1 虚拟机的指令执行设计
1.1 虚拟机的分类
基于栈的虚拟机,比如JVM虚拟机
基于寄存器的虚拟机,比如Dalvik虚拟机
1.2 虚拟机的概念
首先问一个基本的问题,作为一个虚拟机,它最基本的要实现哪些功能?
他应该能够模拟物理CPU对操作数的移进移出,理想状态下,它应该包含如下概念:
(1)将源码编译成VM指定的字节码。
(2)包含指令和操作数的数据结构(指令用于处理操作数作何种运算)。
(3)一个为所有函数操作的调用栈。
(4)一个“指令指针(Instruction Point —IP)”:用于指向下一条将要执行的指令。
(5)一个虚拟的“CPU”–指令的派发者:
1)取指:获取下一条指令(通过IP获取)
2)译码:对指令进行翻译,将要作何种操作。
3)执行:执行指令。
以上是CPU的三级流水线操作,实际上五级流水线还包括回写,即把执行后生成的结果回写进存储器。
有两种基本的方法实现虚拟机:
基于Stack的和基于Register的,比如基于Stack的虚拟机有JVM、.net的CLR、还有最近热门的以太坊EVM,这种基于Stack实现虚拟机是一种广泛的实现方法。而基于Register的虚拟机有Lua VM(是Lau编程语言的虚拟机)和Dalvik VM。
这两种虚拟机实现的不同主要在于操作数和结果的存储和检索机制不一样。
注意Dalvik因为是基于寄存器的虚拟机,其编译结果文件的格式和class文件是完全不同的
1.3 核心概念
1.3.1 最终的指令的执行的表现形式是
ADD P1 P2--- P1 P2为操作数(操作数的本质是地址)
1.3.2 核心需要理解的是,不同芯片,他们的线路设计规格不一致(含单片机)
1.常规CPU Intel ARM AMD等:32、64
2.单片机:8、16
1.4 Stack-Based虚拟机(最大特征就是一堆pop push)
Stack-Based虚拟机(最大特征就是一堆pop push)
如下就是一个典型的计算20+7在栈中的计算过程:
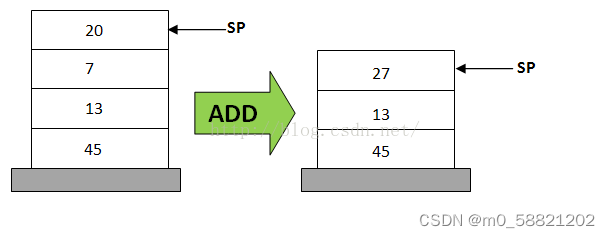
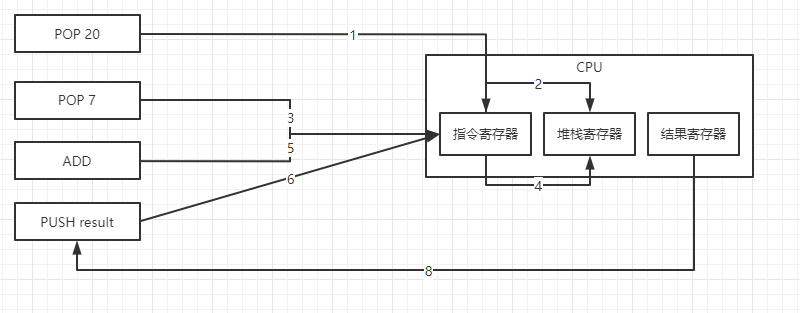
指令执行过程为
1、POP 20
2、POP 7
3、ADD // 此时单条指令就可以了,不需要再跟 20, 7, result
4、PUSH result
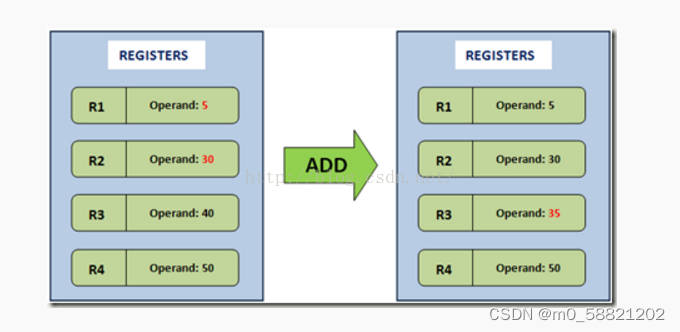
1.5 Register-Based虚拟机(最大特征就是较多操作数)
基于寄存器的虚拟机,它们的操作数是存放在CPU的寄存器的。没有入栈和出栈的操作和概念。但是执行的指令就需要包含操作数的地址了,也就是说,指令必须明确的包含操作数的地址,这不像栈可以用栈指针去操作。比如如下的加法操作:
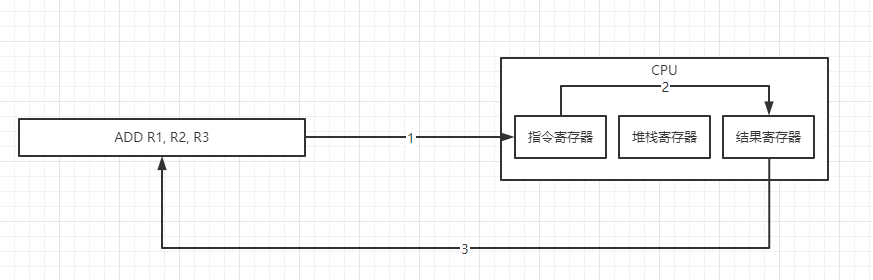
1.5.1 指令执行过程
ADD R1, R2, R3 ;就一条指令搞定了。
1.6 总结
1.6.1 因为计算机芯片规格不一致
像常规Intel ARM AMD这些芯片能够支持比较多的操作,因为一般他们的线路设计都是32以上
像单片机这种,最便宜的单片机可能在线路上的设计是8
1.6.2 因此考虑到设备上的兼容
JAVA的方案
栈---兼容最小8的指令执行(能兼容单片机等设备)
Android的方案
寄存器---无需兼容,android设备一般依赖于高性能芯片
1.7 思考?
基于上篇了解指令执行过程中的问题,那么需要考虑线程资源
什么是线程资源?
参考:C++ chapter 11 STL之线程管理
https://www.processon.com/view/link/62ab388e5653bb5256dae2fd
PS:最好去把这节课看了
线程资源本质
1.指令的最终执行由OS分配
2.虚拟机需要做的事情是将指令编译完成扔给OS的内核
3.完成指令提交通过OS的系统接口完成
4.内核在处理代码时会对代码进行组织,即task_struct对象
5.在内核角度,一个task_struct其实就是一个进程|线程
对于linux而言其实进程与线程没什么太大的区别, 就是信息上有一点差异
6.在内核角度,提供pthread_create这种形式让我们动态生成一个线程资源,本质就是通过该函数告诉linux,哥们开一个新的task_struct,代码就是{自己指定}这一段
2 回顾:GC的实现方案与思路
2.1 虚拟机内存管理思路
2.1.1 说明
虚拟机进行内存管理,本质上是自己提前申请一块内存,然后自己来维护这一块内存,具体案例如下
2.1.2 示例
#include <stdio.h> #include <malloc.h>
#define EDEN_SIZE 1024 * 1024 * 16 int main() {
//堆区初始化大小16M,实际开辟 16 * 3 48M
//其中16M为EDEN 32M为堆区
char* head = malloc(EDEN_SIZE * 3);
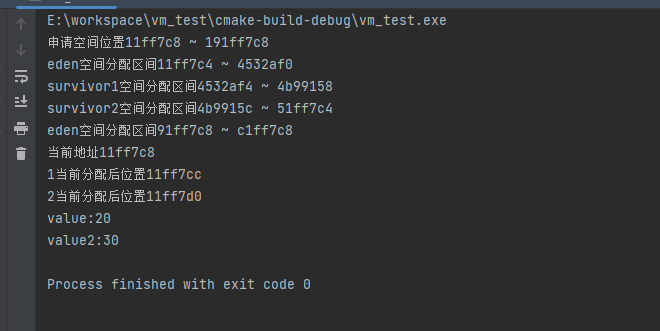
printf("申请空间位置%x ~ %x\n",&head,(&head + (EDEN_SIZE * 3)));
//年轻代设计分配
int yong_begin = &head ;
int yong_end = &head + EDEN_SIZE;
int eden_begin = &yong_begin;
int eden_end = &yong_begin + (int)(EDEN_SIZE * 0.8-1);
//survivor区分配
int survivor1_begin =&yong_begin + (int)(EDEN_SIZE * 0.8); int survivor1_end = &yong_begin + (int)(EDEN_SIZE * 0.9 - 1); int survivor2_begin =&yong_begin + (int)(EDEN_SIZE * 0.9); int survivor2_end =&yong_begin + (int)(EDEN_SIZE); //老年代设计 int old_begin = &head + EDEN_SIZE;
int old_end = old_begin + EDEN_SIZE * 3;
printf("eden空间分配区间%x ~ %x\n",eden_begin,eden_end);
printf("survivor1空间分配区间%x ~ %x\n",survivor1_begin,survivor1_end); printf("survivor2空间分配区间%x ~ %x\n",survivor2_begin,survivor2_end); printf("eden空间分配区间%x ~ %x\n",old_begin,old_end);
//java代码:int i = 10;
//指针标记
char* index = &head;
printf("当前地址%x\n",index);
int i = 20;
//length 4 value 20
char* val = 20;
int length = 4;
char* v1Index = index;
*index = val;
index += length;
printf("1当前分配后位置%x\n",index);
char* v2Index = index;
char* val2 = 30;
int length2 = 4;
*index = val2;
index += length2;
printf("2当前分配后位置%x\n",index);
int value = *v1Index;
printf("value:%d\n",value);
int value2 = *v2Index;
printf("value2:%d\n",value2);
return 0;
}2.1.3 运行结果
2.2 内存碎片处理方案
2.2.1 这种自己来写,首先需要考虑的是内存碎片的问题
2.2.2 传统处理方案一般是依赖于两个阶段
1.标记要处理的数据对象
2.清空要处理的数据对象(PS:但是对于内存数据管理来讲不进行情况,只进行覆盖)
2.2.3 业内处理算法方案
1、垃圾确认算法--标记阶段算法
1)引用计数算法
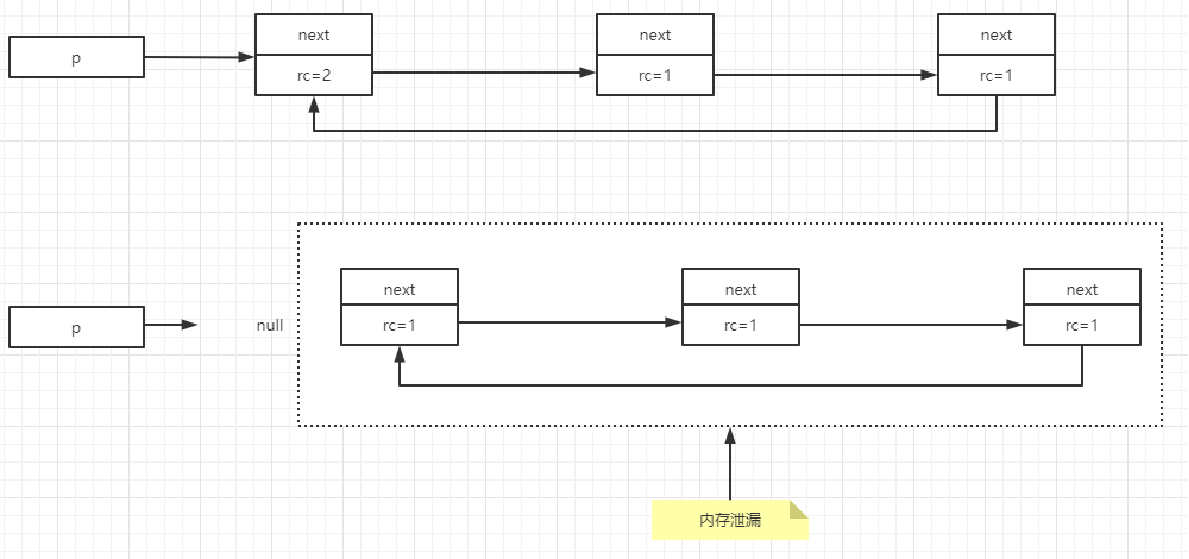
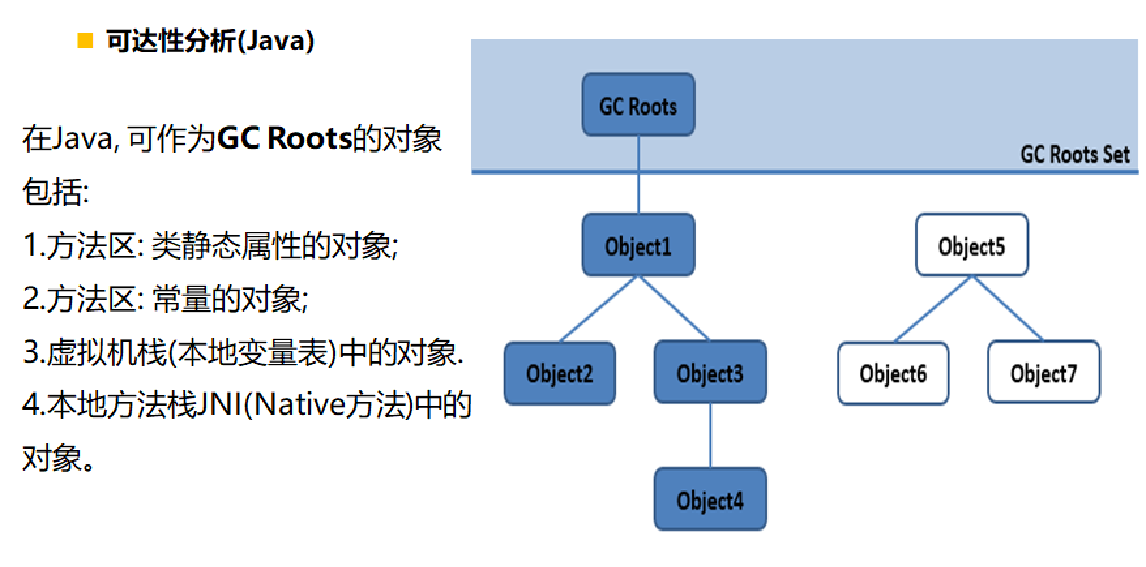
2)GCRoot可达性分析算法
2、清除垃圾算法--清除阶段算法
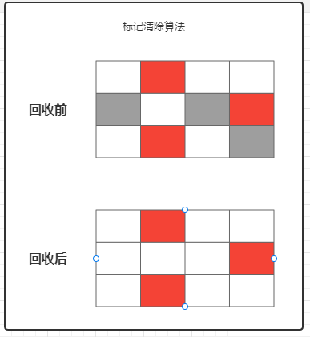
1)清除算法:直接删
有碎片问题
2)复制算法:牺牲空间,换碎片
无碎片问题
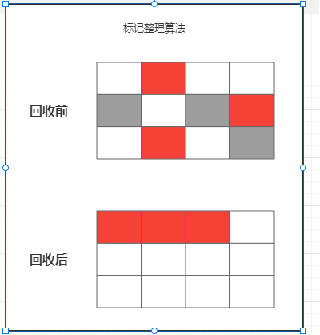
3)压缩/整理算法:牺牲时间,换碎片
无碎片问题
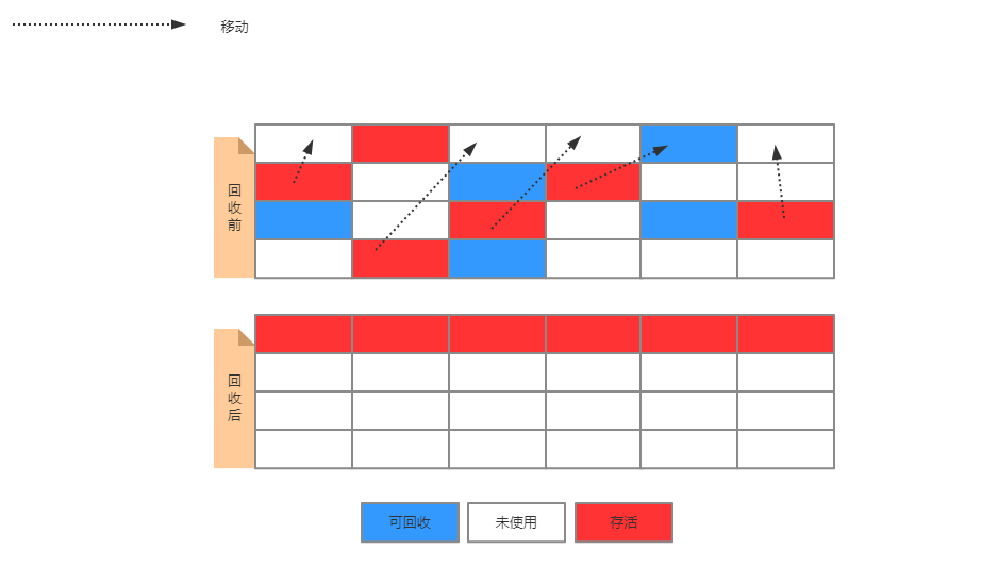
3、三种算法的性能指标对比
效率上来说,复制算法最快,但是内存浪费最多而为了尽量兼顾上面三个指标,标记整理算法相对平滑一些,但是效率上不仅如此任意,他比复制算法多了一个标记阶段,比清除多了一个整理内存阶段

2.3 分代设计的思路
难道没有一种最优算法吗?
2.3.1 分代收集算法
为了满足垃圾回收的效率最优性,所以分代收集算法应运而生
分代收集算法基于一个事实:不同的对象生命周期是不一样的,因此,不同生命周期的对象可以采取不同的手机方式,以便于提高回收效率。一般是把堆分为新生代和老年代,这样就可以根据各个年代的特点使用不同回收算法,相对提高效率
在系统运行过程汇总,会产生大量对象,其中有些对象是业务信息相关,如HTTP请求的Session、线程、Socket连接等对象,这类对象跟业务挂钩,因此生命周期长,还有一部分是运行过程汇总生成的临时变量,这些对象生命周期短,比如:String,这些对象甚至只使用一次即可回收
2.3.2 分代算法衍生后
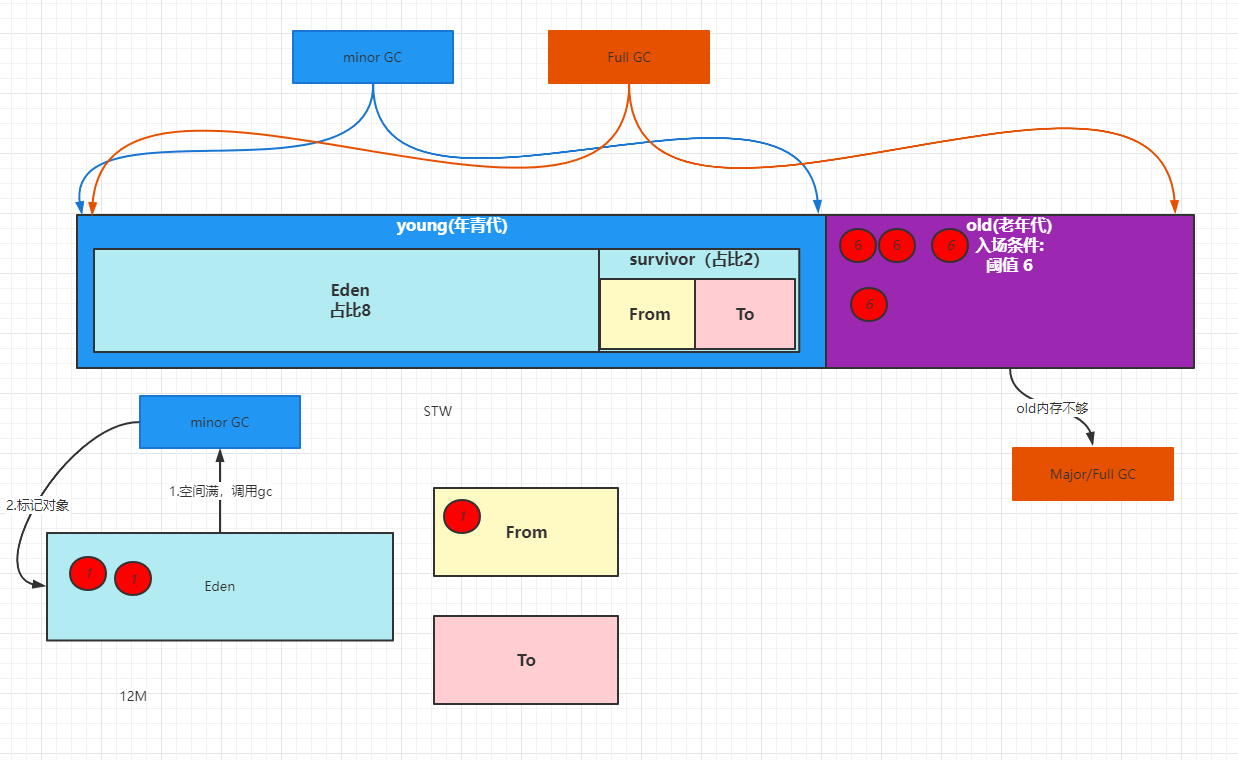
1)eden作为生产地,运用清除算法
2)但是可能存在需要存活的对象数据,所以预留一块数据进行保存存活数据(old)
3)为了保证不产生碎片,且这块数据的体量实际不大,所以这里采用复制算法
4)指针碰撞!
5)处理方案:
维护一个空闲列表,解决碎片化
算法:清除、复制、整理算法
如何自己来设计这个方案
70-99% - 一次性 年轻人
1-30% 长久 老年人
建议新老年代占比:90% 10%
年青代
eden(生产)-survivor(缓冲)
老年代
eden-清除算法 all clear
survivor - 复制 缓冲
old - 清理
2.4 内存回收方案
2.4.1 分区

2.4.2 增量

3 Dart 内存结构设计
3.1 堆栈区设计思路
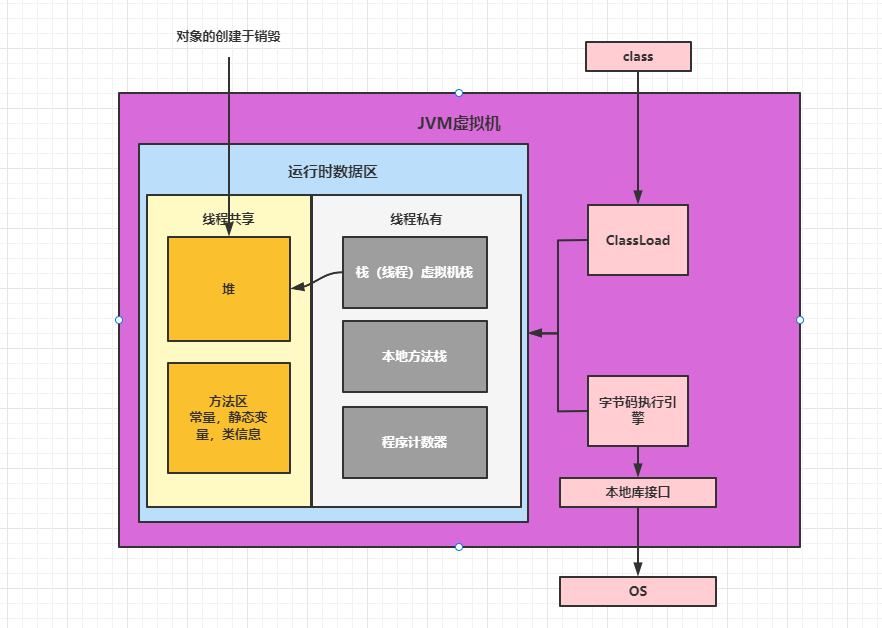
3.1.1 JAVA
3.1.2 Dart
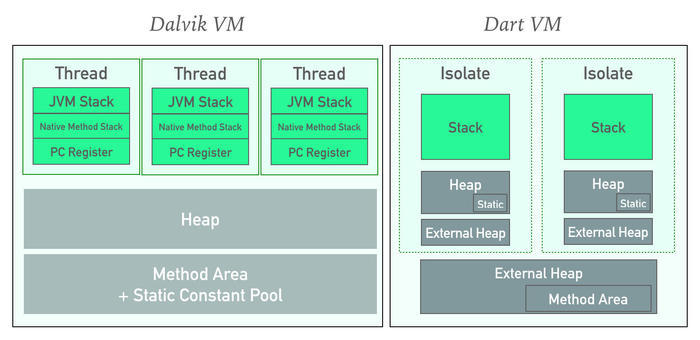
3.2.3 说明
1.JAVA采取的方案
栈区独立内存开销,维持指令运行
堆区数据共享
优点
无额外数据开销,线程间共享数据直接找共享堆区
缺点
因为共享,会出现临界区问题,需要引入锁机制处理
2.Dart采取的方案
GC隔离
如上图展示,在内存管理设计角度,将栈,堆,等数据进行完全隔离设计,包括GC线程也进行隔离
2.2 线程间数据传递问题
2.2.1 JAVA
直接共享堆,但是需要设计锁业务
2.2.2 DART
独立堆栈,但是需要设计隔离区的通信机制
4 事件轮询机制
4.1 事件轮训机制建立的目的
单线程内部建立异步体系
这种方案一般适用于有事件驱动下的业务体系(一般指UI体系)
服务体系一般是多线程
这里设计的目的请注意:
1.dart出现的目的是为了去对标JS做所谓的跨平台
2.后续切入到移动端其实他的本质也不变,因为是为了做UI的跨平台
3.既然是UI的开发那么整个业务运载的模型肯定是事件驱动模型
4.在android当中,是运用handler来支撑事件驱动模型
4.2 程序运行设计模型
4.2.1 单线程模型
单线程同步模型中,任务依次执行,如果某个任务因为I/O阻塞了,其他任务也只能等待,直到前面的任务执行完成后才能执行。这样3个没有依赖关系的任务,需要互相等待顺序执行,大大降低了执行效率。
说明
这种是一根线程的状态,很多单片机是这种,有耗时操作后续就等着
4.2.2 多线程模型
多线程模型中,任务分别在独立的线程中执行,不需要互相等待。在多处理器系统上可以并行处理,在单处理器系统上可以交替执行。这种方式更有效率,但是开发者需要保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
典型的多线程状态,如果存在分支功能,让另外一个线程去进行维护
4.2.3 事件驱动模型
事件驱动模型中,3个任务交替执行,但仍然在一个单独控制的线程中。当处理一个I/O或其他昂贵的操作时,注册一个回调到事件队列中,当I/O操作完成后继续执行。回调描述了如何处理某个事件。事件队列轮询事件,事件发生后将事件分派给事件处理器进行处理。这种方式让程序尽可能执行而不需要额外的线程。使用事件驱动模型开发者不需要担心线程安全的问题。
单线程下的无等待形式运行
1.传统单线程如果需要等待事件的响应去处理某个业务,那么只能等待一个事件,其他需要等这一个事件处理完成后才响应
4.3 事件轮训机制详解
4.3.1 Dart实现过程
图例
说明
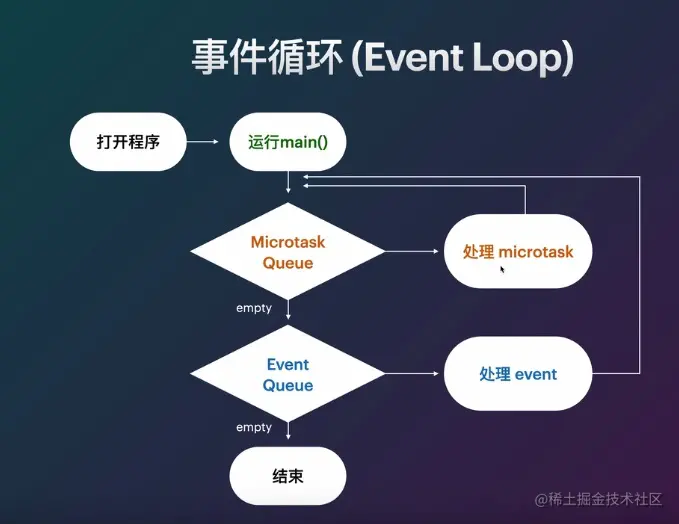
一个Dart应用有一个消息循环和两个消息队列-- event队列和microtask队列。
event队列包含所有外来的事件:I/O,mouse events,drawing events,timers,isolate之间的message等。
microtask 队列在Dart中是必要的,因为有时候事件处理想要在稍后完成一些任务但又希望是在执行下一个事件消息之前。
event队列包含Dart和来自系统其它位置的事件。但microtask队列只包含来自当前isolate的内部代码。
正如下面的流程图,当main方法退出后,event循环就开始它的工作。首先它会以FIFO的顺序执行micro task,当所有micro task执行完后它会从event 队列中取事件并执行。如此反复,直到两个队列都为空。
当一个Dart应用开始的标志是它的main isolate执行了main方法。当main方法退出后,main isolate的线程就会去逐一处理消息队列中的消息。
正如下面的流程图,当main方法退出后,event循环就开始它的工作。首先它会以FIFO的顺序执行micro task,当所有micro task执行完后它会从event 队列中取事件并执行。如此反复,直到两个队列都为空。
当一个Dart应用开始的标志是它的main isolate执行了main方法。当main方法退出后,main isolate的线程就会去逐一处理消息队列中的消息
4.3.2 JAVA模拟示例
Task
package com.kerwin.event;
public abstract class Task {
public abstract void run();
}ScheduleMicrotask
package com.kerwin.event;
public class ScheduleMicrotask extends Task {
@Override
public void run() {}
}Timer
package com.kerwin.event;
public class Timer extends Task {
@Override
public void run() {}
}Main
package com.kerwin.event;
import java.util.Queue;
import java.util.concurrent.LinkedBlockingQueue;
public class Main {
//微任务队列-优先级高
private static Queue<ScheduleMicrotask> scheduleMicrotasks
= new LinkedBlockingQueue<>();
//事件队列-优先级低
private static Queue<Timer> timers = new LinkedBlockingQueue<>();
public static void processAsync(){
while(!scheduleMicrotasks.isEmpty() || !timers.isEmpty()){
Task task = null;
if((task = scheduleMicrotasks.poll()) != null){
}else if((task = timers.poll()) != null){}
task.run();
}
}
public static void main(String[] args){
System.out.println("main start!");
timers.offer(new Timer(){
@Override
public void run() {
System.out.println("timer - event - A");
scheduleMicrotasks.offer(new ScheduleMicrotask(){
@Override
public void run() {
System.out.println("ScheduleMicrotask - A - in Timer A");
}
});
scheduleMicrotasks.offer(new ScheduleMicrotask(){
@Override
public void run() {
System.out.println("ScheduleMicrotask - B - in Timer A");
}
});
}
});
scheduleMicrotasks.offer(new ScheduleMicrotask(){
@Override
public void run() {
System.out.println("ScheduleMicrotask - C - in MAIN ");
timers.offer(new Timer(){
@Override
public void run() {
System.out.println("timer - event - B - in ScheduleMicrotask - C ");
}
});
}
});
System.out.println("main end!");
processAsync();
}
}4.4 示例
import 'dart:async';
void main(){
print("main begin");
Timer.run(() {
print("timer - event - A");
scheduleMicrotask(() {
print("ScheduleMicrotask - A - in Timer A");
});
scheduleMicrotask(() {
print("ScheduleMicrotask - B - in Timer A");
});
});
scheduleMicrotask(() {
print("ScheduleMicrotask - C - in MAIN ");
Timer.run(() {
print("timer - event - B - in ScheduleMicrotask - C ");
});
});
print("main end");
}