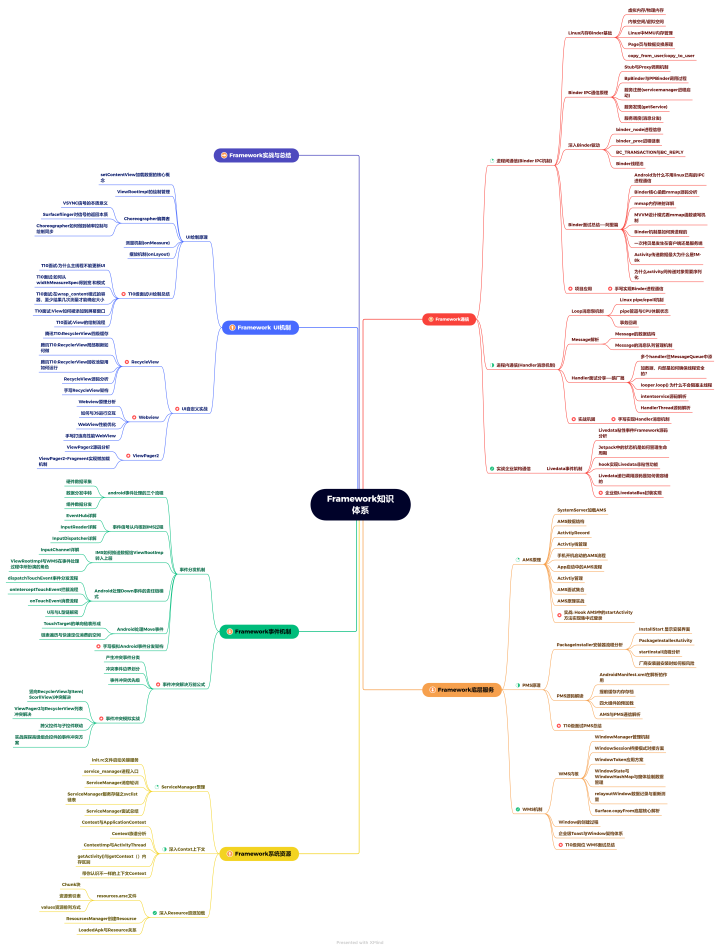
1. 什么是聚类
1.1. 聚类的定义
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
1.2. 聚类和分类的区别
聚类(Clustering):是指把相似的数据划分到一起,具体划分的时候并不关心这一类的标签,目标就是把相似的数据聚合到一起,聚类是一种无监督学习(Unsupervised Learning)方法。分类(Classification):是把不同的数据划分开,其过程是通过训练数据集获得一个分类器,再通过分类器去预测未知数据,分类是一种监督学习(Supervised Learning)方法。
1.3. 聚类的一般过程
- 数据准备:特征标准化和降维
- 特征选择:从最初的特征中选择最有效的特征,并将其存储在向量中
- 特征提取:通过对选择的特征进行转换形成新的突出特征
- 聚类:基于某种距离函数进行相似度度量,获取簇
- 聚类结果评估:分析聚类结果,如
距离误差和(SSE)等
1.4. 数据对象间的相似度度量
对于数值型数据,可以使用下表中的相似度度量方法。

Minkowski距离就是范数(
),而
Manhattan 距离、Euclidean距离、Chebyshev距离分别对应时的情形。
1.5. cluster之间的相似度度量
除了需要衡量对象之间的距离之外,有些聚类算法(如层次聚类)还需要衡量cluster之间的距离 ,假设和
为两个
cluster,则前四种方法定义的和
之间的距离如下表所示。

Single-link定义两个cluster之间的距离为两个cluster之间距离最近的两个点之间的距离,这种方法会在聚类的过程中产生链式效应,即有可能会出现非常大的clusterComplete-link定义的是两个cluster之间的距离为两个``cluster之间距离最远的两个点之间的距离,这种方法可以避免链式效应`,对异常样本点(不符合数据集的整体分布的噪声点)却非常敏感,容易产生不合理的聚类UPGMA正好是Single-link和Complete-link方法的折中,他定义两个cluster之间的距离为两个cluster之间所有点距离的平均值- 最后一种
WPGMA方法计算的是两个cluster之间两个对象之间的距离的加权平均值,加权的目的是为了使两个cluster对距离的计算的影响在同一层次上,而不受cluster大小的影响,具体公式和采用的权重方案有关。
2. 数据聚类方法
数据聚类方法主要可以分为划分式聚类方法(Partition-based Methods)、基于密度的聚类方法(Density-based methods)、层次化聚类方法(Hierarchical Methods)等。
2.1. 划分式聚类方法
划分式聚类方法需要事先指定簇类的数目或者聚类中心,通过反复迭代,直至最后达到"簇内的点足够近,簇间的点足够远"的目标。经典的划分式聚类方法有k-means及其变体k-means++、bi-kmeans、kernel k-means等。
2.1.1. k-means算法
经典的k-means算法的流程如下:

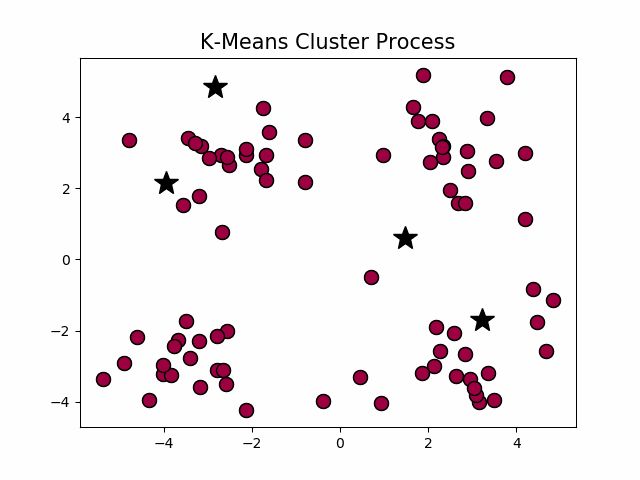
经典k-means源代码,下左图是原始数据集,通过观察发现大致可以分为4类,所以取k = 4,测试数据效果如下右图所示。


该函数的曲线如下图所示

可以发现该函数有两个局部最优点,当时初始质心点取值不同的时候,最终的聚类效果也不一样,接下来我们看一个具体的实例。

在这个例子当中,下方的数据应该归为一类,而上方的数据应该归为两类,这是由于初始质心点选取的不合理造成的误分。而k值的选取对结果的影响也非常大,同样取上图中数据集,取k = 2, 3,可以得到下面的聚类结果:

一般来说,经典k-means算法有以下几个特点:
- 需要提前确定k值
- 对初始质心点敏感
- 对异常数据敏感
2.1.2. k-means++算法
k-means++是针对k-means中初始质心点选取的优化算法。该算法的流程和k-means类似,改变的地方只有初始质心的选取,该部分的算法流程如下

k-means++源代码,使用k-means++对上述数据做聚类处理,得到的结果如下

K-means++ 能显著的改善分类结果的最终误差。尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。
2.1.3. bi-kmeans算法
一种度量聚类效果的指标是SSE(Sum of Squared Error),他表示聚类后的簇离该簇的聚类中心的平方和,SSE越小,表示聚类效果越好。 bi-kmeans是针对kmeans算法会陷入局部最优的缺陷进行的改进算法。该算法基于SSE最小化的原理,首先将所有的数据点视为一个簇,然后将该簇一分为二,之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否能最大程度的降低SSE的值。
该算法的流程如下:

bi-kmeans算法源代码,利用bi-kmeans算法处理上节中的数据得到的结果如下图所示。

这是一个全局最优的方法,所以每次计算出来的SSE值基本也是一样的(但是还是不排除有部分随机分错的情况),我们和前面的k-means、k-means++比较一下计算出来的SSE值
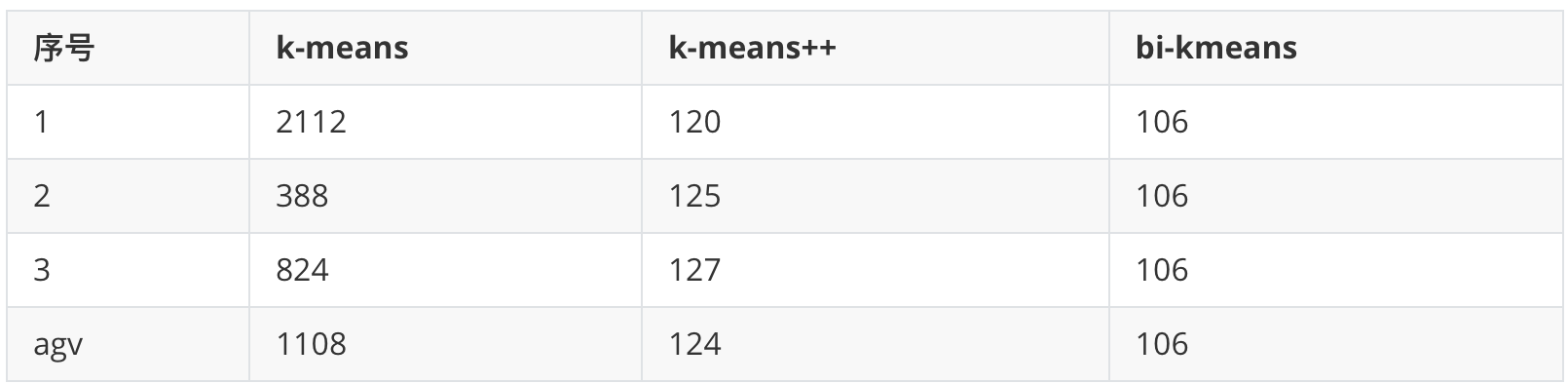
可以看到,k-means每次计算出来的SSE都较大且不太稳定,k-means++计算出来的SSE较稳定并且数值较小,而bi-kmeans 4次计算出来的SSE都一样,并且计算的SSE都较小,说明聚类的效果也最好。
2.2. 基于密度的方法
k-means算法对于凸性数据具有良好的效果,能够根据距离来讲数据分为球状类的簇,但对于非凸形状的数据点,就无能为力了,当k-means算法在环形数据的聚类时,我们看看会发生什么情况。

从上图可以看到,kmeans聚类产生了错误的结果,这个时候就需要用到基于密度的聚类方法了,该方法需要定义两个参数和M,分别表示密度的邻域半径和邻域密度阈值。
DBSCAN就是其中的典型。
2.2.1. DBSCAN算法
首先介绍几个概念,考虑集合,
表示定义密度的邻域半径,设聚类的邻域密度阈值为M,有以下定义:
邻域(
![]()
- 密度(desity)x的密度为
![]()
- 核心点(core-point)

- 边界点(border-point)

- 噪声点(noise-point)

该算法的流程如下:

构建邻域的过程可以使用
kd-tree进行优化,循环过程可以使用Numba、Cython、C进行优化,DBSCAN的源代码,使用该节一开始提到的数据集,聚类效果如下

聚类的过程示意图
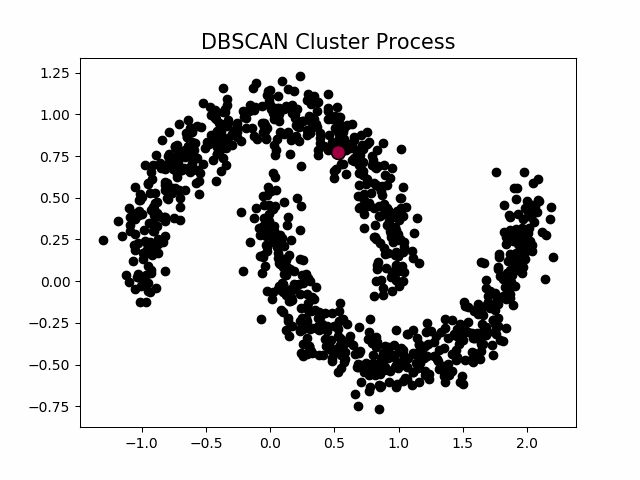
当设置不同的M时,会产生不同的结果,如下图所示

当设置不同的M时,会产生不同的结果,如下图所示

一般来说,DBSCAN算法有以下几个特点:
- 需要提前确定
- 不需要提前设置聚类的个数
- 对初值选取敏感,对噪声不敏感
- 对密度不均的数据聚合效果不好
2.2.2. OPTICS算法
在DBSCAN算法中,使用了统一的值,当数据密度不均匀的时候,如果设置了较小的值,则较稀疏的
cluster中的节点密度会小于,会被认为是边界点而不被用于进一步的扩展;如果设置了较大的值,则密度较大且离的比较近的
cluster容易被划分为同一个cluster,如下图所示。
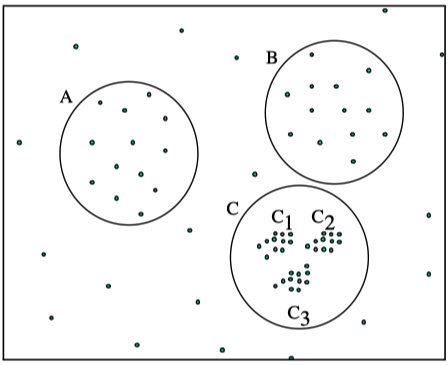
- 如果设置的
cluster - 如果设置的
cluster
对于密度不均的数据选取一个合适的是很困难的,对于高维数据,由于维度灾难(Curse of dimensionality),
的选取将变得更加困难。
怎样解决DBSCAN遗留下的问题呢?
The basic idea to overcome these problems is to run an algorithm which produces a special order of the database with respect to its density-based clustering structure containing the information about every clustering level of the data set (up to a "generating distance"
即能够提出一种算法,使得基于密度的聚类结构能够呈现出一种特殊的顺序,该顺序所对应的聚类结构包含了每个层级的聚类的信息,并且便于分析。
OPTICS(Ordering Points To Identify the Clustering Structure, OPTICS)实际上是DBSCAN算法的一种有效扩展,主要解决对输入参数敏感的问题。即选取有限个邻域参数进行聚类,这样就能得到不同邻域参数下的聚类结果。
在介绍OPTICS算法之前,再扩展几个概念。
- 核心距离(core-distance)

- 可达距离(reachability-distance)

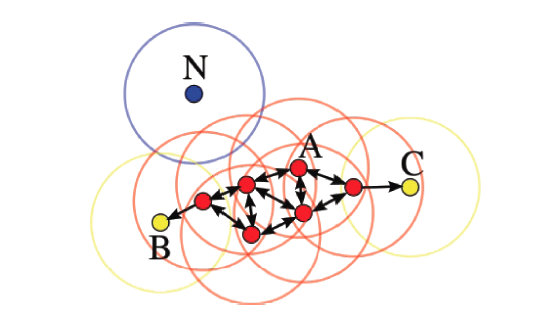
可达距离的意义在于衡量所在的密度,密度越大,他从相邻节点直接密度可达的距离越小,如果聚类时想要朝着数据尽量稠密的空间进行扩张,那么可达距离最小是最佳的选择。
举个例子,下图中假设M = 3,半径是。那么点的核心距离是d(1, P),点2的可达距离是d(1, P),点3的可达距离也是d(1, P),点4的可达距离则是d(4, P)的距离。

OPTICS源代码,算法流程如下:

算法中有一个很重要的insert_list()函数,这个函数如下:

OPTICS算法输出序列的过程:
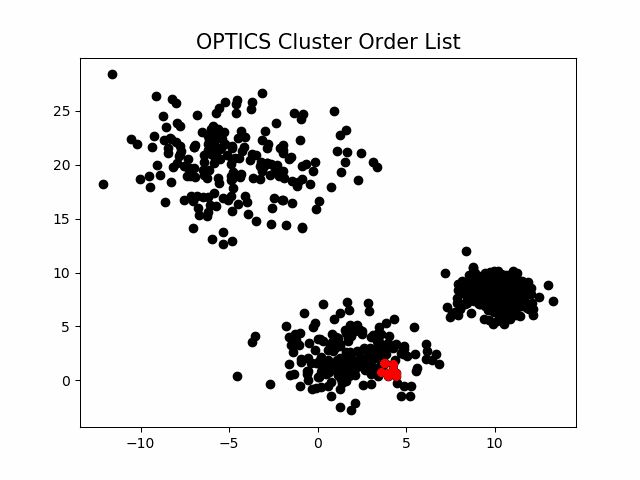
该算法最终获取知识是一个输出序列,该序列按照密度不同将相近密度的点聚合在一起,而不是输出该点所属的具体类别,如果要获取该点所属的类型,需要再设置一个参数
提取出具体的类别。这里我们举一个例子就知道是怎么回事了。
随机生成三组密度不均的数据,我们使用DBSCAN和OPTICS来看一下效果。


可见,OPTICS第一步生成的输出序列较好的保留了各个不同密度的簇的特征,根据输出序列的可达距离图,再设定一个合理的,便可以获得较好的聚类效果。
2.3. 层次化聚类方法
前面介绍的几种算法确实可以在较小的复杂度内获取较好的结果,但是这几种算法却存在一个链式效应的现象,比如:A与B相似,B与C相似,那么在聚类的时候便会将A、B、C聚合到一起,但是如果A与C不相似,就会造成聚类误差,严重的时候这个误差可以一直传递下去。为了降低链式效应,这时候层次聚类就该发挥作用了。
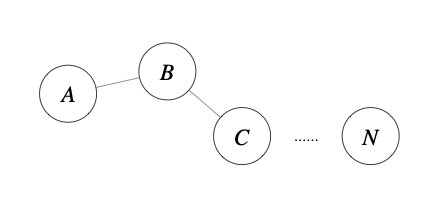
层次聚类算法 (hierarchical clustering) 将数据集划分为一层一层的 clusters,后面一层生成的 clusters 基于前面一层的结果。层次聚类算法一般分为两类:
- Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类,每一个对象最开始都是一个
cluster,每次按一定的准则将最相近的两个cluster合并生成一个新的cluster,如此往复,直至最终所有的对象都属于一个cluster。这里主要关注此类算法。 - Divisive 层次聚类: 又称自顶向下(top-down)的层次聚类,最开始所有的对象均属于一个
cluster,每次按一定的准则将某个cluster划分为多个cluster,如此往复,直至每个对象均是一个cluster。

另外,需指出的是,层次聚类算法是一种贪心算法(greedy algorithm),因其每一次合并或划分都是基于某种局部最优的选择。
2.3.1. Agglomerative算法
给定数据集,
Agglomerative层次聚类最简单的实现方法分为以下几步:

Agglomerative算法源代码,可以看到,该 算法的时间复杂度为(由于每次合并两个
cluster 时都要遍历大小为的距离矩阵来搜索最小距离,而这样的操作需要进行n-1次),空间复杂度为
(由于要存储距离矩阵)。

上图中分别使用了层次聚类中4个不同的cluster度量方法,可以看到,使用single-link确实会造成一定的链式效应,而使用complete-link则完全不会产生这种现象,使用average-link和ward-link则介于两者之间。
2.4. 新发展的方法
2.4.1. 基于约束的方法
真实世界中的聚类问题往往是具备多种约束条件的 , 然而由于在处理过程中不能准确表达相应的约束条件、不能很好地利用约束知识进行推理以及不能有效利用动态的约束条件 , 使得这一方法无法得到广泛的推广和应用。这里的约束可以是对个体对象的约束 , 也可以是对聚类参数的约束 , 它们均来自相关领域的经验知识。该方法的一个重要应用在于对存在障碍数据的二维空间数据进行聚类。 COD (Clustering with Ob2structed Distance) 就是处理这类问题的典型算法 , 其主要思想是用两点之间的障碍距离取代了一般的欧氏距离来计算其间的最小距离。
2.4.2. 基于模糊的聚类方法
基于模糊集理论的聚类方法,样本以一定的概率属于某个类。比较典型的有基于目标函数的模糊聚类方法、基于相似性关系和模糊关系的方法、基于模糊等价关系的传递闭包方法、基于模 糊图论的最小支撑树方法,以及基于数据集的凸分解、动态规划和难以辨别关系等方法。
FCM模糊聚类算法流程:
标准化数据矩阵;
建立模糊相似矩阵,初始化隶属矩阵;
算法开始迭代,直到目标函数收敛到极小值;
根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。
2.4.3. 基于粒度的聚类方法
基于粒度原理,研究还不完善。
2.4.4. 量子聚类
受物理学中量子机理和特性启发,可以用量子理论解决聚类记过依赖于初值和需要指定类别数的问题。一个很好的例子就是基于相关点的 Pott 自旋和统计机理提出的量子聚类模型。它把聚类问题看做一个物理系统。并且许多算例表明,对于传统聚类算法无能为力的几种聚类问题,该算法都得到了比较满意的结果。
2.4.5. 核聚类
核聚类方法增加了对样本特征的优化过程,利用 Mercer 核 把输入空间的样本映射到高维特征空间,并在特征空间中进行聚类。核聚类方法是普适的,并在性能上优于经典的聚类算法,它通过非线性映射能够较好地分辨、提 取并放大有用的特征,从而实现更为准确的聚类;同时,算法的收敛速度也较快。在经典聚类算法失效的情况下,核聚类算法仍能够得到正确的聚类。代表算法有SVDD算法,SVC算法。
2.4.6. 谱聚类
首先根据给定的样本数据集定义一个描述成对数据点相似度的亲合矩阵,并计算矩阵的特征值和特征向量,然后选择合适的特征向量聚类不同的数据点。谱聚类算法最初用于计算机视觉、VLSI设计等领域,最近才开始用于机器学习中,并迅速成为国际上机器学习领域的研究热点。
谱聚类算法建立在图论中的谱图理论基础上,其本质是将聚类问题转化为图的最优划分问题,是一种点对聚类算法。
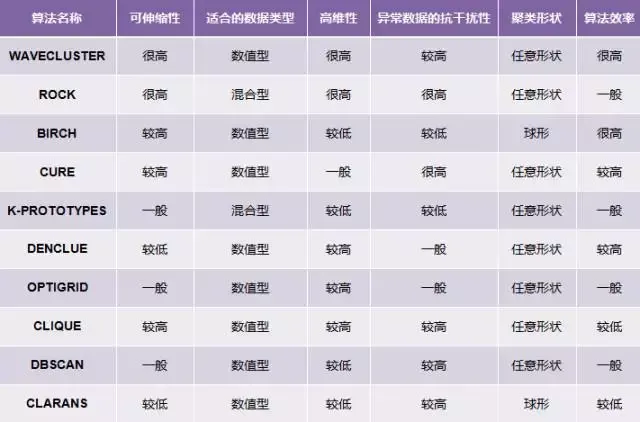
2.5. 聚类方法比较

参考文献
常用聚类算法 - 知乎
用于数据挖掘的聚类算法有哪些,各有何优势? - 知乎