k维,则PCA的主要流程为
- 先将原始数据按列组成 n n n行 m m m列矩阵 X X X,然后对每一行数据进行中心化 x i j = x i j − 1 m ∑ j = 1 m x j x_{ij}=x_{ij}-\frac{1}{m}\sum^m_{j=1}x_j xij=xij−m1∑j=1mxj,记中心化之后的矩阵为 x ′ x' x′
- 计算样本协方差矩阵,由于已经中心化,故可表示为 C = 1 m X ′ X ′ T C=\frac{1}{m}X'X'^T C=m1X′X′T
- 计算协方差矩阵的特征值和特征向量,一般需要用到奇异值分解
- 对特征向量按照特征值大小进行排序,取前 k k k组特征向量组成矩阵 P P P,则 P X PX PX就是 k k k维的主成分
由于矩阵乘法的几何意义是坐标系的旋转、平移以及缩放,所以从几何角度理解PCA,就是将坐标系旋转到尽量与更多样本平行,从而达到简化坐标轴的作用。就好比一条空间中的直线,需要用三个维度来表示,但这条直线是一维的,只需旋转、移动坐标轴,使得这条直线与 x x x轴重合,就能只用一个坐标来表示这条直线。
PCA类
sklearn.decomposition中提供了PCA类,其构造函数为
PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', n_oversamples=10, power_iteration_normalizer='auto', random_state=None)
各参数含义如下
n_components组分个数,默认为样本数和特征数中较小的那个;如果输入为小数,则表示百分之几copy为False时,将覆盖原始数据。whitenbool为True时, 对组分矢量进行如下操作:先乘以样本的方根,然后除以奇异值svd_solver奇异值求解器,可选'auto', 'full', 'arpack', 'randomized'tol容忍度random_state用于设置随机数种子power_iteration_normalizer设置SVD分解方案,可选"LU", "QR", "auto", "none四种。当svd_solver设为arpack时不可用。
奇异值求解器共有4个选择, 其中full将调用scipy.linalg.svd,计算稠密矩阵比较快;arpack将调用scipy.sparse.linalg.svds,更擅长计算稀疏矩阵。二者的具体区别可见scipy奇异值分解💎稀疏矩阵SVD
图像降维与恢复
下面用经典的lena图来测试一下主成分分析。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import decomposition
img = plt.imread('lena.jpg').astype(float)
sh = img.shape # 256x256x3
ns = [256, 128, 64, 32, 16, 5]
imgs = [img]
for i in ns[1:]:
pca = decomposition.PCA(i)
# 彩色图像需要先转化为矩阵再进行PCA
imNew = pca.fit_transform(img.reshape(sh[0], -1))
im = pca.inverse_transform(imNew)
imgs.append(im.reshape(sh))
fig = plt.figure()
for i, im in enumerate(imgs):
ax = fig.add_subplot(231+i)
ax.imshow(im)
plt.title(str(ns[i]))
plt.axis('off')
plt.show()
其中,fit_transform即对图像降维,保留相应组分并输出;inverse_transofrm即对图像进行恢复,最终得到的效果如下,随着组分的逐渐降低,图像也越来越模糊。






![[vue3] pinia的基本使用](https://img-blog.csdnimg.cn/e6459a40afb04adc99aad3068f320be4.png#pic_center)