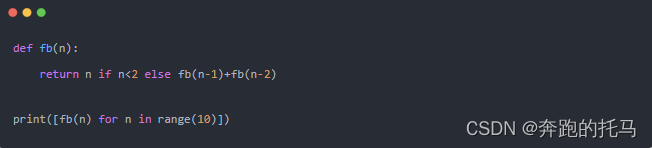
菜单栏

仪表盘:查看被监控服务的运行状态;
拓扑图:以拓扑图的方式展现服务之间的关系,并以此为入口查看相关信息;
追踪:以接口列表的方式展现,追踪接口内部调用过程;
性能剖析:对端点进行采样分析,并可查看堆栈信息;
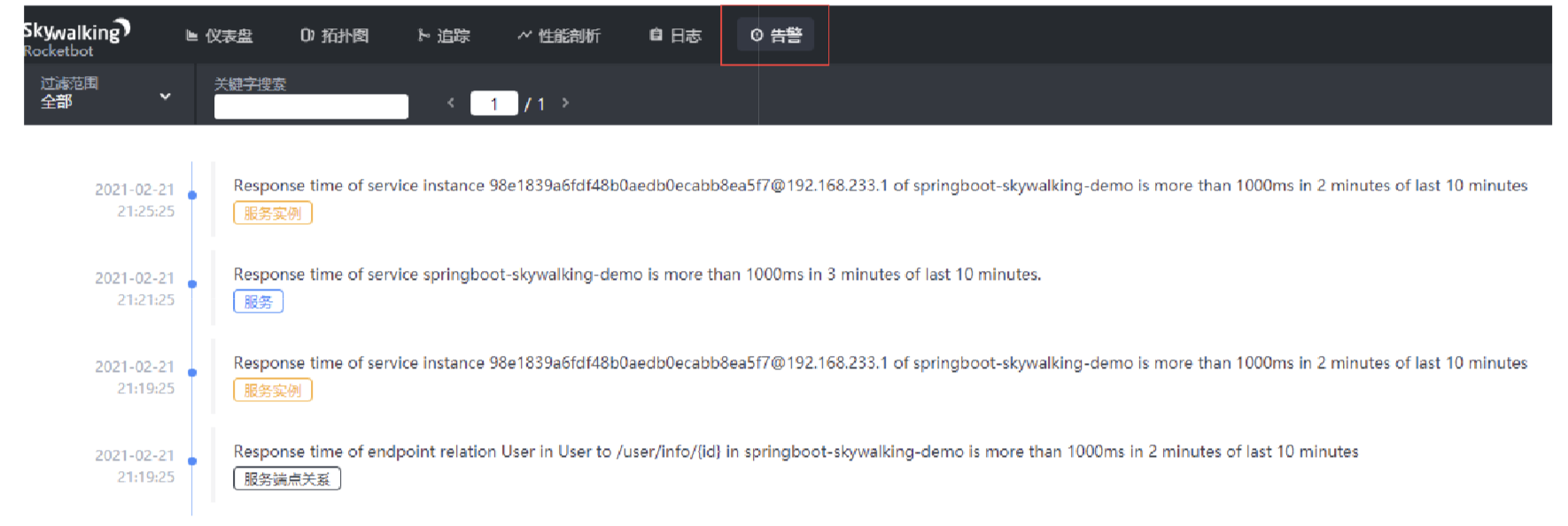
告警:触发告警的告警列表,包括服务失败率,请求超时等;
自动刷新:刷新当前页面数据内容;

第一栏:不同内容主题的监控面板,应用性能管理/数据库/容器等;
第二栏:操作,包括 编辑/导出当前数据/倒入展示数据/不同服务端点筛选展示;
第三栏:不同纬度展示,全局/服务/实例/端点;
展示栏
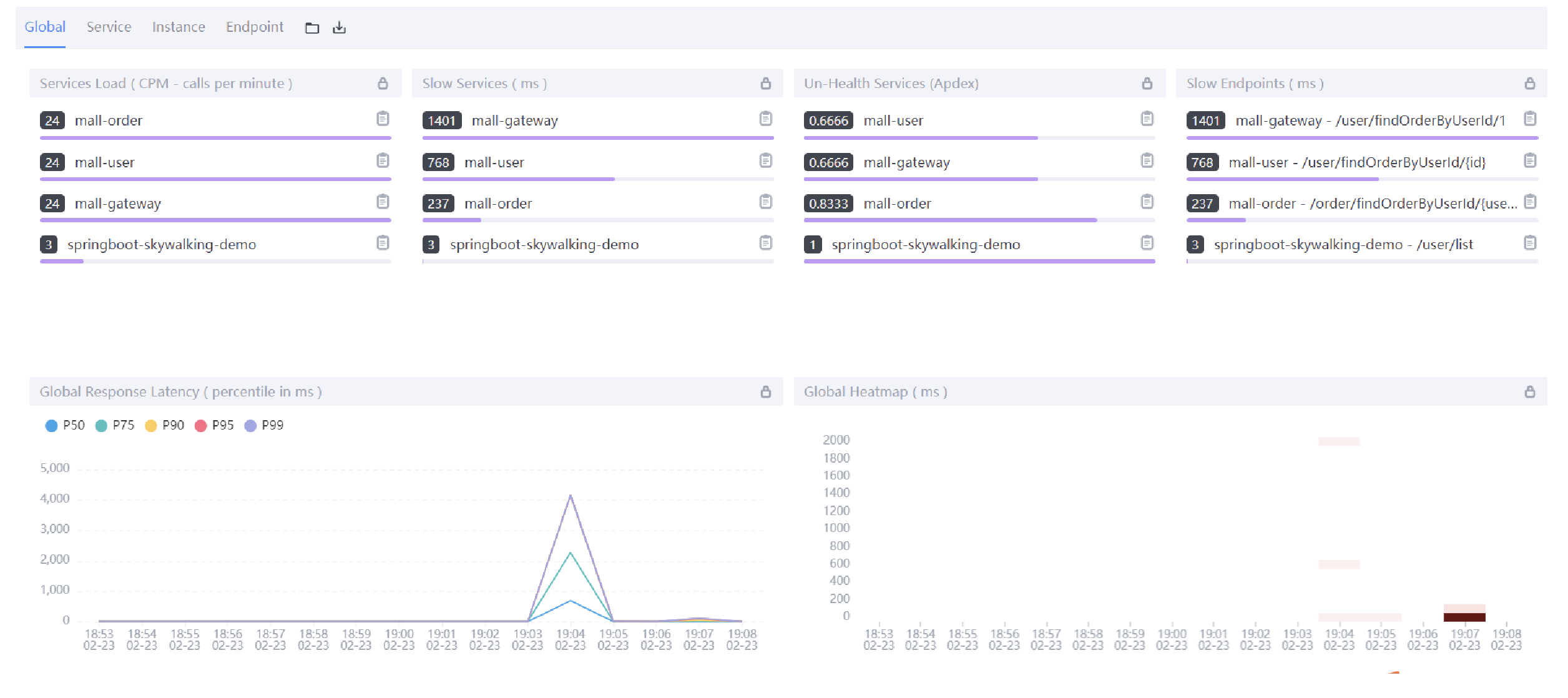
Global全局维度
第一栏:Global、Service、Instance、Endpoint不同展示面板;
Services load:服务每分钟请求数;
Slow Services:慢响应服务,单位ms;
Un-Health services(Apdex): Apdex性能指标,1为满分;
Slow Endpoint:慢响应端点,单位ms;
Global Response Latency:百分比响应延时,不同百分比的延时时间,单位ms;
Global Heatmap:服务响应时间热力分布图,根据时间段内不同响应时间的数量显示颜色深度;
底部栏:展示数据的时间区间,点击可以调整;
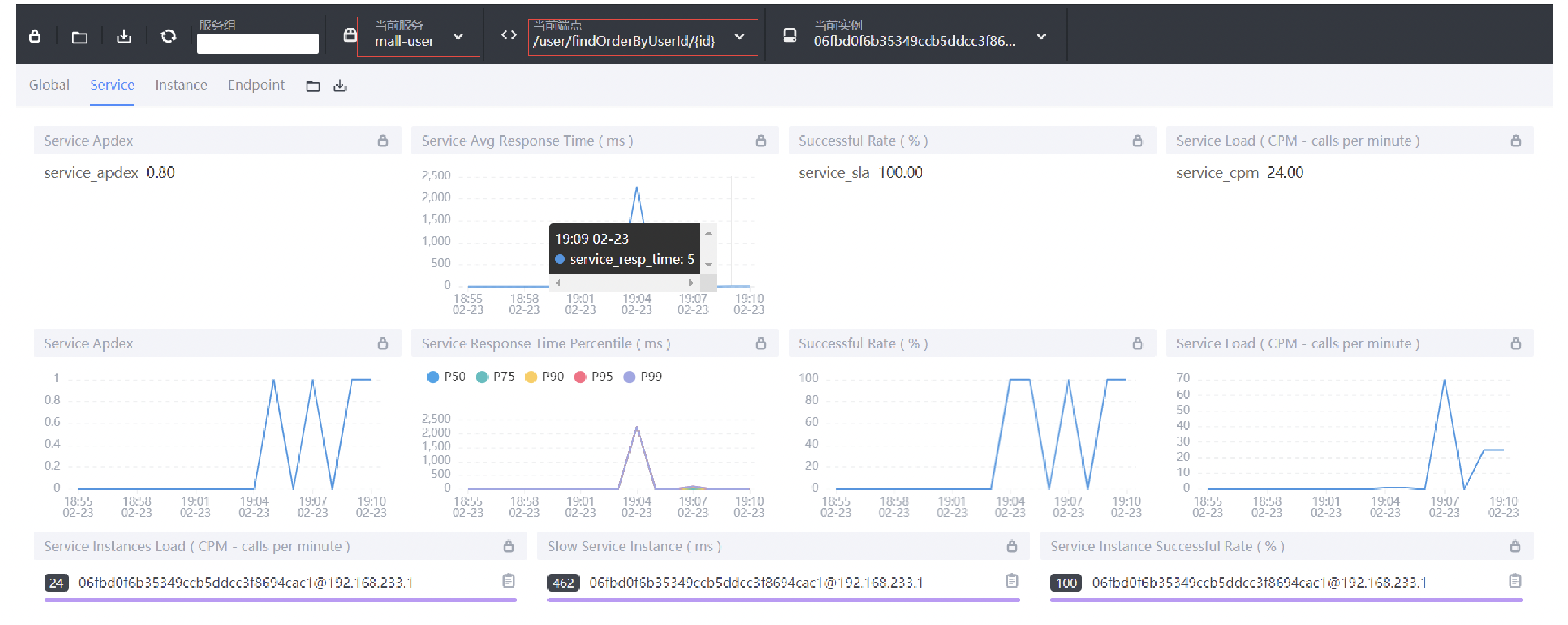
Service服务维度
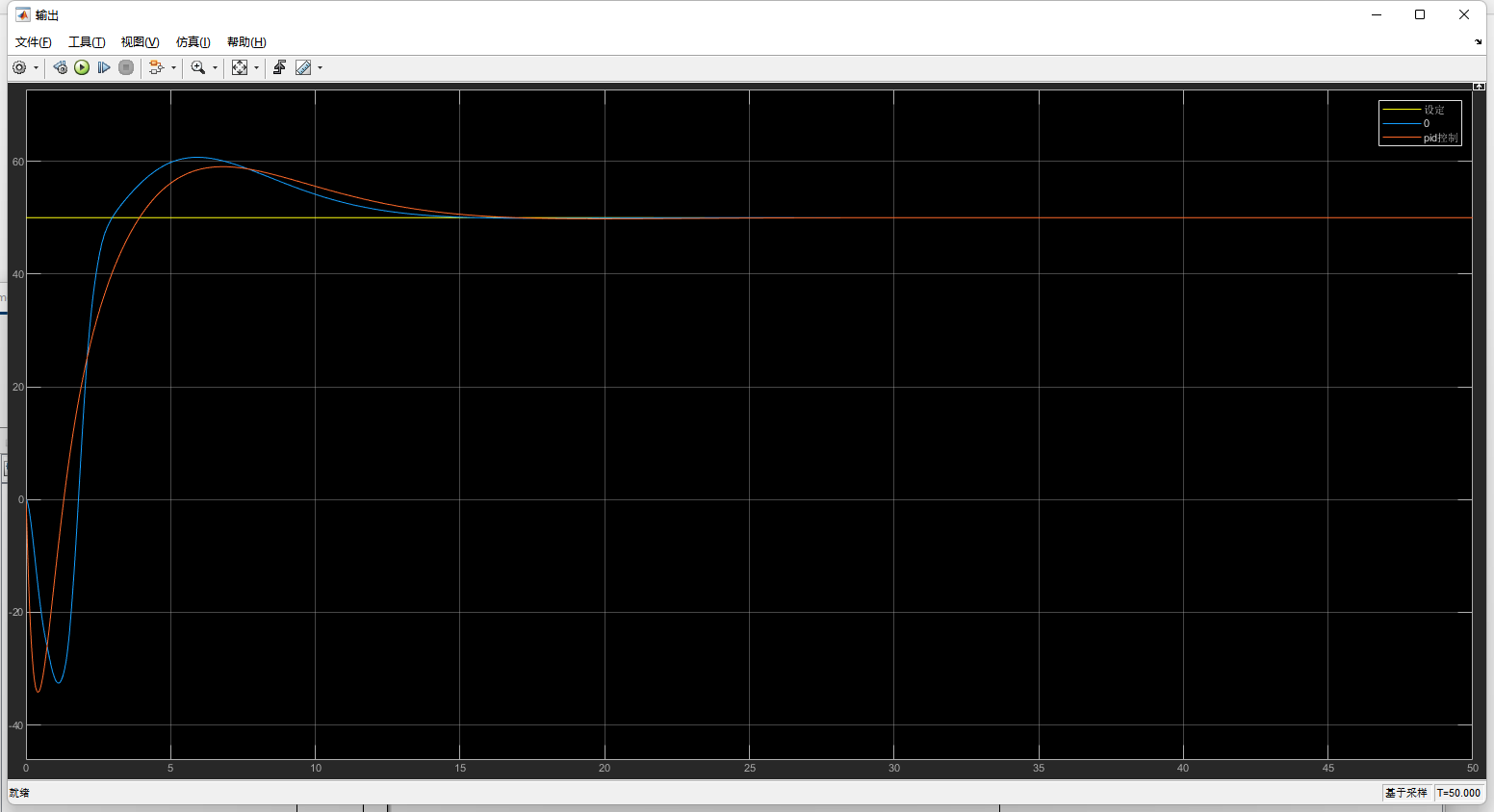
Service Apdex(数字):当前服务的评分;
Service Apdex(折线图):不同时间的Apdex评分;
Service Avg Response Times:平均响应延时,单位ms;
Service Response Time Percentile:百分比响应延时;
Successful Rate(数字):请求成功率;
Successful Rate(折线图):不同时间的请求成功率;
Servce Load(数字):每分钟请求数;
Servce Load(折线图):不同时间的每分钟请求数;
Servce Instances Load:每个服务实例的每分钟请求数;
Show Service Instance:每个服务实例的最大延时;
Service Instance Successful Rate:每个服务实例的请求成功率;
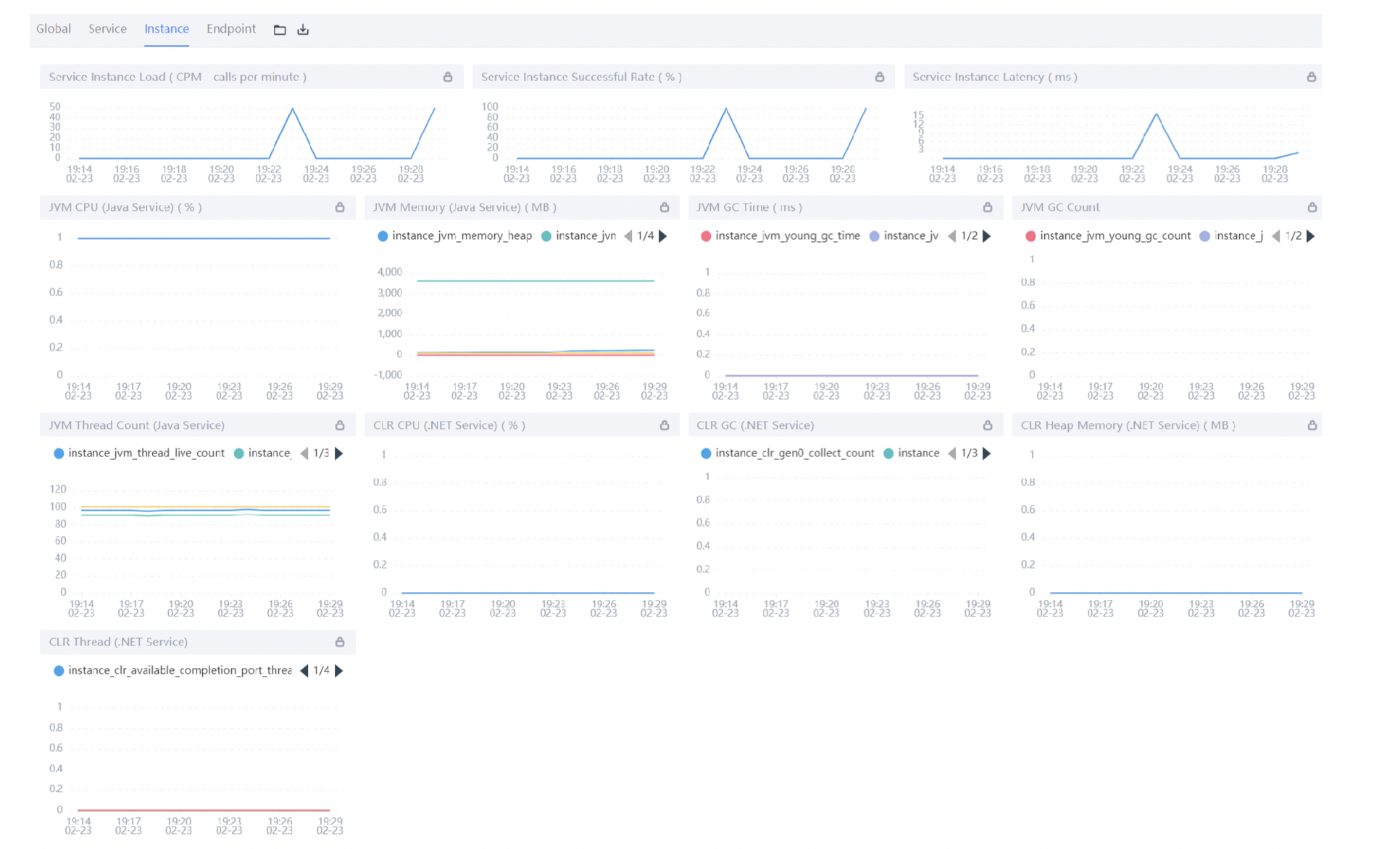
Instance服务维度
Service Instance Load:当前实例的每分钟请求数;
Service Instance Successful Rate:当前实例的请求成功率;
Service Instance Latency:当前实例的响应延时;
JVM CPU:jvm占用CPU的百分比;
JVM Memory:JVM内存占用大小,单位m;
JVM GC Time:JVM垃圾回收时间,包含YGC和OGC;
JVM GC Count:JVM垃圾回收次数,包含YGC和OGC;
JVM Thread Count:JVM线程数;
还有几个是.NET的,类似于JVM虚拟机,暂时不做说明;
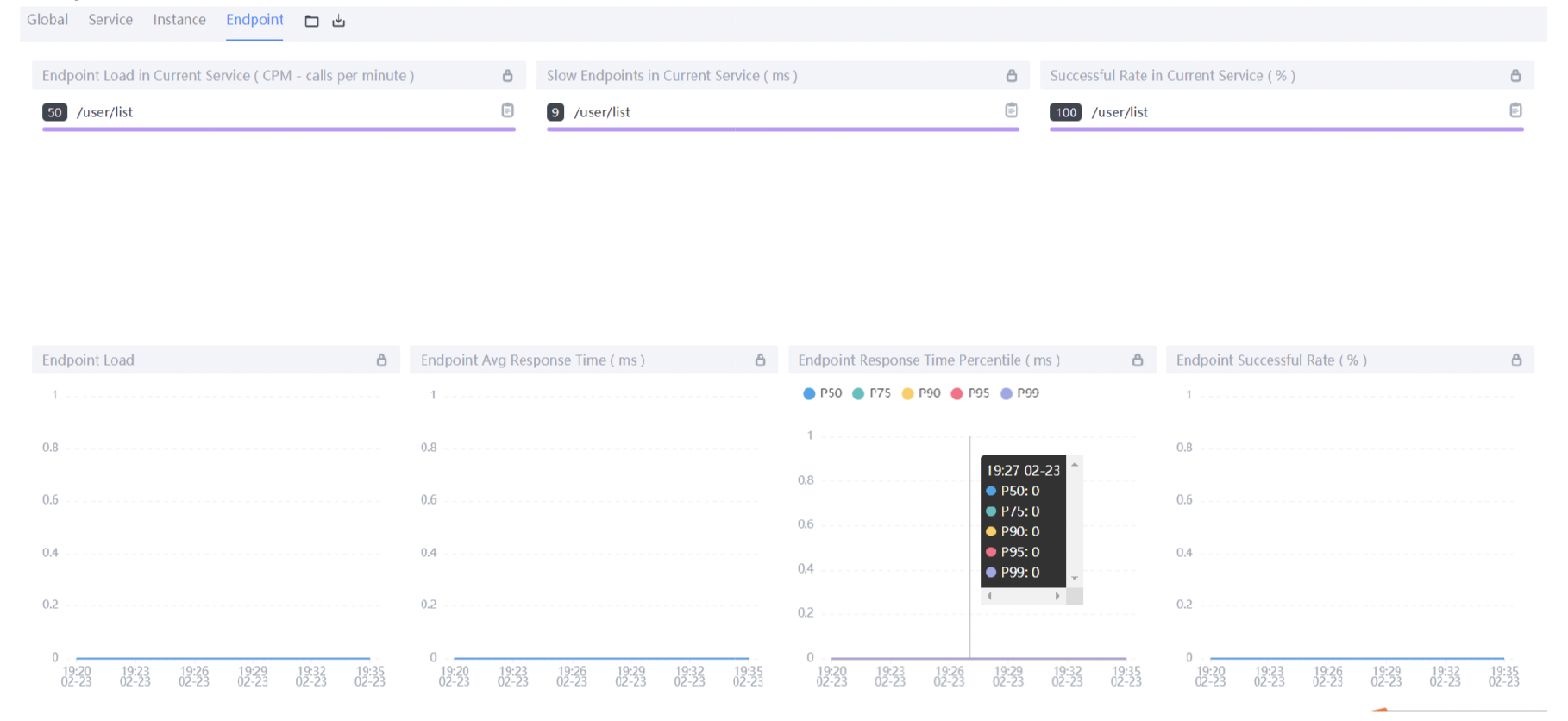
Endpoint端点(API)维度
Endpoint Load in Current Service:每个端点的每分钟请求数;
Slow Endpoints in Current Service:每个端点的最慢请求时间,单位ms;
Successful Rate in Current Service:每个端点的请求成功率;
Endpoint Load:当前端点每个时间段的请求数据;
Endpoint Avg Response Time:当前端点每个时间段的请求行响应时间;
Endpoint Response Time Percentile:当前端点每个时间段的响应时间占比;
Endpoint Successful Rate:当前端点每个时间段的请求成功率;
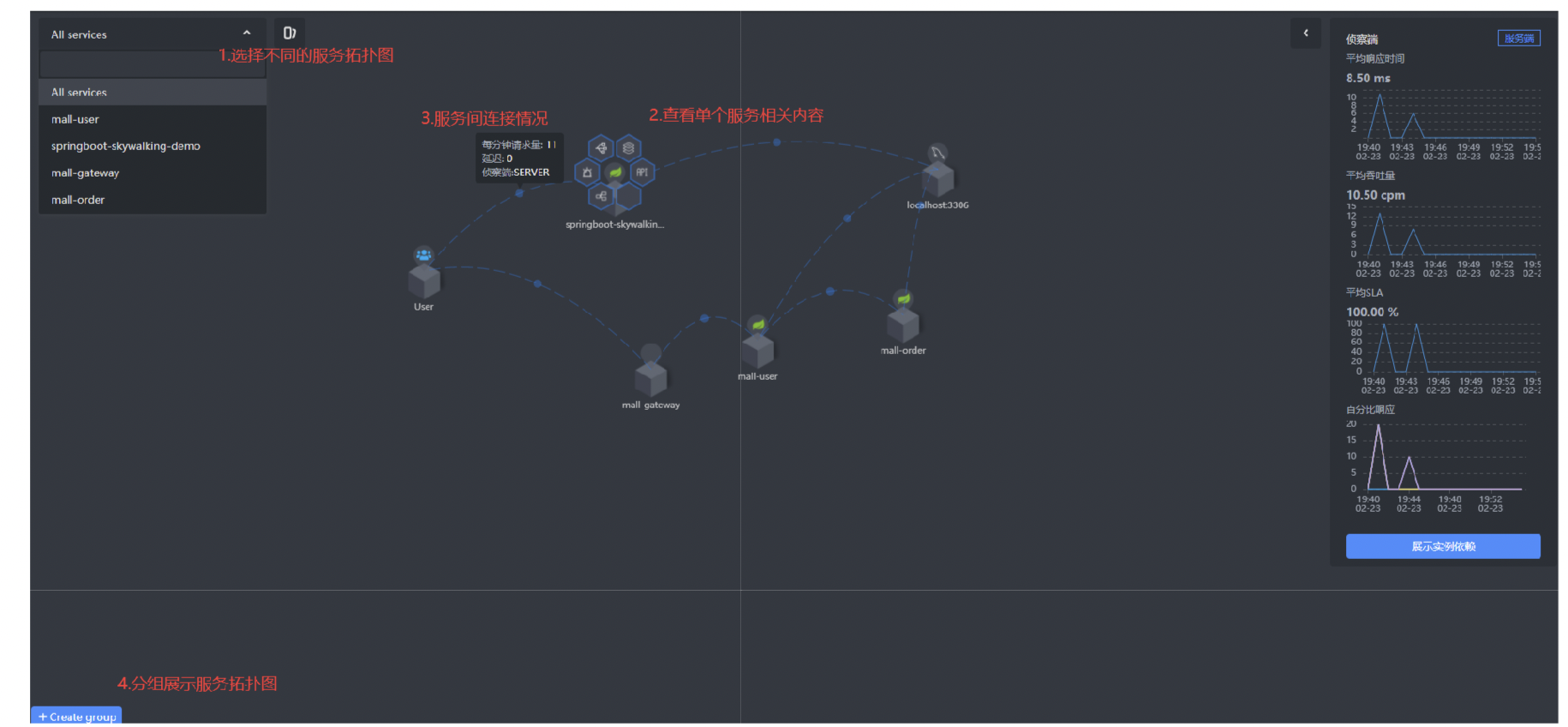
拓扑图
1:选择不同的服务关联拓扑;
2:查看单个服务相关内容;
3:服务间连接情况;
4:分组展示服务拓扑;
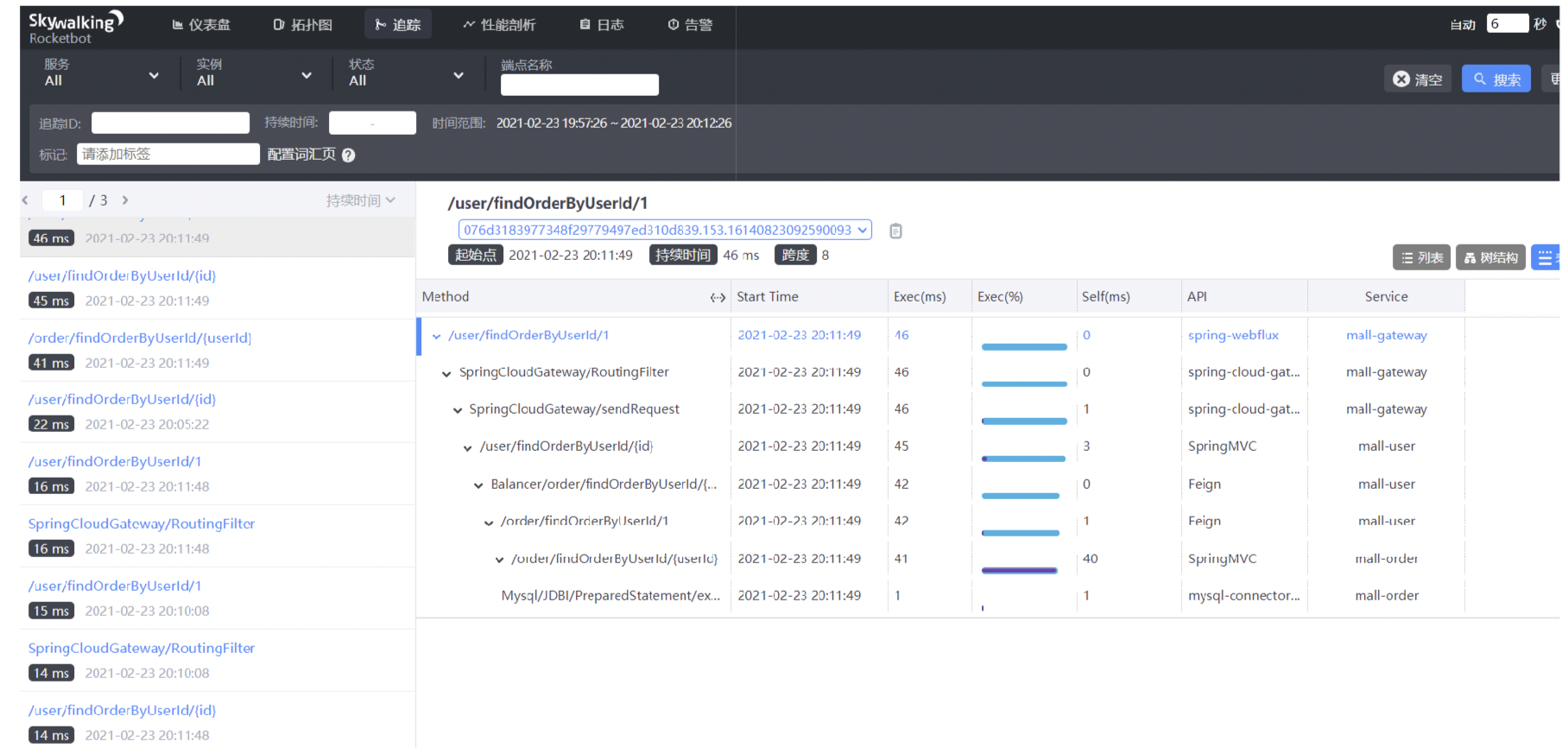
追踪
左侧:api接口列表,红色-异常请求,蓝色-正常请求;
右侧:api追踪列表,api请求连接各端点的先后顺序和时间;
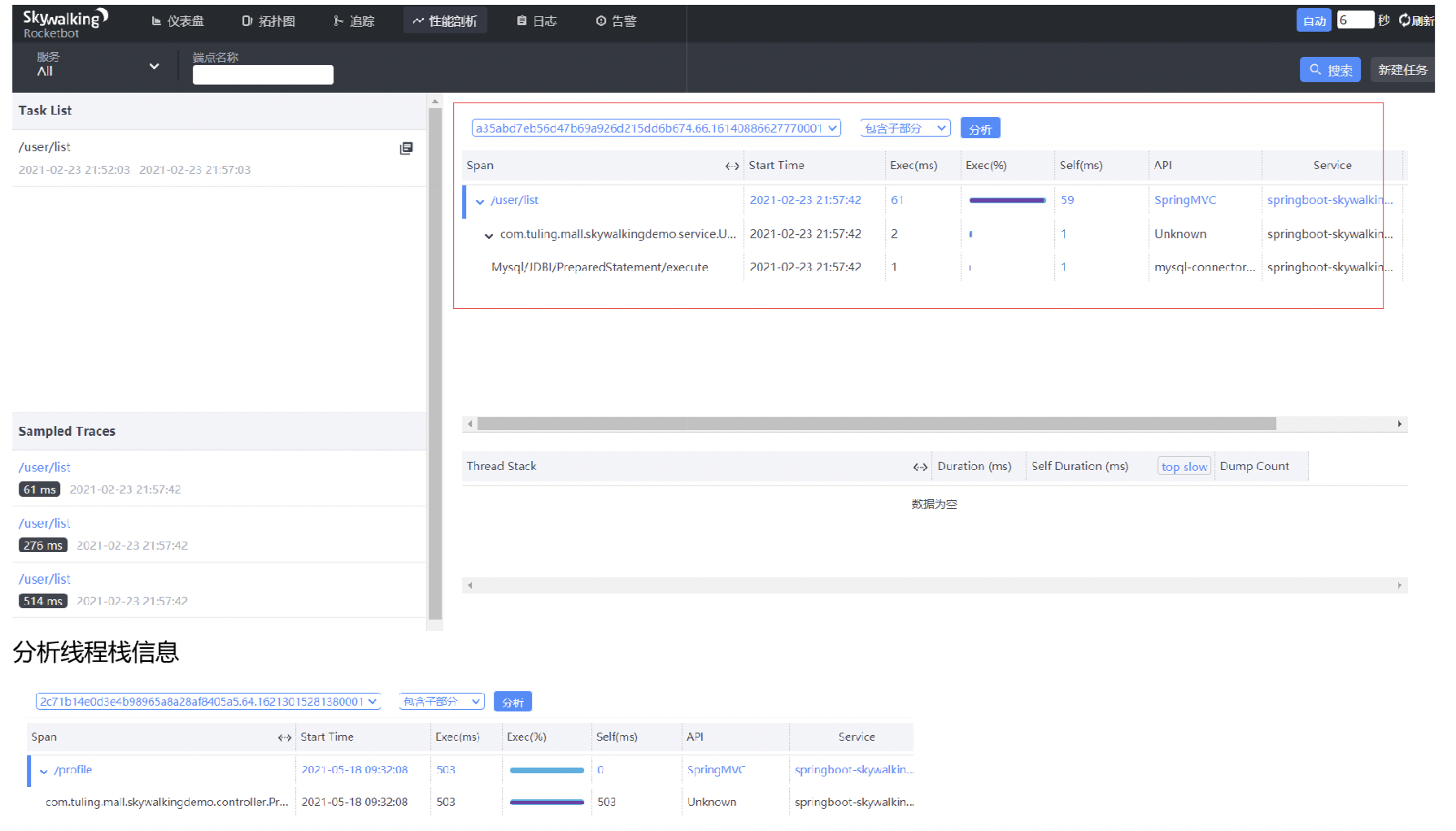
性能剖析
新建任务:新建需要分析的端点
左侧列表:任务及对应的采样请求
右侧:端点链路及每个端点的堆栈信息
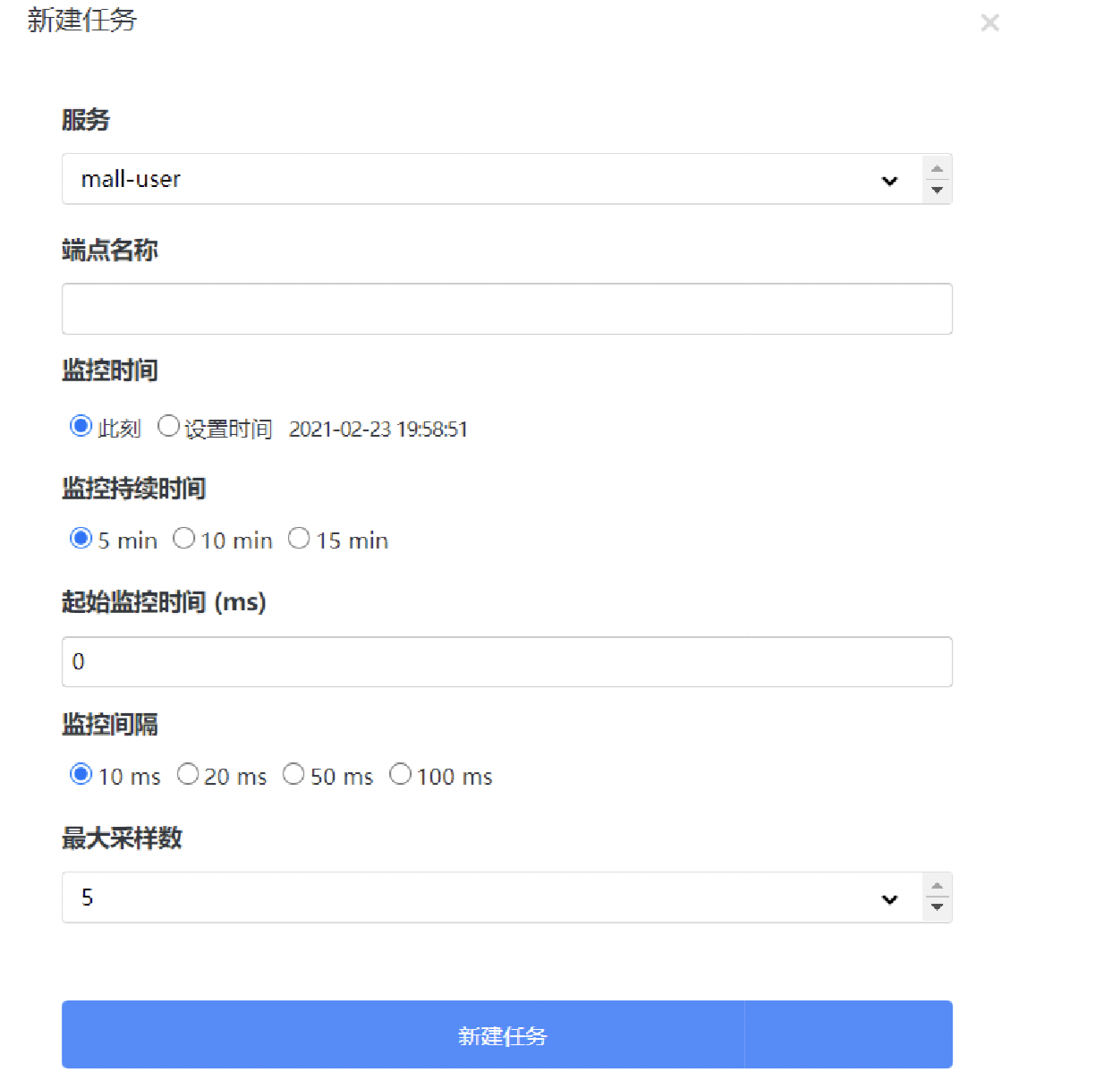
服务:需要分析的服务;
端点:链路监控中端点的名称,可以在链路追踪中查看端点名称;
监控时间:采集数据的开始时间;
监控持续时间:监控采集多长时间;
起始监控时间:多少秒后进行采集;
监控间隔:多少秒采集一次;
最大采集数:最大采集多少样本;
告警
不同维度告警列表,可分为服务、端点和实例。