目录
一、HDFS概述
二、HDFS架构与工作机制
三、HDFS的Shell操作
四、Hdfs的API操作
一、HDFS概述
- HDFS:Hadoop Distributed File System;一种分布式文件管理系统,通过目录树定位文件。
- 使用场景:一次写入,多次读出,且不支持文件的修改。适用于数据分析,不适用于网盘应用;
- 优点:
- 高容错:多个副本,其中一个副本丢失,可以自动恢复;
- 适合处理大数据:数据规模大 & 文件规模大 & 可以构建于廉价机器上。
- 缺点:
- 不适合低延时数据访问;
- 无法高效的对大量小文件进行存储;
- 不支持并发写同一个文件,仅支持追加,不支持文件的随即修改。
二、HDFS架构与工作机制
- 官方文档
Apache Hadoop 3.3.4 – HDFS Architecture - 组成部分
- NameNode(NN):即Master,管理HDFS。
- Secondary NameNode(SNN):不是NN的热备份(热备份是指在程序还在运行的时候对数据进行备份)SNN对于NN的作用不同于平常的热备份的概念,SNN包含Fsimage和Edits,会定期合并Fsimage和Edits并推送给NN。
- DataNode(DN):即Slaver,执行NN下达的命令。
- Client:客户端,交互与访问。
- Block(hdfs文件块)
- Hadoop1.x中是64M,在Hadoop2.x-3.x中是128M;
- 块的大小既不能太大,也不能太小;(块大小的设置取决于磁盘传输的速率);
- NameNode和SecondaryNameNode的工作机制
- NameNode启动
- 第一次启动NN,需要创建命名空间镜像文件(fsimage)和编辑日志文件(edits)(如果NN不是第一次启动,直接加载fsimage文件和edits文件到内存);
- NN记录操作日志,滚动日志;
- NN在内存中对元数据进行修改操作。
- SecondaryNameNode工作过程
- SNN询问NN是否需要CheckPoint(是否需要合并fsimage和edits)。
- Secondary NameNode请求执行CheckPoint。
- NameNode滚动正在写的Edits日志。将滚动前的编辑日志和镜像文件拷贝到SNN,SNN加载编辑日志和镜像文件到内存进行合并,生成新的镜像文件fsimage.chkpoint。
- 拷贝fsimage.chkpoint到NameNode,NameNode将fsimage.chkpoint重新命名成fsimage。

- NameNode启动
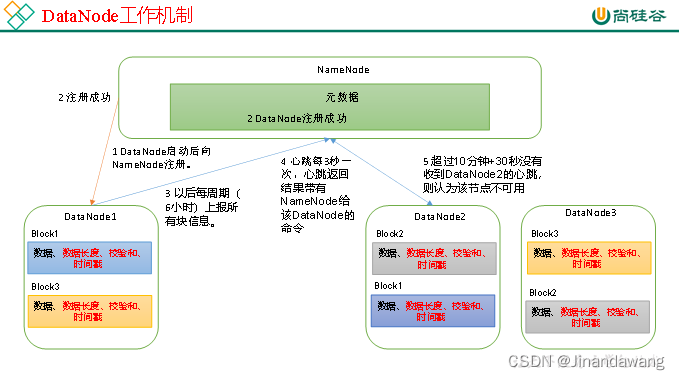
- DataNode的工作机制
- 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳)。
- DataNode启动后向NameNode注册,通过后,周期性(6小时)地向NameNode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
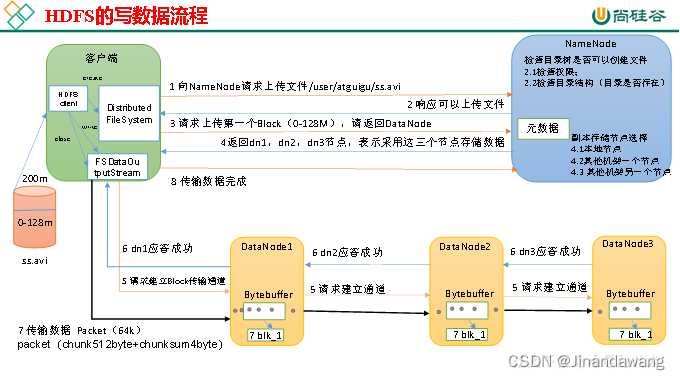
- HDFS的写流程
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查集群上目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求询问第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成(Pipe管道机制)。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet,就会将其放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
- 传输完成后通知NameBode通知Client完成传输。
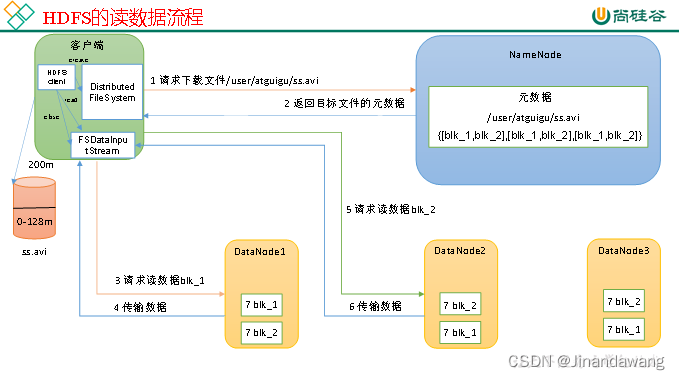
- HDFS的读流程
- 客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
- 网络拓扑-节点距离计算 & 机架感知(副本位置的选择)
- 距离如图所示
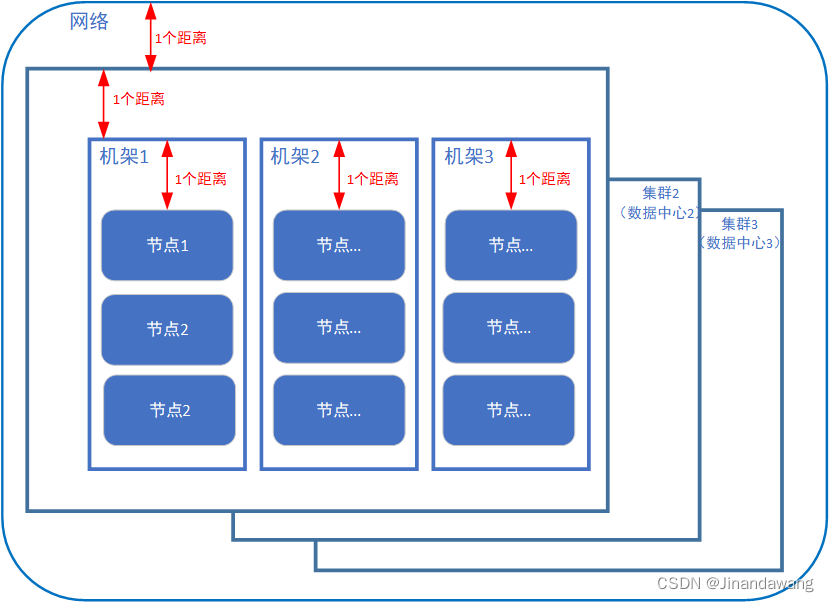
- 网络拓扑(将整个网络视为一个节点,各个大数据集群则是这整个网络节点的子节点,各个机架则分别是每个集群的子节点,每个实际节点又是机架节点的子节点。依次画出网络拓扑图并计算距离)
- 副本位置
- 第一个副本位于客户端所处的节点上,如果客户端不属于集群节点,则随机选择一个;
- 第二、三个副本位于另一个机架上的两个不同节点之上。
- 距离如图所示
- 数据完整性
- DataNode读取Block的时候,它会计算CheckSum,计算Block是否已经损坏;
- DataNode在文件创建后周期验证CheckSum;
三、HDFS的Shell操作
- hadoop fs 某指令 与 hdfs dfs 某指令 是一样的
- Hadoop hdfs的启动与关闭(以下是自定义脚本开启关闭hdfs)
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac - hdfs文件的上传下载
* 格式:hadoop fs -指令 [参数列表]上传: 1、本地"剪切"上传:hadoop fs -moveFromLocal ./localfile.txt /hdfs_dir 2、本地拷贝上传: hadoop fs -copyFromLocal ./localfile.txt /hdfs_dir hadoop fs -put ./localfile.txt /hdfs_dir (工作环境更倾向于用put) 3、追加(hdfs文件已存在) hadoop fs -appendToFile localfile.txt /hdfs_dir/hdfsfile.txt ======================================================================================= 下载: 1、hdfs拷贝至本地: hadoop fs -copyToLocal /hdfs_dir/hdfsfile.txt ./ hadoop fs -get /hdfs_dir/hdfsfile.txt ./ (生产环境更倾向于用get) - 其他Hadoop shell指令(略)
四、Hdfs的API操作
- 在Windows下配置Hadoop的运行环境
- 添加Hadoop的Windows依赖文件夹至Windows下一个纯英文路径,配置HADOOP_HOME和Path环境变量(Hadoop的Windows依赖官网没有直接提供,需要自行下载,双击winutils.exe可以验证环境变量是否正常,报错可能是因为缺少微软运行库)
- 新建Idea Maven项目(配置阿里云maven镜像可以使下载的速度更快)
- 导入相应的依赖坐标(修改pom.xml - import changes)
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency> </dependencies>
- 导入相应的依赖坐标(修改pom.xml - import changes)
-
- 日志添加(在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入)
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 日志添加(在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入)
- API编写代码(*重新理解API这个宽泛的概念)
- Java代码的大致逻辑:获取客户端对象 → 执行操作 → 关闭资源(Java标签的用法也可以了解一下,挺好用的)
package cn.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.sql.Array; import java.util.Arrays; public class HdfsClient { private URI uri; private Configuration conf; private String user = "hadoop"; //文件系统用于进行操作的用户名,这个用户名决定了操作的权限。 private FileSystem fs; @Before public void init() throws URISyntaxException, IOException, InterruptedException { // uri = new URI("hdfs://hadoop101:8020"); // 统一资源定位符:8020是NameNode内部通信端口 conf = new Configuration(); //配置对象默认为空 fs = FileSystem.get(uri, conf, user); //使用get()获取FileSystem实例 } @After public void close() throws IOException { fs.close(); // 关闭FileSystem实例 } @Test //创建目录 public void testmkdir() throws URISyntaxException, IOException, InterruptedException { fs.mkdirs(new Path("/目录名")); //mkdirs()方法:创建一个新的目录 } @Test //测试各个部分配置文件的优先级 /* * 代码内部的配置优先级 > 项目资源目录下的配置文件的优先级 > Linux上的配置文件 > 默认配置 * */ public void testPut() throws IOException, InterruptedException { conf.set("dfs.replication", "2"); //node level参数,指定每个block在集群上有几个备份(因为这个参数在hdfs-site.xml也有配置,所以可以用来比较这些参数之间的优先级) fs = FileSystem.get(uri, conf, user); fs.copyFromLocalFile(false, true, new Path("D:\\Edelweiss.txt"), new Path("hdfs://hadoop101/目录名称")); //hdfs文件路径开始的一部分是主机名 } @Test //文件 下载 public void testGet() throws IOException { fs.copyToLocalFile(false, new Path("/集群上的路径"), new Path("C:\\Users\\用户名\\Desktop"), false); } //删除delete、移动rename、更名rename等操作 略 @Test //列出目录详细信息(也可以用于判断“路径类型”——文件或者目录) public void fileDetail() throws IOException { final RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); //迭代器 while (listFiles.hasNext()) { LocatedFileStatus fileStatus = listFiles.next(); //文件状态 System.out.println("---------------" + fileStatus.getPath() + "---------------"); System.out.println(fileStatus.getPermission()); System.out.println(fileStatus.getBlockLocations()); final BlockLocation[] blockLocations = fileStatus.getBlockLocations(); System.out.println(Arrays.toString(blockLocations)); } } @Test public void Test(){ System.out.println("okk"+"\n"); System.out.println("ookk"+"\\N"); } } - 关于代码内部配置的优先级 > 项目资源目录下的配置文件的优先级 > Linux上的配置文件 > 默认配置。
- Java代码的大致逻辑:获取客户端对象 → 执行操作 → 关闭资源(Java标签的用法也可以了解一下,挺好用的)
- 遇见的报错:
- 不支持发行版本5:https://www.cnblogs.com/KennyWang0314/p/12268953.html 按图设置成与自己本地jdk匹配的版本就好了。之前maven是默认Java5,而我的本地是jdk11,无法生成Java5二进制文件。


![[软件工程导论(第六版)]第3章 需求分析(课后习题详解)](https://img-blog.csdnimg.cn/4c778e1d5cb54e648742e2fea5fe8afc.png)