1、分布式锁 (ngix,zoomkeeper,raft,kafka)
在单机场景下,可以使用语言的内置锁来实现进程或者线程同步。但是在分布式场景下,需要同步的进程可能位于不同的节点上,那么就需要使用分布式锁。
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用并发处理相关的功能进行互斥控制。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的应用并不能提供分布式锁的能力。为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁满足的条件有哪些?
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;基础点
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
实现方式有哪些?
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。
基于数据库实现分布式锁;
基于缓存(Redis等)实现分布式锁;
基于Zookeeper实现分布式锁;
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
INSERT INTO method_lock (method_name, desc备注信息) VALUES (‘methodName’, ‘测试的methodName’);
因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
成功插入则获取锁,执行完成后删除对应的行数据释放锁:
delete from method_lock where method_name =‘methodName’;
注意:这只是使用基于数据库的一种方法,使用数据库实现分布式锁还有很多其他的玩法!
基于数据库的方法缺陷很多:
数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换;
不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;
没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
选用Redis实现分布式锁原因:
(1)Redis有很高的性能;
(2)Redis命令对此支持较好,实现起来比较方便
SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
实现思想:
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
#连接redis
redis_client = redis.Redis(host="localhost",
port=6379,
password=password,
db=10)
#获取一个锁
lock_name:锁定名称
acquire_time: 客户端等待获取锁的时间
time_out: 锁的超时时间
def acquire_lock(lock_name, acquire_time=10, time_out=10):
"""获取一个分布式锁"""
identifier = str(uuid.uuid4())
end = time.time() + acquire_time
lock = "string:lock:" + lock_name
while time.time() < end:
if redis_client.setnx(lock, identifier):
# 给锁设置超时时间, 防止进程崩溃导致其他进程无法获取锁
redis_client.expire(lock, time_out)
return identifier
elif not redis_client.ttl(lock):
redis_client.expire(lock, time_out)
time.sleep(0.001)
return False
#释放一个锁
def release_lock(lock_name, identifier):
"""通用的锁释放函数"""
lock = "string:lock:" + lock_name
pip = redis_client.pipeline(True)
while True:
try:
pip.watch(lock)
lock_value = redis_client.get(lock)
if not lock_value:
return True
if lock_value.decode() == identifier:
pip.multi()
pip.delete(lock)
pip.execute()
return True
pip.unwatch()
break
except redis.excetions.WacthcError:
pass
return False
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
永久节点:不会因为会话结束或者超时而消失;
临时节点:如果会话结束或者超时就会消失;
有序节点:会在节点名的后面加一个数字后缀,并且是有序的,例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,以此类推。
为一个节点注册监听器,在节点状态发生改变时,会给客户端发送消息。
基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock;
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
这里推荐一个Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。如果一个已经获得锁的会话超时了,因为创建的是临时节点,所以该会话对应的临时节点会被删除,其它会话就可以获得锁了。可以看到,这种实现方式不会出现数据库的唯一索引实现方式释放锁失败的问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
2、集群
集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。
负载均衡器可以用来实现高可用以及伸缩性:
高可用:当某个节点故障,负载均衡器会将用户请求转发到另外的节点上,从而保证所有服务持续可用
伸缩性:根据系统整体负载情况,可以很容易地添加或移除节点。
负载均衡器运行过程包含两个部分:
根据负载均衡算法得到转发的节点;
进行转发。
负载均衡算法
轮询算法把每个请求轮流发送到每个服务器上。
一共有 6 个客户端产生了 6 个请求,这 6 个请求按 (1, 2, 3, 4, 5, 6) 的顺序发送。(1, 3, 5) 的请求会被发送到服务器 1,(2, 4, 6) 的请求会被发送到服务器 2。
加权轮询是在轮询的基础上,根据服务器的性能差异,为服务器赋予一定的权值,性能高的服务器分配更高的权值。
最少连接算法就是将请求发送给当前最少连接数的服务器上。
在最少连接的基础上,根据服务器的性能为每台服务器分配权重,再根据权重计算出每台服务器能处理的连接数。
源地址哈希法 (IP Hash)
源地址哈希通过对客户端 IP 计算哈希值之后,再对服务器数量取模得到目标服务器的序号。
可以保证同一 IP 的客户端的请求会转发到同一台服务器上,用来实现会话粘滞
转发如何实现?
1. HTTP 重定向
HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服务器的 IP 地址之后,将该地址写入 HTTP 重定向报文中,状态码为 302。客户端收到重定向报文之后,需要重新向服务器发起请求。
缺点:
需要两次请求,因此访问延迟比较高;
HTTP 负载均衡器处理能力有限,会限制集群的规模。该负载均衡转发的缺点比较明显,实际场景中很少使用它。
- DNS 域名解析
在 DNS 解析域名的同时使用负载均衡算法计算服务器 IP 地址。
优点:DNS 能够根据地理位置进行域名解析,返回离用户最近的服务器 IP 地址。
缺点:由于 DNS 具有多级结构,每一级的域名记录都可能被缓存,当下线一台服务器需要修改 DNS 记录时,需要过很长一段时间才能生效。
大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。也就是说,域名解析的结果为内部的负载均衡服务器 IP 地址。
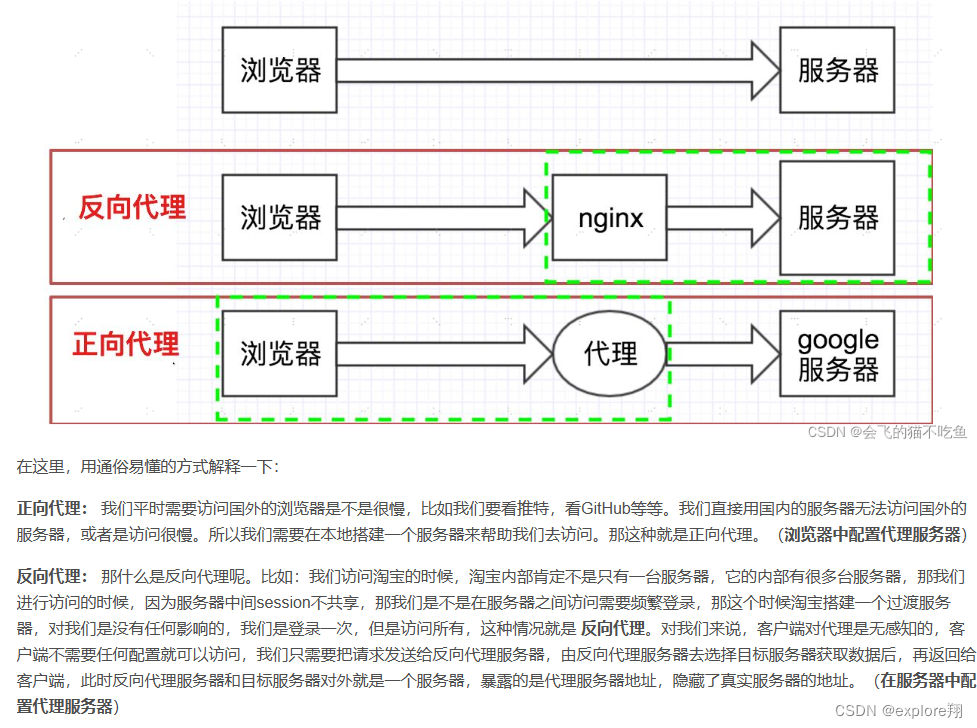
3. 反向代理服务器
反向代理服务器位于源服务器前面,用户的请求需要先经过反向代理服务器才能到达源服务器。反向代理可以用来进行缓存、日志记录等,同时也可以用来做为负载均衡服务器。
在这种负载均衡转发方式下,客户端不直接请求源服务器,因此源服务器不需要外部 IP 地址,而反向代理需要配置内部和外部两套 IP 地址。
优点:
与其它功能集成在一起,部署简单。
缺点:
所有请求和响应都需要经过反向代理服务器,它可能会成为性能瓶颈
4. 网络层
在操作系统内核进程获取网络数据包,根据负载均衡算法计算源服务器的 IP 地址,并修改请求数据包的目的 IP 地址,最后进行转发。
源服务器返回的响应也需要经过负载均衡服务器,通常是让负载均衡服务器同时作为集群的网关服务器来实现。
优点:
在内核进程中进行处理,性能比较高。
缺点:
和反向代理一样,所有的请求和响应都经过负载均衡服务器,会成为性能瓶颈。
5. 链路层
在链路层根据负载均衡算法计算源服务器的 MAC 地址,并修改请求数据包的目的 MAC 地址,并进行转发。
通过配置源服务器的虚拟 IP 地址和负载均衡服务器的 IP 地址一致,从而不需要修改 IP 地址就可以进行转发。也正因为 IP 地址一样,所以源服务器的响应不需要转发回负载均衡服务器,可以直接转发给客户端,避免了负载均衡服务器的成为瓶颈。
这是一种三角传输模式,被称为直接路由。对于提供下载和视频服务的网站来说,直接路由避免了大量的网络传输数据经过负载均衡服务器。
这是目前大型网站使用最广负载均衡转发方式,在 Linux 平台可以使用的负载均衡服务器为 LVS(Linux Virtual Server)
集群下的 Session 管理
一个用户的 Session 信息如果存储在一个服务器上,那么当负载均衡器把用户的下一个请求转发到另一个服务器,由于服务器没有用户的 Session 信息,那么该用户就需要重新进行登录等操作
Sticky Session
需要配置负载均衡器,使得一个用户的所有请求都路由到同一个服务器比如哈希算法,这样就可以把用户的 Session 存放在该服务器中。
缺点:当服务器宕机时,将丢失该服务器上的所有 Session
Session Replication
在服务器之间进行 Session 同步操作,每个服务器都有所有用户的 Session 信息,因此用户可以向任何一个服务器进行请求。
缺点:
占用过多内存;
同步过程占用网络带宽以及服务器处理器时间。
Session Server
使用一个单独的服务器存储 Session 数据,可以使用传统的 MySQL,也使用 Redis 或者 Memcached 这种内存型数据库。
优点:
为了使得大型网站具有伸缩性,集群中的应用服务器通常需要保持无状态,那么应用服务器不能存储用户的会话信息。Session Server 将用户的会话信息单独进行存储,从而保证了应用服务器的无状态。
缺点:
需要去实现存取 Session 的代码。
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。有报告表明能支持高达 50,000 个并发连接数。Nginx支持热部署,启动简单,可以做到7*24不间断运行。几个月都不需要重新启动。
Nginx的负载均衡:轮询,加权轮询,哈希ip
Nginx的动静分离!
Nginx的静态处理能力很强,但是动态处理能力不足,因此,在企业中常用动静分离技术。动静分离技术其实是采用代理的方式,在server{}段中加入带正则匹配的location来指定匹配项针对PHP的动静分离:静态页面交给Nginx处理,动态页面交给PHP-FPM模块或Apache处理。在Nginx的配置中,是通过location配置段配合正则匹配实现静态与动态页面的不同处理方式
目前,通过使用Nginx大大提高了网站的响应速度,优化了用户体验,让网站的健壮性更上一层楼!
location ~ .jsp$ {
proxy_pass http://localhost:8080;
}
location ~ .(html|js|css|png|gif)$ {
root D:/software/developerTools/server/apache-tomcat-7.0.8/webapps/ROOT;
}
raft算法
raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。在这里强调了是在工程上,因为在学术理论界,最耀眼的还是大名鼎鼎的Paxos。 raft是一个共识算法(consensus algorithm),所谓共识,就是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。这些年最为火热的加密货币(比特币、区块链)就需要共识算法,而在分布式系统中,共识算法更多用于提高系统的容错性。
主要是用来竞选主节点。
有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票。
数据同步:来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。Leader 会把修改复制到所有 Follower。Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
关于消息队列
异步处理
发送者将消息发送给消息队列之后,不需要同步等待消息接收者处理完毕,而是立即返回进行其它操作。消息接收者从消息队列中订阅消息之后异步处理。
流量削锋
在高并发的场景下,如果短时间有大量的请求到达会压垮服务器。可以将请求发送到消息队列中,服务器按照其处理能力从消息队列中订阅消息进行处理。
应用解耦
如果模块之间不直接进行调用,模块之间耦合度就会很低,那么修改一个模块或者新增一个模块对其它模块的影响会很小,从而实现可扩展性。
通过使用消息队列,一个模块只需要向消息队列中发送消息,其它模块可以选择性地从消息队列中订阅消息从而完成调用。
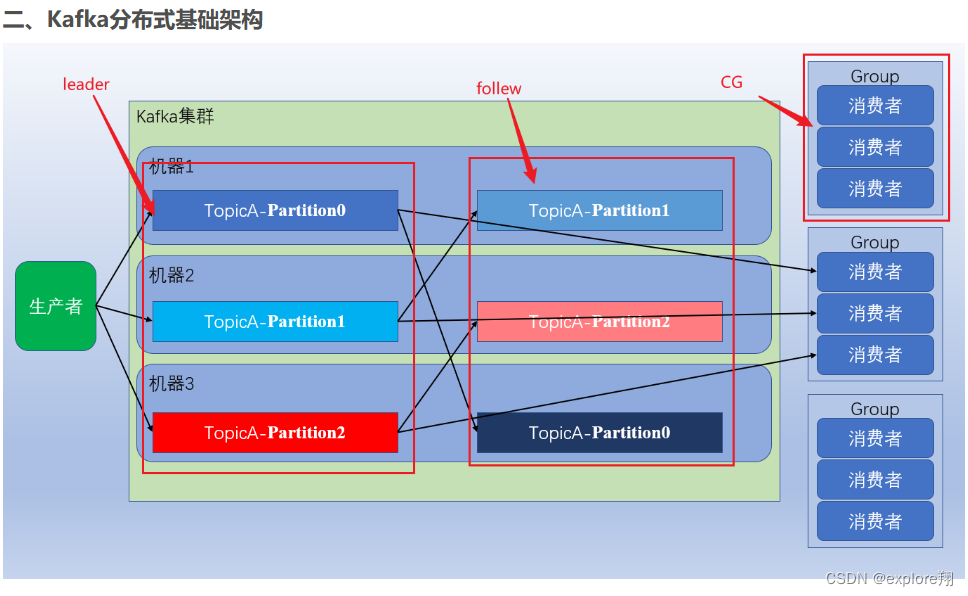
kafka是一个分布式的基于发布/订阅模式的消息队列。
两种模式
点对点(消费者主动拉取数据)。生产者将数据放在消息队列中,消费者消费数据后,消息队列会将数据删除,队列支持可以存在多个消费者,但一个消息能由其中一个消费者消费,即消息和消费者之间是一对一的
发布\订阅模式有一个主题的概念,生产者定义主题,将消息存放在相应的主题中,消费者订阅主题,从该主题中获取数据进行消费,如图该模式下,允许多个消费者订阅同一主题,主题中的每个消息可由多个消费者进行消费,即:消息与消费者之间是一对多的