1.鼠标定位操作
鼠标悬停,即当光标与其名称表示的元素重叠时触发的事件,在 Selenium 中将键盘鼠标操
作封装在 Action Chains 类中。Action Chains 类的主要应用场景为单击鼠标、双击鼠标、鼠标拖
曳等。部分常用的方法使用分类如下:
• click(on_element=None),模拟鼠标单击操作。
• click_and_hold(on_element=None),模拟鼠标单击并且按住不放。
• double_click(on_element=None),模拟鼠标双击。
• context_click(on_element=None),模拟鼠标右击操作。
• drag_and_drop(source,target),模拟鼠标拖曳。
• drag_and_drop(source,xoffset,yoffset),模拟将目标拖曳到目标位置。
• key_down(value,element=None),模拟按住某个键,实现快捷键操作。
• key_up(value,element=None),模拟松开某个键,一般和 key_down 操作一起使用。
• move_to_element(to_element),模拟将鼠标移到指定的某个页面元素。
• move_to_element_with_offset(to_element,xoffset,yoffset),移动鼠标至指定的坐标。
• perform(),将之前一系列的 ActionChains 执行。
• release(on_element=None),释放按下的鼠标。
接下来,列举鼠标右击操作和鼠标双击操作两个实例。
(1)鼠标右击操作,实现右击/双击百度首页“新闻”超链接。代码如下:
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/2/16
form:《Selenium 3+Python 3自动化测试项目实战》
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 定位超链接‘新闻’
element = driver.find_element(By.LINK_TEXT, '新闻')
# 实现在新闻超链接上右击
ActionChains(driver).context_click(element).perform()
# 实现用鼠标实现双击‘新闻’
ActionChains(driver).double_click(element).perform()(2)以百度首页设置为例,使用“move_to_element”的方法,鼠标即可悬停于元素设置:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过id定位超链接‘设置’
setting = driver.find_element(By.ID, 's-usersetting-top')
# 使用方法 move_to_element 模拟将鼠标悬停在超链接“设置”处
ActionChains(driver).move_to_element(setting).perform()
# 定位超链接‘高级设置’,并实现单击操作
driver.find_element(By.CLASS_NAME, 'set').click()实现效果如下:

2.Select 操作
Web 页面中经常会遇到下拉框选项,Select 模块提供了对标准 Select 下拉框的多种操作方
法。打开百度,单击“设置→高级设置”,会出现一个 Select 下拉框,如下图所示:
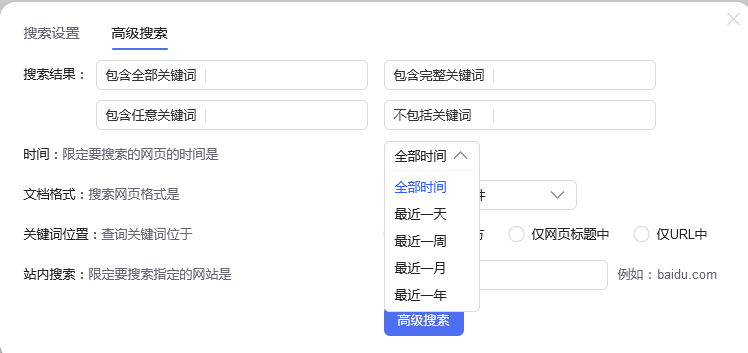
Select 元素的 HTML 代码如下图所示。
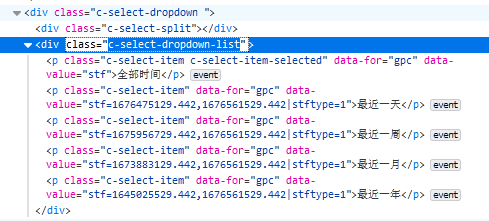
接下来介绍 3 种选择 Select 元素的值的方法。
Select 类:用于定位<select>标签。
select_by_value():通过 value 值定位下拉选项。
select_by_visible_text():通过 text 值定位下拉选项。
select_by_index():根据下拉选项的索引进行选择。第一个选项为 0,第二个选项为 1。
通过 WebDriver 代码操作下拉框,代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from selenium.webdriver.support.select import Select
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 定位超链接‘设置’
setting = driver.find_element(By.ID, 's-usersetting-top')
# 使用方法 move_to_element 模拟将鼠标悬停在超链接“设置”处
ActionChains(driver).move_to_element(setting).perform()
# 通过xpath定位超链接‘高级’,并实现单击操作
driver.find_element(By.XPATH, "//div/a[@target='_blank']/span").click()
# 通过class定位选择‘全部时间’
search_time = driver.find_element(By.CLASS_NAME, 'c-select-selection')
# 通过 value 值定位下拉选项
Select(search_time).select_by_value('stf=1676475129.442,1676561529.442|stftype=1')
# 通过 text 值定位下拉选项
Select(search_time).select_by_visible_text('最近一周')3.键盘操作
前面介绍过,send_keys()方法可以用来模拟键盘输入,我们还可以用它来输入键盘上
的按键,甚至是组合键,如 Ctrl+a、Ctrl+c 等。
经过总结,以下为自动化测试中常用的键盘事件。
• Keys.BACK_SPACE:删除键。
• Keys.SPACE:空格键。
• Keys.TAB:Tab 键。
• Keys.ESCAPE:回退键。
• Keys.ENTER:回车键。
• Keys.CONTROL,”a”:组合键 Ctrl + A。
• Keys.CONTROL,”x”:组合键 Ctrl + X。
• Keys.CONTROL,”v”:组合键 Ctrl + V。
• Keys.CONTROL,”c”:组合键 Ctrl + C。
• Keys.F1:F1 键。
• Keys.F12:F12 键。
用法举例,如下方代码展示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 在输入框输入内容
driver.find_element(By.ID, "kw").send_keys("selenium")
# 删除多输入的一个 m
driver.find_element(By.ID, "kw").send_keys(Keys.BACK_SPACE)
sleep(1)
# 输入空格键+“教程”
driver.find_element(By.ID, "kw").send_keys(Keys.SPACE)
driver.find_element(By.ID, "kw").send_keys("教程")
sleep(1)
# 输入组合键 Ctrl+a,全选输入框内容
driver.find_element(By.ID, "kw").send_keys(Keys.CONTROL, 'a')
sleep(1)
# 输入组合键 Ctrl+x,剪切输入框内容
driver.find_element(By.ID, "kw").send_keys(Keys.CONTROL, 'x')
sleep(1)
# 输入组合键 Ctrl+v,粘贴内容到输入框
driver.find_element(By.ID, "kw").send_keys(Keys.CONTROL, 'v')
sleep(1)
# 用回车键代替单击操作
driver.find_element(By.ID, "su").send_keys(Keys.ENTER)4.利用 JavaScript 操作页面元素
WebDiver 对部分浏览器上控件并不是直接支持的,如浏览器右侧滚动条、副文本等,而是
通常借助 JavaScript 间接操作。WebDriver 提供了 execute_script()和 execute_async_scrip()两种方
法来执行 JavaScript 代码,其区别如下:
(1)execute_script 为同步执行且执行时间较短。WebDriver 会等待同步执行的结果,
然后执行后续代码。
(2)execute_async_script 为异步执行且执行时间较长。WebDriver 不会等待异步执行
代码的结果,而是直接执行后续的代码。
用于调整浏览器滚动条位置的 JavaScript 代码如下。
<!-- window.scrollTo(左边距,上边距); -->
window.scrollTo(0,450);window.scrollTo()方法用于设置浏览器窗口滚动条的水平位置和垂直位置。第一个参数
表示水平的左边距,第二个参数表示垂直的上边距,代码如下。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 设置浏览器窗口大小
driver.set_window_size(800, 700)
driver.find_element(By.ID, "kw").send_keys("selenium")
driver.find_element(By.ID, "su").click()
sleep(3)
# 通过 JavaScript 设置浏览器窗口的滚动条位置
js = "window.scrollTo(100,300)"
driver.execute_script(js)执行结果如下图所示:
5.获得验证信息
在进行 Web 自动化测试中,用得最多的几种验证信息是 title、current_url 和 text。
title:用于获取当前页面的标题。
current_url:用于获取当前页面的 URL。
text:用于获取当前页面的文本信息。
下面仍以百度搜索为例,对比搜索前后的信息。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Firefox()
driver.get('https://www.baidu.com/')
print('Before search================')
# 打印当前页面 title
title = driver.title
print("title:" + title)
# 打印当前页面 URL
now_url = driver.current_url
print("URL:" + now_url)
driver.find_element(By.ID, "kw").send_keys("selenium")
driver.find_element(By.ID, "su").click()
sleep(3)
print('After search================')
# 再次打印当前页面 title
title = driver.title
print("title:" + title)
# 再次打印当前页面 URL
now_url = driver.current_url
print("URL:" + now_url)
# 获取搜索结果条数
num = driver.find_element(By.XPATH, "//span[@class='hint_PIwZX c_font_2AD7M']").text
print("result:"+num)运行结果如下:

通过上面的打印信息可以看出搜索前后的差异,这些差异信息可以拿来作为自动化测试的断言点。
6.设置元素等待
WebDriver 提供了两种类型的元素等待:显式等待和隐式等待。
(1)显示等待
显式等待是 WebDriver 等待某个条件成立则继续执行,否则在达到最大时长时抛出超
时异常(TimeoutException)。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("https://www.baidu.com")
element = WebDriverWait(driver, 5, 0.5).until(
EC.visibility_of_element_located((By.ID, "kw"))
)
element.send_keys('selenium')WebDriverWait 类是 WebDriver 提供的等待方法。在设置时间内,默认每隔一段时间检
测一次当前页面元素是否存在,如果超过设置时间仍检测不到,则抛出异常。
具体格式如下。
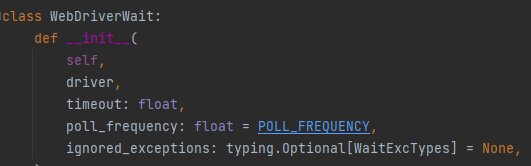
driver:浏览器驱动。
timeout:最长超时时间,默认以秒为单位。
poll_frequency:检测的间隔(步长)时间,默认为 0.5s。
ignored_exceptions:超时后的异常信息,默认情况下抛出 NoSuchElementException异常。
WebDriverWait()一般与 until()或 until_not()方法配合使用,下面是 until()和 until_not()
方法的说明:
until(method, message=″)调用该方法提供的驱动程序作为一个参数,直到返回值为 True。
until_not(method, message=″)调用该方法提供的驱动程序作为一个参数,直到返回值为 False。
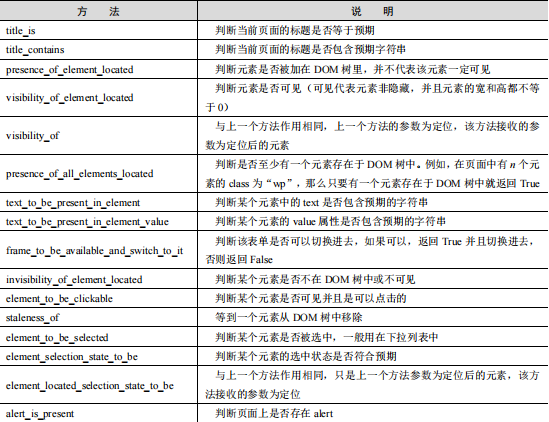
在本例中,通过 as 关键字将 expected_conditions 重命名为 EC,并调用 presence_of_element_located()方法判断元素是否存在。
expected_conditions 类提供的预期条件判断方法如下图所示。
除 expected_conditions 类提供的丰富的预期条件判断方法外,还可以利用is_displayed()方法自己实现元素显示等待。
from time import sleep, ctime
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("https://www.baidu.com")
print(ctime())
for i in range(10):
try:
el = driver.find_element(By.ID, "kw22")
if el.is_displayed():
break
except:
pass
sleep(1)
else:
print("time out")
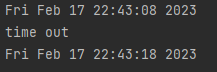
print(ctime())相对来说,这种方式更容易理解。首先 for 循环 10 次,然后通过 is_displayed()方法循环判断元素是否可见。如果为 True,则说明元素可见,执行 break 跳出循环;
否则执行 sleep()休眠 1s 后继续循环判断。10 次循环结束后,如果没有执行 break,则执行 for 循环对应的else 语句,打印“time out”信息。
这里故意将 id 定位设置为“kw22”,定位失败,执行结果如下:
(2)隐式等待
WebDriver 提供的 implicitly_wait()方法可用来实现隐式等待,用法相对来说要简单得
多。
from time import ctime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
driver = webdriver.Firefox()
# 设置隐式等待为 10s
driver.implicitly_wait(10)
driver.get("https://www.baidu.com")
try:
print(ctime())
driver.find_element(By.ID, "kw22").send_keys('selenium')
except NoSuchElementException as e:
print(e)
finally:
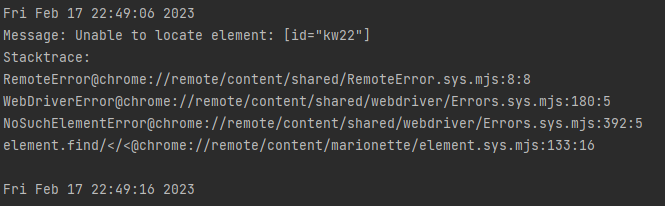
print(ctime())implicitly_wait()的参数是时间,单位为秒,本例中设置的等待时间为 10s。
首先,这10s 并非一个固定的等待时间,它并不影响脚本的执行速度。其次,它会等待页面上的所有
元素。当脚本执行到某个元素定位时,如果元素存在,则继续执行;如果定位不到元素,
则它将以轮询的方式不断地判断元素是否存在。假设在第 6s 定位到了元素,则继续执行,
若直到超出设置时间(10s)还没有定位到元素,则抛出异常。
这里同样故意将 id 定位设置为“kw22”,定位失败,执行结果如下:
7.警告框处理
在 WebDriver 中处理 JavaScript 生成的 alert、confirm 和 prompt 十分简单,具体做法是,
首先使用 switch_to.alert()方法定位,然后使用 text、accept、dismiss、send_keys 等进行操
作。
text:返回 alert、confirm、prompt 中的文字信息。
accept():接受现有警告框。
dismiss():解散现有警告框。
send_keys():在警告框中输入文本(如果可以输入的话)。
这里以百度搜索设置为例,打开百度搜索设置,设置完成后单击“保存设置”按钮,可以使用 switch_to.alert()方法为百度搜索设置弹窗,如下图所示:
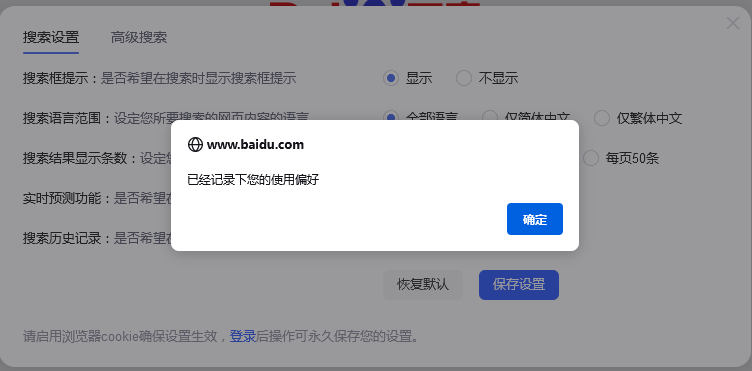
代码如下:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
driver = webdriver.Firefox()
driver.get('https://www.baidu.com/')
# 定位超链接‘设置’
setting = driver.find_element(By.ID, 's-usersetting-top')
# 使用方法 move_to_element 模拟将鼠标悬停在超链接“设置”处
ActionChains(driver).move_to_element(setting).perform()
# 通过class定位超链接‘搜索设置’,并实现单击操作
driver.find_element(By.CLASS_NAME, "set").click()
# 通过xpath获取保存设置
driver.find_element(By.XPATH, "//a[@class='prefpanelgo setting-btn c-btn c-btn-primary']").click()
sleep(3)
# 获取警告框
alert = driver.switch_to.alert
# 获取警告框提示信息
alert_text = alert.text
print(alert_text)
# 接取警告框
alert.accept()8.获取Cookie
有时我们需要验证浏览器中的 Cookie 是否正确,因为基于真实的 Cookie 是无法通过
白盒测试和集成测试的。WebDriver 提供了操作 Cookie 的相关方法,可以读取、添加和删
除 Cookie。
WebDriver 操作 Cookie 的方法如下:
get_cookies():获得所有 Cookie。
get_cookie(name):返回字典中 key 为“name”的 Cookie。
add_cookie(cookie_dict):添加 Cookie。
delete_cookie(name,optionsString):删除名为 OpenString 的 Cookie。
delete_all_cookies():删除所有 Cookie。
下面通过 get_cookies()获取当前浏览器的所有 Cookie。代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('https://www.baidu.com/')
# 获得所有 Cookie 信息并打印
cookie = driver.get_cookies()
print(cookie)执行结果如下:

从执行结果可以看出,Cookie 中的数据是以字典形式存放的。知道了 Cookie 中数据的
存放形式后,即可按照这种形式向浏览器中添加 Cookie。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('https://www.baidu.com/')
# 添加 Cookie 信息
driver.add_cookie({'name': 'foo', 'value': 'bar'})
# 遍历指定的 Cookies
for cookie in driver.get_cookies():
print("%s -> %s" % (cookie['name'], cookie['value']))执行结果如下:
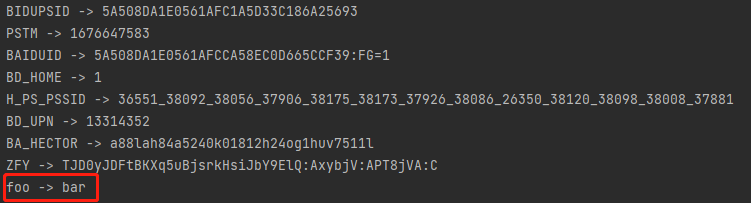
从执行结果可以看出,最后一条 Cookie 是在脚本执行过程中通过 add_cookie()方法添
加的。通过遍历得到所有的 Cookie,从而找到字典中 key 为“name”和“value”的 Cookie
值。
delete_cookie() 和 delete_all_cookies() 方法的使用也很简单,前者通过 name 删除一个
指定的 Cookie,后者直接删除浏览器中的所有 Cookies。
9.窗口截图
自动化测试用例是由程序执行的,因此有时候打印的错误信息不够直观。如果在脚本
执行出错时能够对当前窗口进行截图并保存,那么通过截图就可以非常直观地看到脚本出
错的原因。WebDriver 提供了截图函数 save_screenshot (),可用来截取当前窗口。
from time import sleep
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('https://www.baidu.com/')
sleep(3)
# 截取当前窗口,指定截图图片的保存位置
driver.save_screenshot("D:/baidu_img.png")WebDriver 建议使用 png 作为图片的后缀名。脚本运行完成后,会在D盘根目录下生成 baidu_img.png 图片
这样我们就学习完大部分Selenium 的特殊元素操作方法了,读者可以掌握 Selenium 的常用方法,包括熟悉每种方法使用的场景或者前提条件。