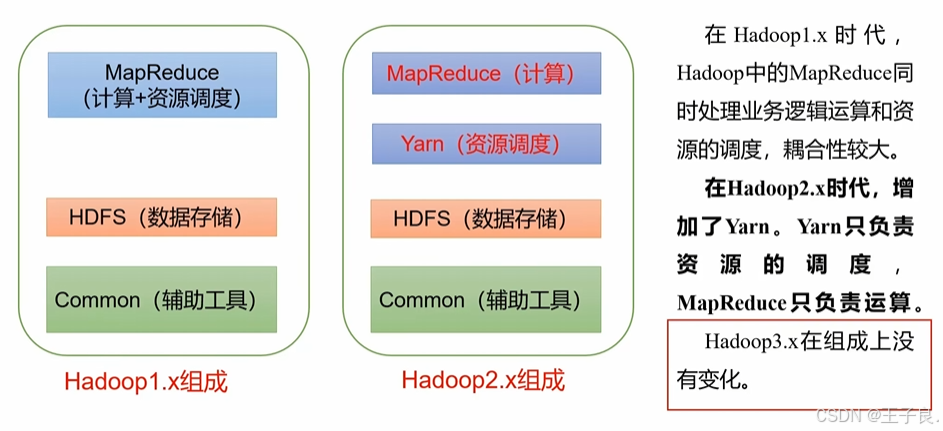
一、feature_importances_属性
在机器学习中,分类和回归算法的 feature_importances_ 属性用于衡量每个特征对模型预测的重要性。这个属性通常在基于树的算法中使用,通过 feature_importances_ 属性,您可以了解哪些特征对模型的预测最为重要,从而可以进行特征选择或特征工程,以提高模型的性能和解释性。
1、决策树
1.1. sklearn.tree.DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0, monotonic_cst=None)[source]
1.2. sklearn.tree.DecisionTreeRegressor
class sklearn.tree.DecisionTreeRegressor(*, criterion='squared_error', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, ccp_alpha=0.0, monotonic_cst=None)
1.3. sklearn.tree.ExtraTreeClassifier
class sklearn.tree.ExtraTreeClassifier(*, criterion='gini', splitter='random', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0, monotonic_cst=None)
1.4. sklearn.tree.ExtraTreeRegressor
property feature_importances_
返回标准化后的特征的重要性,又被称为基尼重要性,即通过计算每个特征在决策树的各个节点上对Gini不纯度的减少量来评估特征的重要性。
具体来说,Gini重要性计算步骤如下:
- 在构建决策树的过程中,每次选择一个特征进行节点分裂时,计算该特征在该节点上的Gini不纯度减少量。
- 将该特征在所有节点上的Gini不纯度减少量累加,得到该特征的总Gini不纯度减少量。
- 对所有特征的总Gini不纯度减少量进行归一化处理,使其总和为1。
最终,Gini重要性值越高,表示该特征对分类结果的贡献越大。Gini重要性常用于特征选择和特征工程中,以识别和保留对模型性能影响较大的特征。
2、随机森林和梯度提升
2.1. sklearn.ensemble.RandomForestClassifier
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None, monotonic_cst=None)
2.2. sklearn.ensemble.RandomForestRegressor
class sklearn.ensemble.RandomForestRegressor(n_estimators=100, *, criterion='squared_error', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=1.0, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None, monotonic_cst=None)
2.3. sklearn.ensemble.GradientBoostingClassifier
class sklearn.ensemble.GradientBoostingClassifier(*, loss='log_loss', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
2.4. sklearn.ensemble.GradientBoostingRegressor
class sklearn.ensemble.GradientBoostingRegressor(*, loss='squared_error', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
property feature_importances_
返回总和为1的特征重要性,除非所有树只有一个根节点。
3、AdaBoost
3.1. sklearn.ensemble.AdaBoostClassifier
class sklearn.ensemble.AdaBoostClassifier(estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm='deprecated', random_state=None)
property feature_importances_
返回值:
feature_importances_:一维数组 (n_features,),The feature importances.
3.2. sklearn.ensemble.AdaBoostRegressor
class sklearn.ensemble.AdaBoostRegressor(estimator=None, *, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None)
property feature_importances_
返回值:
feature_importances_:一维数组 (n_features,),The feature importances.
4、XGBoost
4.1. xgboost.XGBClassifier
classxgboost.XGBClassifier(*, importance_type='total_gain', objective='binary:logistic', **kwargs)
参数:
- importance_type: 特征重要性的类型,关系到 feature_importances_属性:
- 树模型:可选 “gain”, “weight”, “cover”, “total_gain” 或 “total_cover”.
- 线性模型:进可选 “weight” .
属性:propertyfeature_importances_
- 返回值取决于importance_type参数:
- 一维数组[n_features],代表每个特征的重要性
- 线性模型:二维数组(n_features, n_classes),代表每个特征在每个类别上的重要性
4.2. xgboost.XGBRegressor
classxgboost.XGBRegressor(*, importance_type='total_gain', objective='reg:squarederror', **kwargs)
参数与属性相关内容同上
5、LightGBM
5.1. lightgbm.LGBMClassifier
classlightgbm.LGBMClassifier(boosting_type='gbdt', num_leaves=31, max_depth=-1, learning_rate=0.1, n_estimators=100, subsample_for_bin=200000, objective=None, class_weight=None, min_split_gain=0.0, min_child_weight=0.001, min_child_samples=20, subsample=1.0, subsample_freq=0, colsample_bytree=1.0, reg_alpha=0.0, reg_lambda=0.0, random_state=None, n_jobs=None, importance_type='split', **kwargs)
参数:
- importance_type(str, optional (default=‘split’)): 关系到 feature_importances_属性的输出:
- ‘split’:返回结果包含特征使用的次数
- ‘gain’:返回结果包含特征分裂时的总增益
属性:property feature_importances_
- 返回特征重要性,值越高,特征越重要:
- 一维数组[n_features],代表每个特征的重要性
5.2. lightgbm.LGBMRegressor
classlightgbm.LGBMRegressor(boosting_type='gbdt', num_leaves=31, max_depth=-1, learning_rate=0.1, n_estimators=100, subsample_for_bin=200000, objective=None, class_weight=None, min_split_gain=0.0, min_child_weight=0.001, min_child_samples=20, subsample=1.0, subsample_freq=0, colsample_bytree=1.0, reg_alpha=0.0, reg_lambda=0.0, random_state=None, n_jobs=None, importance_type='split', **kwargs)
参数与属性相关内容同上
二、permutation_importance方法
sklearn.inspection.permutation_importance
-评估特征的重要性,且模型已经过训练,即模型已调用fit(X, y)。
-由参数scoring指定评估度量方式;打乱特征列的值,打乱次数由参数n_repeats指定;评估特征值打乱前后的scoring度量结果的差异,即表示该特征的重要程度。
scoring评估指标可参考博客:分类、聚类与回归的评价指标
sklearn.inspection.permutation_importance(estimator, X, y, *, scoring=None, n_repeats=5, n_jobs=None, random_state=None, sample_weight=None, max_samples=1.0)
参数:
estimator:已经训练好的模型X:用于计算特征重要性的输入数据。y:目标值。scoring:评估指标,默认为 None,使用模型的默认评分方法。n_repeats:打乱特征的次数,默认为 5。
返回值:
importances_mean:每个特征基于n_repeats的重要性均值。importances_std:每个特征基于n_repeats的的重要性标准差。importances:每次打乱后特征的重要性。为二维数组,表示每个特征每次打乱后的重要性。
三、小结
feature_importances_是一些基于树的模型自带的一个属性,用于衡量每个特征对模型预测结果的重要性。它通常通过计算每个特征在树结构中的分裂点上所带来的信息增益来确定特征的重要性。permutation_importance是一种模型无关的方法,通过打乱特征的值来评估特征的重要性。具体来说,它通过打乱某个特征的值并观察模型性能的变化来确定该特征的重要性。如果打乱某个特征后模型性能显著下降,则说明该特征对模型非常重要。
| 魔心依赖性 | 计算方式 | 解释性 | |
|---|---|---|---|
feature_importances_ | 仅适用于一些特定的模型(如基于树的模型) | 基于模型内部的机制(如信息增益) | 结果依赖于模型的具体实现,可能不容易解释 |
permutation_importance | 方法是模型无关的,可以用于任何模型 | 通过打乱特征值并观察模型性能变化来计算 | 结果更直观,因为它直接反映了特征对模型性能的影响 |



![[免费]微信小程序(高校就业)招聘系统(Springboot后端+Vue管理端)【论文+源码+SQL脚本】](https://i-blog.csdnimg.cn/direct/6e930f3dde3c4f2bb9cf4501c8642e1c.jpeg)





![[工具]git克隆远程仓库到本地快速操作流程](https://i-blog.csdnimg.cn/direct/ab2ccccf9447452d92fd7a81dfe08d79.png)