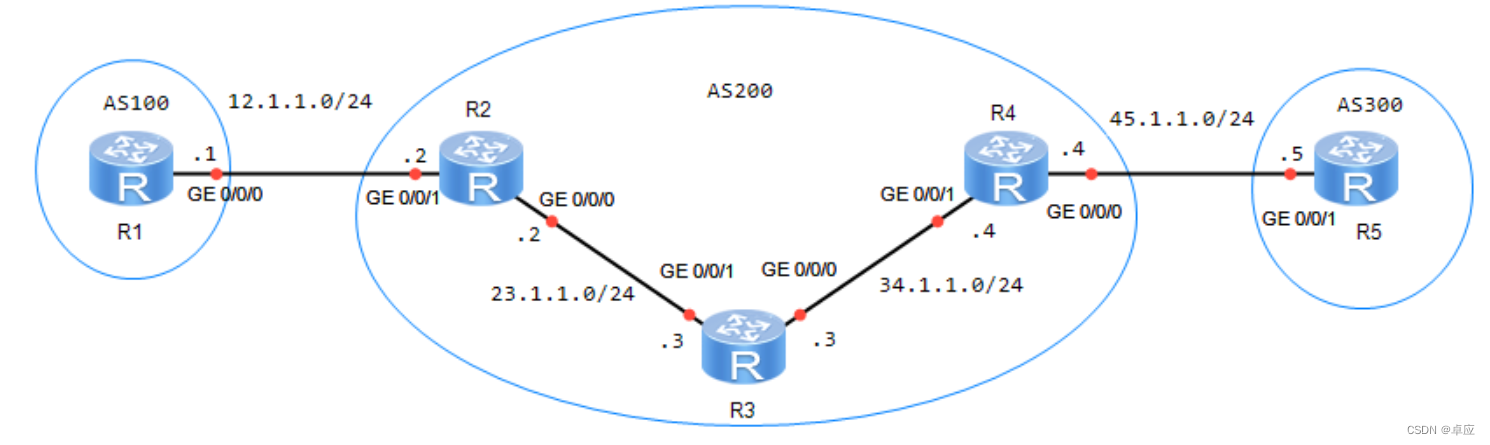
简单行编辑程序
一、引言
1.1 问题的提出
文本编辑程序是利用计算机进行文字加工的基本软件工具,实现对文本文件的插入、删除等修改操作。限制这些操作以行为单位进行的编辑程序称为行编辑程序。
被编辑的文本文件可能很大,全部读入编辑程序的数据空间(内存)的作法既不经济,也不总能实现。一种解决方法是逐段地编辑。任何时刻只把待编辑文件的一段放在内存,称为活区。试按照这种方法实现一个简单的行编辑程序。设文件每行不超过320个字符,很少超过80个字符。
实现以下4条基本编辑命令:
(1) 行插入。格式:i<行号><回车><文本>.<回车>
将<文本>插入活区中第<行号>行之后。
(2) 行删除。格式:d<行号l>[<空格><行号2>]<回车>
删除活区中第<行号l>行(到第<行号2>行)。例如:"d10"和"d1014"。
(3) 活区切换。格式n<回车>
将活区写入输出文件,并从输入文件中读入下一段,作为新的活区。
(4) 活区显示。格式:p<回车>
逐页地(每页20行)显示活区内容,每显示一页之后请用户决定是否继续显示以后备页(如果存在)。印出的每一行要前置行号和一个空格符,行号固定占4位,增量为1。
各条命令中的行号均须在活区中各行行号范围之内,只有插入命令的行号可以等于活区第一行行号减1,表示插入当前屏幕中第一行之前,否则命令参数非法。
1.2 任务需求分析
程序对文字以行为单位进行编辑,功能有行的插入、行的删除、行的交换和进入下一页。要求用文本文件输入数据,并将修改好的数据保存到另一个文件中。因输入文件可能太大,不能将数据一次性全部输入,仅输入一部分。
首先要从文件中将数据读入内存,要以行为单位,而不能以每个字或每句话为单位。因此要定义一个结构体,存储一行的内容。而要使编辑方便,需要每行的编号,因此在结构体中要加入一个存储行号的变量。
但从文件中读数据不能一次全读完,因此定义一个活区的类,这个类里包含了行的数量和行的结构体变量。
接着将文件内容输出到显示器,将活区的内容分次输出。
下面就是对数据的处理了,每行的内容存储到结构体数组中,删除操作只需将后一个的把前一个覆盖,并将数组数量减一。
插入操作,将数组数量加一,从后向前到插入处,把前一个覆盖后一个。然后将要插入的内容写入插入处即可。
二、代码分析
2.1 设计思想
本课程设计主要解决在文本编辑中,对行编辑的问题,通过字符串完善对文本的编辑,实现对文本的查找、替换、和修改数据。在程序设计中采用了字符串的方法实现对简单的行编辑器。程序通过调试运行,初步实现了设计目标,并且经过适当完善后,将可以应用在实际中解决问题。用字符串实现一个简单的行编辑器,其中包括字符的按行录入、修改、替换、查询。用栈实现简单的行编辑程序,文本编辑程序是利用计算机进行文字加工的基本软件工具,实现对文本文件的插入、删除等修改操作。限制这些操作以行为单位进行的编辑程序称为行编辑程序。被编辑的文本文件可能很大,全部读入编辑程序的数据空间(内存)的做法即不经济,又不易实现。一种解决方法是逐段的编辑。任何时刻只把待编辑文件的一段放在内存,称为活区。
通过《简单行编辑程序》的设计过程,我学会了分析研究数据结构的特性,以便为应用涉及的数据选择适当的逻辑结构,存储结构及相应的算法,并初步掌握算法的时间分析和空间分析的技术。一方面,通过该题目设计工程,也是复杂程序设计的训练过程,要求我编写程序设计结构清楚和正确易读,符合软件工程的规范。
2.2 基础知识
2.2.1栈的概念和特性
栈(stack)是一种特殊的线性表。作为一个简单的例子,可以把食堂里冼净的一摞碗看作一个栈。在通常情况下,最先冼净的碗总是放在最底下,后冼净的碗总是摞在最顶上。而在使用时,却是从顶上拿取,也就是说,后冼的先取用,后摞上的先取用。如果我把冼净的碗“摞上”称为进栈(压栈),把“取用碗”称为出栈(弹出),那么上例的特点是:后进栈的先出栈。然而,摞起来的碗实际上是一个线性表,只不过“进栈”和“出栈”都在最顶上进行,或者说,元素的插入和删除操作都是在线性表的一端进行而已。
一般而言,栈是一个线性表,其所有的插入和删除操作均是限定在线性表的一端进行,允许插入和删除的一端称栈顶(Top),不允许插入和删除的一端称栈底(Bottom)。若给定一个栈S=(a1, a2,a3,……,an),则称a1为栈底元素,an为栈顶元素,元素ai位于元素ai-1之上。栈中元素按a1, a2,a3,……,an 的次序进栈,如果从这个栈中取出所有的元素,则出栈次序为an, an-1,……,a1 。也就是说,栈中元素的进出是按后进先出的原则进行,这是栈结构的重要特征。因此栈又称为后进先出(LIFO—Last In First Out)表。
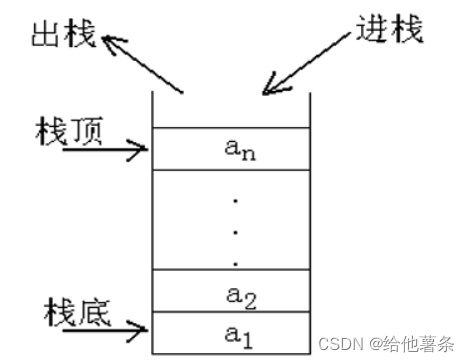
我常用一个图来形象地表示栈,其形式如图2-1:
图2-1 栈操作示意图
通常,对栈进行的操作主要有以下几种:
⑴在使用栈之前,首先需要建立一个空栈,称建栈(栈的初始化);
⑵往栈顶加入一个新元素,称进栈(压栈、入栈);
⑶删除栈顶元素,称出栈(退栈、弹出);
⑷查看当前的栈顶元素,称读栈;{注意与⑶的区别}
⑸在使用栈的过程中,还要不断测试栈是否为空或已满,称为测试栈。
2.2.2栈的存储结构
(1)顺序栈
栈是一种线性表,在计算机中用一维数组作为栈的存储结构最为简单,操作也最为方便。例如,设一维数组STACK[1…n] 表示一个栈,其中n为栈的容量,即可存放元素的最大个数。栈的第一个元素,或称栈底元素,是存放在STACK[1]处,第二个元素存放在STACK[2]处,第i个元素存放在STACK[i]处。另外,由于栈顶元素经常变动,需要设置一个指针变量top,用来指示栈顶当前位置,栈中没有元素即栈空时,令top=0;当top=n时,表示栈满。
如果一个栈已经为空,但用户还继续做出栈(读栈)操作,则会出现栈的“下溢”;如果一个栈已经满了,用户还继续做进栈操作,则会出现栈的“上溢”。这两种情况统称为栈的溢出。
建栈的操作很简单,只要建立一个一维数组,再把栈顶指针置为零即可。栈的容量根据具体的应用要求而定,一般要定义的足够大。如:
type arraytype= array[1.. n] of integer;
var stack:arraytype;
top:integer;
(2)链式栈
当我学可指针和链表后,也可以用链表来模拟栈(链式栈),这样可以提高空间利用率,但编程复杂度提高了。定义方法如下:
type link=^node
node=record
data: integer;
next:link
end;
var hs:link;
链式栈如图
2-2
图2-2 链式栈示意图
2.3程序模块设计
2.3.1 主函数设计
栈是一种先进后出的线性表,为了能按照原来的输入顺序输出元素,我在程序中设计了两个栈,第一个栈用来存储输入的字符,然后把第一个栈的元素出栈,并且把出栈的元素放入第二个栈中,这样就实现了出栈是元素的顺序和最开始输入的顺序是一致的了。
首先,构造一个空栈函数Createlist();然后设计输入函数push(SqStack &S,char e)和出栈函数pop(SqStack &S,char &e);在这两个函数里,我通过顶指针的增加(S.top++=e)和指针的减少来实现元素的进栈和出(e=–S.top)。

我通过设计函数int insert()来进行行插入操作,通freemem()来清空栈中所有的元素,通过使用free()函数来释放top的地址。通过函int saveanddisplay(int hang)输出显示输入的所有元素。具体流程如图2-3。
图2-3 主函数流程图
2.3.2 删除模块设计
代码如下:
void delstringword(char *s,char *str)
{
char *p=strstr(s,str);
char tmp[80];
int len=strlen(s);
int i=len-strlen(p);
int j=i+strlen(str);
int count=0;
for(int m=0;m〈i;m++)tmp[count++]=s[m];
for(int n=j;n〈len;n++)tmp[count++]=s[n];
tmp[count]=’\0';
strcpy(s,tmp);
}
在函数的开始定义了三个指向struct text结构体的指针变量p1,p2,p3。输入要删除的两个行号(比如1 3),表示删除从第1行到第3行的数据。程序流程图如图2-4所示。
执行行删除功能时,由主函数调用删除函数删除所需删除行,再调用显示函数,显示执行行删除后的文本。
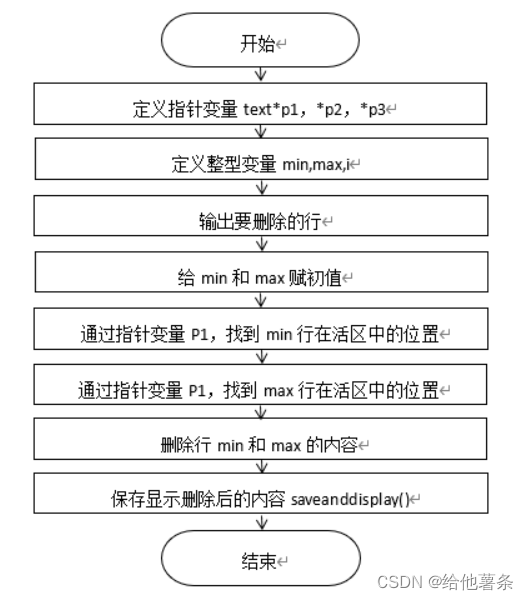
int del(textp head)//删除d命令对应的函数,用来删max-min中的行,用结构体中的flat表示是否被删除。
图2-4 删除模块流程图
2.3.3 插入模块
代码如下:
void insertString()
{
int row, col;
char insstr[MAXLEN];
char newstr [MAXLEN];
char *myline;
interPosition(&row, &col);
myline = buf[row];
printf("插入字符串:");
scanf("&s",insstr);
if(strlen(myline) + strlen(insstr) >= MAXLEN)
return;
sprintf (newstr, "%s%s",insstr, myline + col);
strcpy (myline + col, newstr);
printf("&04d:8s\n", row, myline);
}
行插入函数的开始定义了三个指向struct text结构体的指针变量p,p1,p2,在给hang赋初值后使p1指向头结点,利用for循环,找到要插入行的前一行hang-1,然后
给插入的行分配内存空间。输入文本内容并连入链表。
2.3.4 活区切换格式模块
活区切换函数实现活区之间的切换,把文本的每一页(20行)作为一个活区,可以逐页的把活区内容显示出来。在活区切换函数中定义了一个指向struct text结构体的指针变量p赋初值*p=NULL,当i小于20时,如果行没有被删除(flag=1)就通过fputs函数把活区内容写入到文件(out)流程图如2-5 所示。

图2-5 活区切换格式模块流程图
2.3.5 活区显示格式模块
代码如下:
void listLines()
{
int n;
for(n=0;n<lines;n++) printf("%04d:%s\n",n,buf[n]);
}
void gotoLine()
{
int n;
scanf("%d",&n);
if(0<=n && n<lines) printf("%04d:%s\n",n,buf[n]);
}
显示函数display()在程序运行过程中经常得以调用,是行编辑程序中极其重要的一个函数。行编辑程序通过对显示函数display()的调用,在程序执行行插入、行删除等编辑功能后,输出编辑后的文本。
在活区显示中首先把文本内容链入链表,函数中用page来实现页码的自增。函数种定义了一个指向struct text结构体的指针变量p ,在文件fp非空和行号小于20的情况下,利用fgets函数使p->string从打开的文件fp中得到字符的值,然后输出每一行的行号和每一行的内容。其程序流程图如图2-6所示。

图2-6 活区显示格式模块流程图
三、内核调试
3.1 调试分析
3.1.1 算法的时间复杂度和空间复杂度
1.时间复杂度
一个算法的时间复杂度,是指执行算法所需要的计算工作量。通常,对于一个给定的算法,我要做两项分析。第一是从数学上证明算法的正确性,这一步主要用到形式化证明的方法及相关推理模式,如循环不变式、数学归纳法等。而在证明算法是正确的基础上,第二步就是分析算法的时间复杂度。算法的时间复杂度反映了程序执行时间随输入规模增长而增长的量级,在很大的程度上能很好的反映出算法的优劣与否。
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行才能知道。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数越多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我想知道它变化时呈现什么规律。为此,我引入时间复杂度概念。一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称时间复杂度。
2.空间复杂度
一个程序的空间复杂度是指运行完一个程序所需内存的大小。利用程序的空间复杂度,可以对程序的运行所需要的内存多少有个预先估计。一个程序执行时除了需要存储空间和存储本身所使用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为现实计算所需信息的辅助空间。
3.2 测试结果
测试数据:任意的TXT文件,只要每行不超过80个字符。进入程序的界面,出现命令的帮助信息,按任意键开始程序编辑。输入INPUT文件与OUTPUT文件的名字打开相应的文件 。输入P命令显示活区的内容。
其它的命令操作如下:
行插入格式: i<行号><回车><文本><回车>
行删除格式: d<回车><行号1>[<空格><行号2>]<回车>
活区切换格式: n<回车>
清屏格式: c<回车>
帮助格式: h<回车>
最后输入e命令退出程序。
(1)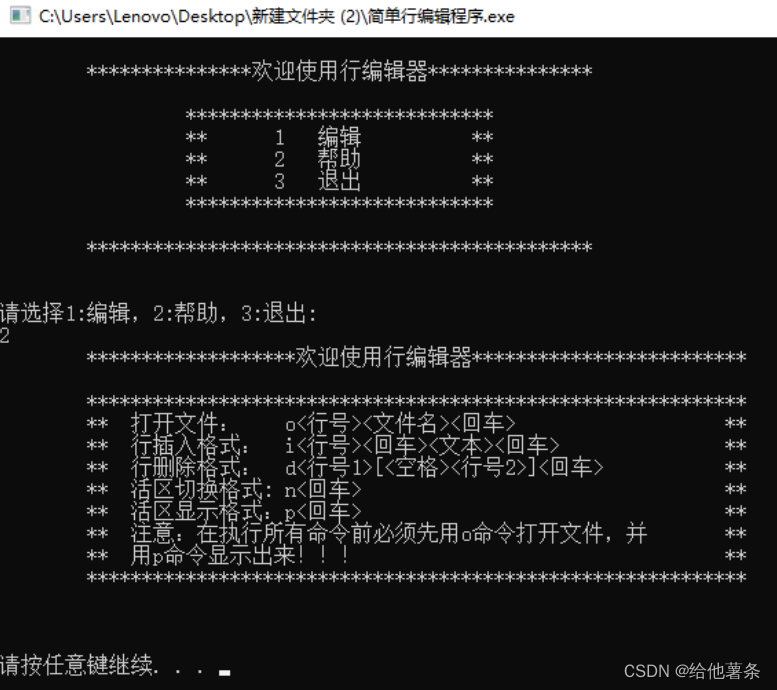
在程序运行初始状态,界面显示如图3-1。提示用户输入任意键进行其他功能。
图3-1 程序主界面图
(2)输入任意键后,用户可根据自己的要求,在输入文件名的情况下输入其他命令。如图3-2。

图3-2 显示文件图

(3)行插入执行过程。在键盘上输入i回车i1i2后,在文本第二行插入i1i2字符串。如图3-3。
图3-3 插入执行图
(4)执行行删除,输入活动区切换等指令后,便会出现图3-4界面。

图3-4 删除执行图
(5)建立a.txt文件,用于程序执行测试。如图3-5。
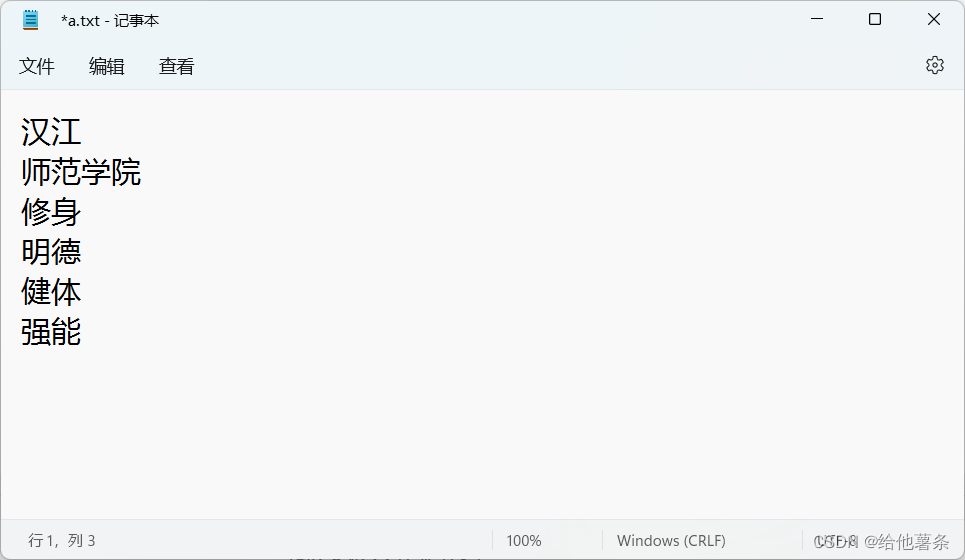
图3-5 测试文件图
(6) 计算机中存储的文本b.txt本是一个空文本文档,但在执行完程序后,文本中出现了程序运行的如图3-6最终结果。

图3-5 结果文件图
四、课程设计总结
本次课程设计的内容是简单行编辑程序。经过一个周,我完成了本次课程设计,过程可谓曲折。在此过程中,构思,编写程序代码的过程是最花费时间的,对于我而言,编写一个简单行编辑程序有些困难,每天对着电脑,查阅各种资料。在程序的调试中,经常会遇到这样那样的错误,有的是因为对基本知识点不熟悉,造成的语法错误,有的是由于粗心,造成的错误,所以导致了程序的不能正常运行。每个实验通常都要花很长时间才能够理清一个程序的思路,而且要不断地调试程序,同时还要做到界面的美化。在此期间,整个课程设计的过程中让我严肃认真的对待本次课程设计,所以让我很回味这整个过程,最终,在我一起的努力下,最终完成了本次任务。
在这次课程设计中,使我懂得了理论与实际相结合是非常重要的。只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能提高自己的思考和解决问题以及实际动手能力。同时也巩固和加深了我对数据结构的进一步掌握, 提高综合运用本课程所学知识的能力,培养了我运用参考书,查阅手册及文献资料的能力,培养独立思考,深入研究,分析问题,解决问题的能力。通过实际对编译系统的分析设计,编程调试,掌握应用软件的分析方法和设计方法。而且,在做课程设计的同时也是对课本知识的巩固和加强,平时看课本时,有些问题就不是很理解,做完课程设计,这些问题就迎刃而解了,还可以记住很多东西。
认识来源于实践,实践是认识的最终目的,所以这个学期期末的数据结构课程设计对我来所作用非常大,让我更加了解数据结构的重要性,它将会在我的专业发展中发挥重要的作用。有了这次课程设计,我相信在以后的课程设计制作中,能够轻松并高质量的完成。
参考文献
[1]严蔚敏,吴伟明;《数据结构》(C语言版),清华大学出版社,2007年
[2]韩海,梁庆中;《程序设计:C语言》,科学出版社,2015年
[3]谭浩强.C语言程序设计(第2版)学习指导.北京:清华大学出版社,2009.
[4]杨莉,龚义建.C语言程序设计实训指导教程.武汉:华中科技大学出版社,2009.
[5]张小东,郑宏珍.C语言程序设计与应用.北京:人民邮电出版社,2009.
[6]郭翠英.C语言课程设计案例精编.北京:中国水利水电出版社,2004.
[7]伍一,孔凡辉,孙柏祥.数据结构应用教程(第二版).清华大学出版社,2012.
[8]胡学刚.数据结构(c语言版).北京:高等教育出版社,2007.







![C#操作字符串方法 [万余字总结 · 详细]](https://img-blog.csdnimg.cn/9fb8984127ff483db400fc8542344fb4.png)