文章目录
- 分层设置与查询
- 数据
- index 为有序
- index 为无序(中文)
- 查看数据
- 示例
- 多层索引的创建方式(行)
- 1、from_arrays 方法
- 2、from_tuples 方法
- 3、from_product 方法
- 多层索引的创建方式(列)
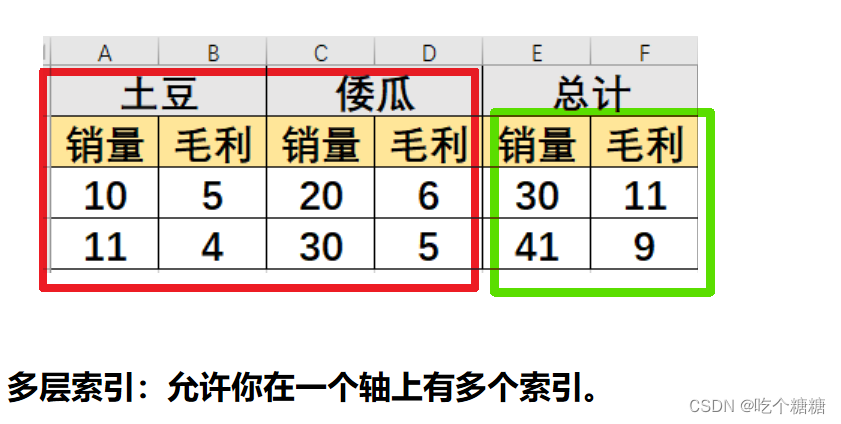
- 分层索引计算
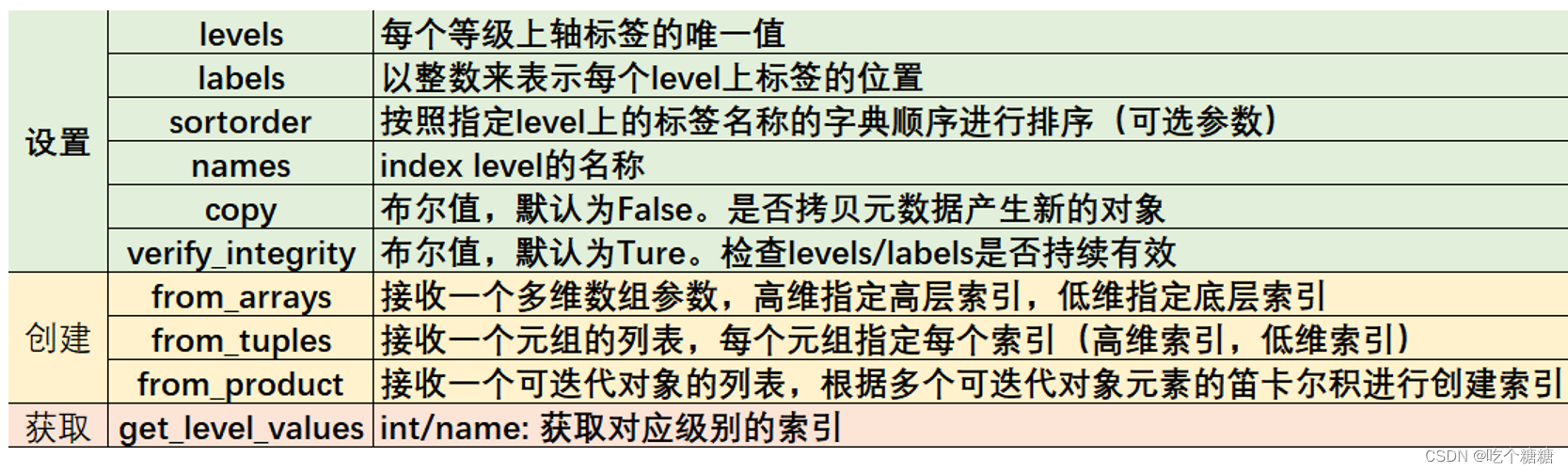
- MultiIndex 参数表
分层设置与查询
数据
index 为有序
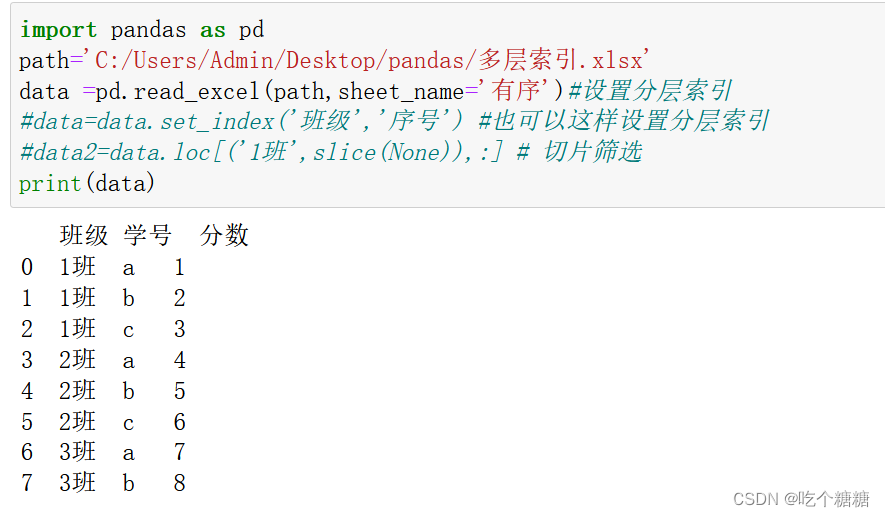
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/多层索引.xlsx'
data =pd.read_excel(path,index_col=[0,1],sheet_name='有序')#设置分层索引
#data=data.set_index('班级','序号') #也可以这样设置分层索引
data2=data.loc[('1班',slice(None)),:] # 切片筛选
print(data2)


index 为无序(中文)
查看数据
示例
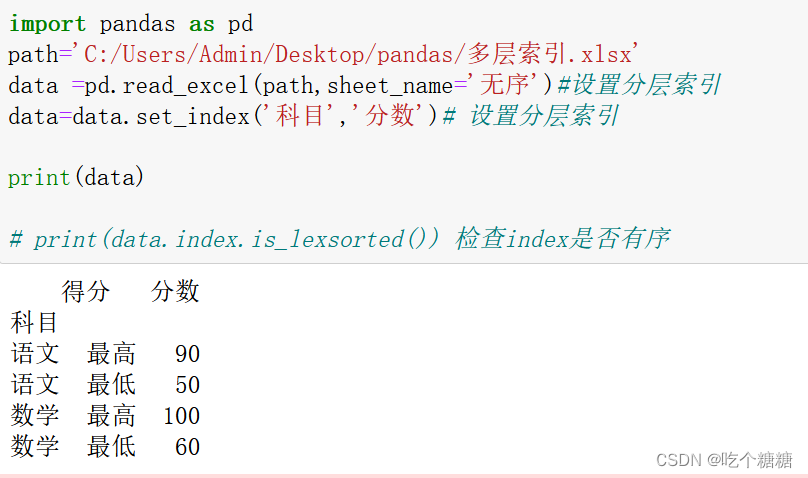
import pandas as pd
path='C:/Users/Admin/Desktop/pandas/多层索引.xlsx'
data =pd.read_excel(path,sheet_name='无序')#设置分层索引
data=data.set_index('科目','分数')# 设置分层索引
data2=data.sort_index(level='科目')
data2=data.loc[('语文',slice(None))]
print(data2)

多层索引的创建方式(行)

1、from_arrays 方法

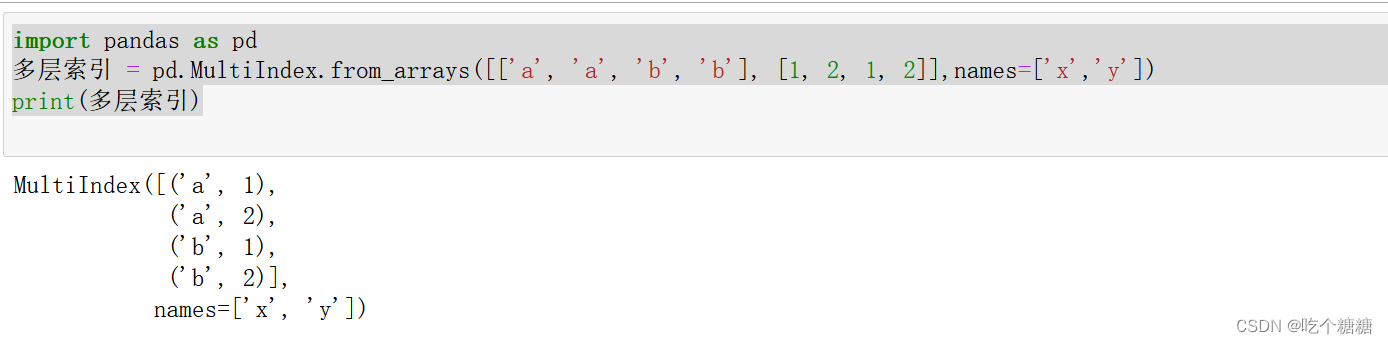
import pandas as pd
多层索引 = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],names=['x','y'])
print(多层索引)
2、from_tuples 方法

import pandas as pd
多层索引 = pd.MultiIndex.from_tuples([('a',1),('a',2),('b',1),('b',2)],names=['x','y'])
print(多层索引)
3、from_product 方法

import pandas as pd
多层索引 = pd.MultiIndex.from_product([['a', 'b'], [1, 2]],names=['x','y'])
print(多层索引)


多层索引的创建方式(列)
import pandas as pd
import numpy as np
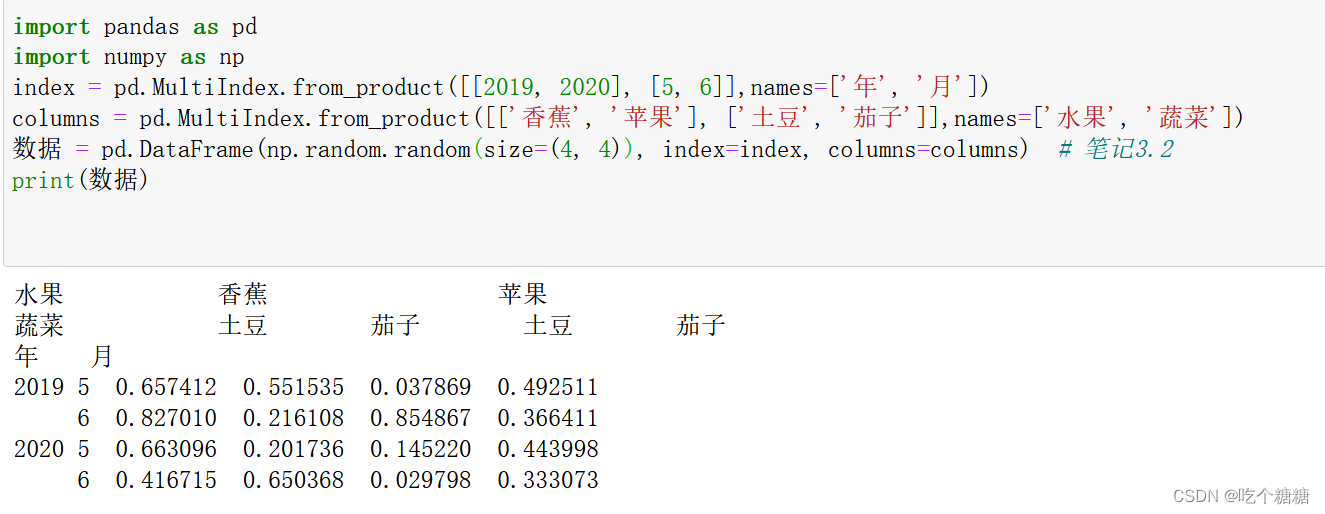
index = pd.MultiIndex.from_product([[2019, 2020], [5, 6]],names=['年', '月'])
columns = pd.MultiIndex.from_product([['香蕉', '苹果'], ['土豆', '茄子']],names=['水果', '蔬菜'])
数据 = pd.DataFrame(np.random.random(size=(4, 4)), index=index, columns=columns) # 笔记3.2
print(数据)
分层索引计算
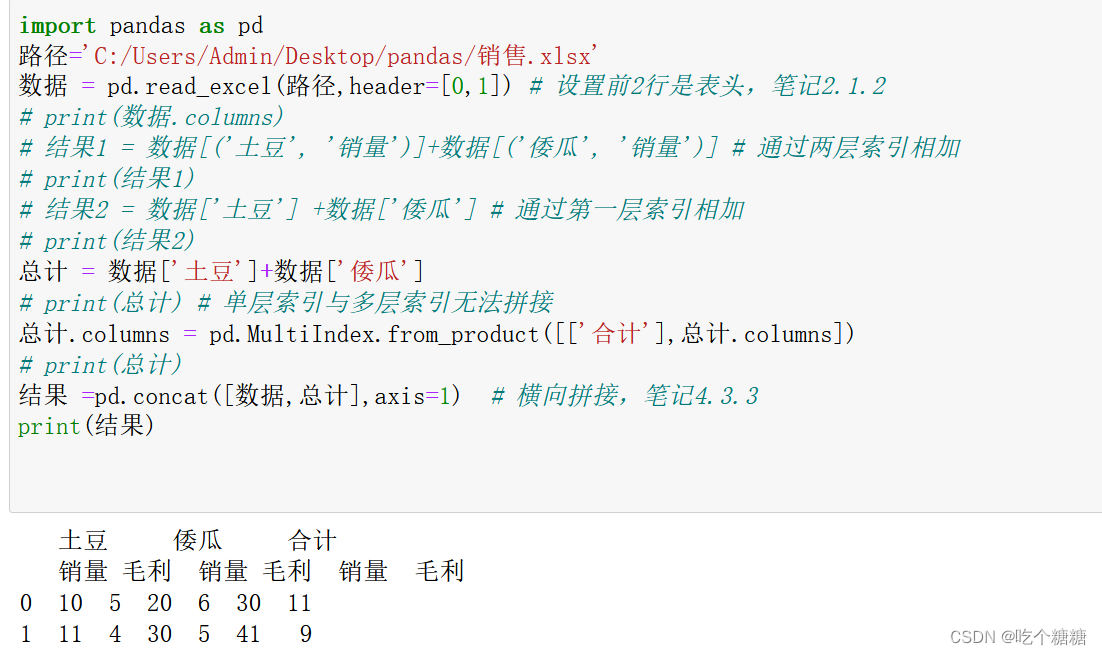
import pandas as pd
路径='C:/Users/Admin/Desktop/pandas/销售.xlsx'
数据 = pd.read_excel(路径,header=[0,1]) # 设置前2行是表头,笔记2.1.2
# print(数据.columns)
# 结果1 = 数据[('土豆', '销量')]+数据[('倭瓜', '销量')] # 通过两层索引相加
# print(结果1)
# 结果2 = 数据['土豆'] +数据['倭瓜'] # 通过第一层索引相加
# print(结果2)
总计 = 数据['土豆']+数据['倭瓜']
# print(总计) # 单层索引与多层索引无法拼接
总计.columns = pd.MultiIndex.from_product([['合计'],总计.columns])
# print(总计)
结果 =pd.concat([数据,总计],axis=1) # 横向拼接,笔记4.3.3
print(结果)

MultiIndex 参数表




![[安装] Dell电脑安装系统时看不到固态硬盘的解决方案](https://img-blog.csdnimg.cn/img_convert/fc95cc2782e24f7aba4f172cc82b5039.png)