虚拟内存的能力
- 它将主存看成是一个存储在地址空间的高速缓存,在主存中只保存活动区域,并更具需要在磁盘和主存之间来回传送数据,通过这种方式来高效使用主存(DRAM)
- 它为每个进程提供了一致的地址空间,从而简化了内存管理
- 它保护了每个进程的地址空间不被其他进程破坏
物理和虚拟地址
计算机系统的主存被组织成一个由M个连续的字节大小的单元组成的数组,每个字节都有唯一的物理地址。CPU访问内存的最自然的方式就是使用物理地址,早期的计算机使用物理寻址,现代使用的是虚拟寻址。
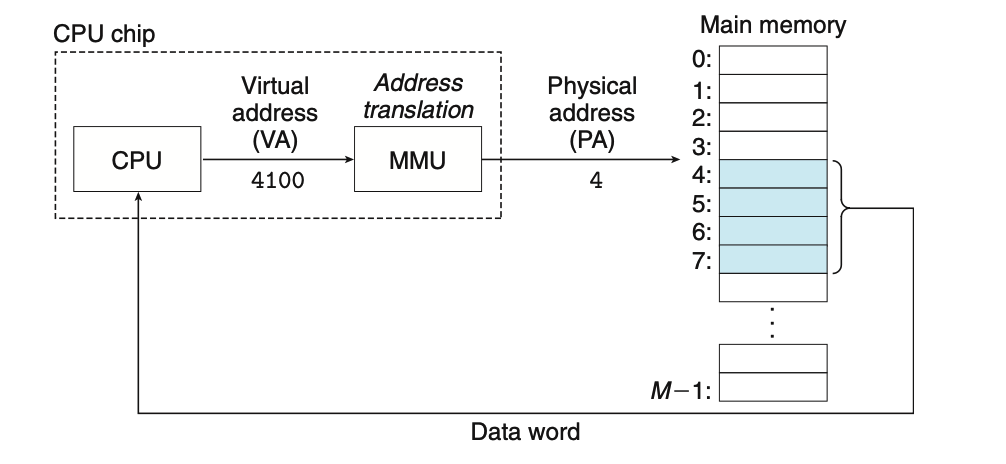
使用虚拟地址,cpu通过生成一个虚拟地址(Virtual Address, VA)来访问主存,这个虚拟地址在被送入Main memory之前会由CPU芯片上的内存管理单元(Memory Management Unit,MMU)利用存在主存中的查询表完成地址翻译(Address translation),该表的内容由操作系统管理.
虚拟内存作为缓存的工具
-
虚拟内存在哪?
虚拟内存被组织为一个由存放在磁盘上的N个连续的字节大小的单元组成的数组。每个字节都有唯一的虚拟地址,作为到数组的索引。磁盘上数组的内容被缓存在DRAM主存中.
-
如何缓存
与存储器层次结构缓存一样,磁盘(较低层)上的数据(虚拟内存)被分隔成块,这些块作为磁盘和主存(较高层)之间的传输单元。
虚拟内存系统将虚拟内存分隔为称为虚拟页(Virtual Page,VP)的固定大小来处理这个问题,每个VP的大小为 P = 2 p P=2^p P=2p字节。类似地,物理内存被分隔成物理页(Physical Page, PP),大小也为P字节,物理页也被称为页帧。
-
虚拟页面的三种状态
- 未分配的:VM系统还没有分配或创建的VP,未分配的VP没有任何数据与其相关联,也就不占用任何磁盘空间
- 缓存的:当前已经缓存在主存中的已分配页
- 未缓存的:未缓存在主存中,但是已经分配了对应的物理页
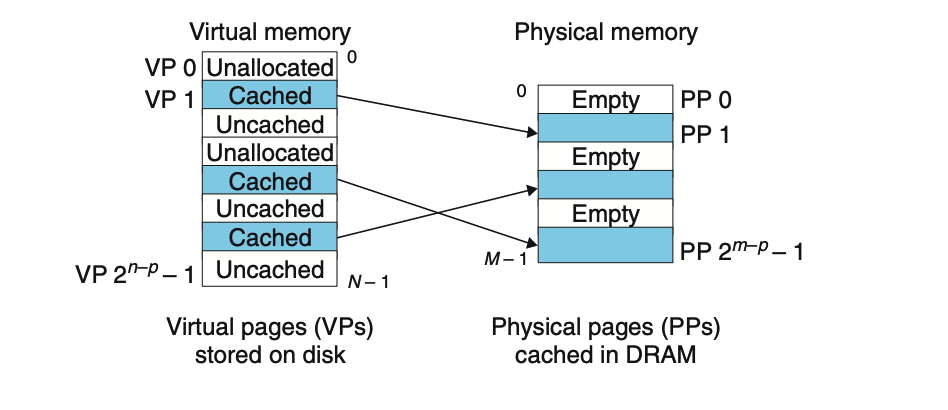
DRAM缓存的组织结构
SRAM缓存位于CPU和主存之间的L1、L2和L3级高速缓存,DRAM缓存表示虚拟内存系统的缓存,它在主存中缓存虚拟页。
根据存储器层次结构的知识,对于DRAM缓存的不命中,成本是极其高的,因为DRAM直接与磁盘打交道。正因如此DRAM缓存的组织结构的设计也极为重要:
- 虚拟页往往很大,通常是4KB-2MB
- DRAM缓存是全相联的(S=1),即任何虚拟页都可以放置在任何的物理页中
- DRAM缓存使用了更复杂精密的替换算法
- DRAM总是采取写回策略(直到被驱逐时才写回),而不是直写
页表
-
页表的作用
判定一个虚拟页是否缓存在DRAM中的某个地方,是的话还能确定其在DRAM中的位置;如果不是,那么该虚拟页在磁盘上的位置也要确定
-
流程
每次MMU做地址翻译的时候都会从主存中读取页表,虚拟地址作为索引定位PTE。操作系统负责维护页表的内容,并且在磁盘和DRAM中传送页
-
页表结构

页表是一个页表条目(Page Table Entry,PTE)的数组,每个PTE由一个有效位和n位地址字段组成。Valid位为1表示该虚拟页被缓存在DRAM中,并且地址字段就是DRAM相应物理页的起始位置;如果Valid位为0,表示虚拟页还没有缓存在DRAM,如果地址字段为空表示这个虚拟页还没有被分配,否则就是虚拟页未缓存的状态,地址指向该虚拟页在磁盘上的起始位置
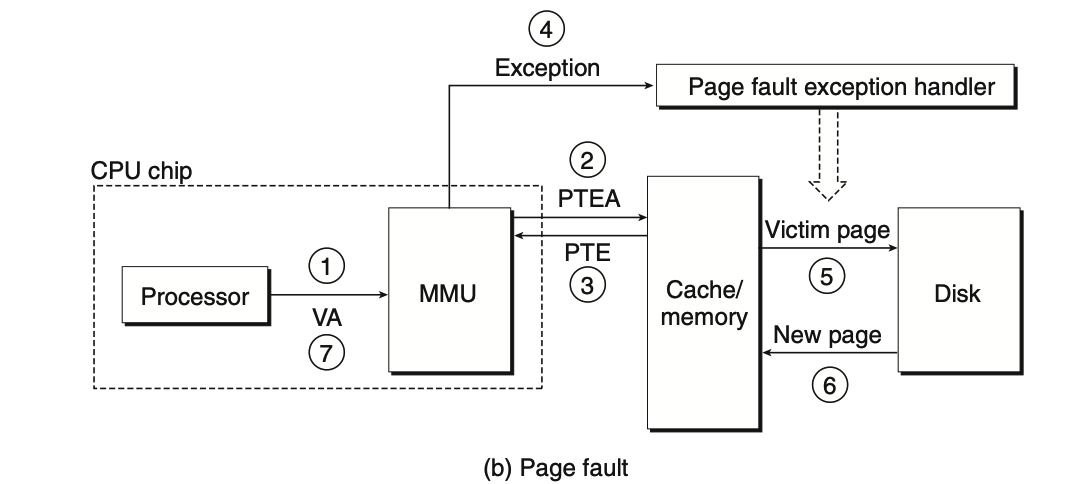
缺页
(这段我认为英文原版描述地更为清晰
The CPU has referenced a word in VP 3, which is not cached in DRAM. The address translation hardware reads PTE 3 from memory, infers from the valid bit that VP 3 is not cached, and triggers a page fault exception. The page fault exception invokes a page fault exception handler in the kernel, which selects a victim page—in this case, VP 4 stored in PP 3. If VP 4 has been modified, then the kernel copies it back to disk. In either case, the kernel modifies the page table entry for VP 4 to reflect the fact that VP 4 is no longer cached in main memory.
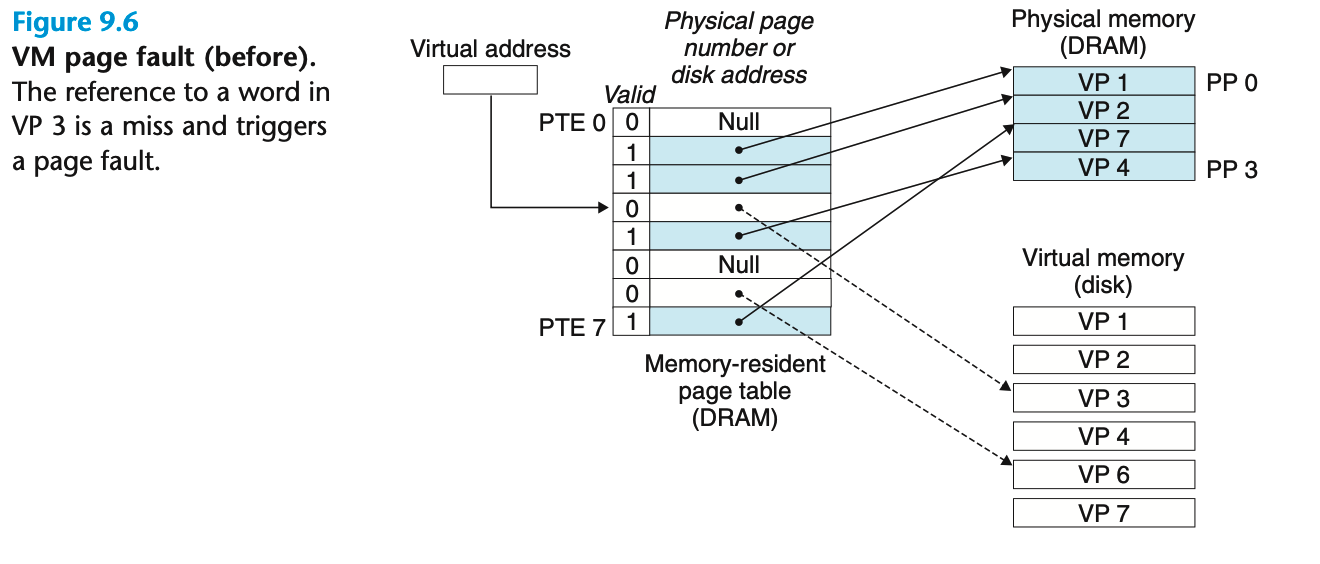
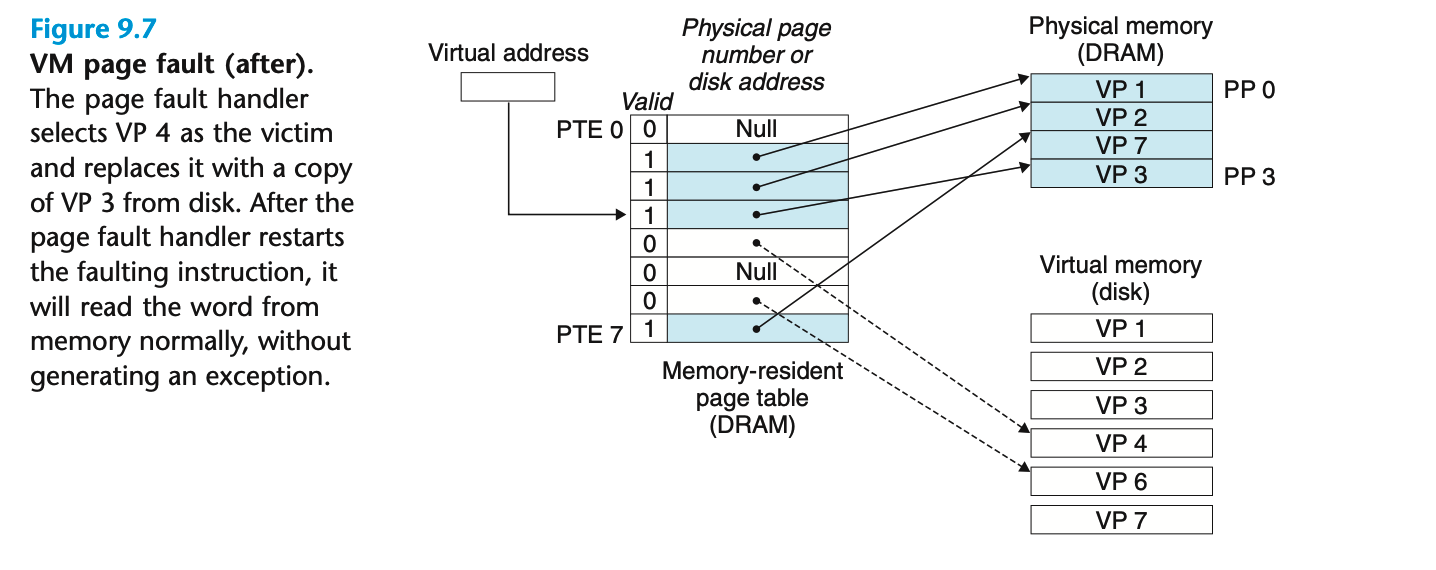
Next, the kernel copies VP 3 from disk to PP 3 in memory, updates PTE 3, and then returns. When the handler returns, it restarts the faulting instruction, which resends the faulting virtual address to the address translation hardware. But now, VP 3 is cached in main memory, and the page hit is handled normally by the address translation hardware. Figure 9.7 shows the state of our example page table after the page fault.
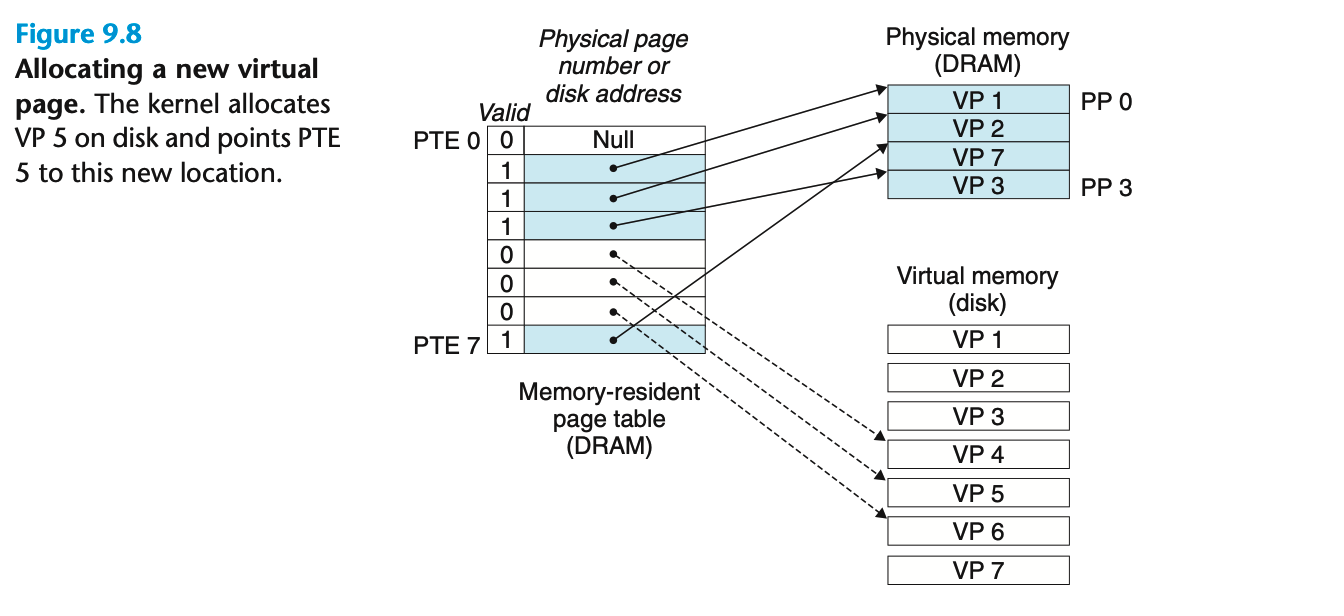
分配页面
操作系统分配一个新的虚拟页时对页表的影响(malloc的结果)
VP5的分配过程是在磁盘上创建空间,并且更新PTE5,使其指向磁盘上这个新创建的页面
虚拟内存作为内存管理的工具
操作系统为每个进程都提供了一个独立的页表,因而也就是一个独立的虚拟地址空间。
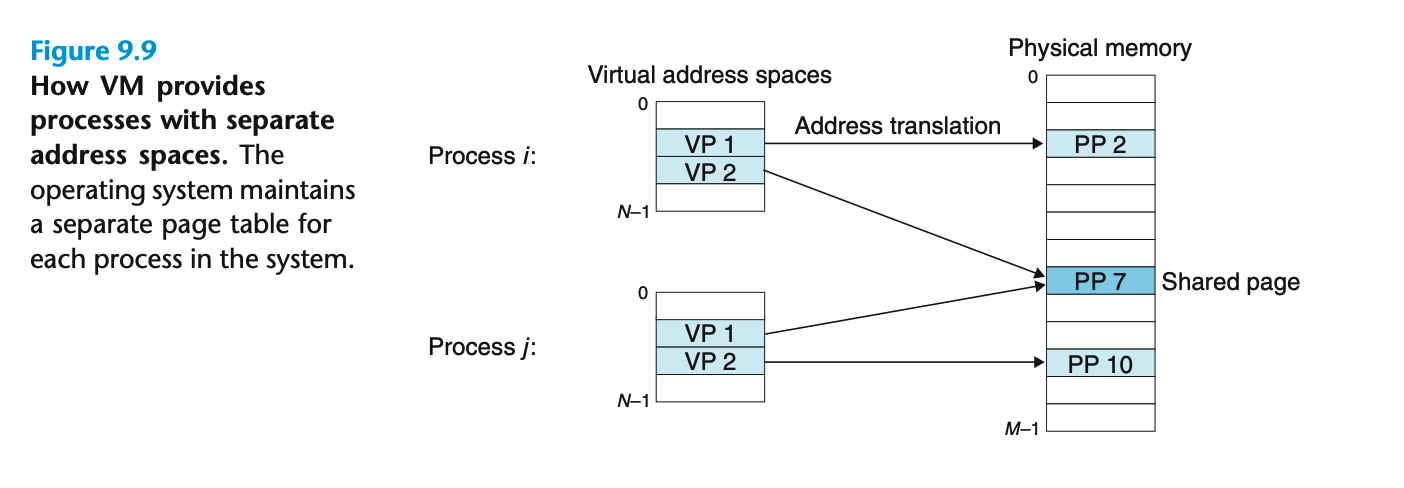
- 简化链接
- 简化加载
- 简化共享
- 简化内存分配
虚拟内存作为内存保护的工具
如何利用虚拟内存来实现用户对数据的读写权限控制呢?
在PTE上添加一些额外的许可位来控制对一个虚拟页面内容的访问:
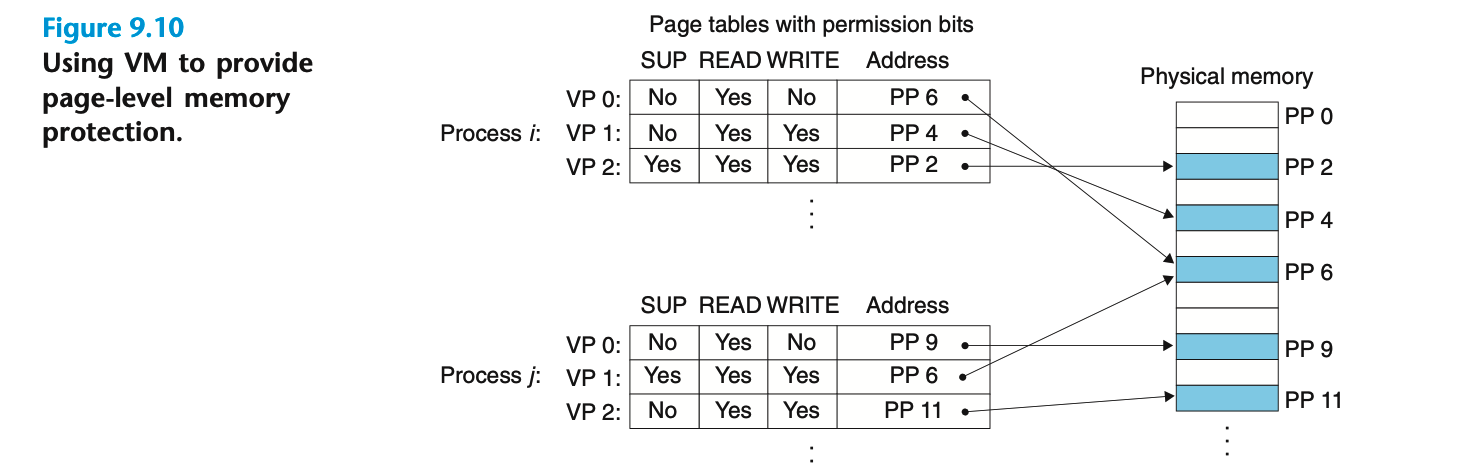
- SUP位:表示进程是否必须运行在内核(超级用户)模式下才能访问该页。运行在内核模式下的进程可以访问所有页面,而在用户模式下运行的进程只能访问SUP位为0的页面
- READ位:表示在可以访问该页面的情况下,是否能读
- WRITE位:表示在可以访问该页面的情况下,是否能写
地址翻译
下图展示了MMU如何利用页表来实现地址翻译
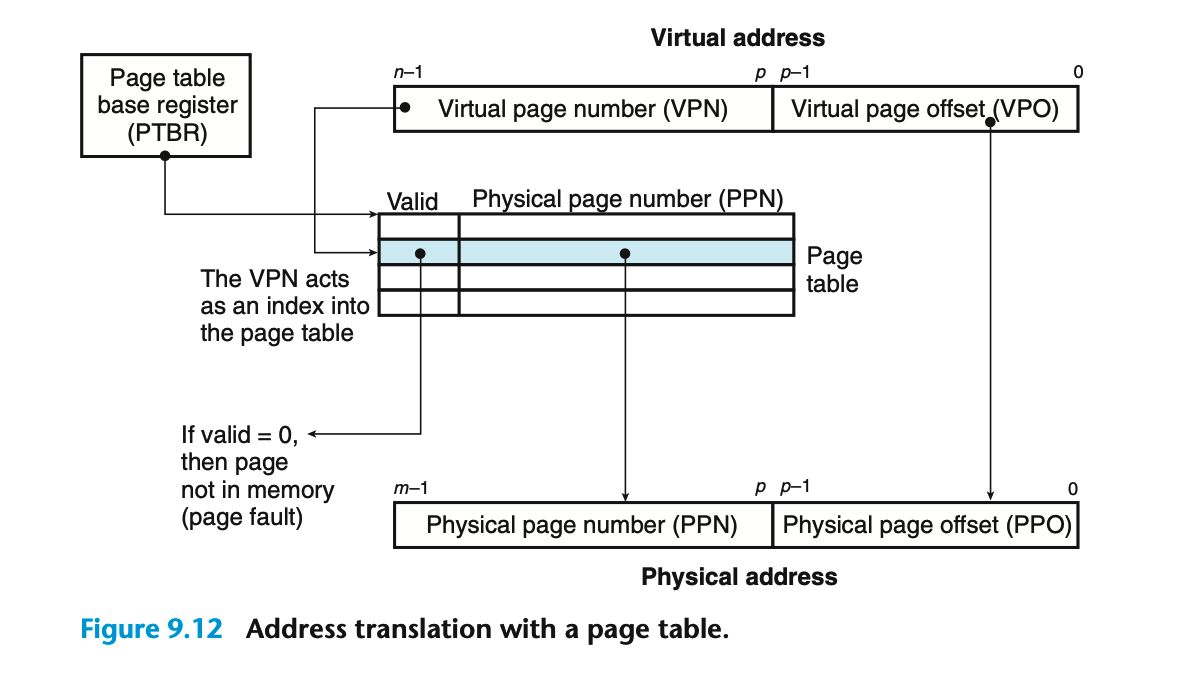
CPU中有一个控制寄存器——**页表基址寄存器(Page Table Base Register,PTBR)**指向当前页表(进程)。
-
解析虚拟地址和物理地址
n位的虚拟地址包括p位的虚拟页面偏移VPO,和(n-p)位的虚拟页号VPN,MMU利用VPN来选择适当的PTE,例如VPN0对应PTE0,VPN1选择PTE1,以此类推。将选中的PTE中的物理页号PPN和虚拟地址中的VPO串联起来,就是相应的物理地址PA。注意,这里因为VPO和PPO都是p位所以二者也是相同的。
-
CPU执行的步骤
-
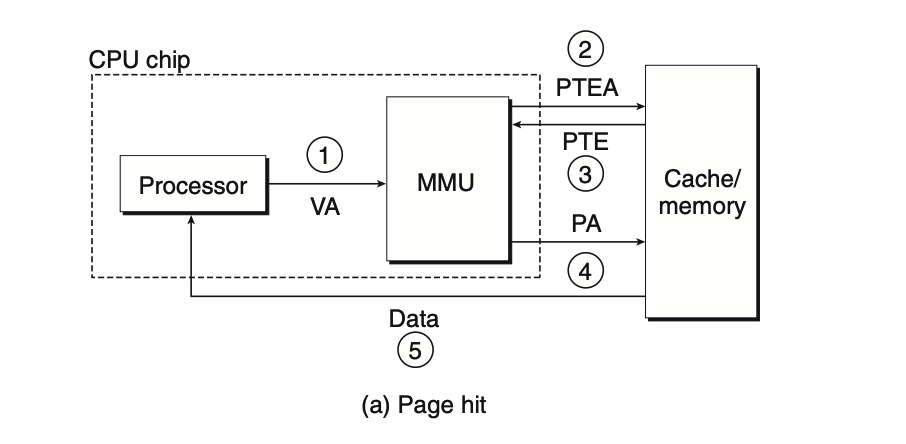
命中
- 处理器Processor生成一个虚拟地址VA发送给MMU
- MMU解析出对应PTE的地址发送给高速缓存/主存
- 高速缓存/主存把PTE返回给MMU
- MMU检查PTE的valid位为1,并联合VPO和PPN构造物理地址PA,转送给高速缓存/主存
- 高速缓存/主存将所请求的数传字返回给Processor
-
缺页
-
前三步和命中的情况是一样的
-
MMU检查PTE的valid位为0,MMU触发一次异常,控制传递给CPU的缺页处理程序
-
缺页处理程序根据替换算法来确定Victim Page,如果该Page已经被修改了,那么就写回到磁盘
-
缺页处理程序调入新的页面,并更新内存中的页表
-
控制传回引发异常的进程,再次执行导致缺页的指令,重复命中的流程
-
-
结合高速缓存和虚拟内存
-
结合的方式
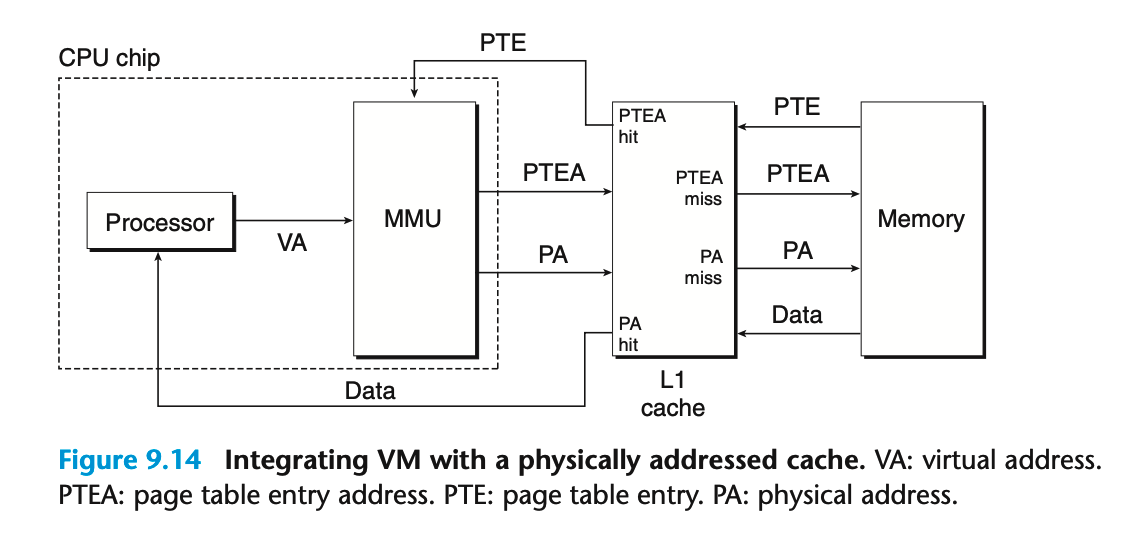
因为MMU的地址翻译需要频繁地从主存中读取页表,所以采取将部分页表条目存储在高速缓存SRAM中,以提高翻译效率
-
MMU如何访问SRAM
MMU访问主存DRAM是用的虚拟地址,那么访问SRAM,一般而言是用的物理地址。使用物理地址更为简单地使多个进程访问各自的页表和相同的虚拟页,不必再加一层虚拟地址转换,本末倒置
利用TLB加速地址翻译
在上面已经将SRAM与虚拟内存结合,将从主存中读取PTE的周期从几十上百下降到1或2个周期,但仍有许多系统试图消除这个周期。这些系统直接在MMU中增加了一个小型缓存,称为快表(Translation Lookaside Buffer,TLB)
-
TLB的结构
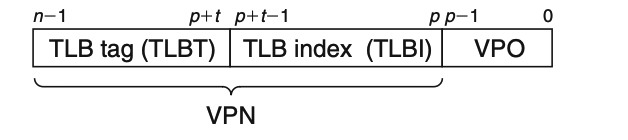
TLB是一个小的,虚拟地址的缓存,其中每一行都保存了一个PTE组成的块,TLB拥有很高的相联度。如上图所示,用于组选择和行匹配的字段是从虚拟地址中的虚拟页号VPN提取出来的。如果TLB有 T = 2 t T=2^t T=2t个组,那么TLB索引(TLBI)是由VPN的最低的t位组成的,而TLB标记(TLBT)则有VPN中剩下的位组成
-
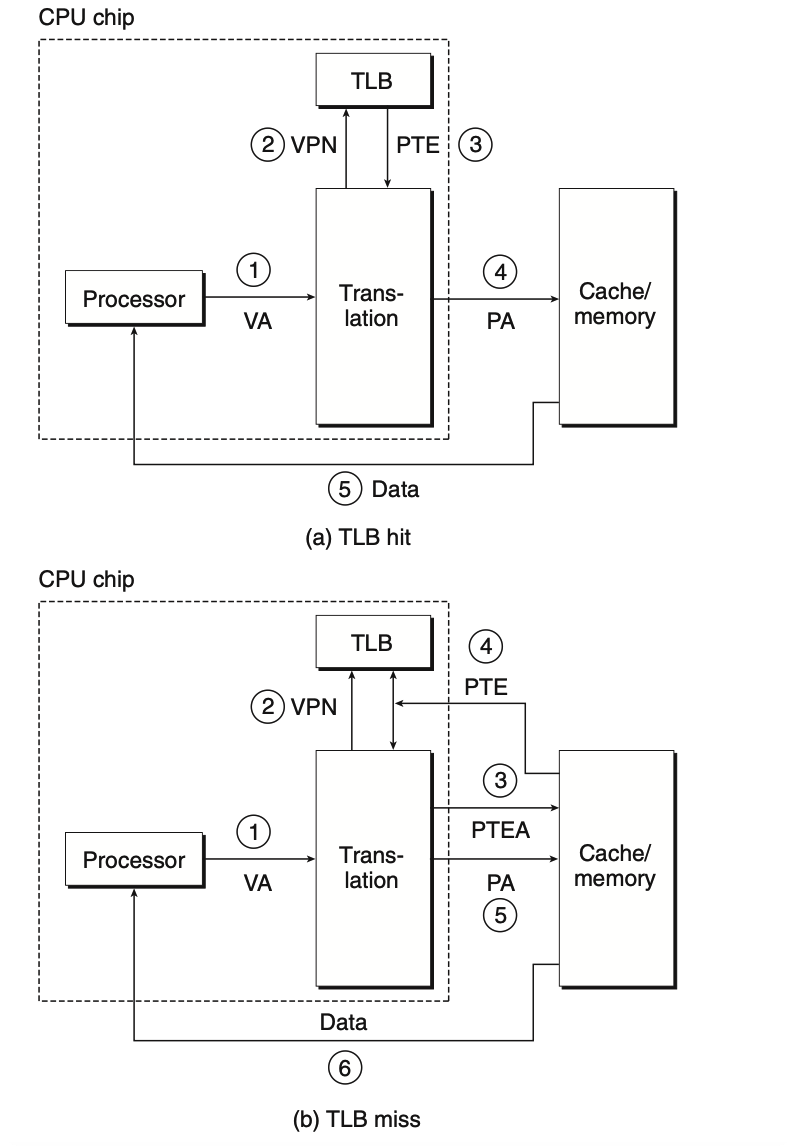
附加TLB后的地址翻译
- CPU产生一个虚拟地址
- MMU从TLB中取中相应的PTE
- MMU利用PTE中的PPN和VA中的VPO串联成物理地址PA,发送给高速缓存/主存
- 高速缓存/主存将所请求的数据字返回给CPU
增加了TLB后整个地址翻译的速度是非常快的,因为整个过程都是在MMU中完成
如果出现TLB miss的情况,MMU会从SRAM中取出相应的PTE,新的PTE存放在TLB中,可能会覆盖一个已经存在的PTE
多级页表
-
如果只有一级页表
对于32位的地址空间,4KB的页面和一个4字节的PTE,那么就需要总共 2 32 / ( 4 ∗ 2 10 ) = 2 20 = 1 M , 1 M ∗ 4 = 4 M 2^{32}/(4*2^{10})=2^{20}=1M, 1M*4=4M 232/(4∗210)=220=1M,1M∗4=4M的页表驻留在内存中,如果是64位问题会更复杂
-
二级页表
在32位下,我们构造的二级页表的第一级有1024个PTE,第一级的每个PTE对应1024个二级PTE,每个二级PTE对应一个4KB的页,也就是1024个一级PTE就能覆盖 2 10 ∗ 2 10 ∗ 4 K B = 4 G B 2^{10}*2^{10}*4KB=4GB 210∗210∗4KB=4GB的地址空间
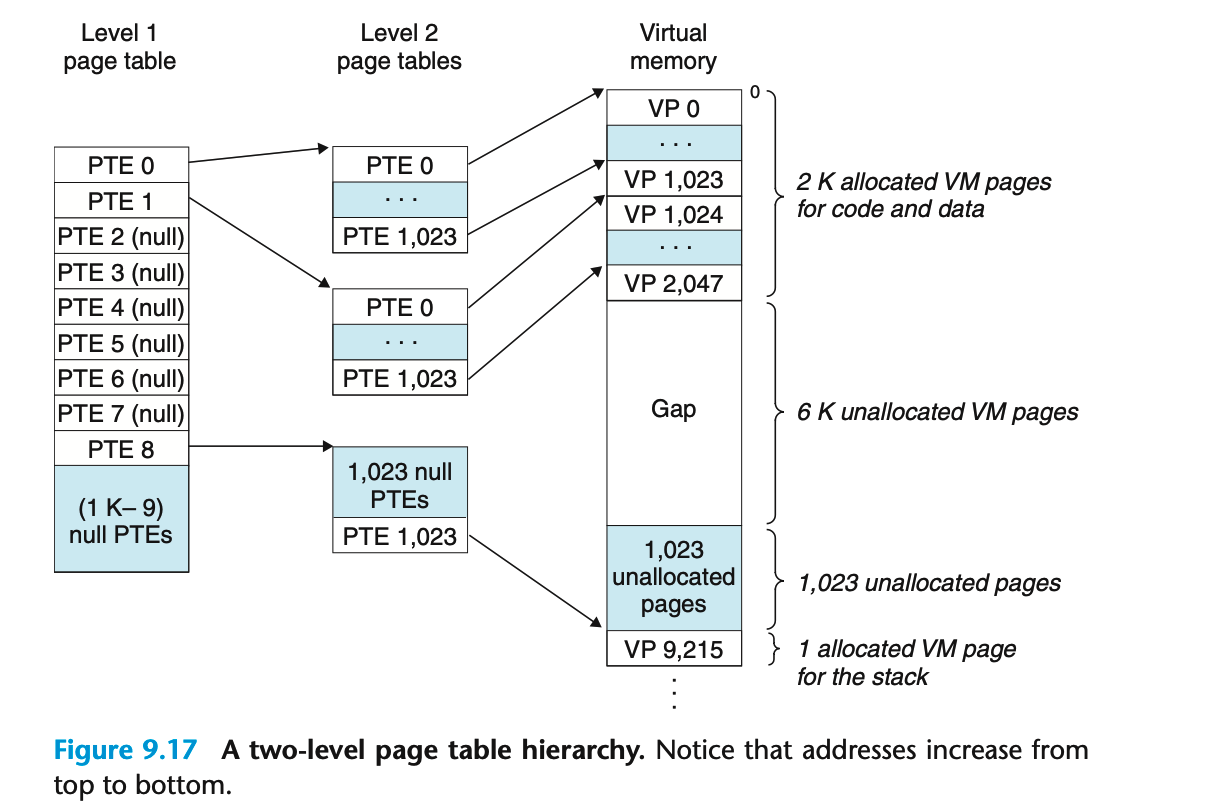
可能会有疑惑,一级1024个PTE,每个一级PTE还对应1024个PTE不也是1M个PTE和一级页表有什么区别呢?
实际上,如果一级页表是空的,相应的二级页表就根本不会存在,就像上图中的PTE2-7都是空的,也就没有相应的二级PTE,这就代表着巨大的潜在节约,因为对于一个程序而言,4GB的虚拟地址空间的大部分都是未分配的。第二,只有一级页面才总需要在主存中,虚拟内存系统可以在需要时创建、页面调入或调出二级页表,这就减少了主存的压力;只有最经常使用的二级页表才常驻主存中
-
k级页表
下图是常见的k级页表的地址翻译流程图
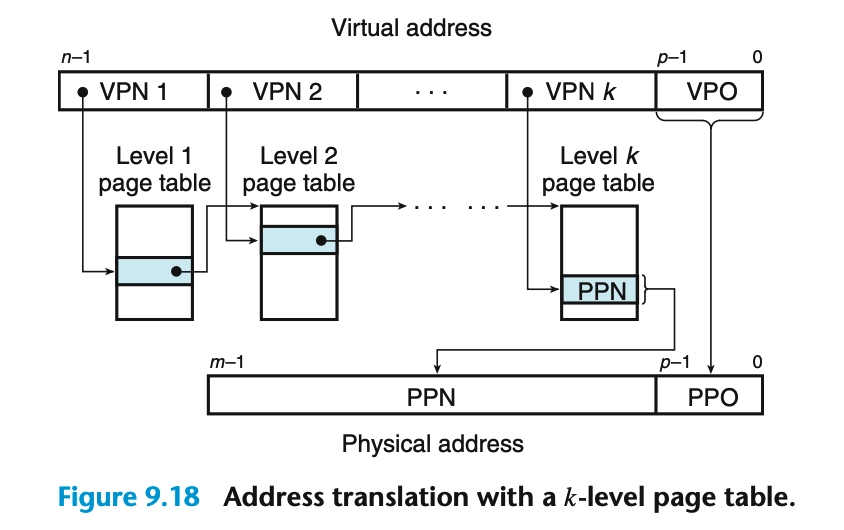
虚拟地址的虚拟页号VPN被划分成k个,每个VPN i i i 都是一个到第 i i i 级页表的索引,其中 1 ≤ i ≤ k 1 \leq i \leq k 1≤i≤k。第 j j j 级页表的每一个PTE, 1 ≤ j ≤ k − 1 1 \leq j \leq k-1 1≤j≤k−1,都指向 j + 1 j+1 j+1 级某个页表的基址。第 k k k 级页表中的每个PTE包含某个物理页面的PPN,或者一个磁盘块的地址。
为了构造物理地址,确定PPN,MMU必须访问k个PTE。这种情况下VPO和PPO也一样。访问k个PTE看上去成本会很高,然后TLB可以将不同层次的页表中常用的PTE都缓存起来,实际并不会比单级页表慢很多,但节约了大量的主存空间。
综合:端到端地址翻译实例
请直接翻看CSAPP3e P573-576(中文版)
整体流程:从给出的虚拟地址中提取VPN,从VPN中再提取TLBI和TLBT,去读取TLB,如果命中,将TLB返回的PPN和VPO结合即可;如果TLB没有命中,则要去主存中取出相应的PTE;之后根据缓存的组数行数和块大小,将物理地址拆分成CO、CI和CT,再从缓存中读取数据字。
参考
CSAPP