JOIN的种类
LEFT JOIN
SELECT <select_list>
FROM Table_A A
LEFT JOIN Table_B B
ON A.Key = B.Key
求的是A所有的数据以及A与B的交集
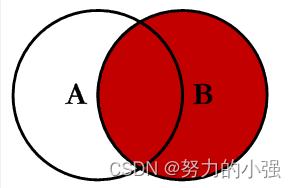
RIGHT JOIN
SELECT <select_list>
FROM Table_A A
RIGHT JOIN Table_B B
ON A.Key = B.Key
求的是B所有的数据以及A和B的交集
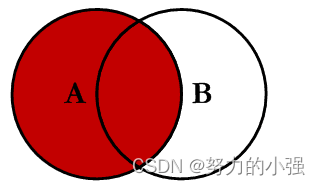
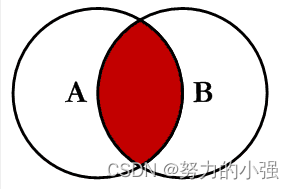
INNER JOIN
SELECT <select_list>
FROM Table_A A
INNER JOIN Table_B B
ON A.Key = B.Key
求的是A和B的交集
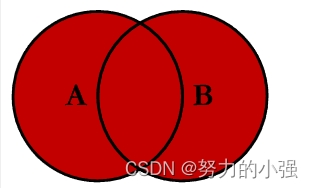
OUTER JOIN
SELECT <select_list>
FROM Table_A A
FULL OUTER JOIN Table_B B
ON A.Key = B.Key
求的是A和B所有的数据
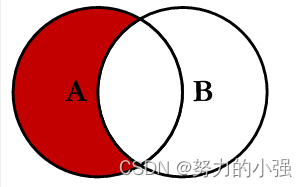
LEFT EXCLUDING JOIN
SELECT <select_list>
FROM Table_A A
LEFT JOIN Table_B B
ON A.Key = B.Key
WHERE B.Key IS NULL
求的是A除去和B的交集的数据
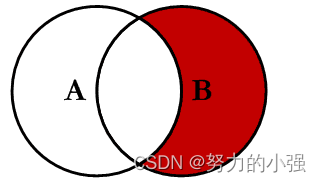
RIGRT EXCLUDING JOIN
SELECT <select_list>
FROM Table_A A
RIGHT JOIN Table_B B
ON A.Key = B.Key
WHERE A.Key IS NULL
求的是B除去和A的交集的数据
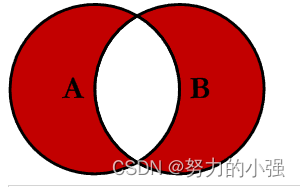
OUTER EXCLUDING JOIN
SELECT <select_list>
FROM Table_A A
FULL OUTER JOIN Table_B B
ON A.Key = B.Key
WHERE A.Key IS NULL OR B.Key IS NULL
求的是A和B除去交集部分的所有数据
CROSS JOIN(笛卡尔连接)
SELECT <select_list>
FROM Table_A A
CROSS JOIN Table_B B
求的是A和B的任意联接的数据,数量是A表行数和B表行数的乘积。如果加上了ON语句,则等同于INNER JOIN。
JOIN算法
Nested-Loop Join(NLJ:嵌套循环JOIN)
| Table | Join Type |
|---|---|
| t1 | range |
| t2 | ref |
| t3 | ALL |
计算过程:
for each row in t1 matching range{
for each row in t2 matching reference key{
for each row in t3{
if row satisfies join conditions,send to client
}
}
}
先从t1中查找出符合要求的数据,然后for循环遍历这些数据;在循环体里查询出t2表中符合要求的数据,并使用key(ON语句用来连接的字段)进行匹配;因为t3是ALL,全表扫描,所以拿t3
表中所有的数据进行匹配,如果满足ON条件,则返回给客户端。因为是嵌套循环进行计算的,所以该算法效率并不高。
假设。第一层循环有100条数据,第二层循环有100条数据,t3表有100条数据,那么总的循环次数就是100100100=1000000。
Block Nested-Loop Join(BNLJ:块嵌套循环JOIN)
还是采用上述三张表进行join查询
计算过程:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
empty buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
}
还是先查询t1中符合条件的数据,然后for循环遍历;在循环体里查询出t2表中符合要求的数据,并使用key(ON语句用来连接的字段)进行匹配;将t1,t2需要用到的数据存到join buffer(连接缓存)中,一直往join buffer中存放数据,当join buffer存满时,会与t3进行匹配,将符合要求的数据返回给客户端,并将缓存清空,继续下一次循环。当循环结束,判断缓存是否为空,不为空则将剩余的数据与t3进行匹配,将符合要求的数据返回给客户端。
BNLJ扫描次数计算公式
(S * C)/join_buffer_size + 1
- S:缓存的t1/t2表的一行数据大小
- C:缓存的行数
- join_buffer_size:join buffer的大小
假设,第一层有100条数据,第二层有100条数据,join buffer中可以存放t1/t2数据为100条,则需要100 * 100 / 100 + 1=101,需要扫描101次。
使用join buffer的条件
- 连接类型是ALL、index或range
- 第一个nonconst table不会分配join buffer,即使类型是ALL、index或range
- join buffer只会缓存需要的字段,而非整行数据
- 可通过join_buffer_size变量设置join buffer的大小
- show variables like ‘join_buffer_size’;查看当前join buffer大小
- set join_buffer_size = XXXX; 设置当前session的join buffer的大小
- set global join_buffer_size = XXXX;设置全局join buffer的大小
- 每个能被缓存的join都会分配一个join buffer,一个查询可能拥有多个join buffer
- join buffer在执行联接之前会分配,在查询完成后释放
Batch Key Access Join(BKA:批量键值访问)
- MySQL5.6引入
- BKA的基石:Multi Range Read(MRR)
什么是MRR
在一次范围查询中,如果未使用主键索引,那么查询到的数据集在查找是可能会伴随大量的随机IO,因为我们的数据是按照主键索引进行排列的;我们知道,非主键索引存储的是主键而不是具体的数据,MRR会在查询到数据集后,根据主键进行一次排序,然后再根据排序后的主键顺序去查找数据,从而将随机IO转换为了顺序IO。MRR的核心就是:将随机IO转换成顺序IO,从而提升性能。
MRR参数
- optimizer_switch的子参数
- mrr:是否开始mrr,on开启,off关闭
- mrr_cost_based:表示是否要开启基于成本计算的MRR
- read_rnd_buffer_size:指定mrr缓存大小
BKA流程
上述的NLJ和BNLJ两种算法都是每次进行IO查找,而BKA则是将外层循环计算的结果存入join buffer中,然后使用t3表索引去跟join buffer中的数据匹配,将一批的数据进行MRR基于主键排序,然后再去进行顺序IO查找。
BKA参数
- optimizer_switch的子参数
- batched_key_access:on开启,off关闭
HASH JOIN
- MySQL8.0.18引入,用来替代BNLJ
- join buffer缓存外部循环的hash表,内层循环遍历时到hash表匹配
SELECT given_name,country_name
FROM persons JOIN countries
ON persons.country_id = countries.country_id;
在构建阶段,拿countries表的country_id构建了一张hash表存放在了内存;在探测阶段,拿persons表的country_id计算hash然后到上一步构建的hash表中进行匹配;另外,在内存存放不下第一步构建的hash表时,会把hash表存放到磁盘。
HASH JOIN注意点
- MySQL8.0.18才引入hash join,且有很多限制,比如不能作用于外连接,比如left join/right join等等。从8.0.20开始,限制少了很多,建议用8.0.20或更高版本。
- 从MySQL8.0.18开始,hash join的join buffer时递增分配的,意味着,你可以为join_buffer_size设置比较大的值。该版本中,如果你使用了外连接,外连接没法用hash join,此时join_buffer_size会按照你设置的值直接分配内存。因此join_buffer_size还是得谨慎设置。从该版本开始,BNLJ已被删除,用hash join替代了BNLJ。
JOIN优化
驱动表 vs 被驱动表
- 外层循环的表是驱动表,内层循环的表是被驱动表
JOIN调优原则
- 用小表驱动大表
- 一般无需人工考虑,关联查询优化器会自动选择最优的执行顺序
- 如果优化器没有进行优化,可使用STRAIGHT_JOIN
- 如果有where条件,应该要能够使用索引,并尽可能的减少外层循环的数据量
- join的字段尽量创建索引
- 尽量减少扫描的行数
- 参与join的表不要太多
- 阿里编程规约建议不超过3张
- 如果被驱动表的join字段无法使用索引,且内存较为充足,可以考虑把join_buffer_size设置的大一些