字符串匹配(String Matchiing)也称字符串搜索(String Searching)是字符串算法中重要的一种,是指从一个大字符串或文本中找到模式串出现的位置。
字符串匹配概念
字符串匹配问题的形式定义:
文本(Text)是一个长度为 n 的数组 T[1..n];
模式(Pattern)是一个长度为 m 且 m≤n 的数组 P[1..m];
T 和 P 中的元素都属于有限的字母表 Σ 表;
如果 0≤s≤n-m,并且 T[s+1..s+m] = P[1..m],即对 1≤j≤m,有 T[s+j] = P[j],则说模式 P 在文本 T 中出现且位移为 s,且称 s 是一个有效位移(Valid Shift)。
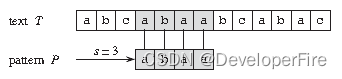
比如上图中,目标是找出所有在文本 T = abcabaabcabac 中模式 P = abaa 的所有出现。该模式在此文本中仅出现一次,即在位移 s = 3 处,位移 s = 3 是有效位移。
字符串匹配算法通常分为两个步骤:预处理(Preprocessing)和匹配(Matching)。所以算法的总运行时间为预处理和匹配的时间的总和。

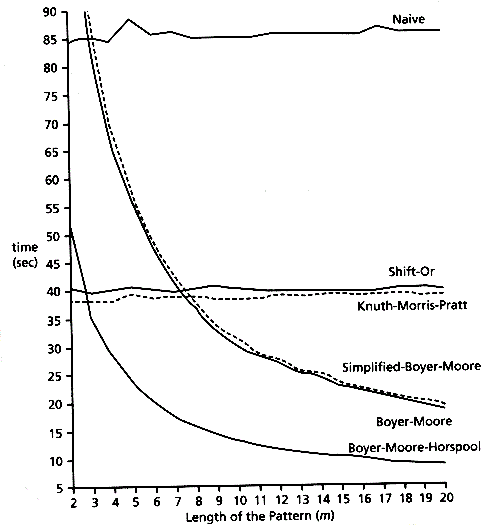
上图描述了常见字符串匹配算法的预处理和匹配时间。
字符串匹配算法
解决字符串匹配的算法包括:朴素算法(Naive Algorithm) 即暴力破解、Rabin-Karp 算法、有限自动机算法(Finite Automation)、 Knuth-Morris-Pratt 算法(即 KMP Algorithm)、Boyer-Moore 算法、Simon 算法、Colussi 算法、Galil-Giancarlo 算法、Apostolico-Crochemore 算法、Horspool 算法和 Sunday 算法等。
朴素的字符串匹配算法(Naive String Matching Algorithm)
朴素的字符串匹配算法又称为暴力匹配算法(Brute Force Algorithm),最为简单的字符串匹配算法
Knuth-Morris-Pratt 字符串匹配算法(即 KMP 算法)
Knuth-Morris-Pratt算法(简称KMP)是最常用的字符串匹配算法之一
Boyer-Moore 字符串匹配算法
各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法,效率非常高
字符串匹配 - 文本预处理:后缀树(Suffix Tree)
上述字符串匹配算法(朴素的字符串匹配算法, KMP 算法, Boyer-Moore算法)均是通过对模式(Pattern)字符串进行预处理的方式来加快搜索速度。对 Pattern 进行预处理的最优复杂度为 O(m),其中 m 为 Pattern 字符串的长度。那么,有没有对文本(Text)进行预处理的算法呢?本文即将介绍一种对 Text 进行预处理的字符串匹配算法:后缀树(Suffix Tree)