在搜索和推荐任务中,系统常返回一个item列表。如何衡量这个返回的列表是否优秀呢?
例如,当我们检索【推荐排序】,网页返回了与推荐排序相关的链接列表。列表可能会是[A,B,C,G,D,E,F],也可能是[C,F,A,E,D],现在问题来了,当系统返回这些列表时,怎么评价哪个列表更好?
这就引出了这篇文章要介绍的两个评价指标——NDCG和MAP,这两个指标都是用来评估排序结果的。
1. NDCG
NDCG的全称是:Normalized Discounted Cumulative Gain(归一化折损累计增益)学习NDCG最好按照G-CG-DCG-NDCG这个顺序来学习。
-
Gain:表示一个列表中所有item的相关性分数。rel(i)表示item(i)相关性得分。
G a i n = r e l ( i ) Gain = rel(i) Gain=rel(i)
-
Cumulative Gain:表示对K个item的Gain进行累加。
C G k = ∑ i = 1 k r e l ( i ) CG_k = \sum_{i=1}^krel(i) CGk=∑i=1krel(i)
CG只是单纯累加相关性,不考虑位置信息。
如果返回一个list_1= [A,B,C,D,E],那list_1的CG为0.5+0.9+0.3+0.6+0.1=2.4
如果返回一个list_2=[D,A,E,C,B],那list_2的CG为0.6+0.5+0.1+0.3+0.9=2.4
所以,顺序不影响CG得分。如果我们想评估不同顺序的影响,就需要使用另一个指标DCG来评估。
-
Discounted Cumulative Gain: 考虑排序顺序的因素,使得排名靠前的item增益更高,对排名靠后的item进行折损。
CG与顺序无关,而DCG评估了顺序的影响。DCG的思想是:list中item的顺序很重要,不同位置的贡献不同,一般来说,排在前面的item影响更大,排在后面的item影响较小。(例如一个返回的网页,肯定是排在前面的item会有更多人点击)。所以,相对CG来说,DCG使排在前面的item增加其影响,排在后面的item减弱其影响。
D C G k = ∑ i = 1 k r e l ( i ) l o g 2 ( i + 1 ) DCG_k = \sum_{i = 1}^k\frac{rel(i)}{log_2(i+1)} DCGk=∑i=1klog2(i+1)rel(i)
怎么实现这个思想呢?DCG在CG的基础上,给每个item的相关性比上log2(i+1),i越大,log2(i+1)的值越大,相当于给每个item的相关性打个折扣,item越靠后,折扣越大。
还是上面那个例子:
list_1=[A,B,C,D,E], 其对应计算如下:
i rel(i) log(i+1) rel(i)/log(i+1) 1=A 0.5 1 0.5 2=B 0.9 1.59 0.57 3=C 0.3 2 0.15 4=D 0.6 2.32 0.26 5=E 0.1 2.59 0.04 list_1的 DCG_1= 0.5+0.57+0.15+0.26+0.04=1.52
list_2=[D,A,E,C,B],其对应计算如下:
i rel(i) log(i+1) rel(i)/log(i+1) 1=D 0.6 1 0.6 2=A 0.5 1.59 0.31 3=E 0.1 2 0.05 4=C 0.3 2.32 0.13 5=B 0.9 2.59 0.35 list_2的 DCG_2= 0.6+0.31+0.05+0.13+0.35=1.44
DCG_1 > DCG_2, 所以在这个例子里list_1优于list_2。
到这里,我们可以知道,使用DCG方法就可以对不同的list进行评估,那为什么后面还有一个NDCG呢?
-
NDCG(Normalized DCG): 归一化折损累计增益
在NDCG之前,先了解一些IDGC(ideal DCG)–理想的DCG,IDCG的依据是:是根据rel(i)降序排列,即排列到最好状态。算出最好排列的DCG,就是IDCG。
IDCG=最好排列的DCG
对于上述的例子,按照rel(i)进行降序排列的最好状态为list_best=[B,D,A,C,E]
i rel(i) log(i+1) rel(i)/log(i+1) 1=B 0.9 1 0.9 2=D 0.6 1.59 0.38 3=A 0.5 2 0.25 4=C 0.3 2.32 0.13 5=E 0.1 2.59 0.04 IDCG = list_best的DCG_best = 0.9+0.38+0.25+0.13+0.04=1.7 (理所当然,IDCG>DCG_1和DCG_2)
因为不同query的搜索结果有多有少,所以不同query的DCG值就没有办法来做对比。所以提出NDCG。
N D C G = D C G I D C G NDCG = \frac{DCG}{IDCG} NDCG=IDCGDCG
所以NDGC使用DCG/IDCG来表示,这样的话,NDCG就是一个相对值,那么不同query之间就可以通过NDCG值进行比较评估。
2. MAP
要学习MAP指标首先要了解Precision这个指标,即精确度。在推荐系统场景下,我们可以定义正样本为相关的商品,因此Precision就代表了,推荐的 n 个商品中,有多少个商品是相关的。而Recall就代表了数据库中一共有 m个相关商品,推荐系统选出了多少个相关商品。
例如下面的理财产品推荐场景,用户在未来购买了四款产品,而一个推荐系统在当前推荐了三款产品,用户只购买了一款产品。那么此时,推荐系统的Recall为 1/4 ,Precision为 1/3。
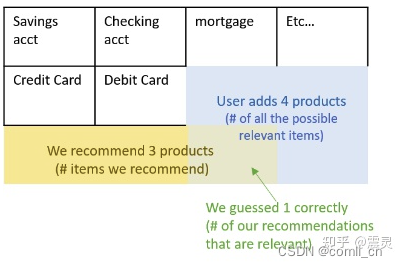
值得注意的是,由于屏幕大小限制,推荐系统只能展示前 N 个商品,因此一般推荐系统中的Precision计算会采用Cutoff形式进行计算。如下图所示,尽管我们的推荐系统可以推荐 m个商品,但是在Cutoff-Precision的计算过程中,只会考虑前 k 个商品的Precision。

根据上面的概念,我们就可以定义Average Precision。从公式中可以看出,AP@N可以直观理解为枚举Precision@k之后取平均值。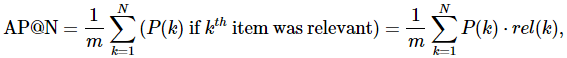
第k个item的precision是指前k个推荐的item里被用户pick的item有几个
在推荐系统场景下,使用AP最大的好处在于AP不仅仅考虑了商品推荐的准确率,还考虑了推荐顺序上的差异。考虑下面这样一个表格,从整体来考虑的话,三种推荐方案都只推荐了一个相关商品,但是第一种推荐方案明显是更好的,而AP指标可以体现这种差异。

介绍了AP@N指标,我们就可以定义MAP@N指标了。其实MAP@N指标就是将所有用户 UUU 的AP@N指标进行平均。
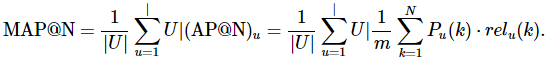
总的来说,MAP指标同时考虑了预测精准度和相对顺序,从而避免了传统Precision指标无法刻画推荐商品相对位置差异的弊端。因此。在很多推荐系统场景下,MAP指标是一个非常值得尝试的推荐系统评估指标。
参考1:知乎Satellite
参考2:知乎震灵




![[软件工程导论(第六版)]第3章 需求分析(课后习题详解)](https://img-blog.csdnimg.cn/4c778e1d5cb54e648742e2fea5fe8afc.png)