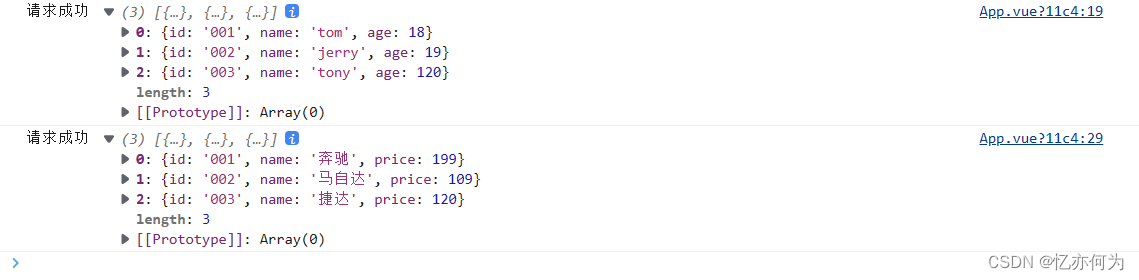
用python程序和谷歌selenium插件获取某东商品详细信息【商品名称、商品简介,超链接】
利用selenium自动化程序 中的css页面结构索取来获取详细数据
关于谷歌selenium的安装方法和使用方法
第一步检查自己谷歌浏览器的版本
1.1 找到设置:并鼠标点击进入

1.2进入设置选项后,下滑到最底部找到“关于Chrome”鼠标点击进入
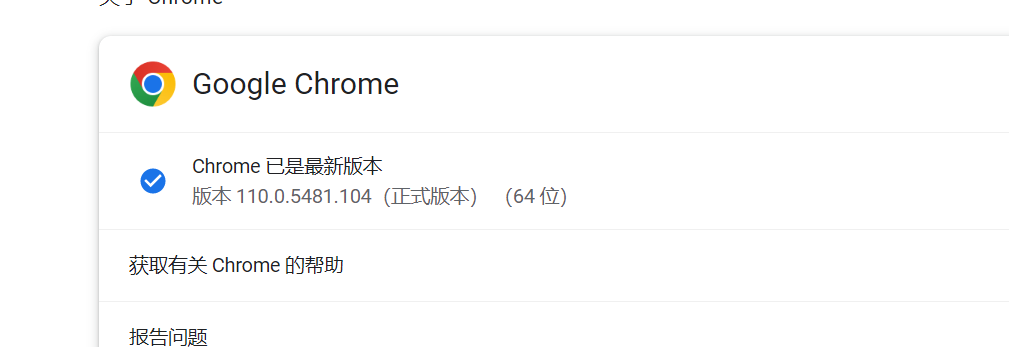
1.3查看谷歌浏览器的版本号
第二步:进入selenium谷歌驱动网址下载对应版本号的驱动
(不要过分追求一致性,只要110.05481.xxx)xxx不一致没关系
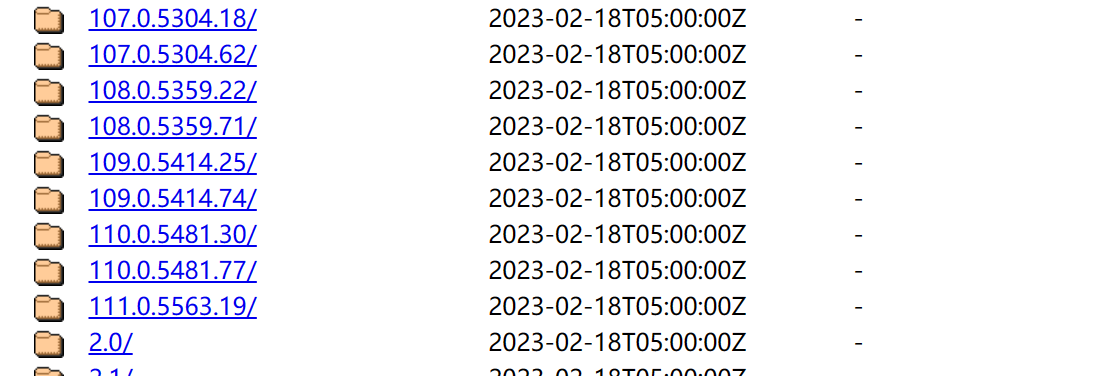
查找对应操作系统的版本(一般是win32.zip,除非你会用虚拟机,或者你用的是iphone操作系统可以选择对应的)我们的电脑不是64位操作系统吗为什么安装32位的,这我也不知道,反正大家都是这样弄的。

点击下载:
将下载完成后的“chromedriver.exe“运行文件 复制到python运行的直系文件中
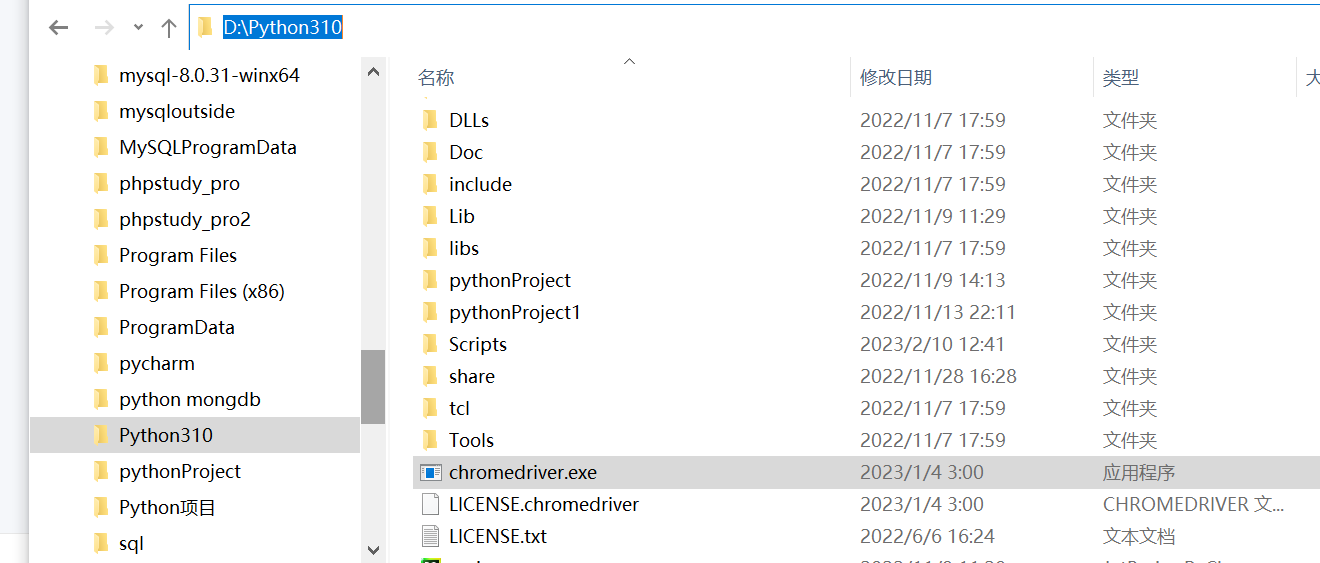
在python的第三方库中安装好selenium
安装第三方库或者模块的方法有两种:
第一种:pycharm
第二种:命令提示符cmd的方式输入 pip install selenium
CMD全称command。即命令提示符,是在OS / 2 , Windows为基础的操作系统下的DOS 方式
第三部分代码详解:
3.1在pycharm中导入第三方模块(selenium)
时间模块
import time
网页请求模块
import requests
新版本selenium库的导入方法
from selenium.webdriver.common.by import By3.2主函数方法的调用 :
if __name__ == '__main__':
spider('https://www.jd.com/?',keyword='python数据结构')3.3
spider()方法的执行模块
作用向网页发起请求,并且利用selenium方法将谷歌浏览其控制起来
def spider(url,keyword): #构造一个方法
# 通过运行程序打开浏览器
open_Chrome = webdriver.Chrome()
open_Chrome.get(url=url)
#open_Chrome.implicitly_wait(3) #隐式等待
input_date = open_Chrome.find_element(by=By.ID, value='key')
input_date.send_keys(keyword)
# 这种写法是不被允许的,input_date = open_Chrome.find_element(by=By.ID,value='key').send_keys(keyword)
#不是input_date = open_Chrome.find_element(by=By.ID,value='').send_keys()这种方法不被允许,而是,要写都写成这样不要一个写成这样一个有进行方法的调用
#比如:
input_date.send_keys(Keys.ENTER) #用Keys中的点击方法
open_Chrome.implicitly_wait(10)
drop_down(open_Chrome)
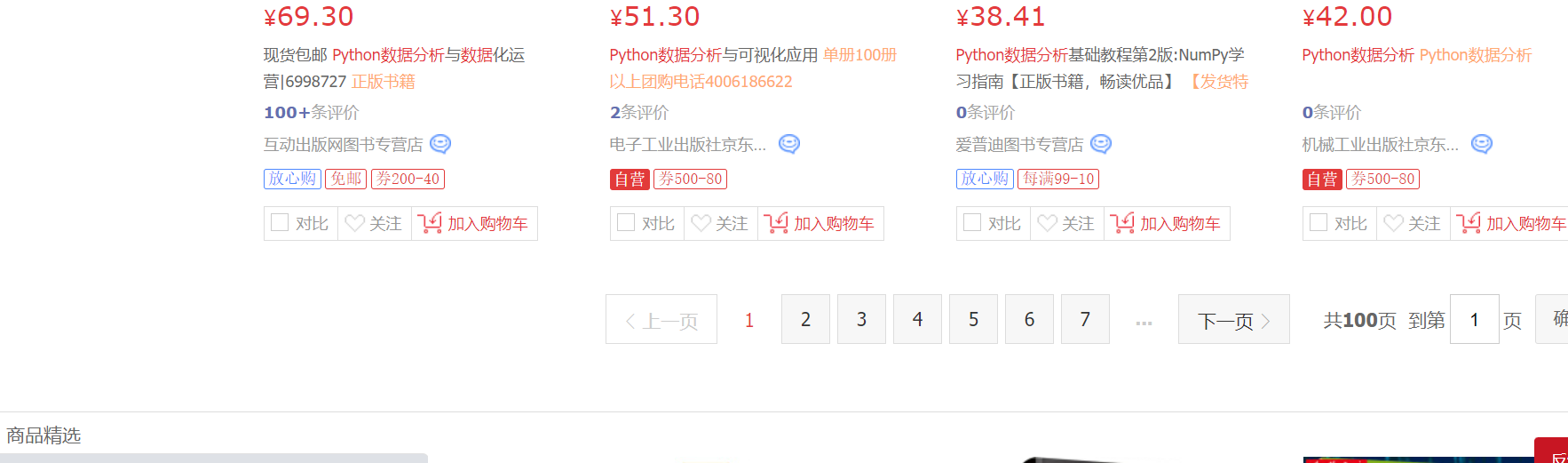
get_gods(open_Chrome)执行结果:
这都是程序自己干的我只是运行了一下程序
3.2让自动化程序控制谷歌浏览器在商品页界面最右侧的黑灰色滑块进行滑动
def drop_down(open_Chrome):
for x in range(1,12,2):
time.sleep(1)
j = x / 9
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
open_Chrome.execute_script(js)
buttons(open_Chrome)
3.3当前数据页面解析:
使用的方法是:通过css选择器来定位标签元素。
使用方法:find_elements(By.####,'.xxxxx') ####表示使用那种方法,xxxxx表示该页面css的值
def get_gods(open_Chrome):
#css选择器中#键表示id选择器,.表示class选择器
#labels 获取的是每一个商品数据
labels = open_Chrome.find_elements(By.CSS_SELECTOR,'.goods-list-v2 .gl-item') #find_elements 获取的是多个数据,find_element只能获取一个
print(labels)
for label in labels:
em_txt= label.find_element(By.CSS_SELECTOR,'.p-name em').text
money_txt = label.find_element(By.CSS_SELECTOR,'.p-price strong i').text
Release_txt = label.find_element(By.CSS_SELECTOR, '.hd-shopname').text
hyper_link = label.find_element(By.CSS_SELECTOR,'.p-name a').get_attribute('href') #get_attribute 获取标签的属性
print(em_txt,f"{money_txt}:元",Release_txt,hyper_link)关于selenium页面解析的其他方法,有很多那个效率更高,比较简单就去使用那个:具体方法要去学习,如何简单调用我将写在下方

新版本 find_element()的使用方法

selenium的页面元素定位方法find_element
感谢这两位作者提供关于selenium的简介和最新使用方法,因为selenium已经更新了,如果在pcharm下载的selenium是2.0以上版本的要使用最新方法,如何进行简单调用请通过上方的连接地址进行访问阅读
3.4 进行多页面爬取(一个页面肯定不够)
这是一个自动点击“下一页”的按钮,click()就是自动点击的方法
def buttons(open_Chrome):
button = open_Chrome.find_element(By.CSS_SELECTOR,'.page .p-num .pn-next em')
button.click()
time.sleep(2)
get_gods(open_Chrome)关于我为什么要加上下滑的方法,大家可以去某东网页去感受一下,现在某东将两张页面合并在了一起,本质上是一张页面,但是又包含了两页信息,所以我们需要通过滑块下滑的方法将完整的一页信息加载出来,要不然拿到的数据不完整。
完整代码:
import time
import requests
from selenium.webdriver.common.by import By
from selenium import webdriver
#这种写法已经被舍弃掉了
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys #模拟键盘点击
#打开浏览器
# 2.登录京东
#打开网页
def spider(url,keyword): #构造一个方法
# 通过运行程序打开浏览器
open_Chrome = webdriver.Chrome()
open_Chrome.get(url=url)
#open_Chrome.implicitly_wait(3) #隐式等待
input_date = open_Chrome.find_element(by=By.ID, value='key')
input_date.send_keys(keyword)
# 这种写法是不被允许的,input_date = open_Chrome.find_element(by=By.ID,value='key').send_keys(keyword)
#不是input_date = open_Chrome.find_element(by=By.ID,value='').send_keys()这种方法不被允许,而是,要写都写成这样不要一个写成这样一个有进行方法的调用
#比如:
'''
input_date = open_Chrome.find_element(by=By.ID, value='key').send_keys(keyword)
input_date.send_keys(Keys.ENTER)
'''
input_date.send_keys(Keys.ENTER) #用Keys中的点击方法
open_Chrome.implicitly_wait(10)
drop_down(open_Chrome)
get_gods(open_Chrome)
#这个自定义的方法就是让其右边的滑轮自动滑动
def drop_down(open_Chrome):
for x in range(1,12,2):
time.sleep(1)
j = x / 9
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
open_Chrome.execute_script(js)
buttons(open_Chrome)
def buttons(open_Chrome):
button = open_Chrome.find_element(By.CSS_SELECTOR,'.page .p-num .pn-next em')
button.click()
time.sleep(2)
get_gods(open_Chrome)
def get_gods(open_Chrome):
#css选择器中#键表示id选择器,.表示class选择器
#labels 获取的是每一个商品数据
labels = open_Chrome.find_elements(By.CSS_SELECTOR,'.goods-list-v2 .gl-item') #find_elements 获取的是多个数据,find_element只能获取一个
print(labels)
for label in labels:
em_txt= label.find_element(By.CSS_SELECTOR,'.p-name em').text
money_txt = label.find_element(By.CSS_SELECTOR,'.p-price strong i').text
Release_txt = label.find_element(By.CSS_SELECTOR, '.hd-shopname').text
hyper_link = label.find_element(By.CSS_SELECTOR,'.p-name a').get_attribute('href') #get_attribute 获取标签的属性
print(em_txt,f"{money_txt}:元",Release_txt,hyper_link)
# for label in labels:
# name = label.find_element(By.XPATH,'./div[@class="gl-i-wrap"]//em/font/text()')
# print(name)
# input()
#主函数:方法调用
if __name__ == '__main__':
spider('https://www.jd.com/?',keyword='python数据结构')测试结果:
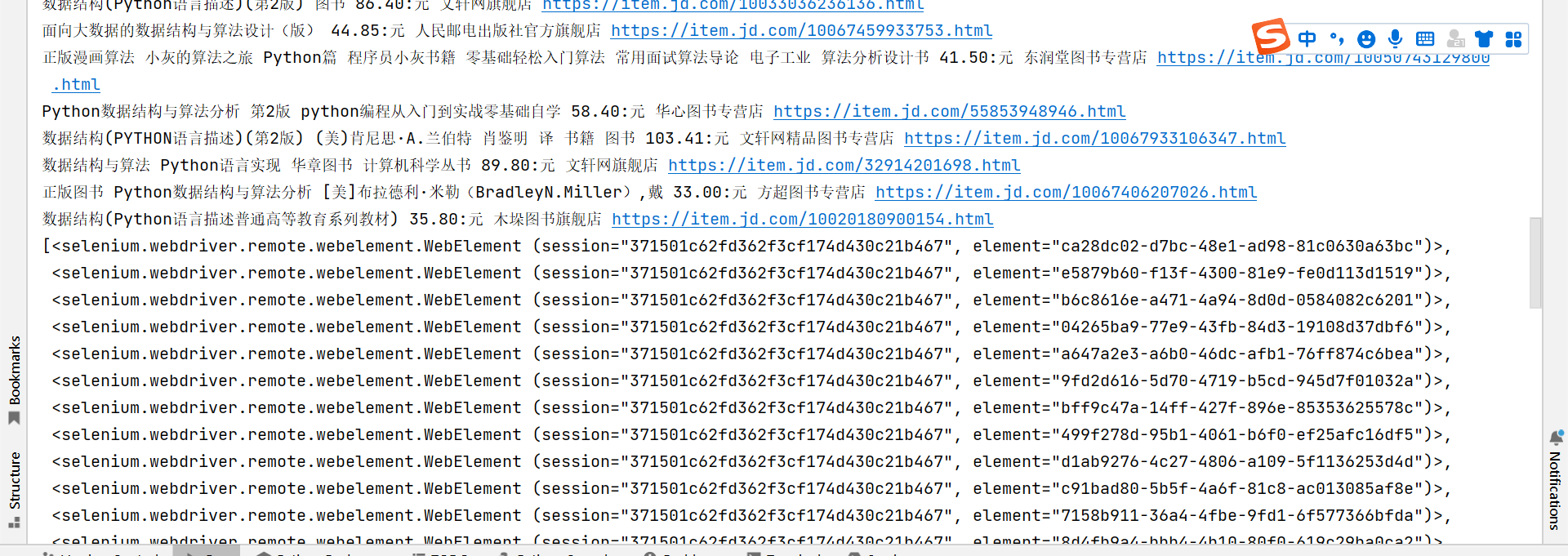
关于代码的解析太过于繁琐,我就不进行赘述了,大家哪里不懂可以留言私信。




![[软件工程导论(第六版)]第3章 需求分析(课后习题详解)](https://img-blog.csdnimg.cn/4c778e1d5cb54e648742e2fea5fe8afc.png)