文章目录
- 项目列表
- 前言
- U-net
- 模型概况
- 下采样过程
- 上采样过程
- 模型代码
- 上采样代码
- U-net模型构建
- deeplabv3+
- 模型概况
- 模型代码
- resNet
- ASPP
- deeplabv3+模型构建
- 结尾
项目列表
语义分割项目(一)——数据概况及预处理
语义分割项目(二)——标签转换与数据加载
语义分割项目(三)——语义分割模型(U-net和deeplavb3+)
前言
在前两篇中我们完成了针对数据的处理和加载,本篇文章中我们将介绍两个常见的语义分割模型U-Net和deeplabv3+来完成航拍语义分割项目
U-net
模型概况
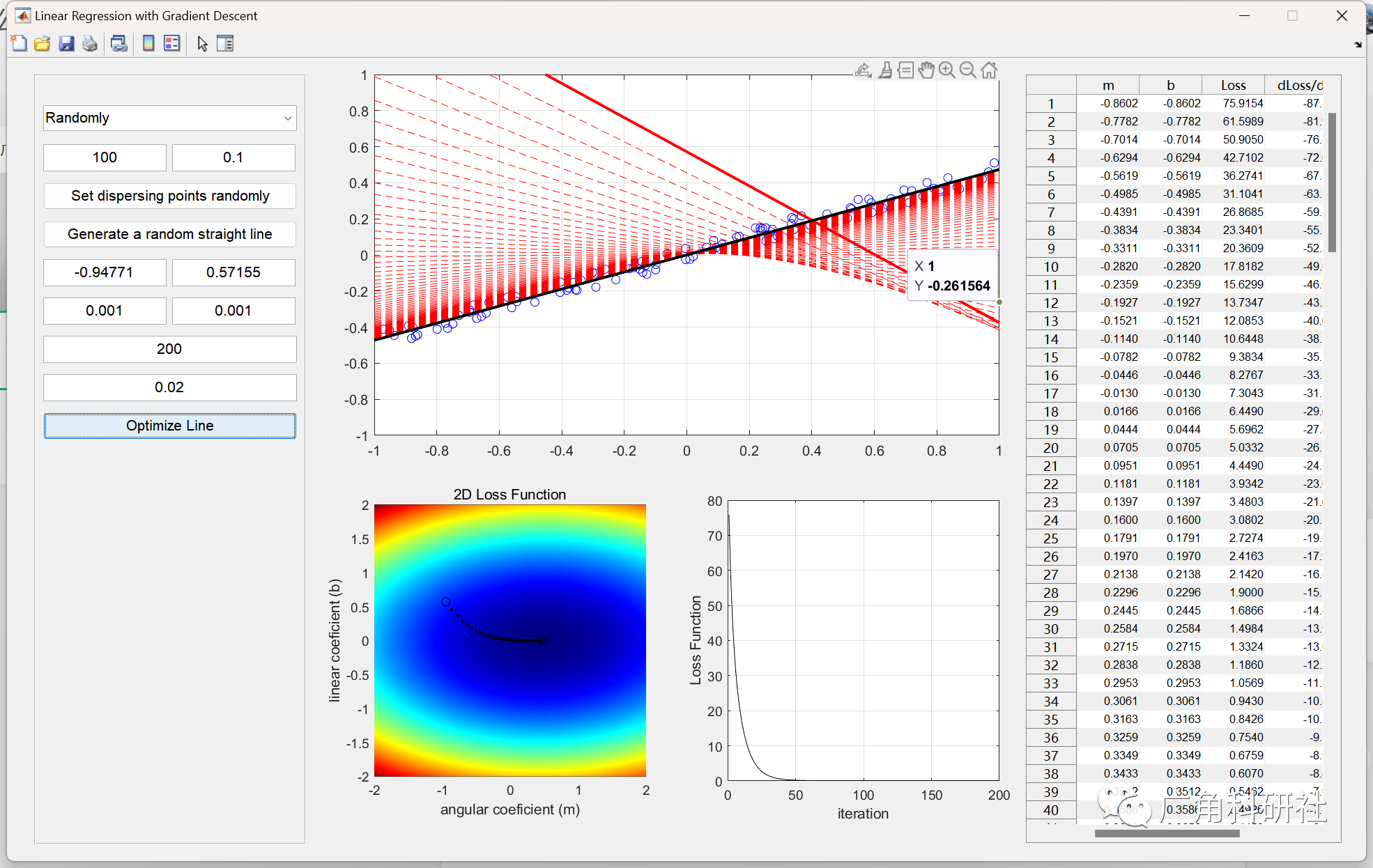
首先来看U-net的模型结构
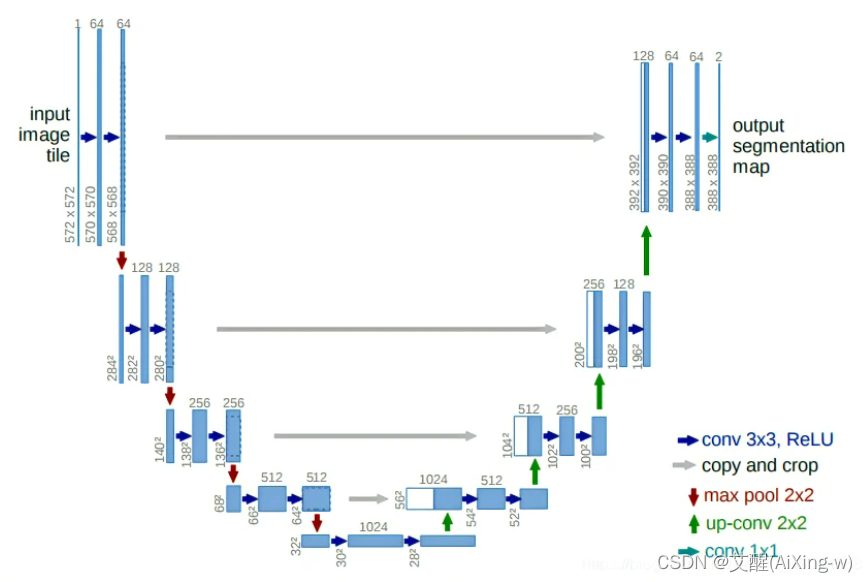
下采样过程
模型首先是进行多次下采样,每次下采样后的结果保留一份以供后边合并
上采样过程
进行多次下采样后,对最后一层下采样的结果进行上采样并与上一层下采样的结果通道合并,再对通道合并后的结果进行通道调整,再次进行上采样和合并操作直到图像宽高与原图像宽高相同为止,最后再把通道数调整到与分类的类别数相同即可
模型代码
在本文中我们使用vgg16来作为backbone,vgg16前向传递的过程就是下采样的过程,正好vgg16和图中相符,也是进行了5次下采样,所以我们只需对下采样过程进行编写即可。
上采样代码
向上采用的过程我们采用的是转置卷积(有些地方也翻译为反卷积),输入值是待上采样的值(设为A)和他上一层下采样得到的值(设为B),操作过程就是先对A进行上采样,然后进行线性插值使得A的高宽变为和B高宽相同,然后合并他们的通道,随后进行两次卷积操作并传入激活函数获得上采样的结果
class up_sample(nn.Module):
def __init__(self, channel1, channel2):
super(up_sample, self).__init__()
self.up = nn.ConvTranspose2d(channel1, channel1, kernel_size=2, stride=2, bias=False)
self.conv1 = nn.Conv2d(channel1 + channel2, channel2, kernel_size = 3, padding = 1)
self.conv2 = nn.Conv2d(channel2, channel2, kernel_size = 3, padding = 1)
self.relu = nn.ReLU(inplace = True)
def forward(self, input1, input2):
if input1.shape[-2:] != input2.shape[-2:]:
input1 = self.up(input1)
image_size = input2.shape[-2:]
input1 = F.interpolate(input1, image_size)
outputs = torch.cat([input1, input2], dim=1)
outputs = self.conv1(outputs)
outputs = self.conv2(outputs)
outputs = self.relu(outputs)
return outputs
U-net模型构建
由于我们是初试语义分割,所以我们希望能够迅速的获得实验结果,所以我们使用torch中预训练好的vgg16作为backbone,如果对于自己手动搭建更为感兴趣,可以参考下面这篇博客尝试——常用线性CNN模型的结构与训练
如果上文的过程能够理解,下面的代码就不难理解了,我们截取vgg16的五个下采样过程,然后进行上采样,最后调整通道数即可
class U_net(nn.Module):
def __init__(self, backbone='VGG16', channels=[64, 128, 256, 512, 512], out_channel=6):
super(U_net, self).__init__()
if backbone == 'VGG16':
vgg16 = models.vgg16(pretrained=True)
backbone = list(vgg16.children())[0]
self.b1 = nn.Sequential(*list(backbone.children())[:5])
self.b2 = nn.Sequential(*list(backbone.children())[5:10])
self.b3 = nn.Sequential(*list(backbone.children())[10:17])
self.b4 = nn.Sequential(*list(backbone.children())[17:24])
self.b5 = nn.Sequential(*list(backbone.children())[24:])
self.up_sample2 = up_sample(channels[1], channels[0])
self.up_sample3 = up_sample(channels[2], channels[1])
self.up_sample4 = up_sample(channels[3], channels[2])
self.up_sample5 = up_sample(channels[4], channels[3])
self.uplayer = nn.ConvTranspose2d(channels[0], out_channel, kernel_size=2, stride=2, bias=False)
def forward(self, X):
X1 = self.b1(X)
X2 = self.b2(X1)
X3 = self.b3(X2)
X4 = self.b4(X3)
X5 = self.b5(X4)
output = self.up_sample5(X5, X4)
output = self.up_sample4(output, X3)
output = self.up_sample3(output, X2)
output = self.up_sample2(output, X1)
output = self.uplayer(output)
return output
deeplabv3+
模型概况
其中DCNN指的是深度卷积神经网络,本文中我们将采用resnet18,deeplabv3+的主要思路是从深度卷积神经网络中间的输出结果中先取一个结果经过卷积后放到解码器中(其实这里的解码器只是一种说法,实际就是取出备用,假设经过操作后的结果为A),然后从DCNN末尾的输出经过5种卷积组合分别得到5个值,并将这些值通道合并,然后对于合并后的结果进行通道数调整,调整后的结果再进行上采样使得结果的高和宽与A的高和宽相同,然后再将他们通道数合并,随后经过卷积和上采样得到与原图高宽相同的结果
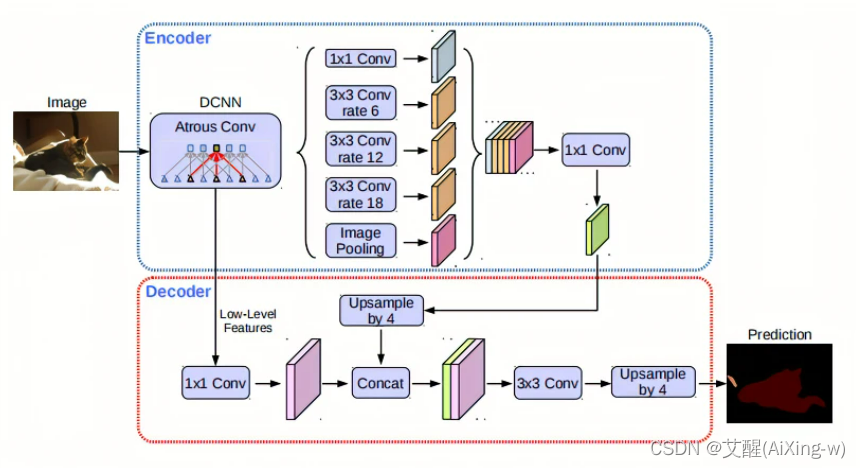
模型代码
resNet
关于resNet的构建请参照常用结构化CNN模型构建在这里我们不再赘述,只放出代码
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
def resNet18(in_channels):
b1 = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5)
return net
ASPP
五种不同卷积组合的过程被称为ASPP,ASPP代码如下
class ASPP(nn.Module):
def __init__(self, dim_in, dim_out, rate=1, bn_mom=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 1, 1, padding=0, dilation=rate,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=6*rate, dilation=6*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=12*rate, dilation=12*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=18*rate, dilation=18*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch5 = nn.Sequential(
# nn.AdaptiveAvgPool2d((1, 1)), # (b, c, r, c)->(b, c, 1, 1)
nn.Conv2d(dim_in, dim_out, 1, 1, 0,bias=True), # (b, c_out, 1, 1)
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True)
)
self.conv_cat = nn.Sequential(
nn.Conv2d(dim_out*5, dim_out, 1, 1, padding=0,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
def forward(self, x):
[b, c, row, col] = x.size()
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
global_feature = torch.mean(x, 2, True)
global_feature = torch.mean(global_feature, 3, True)
global_feature = self.branch5(global_feature)
global_feature = F.interpolate(global_feature, (row, col), None, 'bilinear', True)
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result
deeplabv3+模型构建
class deeplabv3(nn.Module):
def __init__(self, in_channels, num_classes, bonenet='resNet18'):
super(deeplabv3, self).__init__()
if bonenet == 'resNet18':
self.bonenet = 'resNet18'
self.layers = resNet18(3)
low_level_channels = 64
high_level_channels = 512
low_out_channels = 64
high_out_channels = 256
self.shortcut_conv = nn.Sequential(
nn.Conv2d(low_level_channels, low_out_channels, 1),
nn.BatchNorm2d(low_out_channels),
nn.ReLU(inplace=True)
)
self.aspp = ASPP(high_level_channels, high_out_channels)
self.cat_conv = nn.Sequential(
nn.Conv2d(256+64, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
)
self.cls_conv = nn.Conv2d(256, num_classes, 1, stride=1)
if self.bonenet == 'resNet18':
self.up_sample = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=2, padding=2, stride=2, bias=False)
def forward(self, X):
img_size = X.shape[-2:]
if self.bonenet == 'resNet18':
X = self.layers[:2](X)
short_cut = self.shortcut_conv(X)
if self.bonenet == 'resNet18':
X = self.layers[2:](X)
aspp = self.aspp(X)
aspp = F.interpolate(aspp, size=(short_cut.shape[-2], short_cut.shape[-1]), mode='bilinear', align_corners=True)
concat = self.cat_conv(torch.cat([aspp, short_cut], dim=1))
ans = self.cls_conv(concat)
ans = self.up_sample(ans)
# ans = F.interpolate(ans, size=(img_size[0], img_size[1]), mode='bilinear', align_corners=True)
return ans
结尾
本篇中我们完成了对于U-net和deeplabv3+的构建,在下一篇中我们将构建用于训练的损失函数与训练过程,完成使用航拍语义分割









![[一键CV] Blazor 拖放上传文件转换格式并推送到浏览器下载](https://user-images.githubusercontent.com/8428709/205942253-8ff5f9ca-a033-4707-9c36-b8c9950e50d6.png)
