数据库管理 2023-02-18
- 第五十七期 多灾多难
- 1 网络震荡
- 2 挂一大片
- 3 恢复虚拟机
- 总结
第五十七期 多灾多难
2月第三周,怎么说呢,多灾多难的一周,一周两次严重故障,而且事情还都发生在24小时之内,
1 网络震荡
本周四一大早显示一个业务说很多服务器连不到数据库了,我看了看PGA占用确实快满了,但也仅仅是快满了,我自己去测试连接也没有问题,没办法只能将idle非常就的非集群会话都干掉,但也没有明显改善问题,PGA下降也不多,我承认这里有点疑惑性。这里说一下这个业务,数据库在A数据中心,业务服务在B数据中心,两个数据中心有4套100GE总计100GE的链路。而同样布局的也是这家公司开发维护的另一个业务则没有出现相同的问题。
在还在纠结是哪出问题,业务方项目经理都准备找客户背书的时候,另一个业务也爆出了问题,这个业务则是业务服务在A数据中心,数据库在B数据中心。通过EM的ASH分析看到了下面的内容:
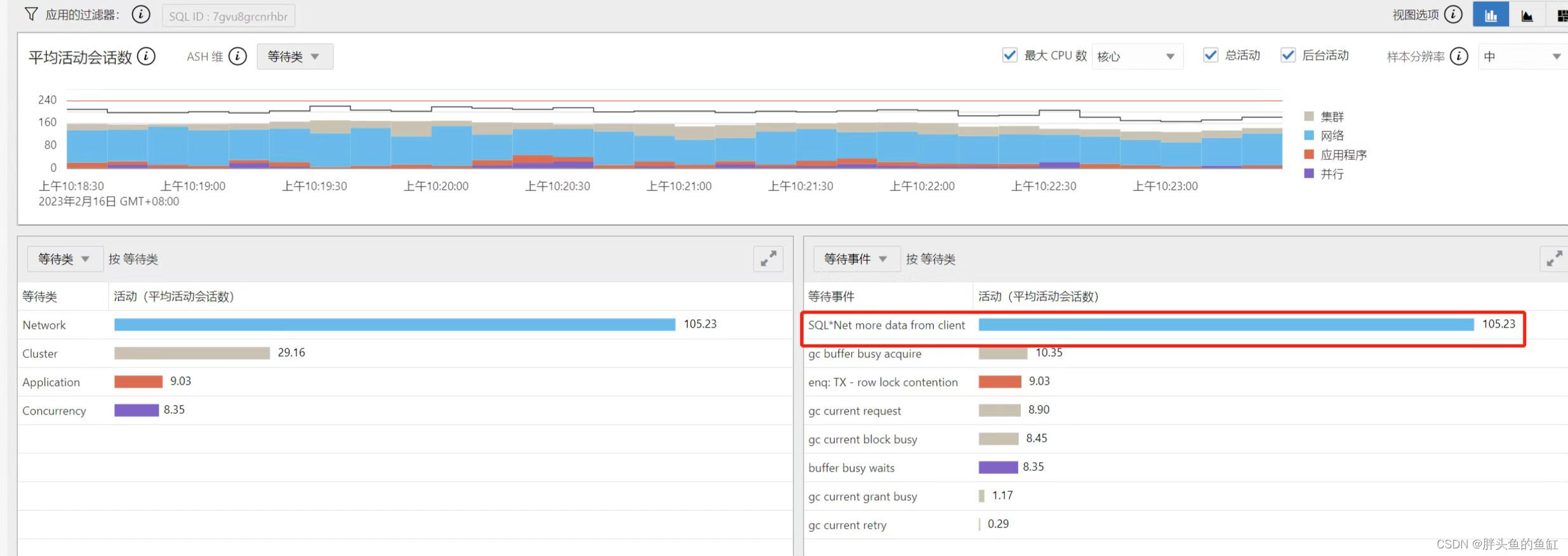
数据库本身运行并未太多异常等待,但是出现了大量的SQL*Net More data from client等待,加上这个业务服务在B数据中心的部分并没有出现问题,这里就基本能够确定应该是网络出现了异常。随即反馈网络工程师进行排查,一开始还说没啥告警应该没问题,紧接着就说有一条100GE的链路震荡了在闪断,在链路恢复前暂时屏蔽了这条链路,随即业务均恢复正常,前前后后大概处理了半小时。
其实这次故障不算小,影响了一线业务展开,也影响了各类流程、工单流转,但是好在时间不长,也不是全受影响(其中我的那套备库同步就没有受到影响),所以总体来说还好。
2 挂一大片
本以为本周的“大事”就此过去,结果星期五凌晨在B数据中心就出现了一台EMC unity存储,两个存储控制器同时挂掉的问题,我也是睡下没多久,就接到硬件维护的电话,打开手机看到了灾备数据库实例都挂掉的告警信息。因为我那套备库ASM只有部分使用了这台存储,且集群运行也并未在这台存储上,所以GI没挂DB挂了,又因为是备库,因此不影响我这边(要不然就需要failover了)。
然后就是这套存储还承载了两套虚拟化集群,包括我管理B数据中心Oracle数据库的一套运行EM的虚拟机。因为不知道恢复时间,加上故障处理群一直有消息,所以睡得不是很好。第二天一大早还陪媳妇儿去了趟医院,到了午后存储才恢复了单边控制器,而我这边数据库在刷了半个小时链路后才识别完所有LUN,才把数据库起起来,ADG的好处是,备库故障时,主库的归档日志仍然保留不会因备份delete input删除,在备库恢复后,所有的需要的介质恢复都会从主库同步过来,所以这套备库的恢复还是顺利的,只不过花了不少时间同步主库日志并应用(虽然中间存储又波动了一次,DB又挂掉重新扫盘启动,但是并没有太大问题)。
3 恢复虚拟机
其实虚拟化这块操作系统的启动倒是出了很多问题,以我那台EM虚拟机为例,操作系统能正常启动,但是数据盘启动自动挂载后就会掉盘,umount -f再mount后问题依旧,尝试重启也没有恢复。查看系统日志发现这块逻辑卷的xfs出现了异常,无法进行IO操作。因此尝试进行xfs_repaire:
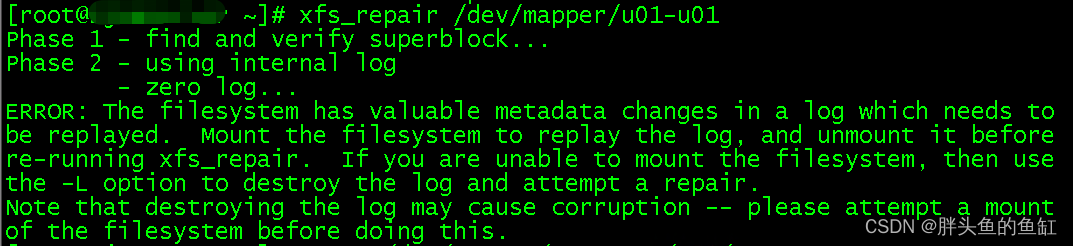
根据ERROR反馈执行:
mount /u01
umount /u01
xfs_repaire /dev/mapper/u01-u01
##成功完成修复
mount /u01
##挂载后无异常
在重启数据库的时候又出现另一个问题:
ORA-00214: control file '/u01/app/oracle/oradata/omsdb/controlfile/control01xxx' version N inconsistent with
file '/u01/app/oracle/fast_recover_area/oms/controlfile/control02xxx' version n
两个控制文件版本(SCN)不一致,通过相互覆盖的方式尝试mount数据库仍然出现ORA-600的报错无法启动,也就说明两个控制文件都不是最新的,因此只能通过语句重建control file:
STARTUP NOMOUNT
##摘自19c官方文档(少量修改)
CREATE CONTROLFILE REUSE DATABASE "omsdb" NORESETLOGS NOARCHIVELOG
MAXLOGFILES 32
MAXLOGMEMBERS 3
MAXDATAFILES 1024
MAXINSTANCES 1
MAXLOGHISTORY 1024
LOGFILE ##需要所有
GROUP 1 '/u01/app/oracle/oradata/omsdb/onlinelog/redo01.log' SIZE 1g,
GROUP 1 '/u01/app/oracle/oradata/omsdb/onlinelog/redo02.log' SIZE 1g,
GROUP 1 '/u01/app/oracle/oradata/omsdb/onlinelog/redo03.log' SIZE 1g
# STANDBY LOGFILE
DATAFILE #需要填写所有数据文件,不需要临时文件
'/u01/app/oracle/oradata/omsdb/datafiles/system01.dbf',
'/u01/app/oracle/oradata/omsdb/datafiles/sysaux01.dbf',
'/u01/app/oracle/oradata/omsdb/datafiles/mgmt01.dbf',
'/u01/app/oracle/oradata/omsdb/datafiles/sysman01.dbf'
...
CHARACTER SET AL32UTF8
;
alter database mount;
这里数据库是可以mount的,但是在open的时候又出现了ORA-01113 file xxx needs media recovery,通过recover database成功恢复数据库并启动(如果recover操作出现问题,可能就需要不完全恢复了,还好这只是个监控数据库,丢数据没啥问题)。
当然,我觉得我这台虚拟机恢复还算是简单的了,客户那边并没有操作系统方面的专门维护人员,都是硬件维护兼任的,两个虚拟化集群的大量机器大多数都或多或少出现了一些异常,比如引导故障、磁盘(逻辑卷)只读、权限问题等等,因此我们也借调了以为Linux工程师(红帽授权那种)到现场协助进程处理,大大加快了恢复进程。
总结
算是熬了一天,虽然睡了很久,还是头疼。
老规矩,知道写了些啥。


![[安装] Dell电脑安装系统时看不到固态硬盘的解决方案](https://img-blog.csdnimg.cn/img_convert/fc95cc2782e24f7aba4f172cc82b5039.png)