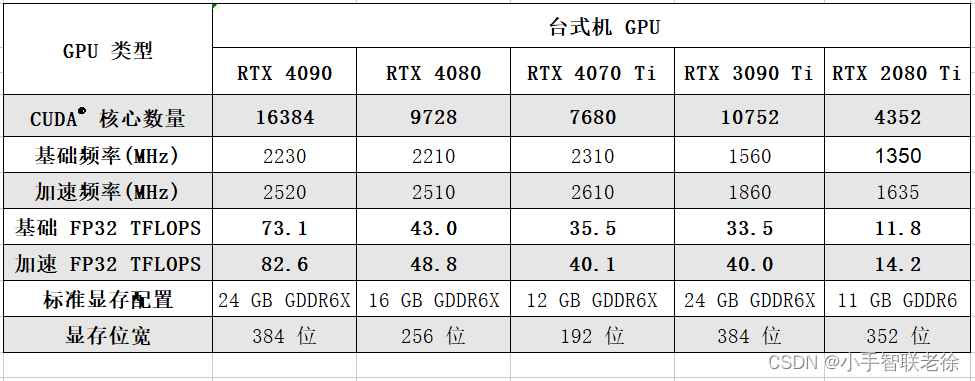
几种工具的处理效率比较:

每次循环都使用复杂的操作尽可能拆分成向量化操作,也可转为numpy,再用numba加速。
对 DataFrame 中的数据做循环处理的效率:
方法一:下标循环
for i in range(len(df)):
if df.iloc[i]['test'] != 1:
df1.iloc[i]['test'] = 0
通过循环一个下标数列,通过iloc获取数据,是最慢的方法。
方法二:iterrows 循环
for ind, row in df.iterrows():
if row['test'] != 1:
df1.iloc[i]['test'] = 0
i += 1
通过iterrows循环,ind和row代表了每一行的index和内容,比下标循环速度提升了300倍。
方法三:Apply
df1['test'] = df['test'].apply(lambda x: x if x == 1 else 0)
Apply内接匿名函数,对Dataframe每一行循环处理,比下标循环速度提升了800倍。
方法四:Pandas内置向量化函数
res = df.sum()
Pandas有大量内置向量化函数,比如sum,mean可快速计算。比下标循环快了9280倍。
方法五:Numpy
df_values = df.values
res = np.sum(df_values)
将Pandas数据转为Numpy,用Numpy内置函数做向量化操作,比下标循环快了71800倍。
参考:
dataframe 循环_【Python效率】五种Pandas循环方法效率对比_weixin_39744230的博客-CSDN博客