引言:
北京时间:2023/2/17/8:17,目前听着超能陆战队主题曲《Immortals》,感觉又要螺旋式升天,并且为我今天上午没课感到happy,所以继我们很久以前的关于进程的博客,今天我们就再来学习一下有关进程状态这一方面的知识,让我们可以更好的理解硬件、操作系统和各种应用软件之间的关系和原理。

有关为什么学习Linux、Linux的指令,权限、各种工具使用、操作系统等知识各位可以适当的复习一下哦!这里我就不多加赘述了。进入主题:
从系统操作看进程
一个程序的执行过程
磁盘中存放着我们的可执行文件(后缀 .obj),此时我们电脑中有一个可执行文件存储在磁盘中,当我们双击运行此文件时,我们的操作系统识别到此操作,于是通过文件系统驱动找到此文件,然后把此文件就给加载到了内存之中,此时我们的可执行文件也就加载到了内存之中。当我们内存中的可执行文件被CPU调用,然后经过CPU的计算和控制之后,返回到内存并最终被我们的操作系统重新从内存中识别,然后运行到我们电脑的其它硬件或软件之上,此时我们才可以说我们形成了一个进程,此时也就可以在我们的显示屏上的任务资源管理器上看到该进程了。
认识内存对pcb(task_struct)的管理
通过上述的程序执行的过程,相信有的小伙伴就会有一个疑问?我们在从磁盘到内存的过程中,我的文件系统驱动器可以从磁盘中拿到指定的文件是因为我已经把该文件给包装好了并且自己找到点击了该文件,那当CPU从内存中获取该文件的时候,为什么不需要经过我的操作也可以准确、完整、快速的拿到该文件呢?并且当我在内存中存放了很多不同的可执行文件时,我的CPU是怎么区分这些数据,从而执行我想要执行的程序呢?
想要解决上述两个疑问,我们就需要引入,进程中的一个很重要的概念了,pcb(pcb也叫task_struct),顾名思义,就是一个结构体,一个任务结构体,该结构体用来干嘛的呢? 本质上,此时的task_struct就是用来存储文件相关的属性和内容的(并且此处强调,文件 = 内容 + 属性),这样我把我的每一个我想要执行的文件通过操作系统加载到内存之后,有强迫症并且能干的内存就把这些文件一个一个的放到了相应的task_struct中,加载一个文件,内存就生成一个task_struct,这样内存就可以通过task_struct结构体来把加载到内存中的数据按照按照task_struct结构体中存储的属性(地址或者名字)来对内存中各种各样的代码和数据进行一一对应管理,从而解决第一个问题,实现准确无误的给CPU提供数据。
具体管理方式: 内存管理task_struct结构体(并且此处强调,管理 = 先描述,再组织),此时因为我们已经用task_struct对文件的内容和属性描述好了,所以此时就只需要进行组织,我们的内存就完成了管理各种各样的文件的任务了,此时内存只要在每一个task_struct结构体中增加一个指针(也就是以单链表的形式),将这一个一个的task_struct结构体链接在一起,我们的内存就完成了管理工作,此时无论CPU想要获取那个数据,获取那个优先级高的数据,都可以说是很简单的就可以快速,完整的从内存中获取。当然这个获取的过程还是由我们的操作系统来完成的。
回顾进程
基本概念:程序的一个执行实例,正在执行的程序等 内核观点:担当分配系统资源的实体,浅薄理解系统资源就是CPU资源和内存资源,具体理解请看该链接:系统资源深入理解
回顾pcb
基本概念:当进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合(相应的pcb就对应着相应的进程的信息)
浅显错误理解进程:
进程就是将一个可执行文件通过操作系统加载到内存之中
正确理解进程:
进程是 内核数据结构 + 该进程对应的代码和数据
理解操作系统和进程pcb的关系
操作系统为了管理我们的进程,就必须从进程当中提取或者抽象出与进程相关的属性集合,构建出对应的数据结构对象,再加上从外设中加载到内存中的和该进程相匹配的代码和数据,所以操作系统对进程的管理并不是对内存中的对二进制文件做管理,而是抽象出进程的数据结构(就是pcb中的属性集合),当然此时pcb是可以通过属性集合找到对应的内存中的代码和数据,所以该进程创建的内核数据结构,压根就不关心代码和数据在哪里,只关心该进程的进程控制块,也就是pcb。
所以进程控制块就是: 所有加载到内存的进程,通过内存创建出来的这种特定的,用来描述进程的数据结构,结构体对象,就叫做该进程的进程控制块,简称pcb。
进程状态问题
为了深入理解什么是进程,此时我们就从进程的状态为切入点,详细的了解一下有关进程的知识,首先我们要明白一个进程是可以有好几个状态的(在Linux内核里,进程也叫做任务)
深入进程状态
什么是进程状态呢?首先从一个生活小问题出发,当电脑在使用一款软件的时候,例:CSDN,此时我们一直在CSDN上码字,那么此时的CSDN是否是一直属于运行状态呢?(此时的一直属于运行状态指的是一直处于CPU的调度状态)面对这个问题,答案肯定是否定的,因为在电脑中时刻存在着很多的进程,例如:操作系统本身的进程,此时如果需要让每一个进程都可以得到运行,CPU就需要对这些进程进行管理,例如:切换进程(一个进程被CPU处理了之后,又从CPU上拿下来,然后让CPU处理别的进程,然后该进程被重新进行管理(排队),之后轮到该进程时,该进程才会被再处理),但由于CPU的运算速度和我们的感知相差巨大,所以此时我们默认这些进程是同时被CPU执行的,所以默认进程是同时运行的,本质上却是进程一个一个的被切换交替执行。此时就可以由切换进程这个概念,引入我们之后要学习的进程状态的概念了,什么是进程切换呢?如何进行进程切换呢?让我们带着这些问题,首先来看一下什么是进程的状态。
搞定了上述的小知识,此时我们就再来看一下操作系统中,进程在被执行的时候,涉及了两个非常重要的概念吧!一个是阻塞,一个是挂起,没错就是高高挂起的挂起,但此挂起并非彼挂起哦!
阻塞:
当我们写了一个程序,生成了一个二进制可执行文件,该文件被加载到了内存,但在内存中时,该二进制文件自始至终都没有被CPU执行,此时该文件在干什么呢?或者说此时该进程在干什么呢?或者说此时该进程是属于什么状态呢?通过这个场景此时我们可以想象到另一个场景,就是当我们的电脑执行的程序过多的时候,此时如果想要执行一个二进制文件,当我们点击该文件的时候,就有可能会导致电脑卡住(程序不能立即执行),此时该场景就相当于是上述的那个场景,文件被加载到内存之后,不执行,所以此时该进程就是属于卡住了,卡住了也就相当于我们要理解的阻塞了。那么为什么会卡住呢?通过上述,我们知道,电脑中是有非常多的进程需要被执行的,并且进程的执行是需要资源的,此时的资源就好比我们上述所说进程的基本概念中的系统资源,因为一个电脑中的资源是有限的,所以此时进程卡住(阻塞)的本质就是:进程因为等待某种条件就绪,而导致的一种不推进的状态,也就是进程卡住了。
总:阻塞一定是因为在等待某种系统资源。浅显理解系统资源(CPU资源、内存资源、网络资源、外设资源等!)
那么什么叫做等待,什么叫做资源和等待资源呢?
其实这个概念是非常好理解的,大家在生活中肯定都有遇到过,此时我们就以一个生活中的场景来抽象这些问题,例:下图

一个银行排队的场景,当我们想要办理一张银行卡或者申请贷款之类的,第一件事情就是前往银行(抽象成文件被加载到内存之中),第二件事情就是排队等待柜台处理(抽象成在内存中等待CPU处理),第三件事情就是办理业务(抽象成进程被CPU处理),第四,此时因为你的业务属于比较复杂的业务,需要你有完整的手续才可以进行(抽象成一个程序想要被执行就要先拥有各种资源的使用权),第五 (重点),由于业务安全性比较高,需要你重新填保证单、个人信息之类的,但是此时该保证单和个人信息表没有了,需要等待银行工作人员去打印新的保证单和个人信息表,所以此时柜台就会让你先去别的地方进行等待,让下一个人先到柜台办理,等你把保证单和个人信息表填好了之后,你才可以再到柜台办理该业务(抽象成CPU此时没有相应的资源,需要你继续等待,等到你拥有了资源之后,才可以继续执行) ,所以当我们去别地方等待新的单子进行填写的时候(就是程序阻塞的时候),并且此时的状态就叫做阻塞状态。
结合上述的阻塞理解和下面的这个抽象银行理解,此时我们具体把程序等待资源的过程给搞明白了,但是我们还并不明白程序到底是如何进行等待? ,为了搞懂这个问题,就要涉及到操作系统是如何管理我们的软硬件的,我相信大家对这个概念是有一定的了解的,操作系统通过先描述再组织的方法对各种软件和硬件进行管理,具体方法:把无论是硬件还是软件,都给抽象成一个一个的结构体,然后结构体中存在指针变量,通过该指针变量,对无论是软件结构体还是硬件结构体,都以特殊的数据结构(链表、队列、栈)的形式,进行增删查改。 所以进程是什么呢?操作系统需不需要对其进行管理呢?如果要管理,应该怎么管理呢?显然这些问题对于现在的我们来说,答案是呼之欲出的,当然要管理,并且操作系统还是使用和以前一样的办法,先描述,再组织 ,通过该办法对进程进行合理的管理,当然这也就是我们上述文章开头复习的内容,有关pcb(task_struct) 的内容,操作系统就是通过pcb结构体对进程进行管理(增删查改),所以有了这块的知识,我们就可以解决程序是如何进行等待的问题了,操作系统将需要等待资源的进程,以pcb结构体的方式,链接到特定的数据结构中,此时该数据结构中的结构体再被操作系统一个一个的调用,此时操作系统调用数据结构中的pcb结构体的顺序,就是进程等待的过程。
强调:描述就是:结构体中(成员变量的类型),组织就是:数据结构(链表、队列、栈、等!)
总:进程等待某种资源,本质就是把该进程的pcb结构体,给链接到某个与外设有关的资源的数据结构(队列)中去排队,此时CPU就不会调用它,在我们看来该进程就是卡住了,所以阻塞就是不被调度,并且一定是因为当前进程需要等待某种资源就绪,导致进程pcb结构体需要在某种操作系统管理的资源下排队(一般是外设资源下),所以pcb是可以被维护在不同的数据结构(队列)中的,使进程可以被快速的完成,用户得到稳定、快速的体验。
挂起:
当我们理解了什么是阻塞,现在开始学习挂起就会变得更加的轻松了,什么是挂起?为什么会出现挂起的概念?让我们从问题出发,来寻找答案,首先第一步还是回到阻塞中的问题,当一个程序被阻塞的时候,此时就导致该进程的pcb结构体被链接到对应的资源数据结构(队列)之中,在该数据结构(队列)之中排队,等待相应的资源;假设一个场景:当电脑中有非常多的程序需要运行时,把非常多的代码和数据加载到内存中,由于资源有限,只有少数的程序可以被CPU处理,大部分程序的pcb需要等待,此时就会导致内存中不仅存储了大量的pcb结构体,还存储了大量的该pcb结构体对应的代码和数据,按原理来说,pcb结构体所占的内存空间应该是不大的,因为其只是包含文件代码和数据的各种属性而已,但是如果代码和数据存储在了内存之中,那么此时内存就会严重不足,此时就会导致很多的程序直接崩溃,所以当我们的操作系统识别到这种不工作,并且还占用大量的内存的程序,就会把该程序的代码和数据给放到磁盘中存储,而不是在内存中,这样就可以很好的减轻内存的存储压力,只有当对应的pcb结构体要被CPU调度的时候,才会把该pcb对应的代码和数据给重新加载到内存之中,所以这种把进程的代码和数据暂时性的由操作系统从内存交换到磁盘的行为,我们就称之为是该进程的挂起状态。 简而言之就是,进程的pcb结构体没有和该进程的代码和数据同时处于内存中,该进程就处于挂起状态。
全称:阻塞挂起状态。
通过文字描述之后,此时我们可以很好的理解进程中的阻塞和挂起状态,但是一个进程的运行并不只有这两个状态,如下图为一个进程的具体状态的转换图:
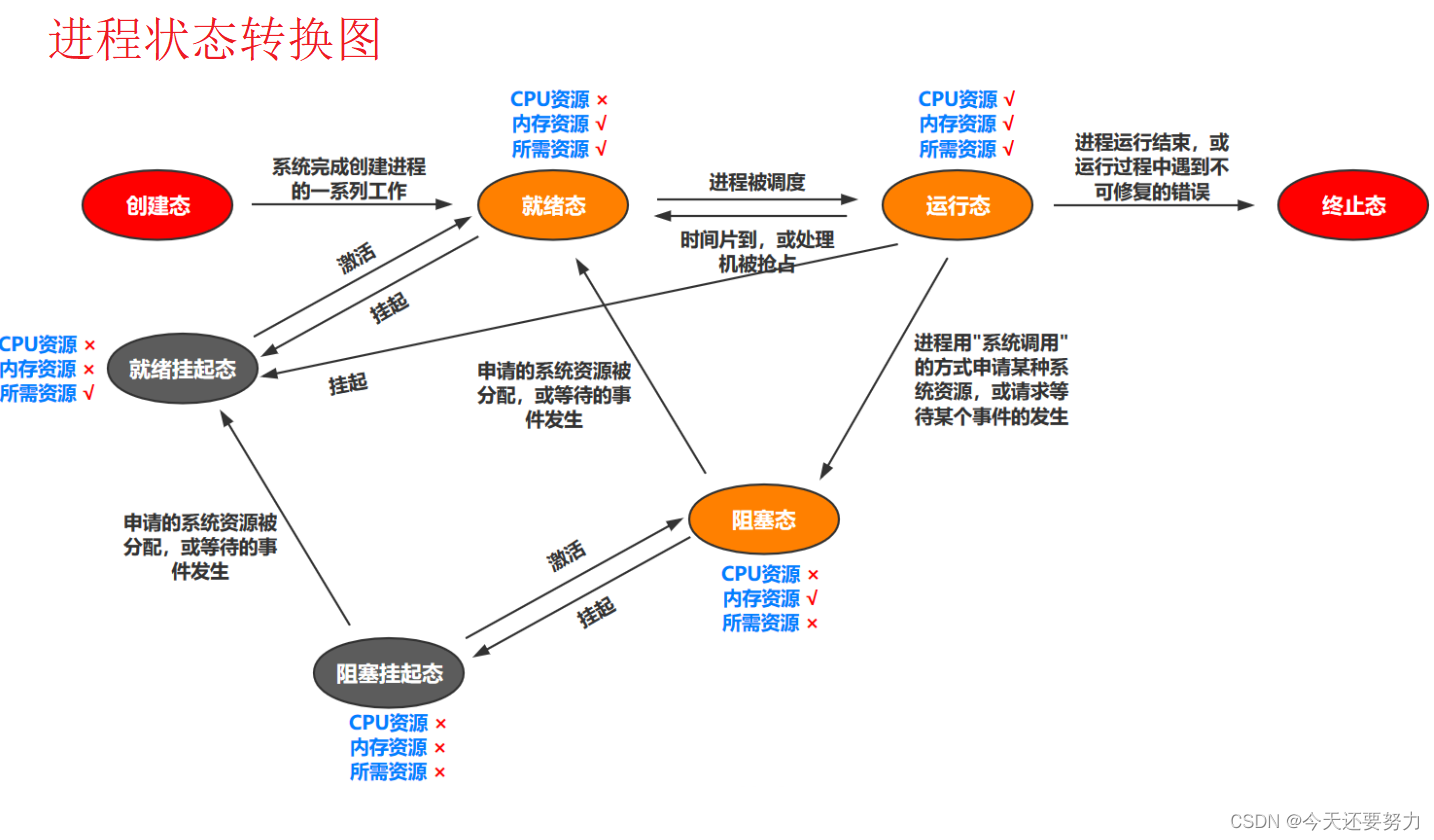
此时让我们通过这个图,通过上述的阻塞和挂起状态与图中其它状态之间的联系,让我们去了解一下别的进程状态和各个进程状态之间的切换关系。
进程的状态:
| 一个进程在执行的过程中,是有很多的状态的 |
|---|
| R - 运行状态 (并不意味着进程就是在执行,它表明该进程要么是在运行中,要么是在运行队列里) |
| S - 睡眠状态(意味着进程在等待事件的完成)(有时候,此时的睡眠也叫可中断睡眠) |
| D - 磁盘休眠状态(有时候也叫不可中断睡眠状态,在这个状态的进程通常会等待IO的结束) |
| T - 停止状态(可以通过发送停止信号给进程来停止进程),这个被暂停的进程可以通过发送开始信号让进程继续运行 |
| X-死亡状态 :这个状态只是一个返回状态,你不会在任务列表里看到这个状态 |
| Z-僵死状态:进程已经退出,但资源没有完全被释放时处于的一种状态(等待后续被处理的一种状态) |
了解了剩下的基本进程状态,此时我们就开始一一谈谈这些状态,首先是运行状态和睡眠状态(R、S), 如下图我们写了一个代码,并且让它运行起来,此时就可以通过Linux操作系统具体的看一下,这个代码此时运行起来之后,对应的进程是属于什么状态,如下图:
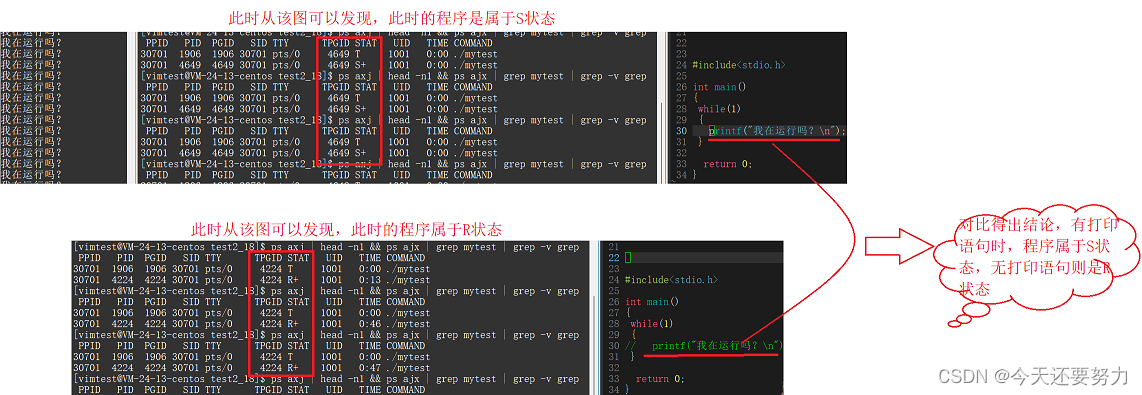
可以发现,当我们有打印语句的时候,我们的进程就算运行起来,此时也不是运行状态(R),而是睡眠状态(S),并且当我们把打印语句给注释掉的时候,此时的进程运行起来之后,就是运行状态(R)了,这是为什么呢?原因 :当我们在第一个代码中输入打印语句的时候,此时表示我需要打印出我想要的语句,此时就会导致该代码生成的进程具有打印属性,此时该进程就需要有打印语句的资源(也就是外设中的显示器),所以当CPU对该进程进行执行的时候,该进程就需要有外设这个资源,如果没有,按照原理,此时该进程就会被操作系统给链接到有关外设的数据结构(队列)中去排队,并且又因为此时的这个程序的代码是一个死循环的代码,此时就需要频繁的打印,导致每次CPU执行该进程,该进程都需要去频繁的访问外设,频繁访问外设,就会导致外设资源不足,所以此时就会导致该进程直接就不是在CPU的队列中排队,而是在外设的队列中排队,然后等待外设就绪之后,再回到CPU运行队列中,然后此时我们根据运行状态(R) :进程只有在运行中,或者是在运行队列中才算是运行状态;此时就可以很好的理解,为什么上述的代码不在运行状态,而在睡眠了,因为频繁访问外设,导致外设资源不足,进程需要在外设队列中排队,不在运行队列,导致不是运行状态。 当然,这也就是为什么把打印语句去掉之后,该进程的状态就从睡眠状态变成了运行状态。
总:只要进程不是在运行中或者CPU运行队列中而是在等待某种资源的运行队列中,此时该进程就不叫运行状态。
本质:CPU运行速度太快,而程序中打印代码访问外设的速度跟不上CPU的速度,导致被频繁的从CPU运行队列切换到外设的运行队列。(当然队列都是由操作系统维护的,切换工作自然也是由操作系统来完成)
不可中断睡眠状态(D)
通过上述的例子,我们把运行状态和睡眠状态(可中断)差不多搞清楚了,这边再学习一下不可中断的睡眠状态(D),此时我们通过一个场景来理解不可中断睡眠状态的理解,首先明白一点,当我们的操作系统当中,有非常多的进程时,并且有的进程处于不工作状态的时候,操作系统具有删除进程的功能,并且由于进程长时间不工作,操作系统会将该进程存放在内存中的代码和数据给转换到磁盘当中,在该情况之下,磁盘中的代码和数据对应的进程被删除之后,会导致一个很严重的问题,就是这些代码和数据无法被找到,操作系统是不允许这样干的,所以研发操作系统的人就设计出了一个叫不可中断睡眠状态,只要此时的进程属于该状态,那么它就不允许被操作系统删除,这样相应的在磁盘中的数据就不会丢失,任然可以被CPU执行。并且处于该状态的进程只有两种方法可以删除,一是等待其自己醒来,二是关机重启。所以D状态,不可中断状态,是一个非常不好的进程状态,只要电脑中有该状态的进程,那么电脑就快要崩了。
停止状态(T)
如下图:
 我们可以发现,进程的状态处于停止状态(T)的时候,在T的后面并没有加号(+),只有当进程属于睡眠状态(S)时,它的后面才会有一个加号,那么这个加号是什么意思呢?此时要理解这个加号(+),我们就需要引入一个新的概念,叫前台和后台,所以此时进程状态中有带加号的就表示在前台运行,不带加号的就表示在后台运行,在前台运行的程序可以使用Ctrl+C或者
我们可以发现,进程的状态处于停止状态(T)的时候,在T的后面并没有加号(+),只有当进程属于睡眠状态(S)时,它的后面才会有一个加号,那么这个加号是什么意思呢?此时要理解这个加号(+),我们就需要引入一个新的概念,叫前台和后台,所以此时进程状态中有带加号的就表示在前台运行,不带加号的就表示在后台运行,在前台运行的程序可以使用Ctrl+C或者kill -9+pid进行终止,在后台运行的程序却只可以使用kill -9+pid进行终止,所以我们的停止状态(T)都是在后台运行的。
总:除了运行状态,无论是可中断睡眠状态、不可中断睡眠状态还是停止状态,本质上都是阻塞状态
僵尸状态(Z)
基础概念:僵尸进程是非常特殊的一种,它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集(如供父进程),除此之外,僵尸进程不再占有任何内存空间。
理解僵尸进程:我们还是从问题出发,我们为什么要创建进程呢?原因是因为我们要执行代码,我们为什么要执行代码?原因是因为我们需要代码为我完成某个工作,所以总的来说,创建进程就是需要它来帮我办事。此时假如我们很关心这个代码的结果,那么此时我们就需要去了解进程的结果,例:我们代码中的main函数,此时都会和return配套使用,此时的return函数就是一个进程的退出码的意思,并且在Linux中查看进程的退出码指令(echo $?),所以使用该指令就是获得进程退出码一个方法;但此时还有另一个方法,就是僵尸进程的概念,当Linux退出的时候,一般不会立即彻底退出,而是维持一个叫僵尸状态(Z)的状态,这样可以方便后续父进程或者操作系统去读取该子进程退出的退出结果,通过僵尸进程的概念,此时我就有了另一种获得退出结果的方法了。
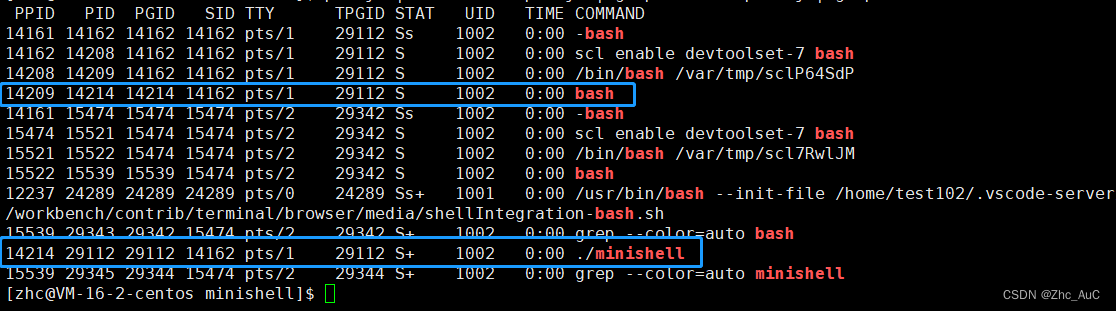
如下图:从代码角度理解僵尸进程

可以发现此时我们的子进程和父进程都是处于睡眠状态(S),所以按照上述的原理,此时我们使用(kill -9)把子进程杀掉,那么此时的该进程并不是处于死亡状态(X),而是处于僵尸状态(Z),如下图所示:

所以此时的子进程就从睡眠状态(S)变成了僵尸状态(Z),所以根据僵尸进程的概念,我们可以知道,该进程此时是处于死亡状态,但是并没有被清理,资源没有被释放完(内存),所以如果这些资源没有被释放,又会有什么问题呢?就会导致内存泄露问题,就可能导致程序崩溃。
总:所以为什么要有僵尸状态呢?就是为了可以让别人去甄别该进程退出的原因和结果。所以维持僵尸进程就是为了可以让父进程或者操作系统读取到退出结果和相关信息。