文章目录
- 前言
- 一、需求分析
- 1.功能需求
- 2.技术需求
- 二、流程分析
- 1.分析请求过程
- 2.分析代码编写过程
- 四、代码编写
前言
作为2020级入学的大学生,在疫情的笼罩下步入了大学的校门,到校第一件事就是接到了每日进行健康日报身体情况上报的通知,每日醒来第一件事就是打开微信,找到学校公众号平台—>找到健康日报入口—>选择相应的选项—>上报信息,看似非常简单的一件事难免会因为粗心遗忘掉,所以结合自身所学知识编写了一个自动健康上报机器人。从此只需在身体出现特殊情况的时候修改上报信息即可。写下本博客只为记录下编写插件时自己的思路,便于以后复习,也希望这个插件编写的思路可以帮助到对此感兴趣的同学。
声明:目前该健康日报系统已下线,该教程只为给大家提供编写该类型插件的思路,提高大家编程能力。
一、需求分析
1.功能需求
- 信息持久化(做一个可用系统这一点是必须的)
- 发送健康日报上报请求并做出判断
- 可以自行录入信息并可以选择性更改信息
2.技术需求
- Nonebot2(作为机器人后端)需掌握语法
- Go-cqhttp(作为机器人前端)了解接口即可
- Python爬虫知识
- 正则表达式(网页源码解析能力)
- Web前端页面分析能力
- 会用Charles或者小黄鸟等抓包工具
- 会连接数据库并编写SQL语句
- 熟练操作Linux系统
- 熟悉网络通信知识
二、流程分析
1.分析请求过程
找到健康日报上报系统主页
可以看到填写表单的最后有一个提交按钮,猜想模拟这个请求即可。于是可以使用抓包工具进行抓包并分析。这里我用的是花瓶,使用花瓶之前可以先配置一下SSL证书,不配置的话无法解析https请求。可以先导出你电脑的证书,然后配置给花瓶即可(网上教程一大堆)
模拟请求之后得到大概这样的包,由于目前该系统已下线,所以没有截到相应的健康上报请求。在之前的话,只要抓到这个网站发送的任意包就可以抓到健康上报请求包,然后分析表单信息找到网络接口,使用Python爬虫模拟网络请求即可。
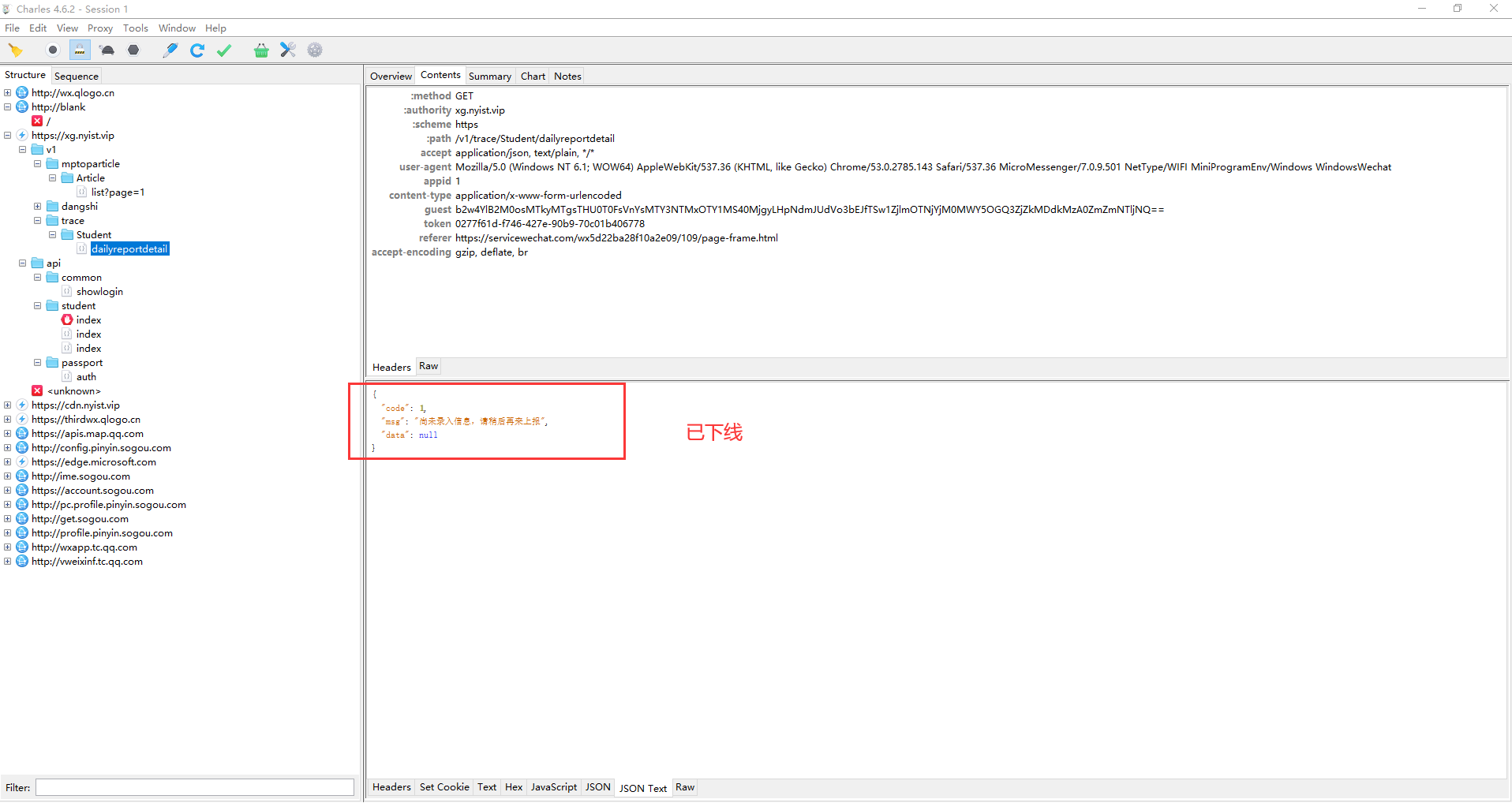
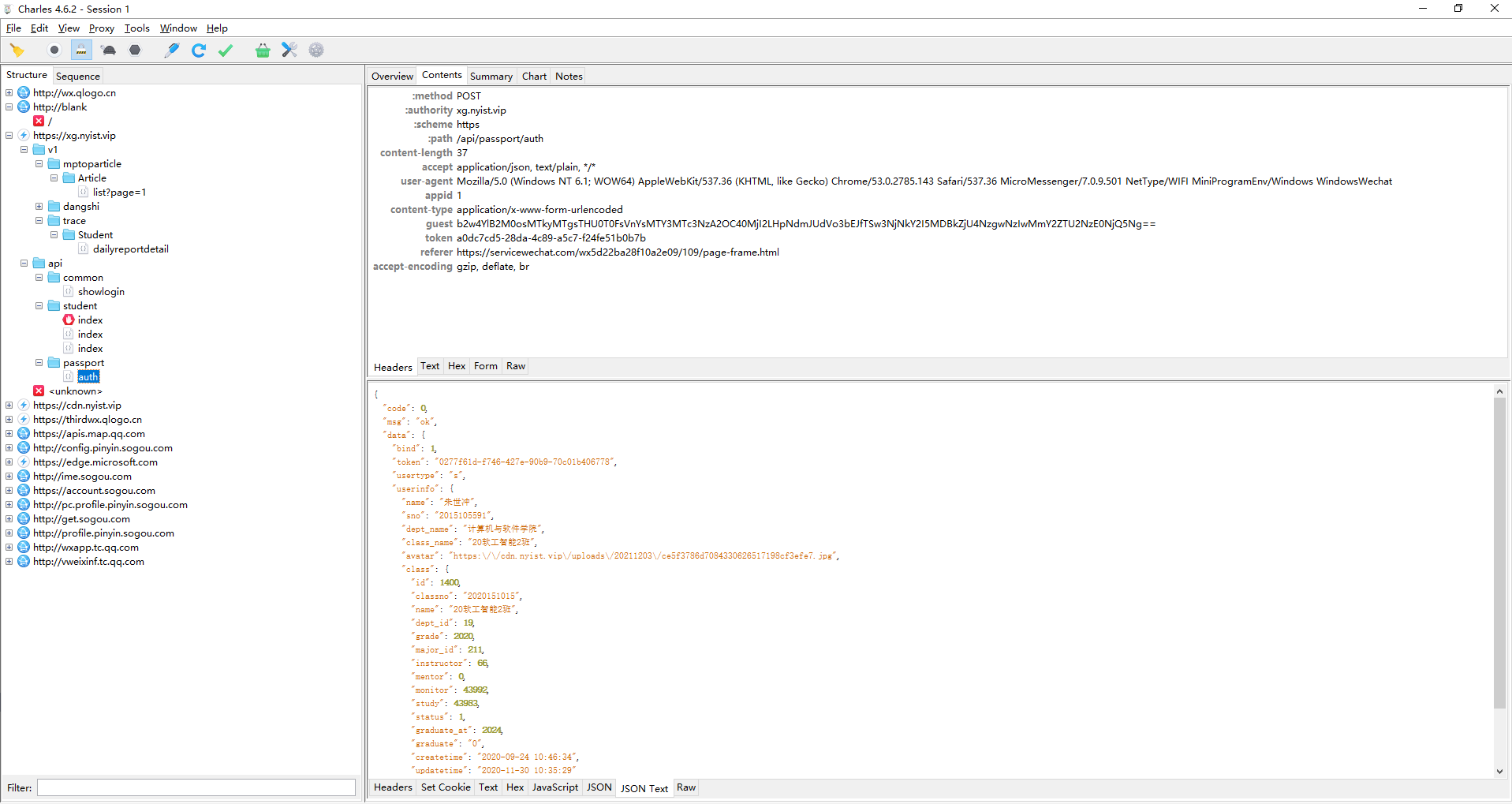
在分析完网络请求过程之后,身份信息持久化就成为了下一个问题,通过分析只能发现三串有用的信息
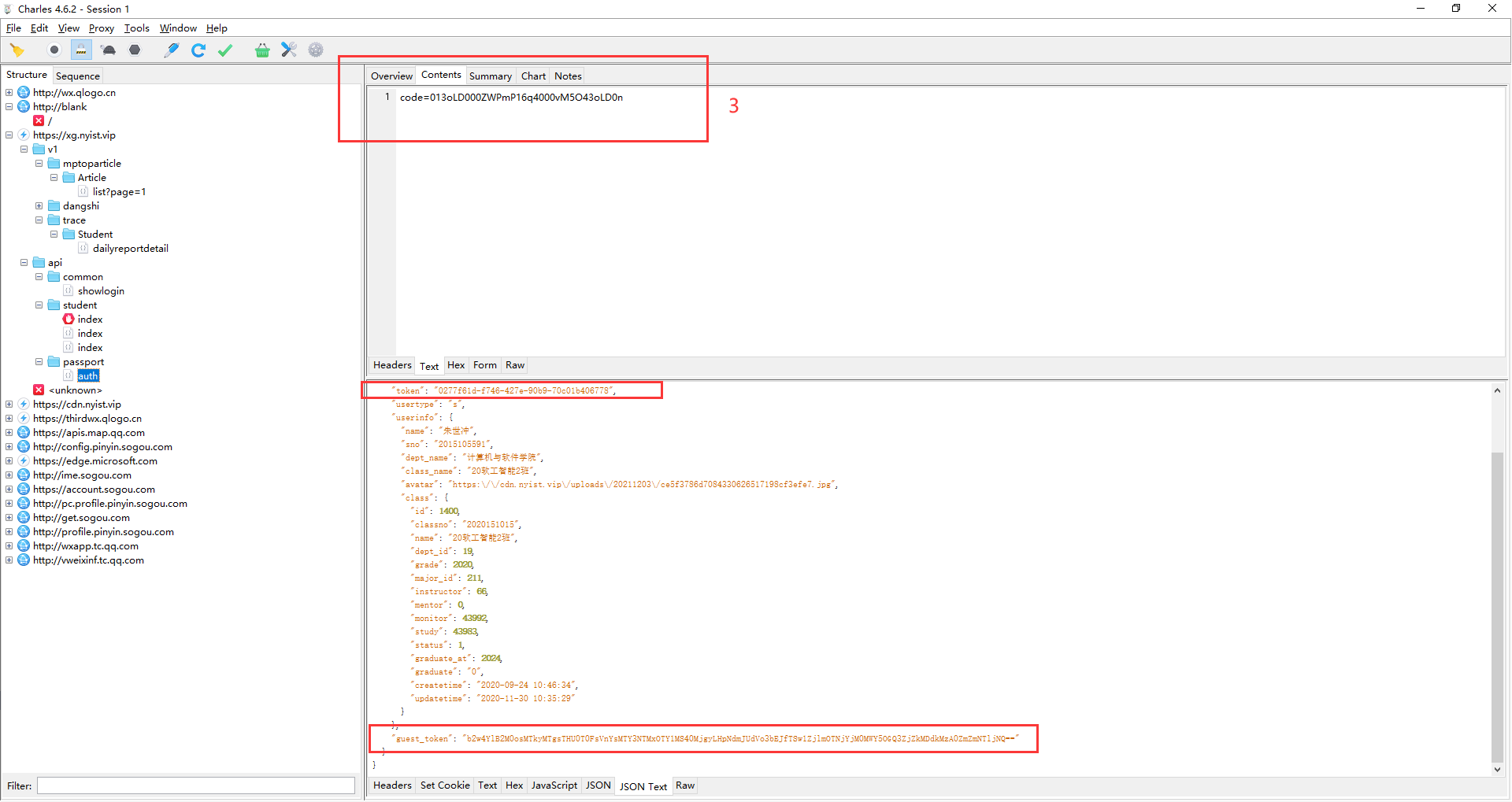
可以发现0277开头的token与b2开头的guest应该就是身份信息的必要字串,之前在写这个机器人时以为分析到这里就结束了,没想到这才是刚刚开始,后来发现这个token信息具有时效性,时效为48小时,并且guest也并不是一成不变的,于是便将分析重心放到了如何获取guest与token上。
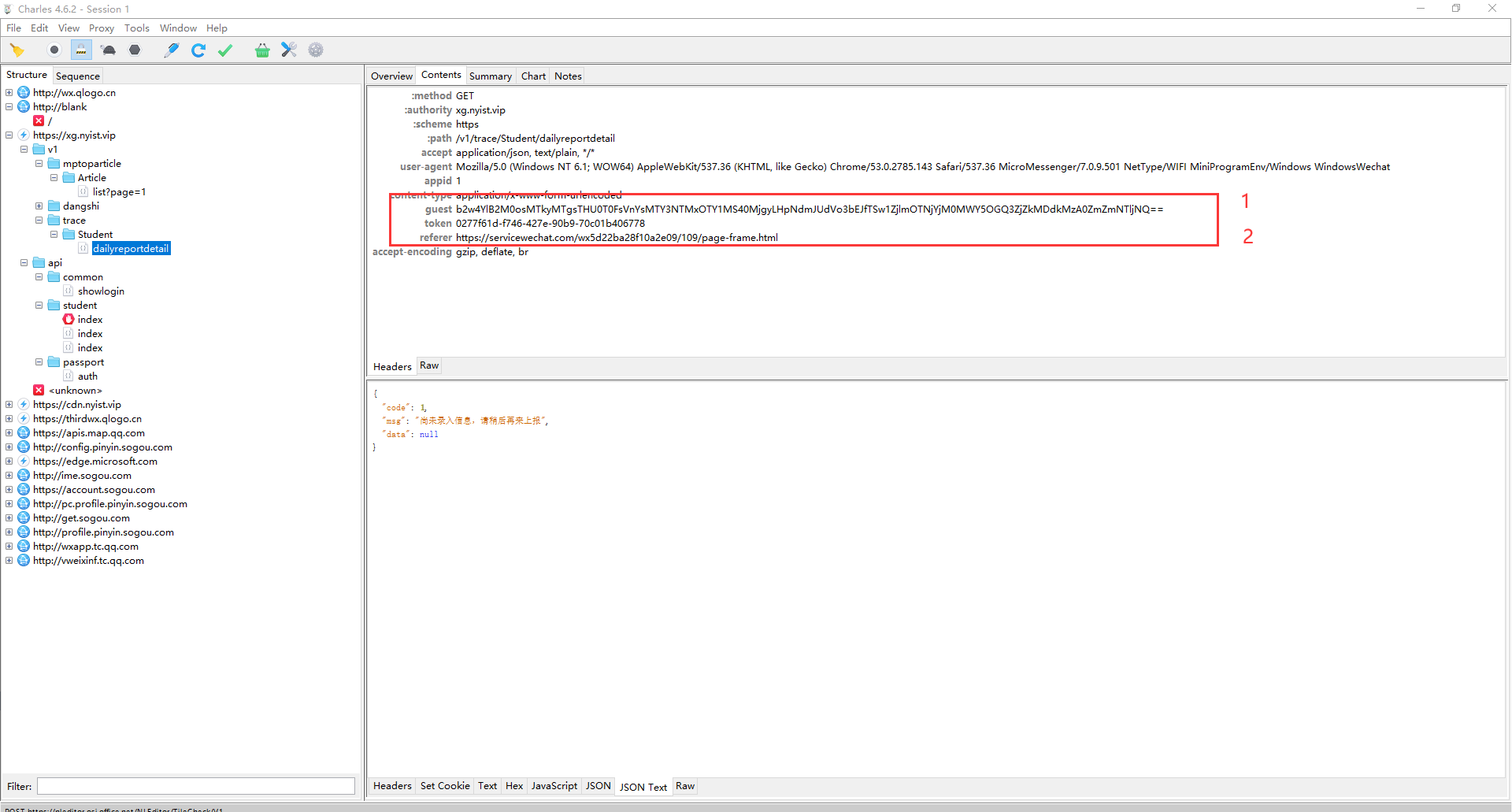
由于该系统开发时我并没有参与其中,所以许多细节均需要自己分析,在愁眉苦脸分析几天如何获取guest与token未果后,发现了只要token过期,就会向以下接口发送请求,这仿佛使我找到了突破口,还没来的及高兴发现这个请求携带的code,我并不会伪造,于是又在此阶段停留了好几天。
偶然一天又进行分析的时候发现,在请求时官网的域名较为熟悉于是抱着试一试的心态打开看看,没想到直接就是这个好奇心解决了根本问题。
打开该域名之后确实进到了一个Web网站。
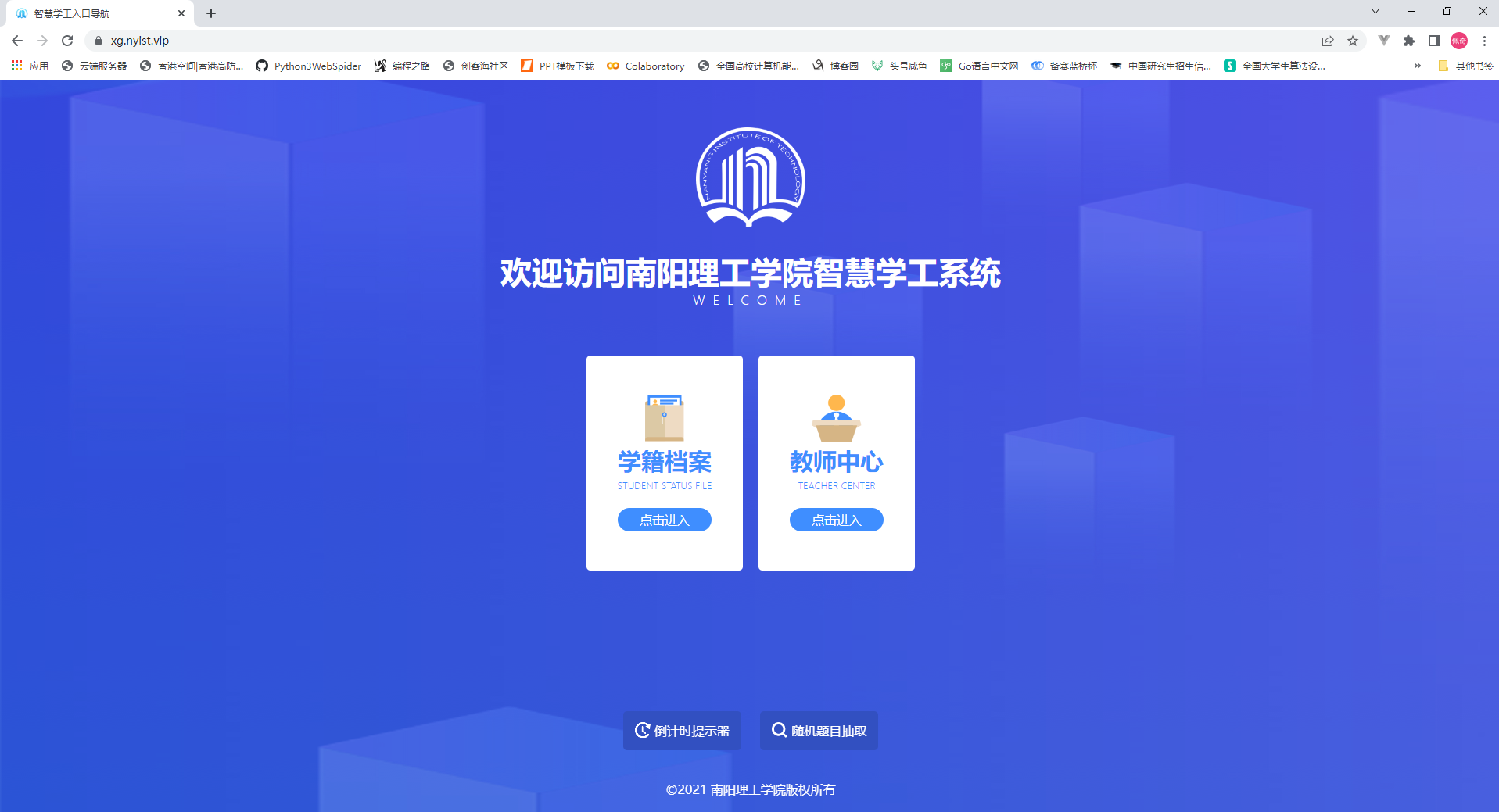
于是猜想这个网站上可不可以进行健康日报的上报?事实证明是可以的,我登录该网站后,利用该网站的身份验证信息SESSIONID与stoken成功进行了健康日报的上报,这又使我看到了希望。于是接下来开始分析,如何模拟登录该网站,如何将网站的session信息保活!于是我进行了以下分析:
请求主页,想要获取二维码,扫描二维码之后就可以获取到用户的token信息

获取到二维码
格式是base64的,因为这个格式在传输过程中可以加快速度(只需后端生成,前端展示即可)
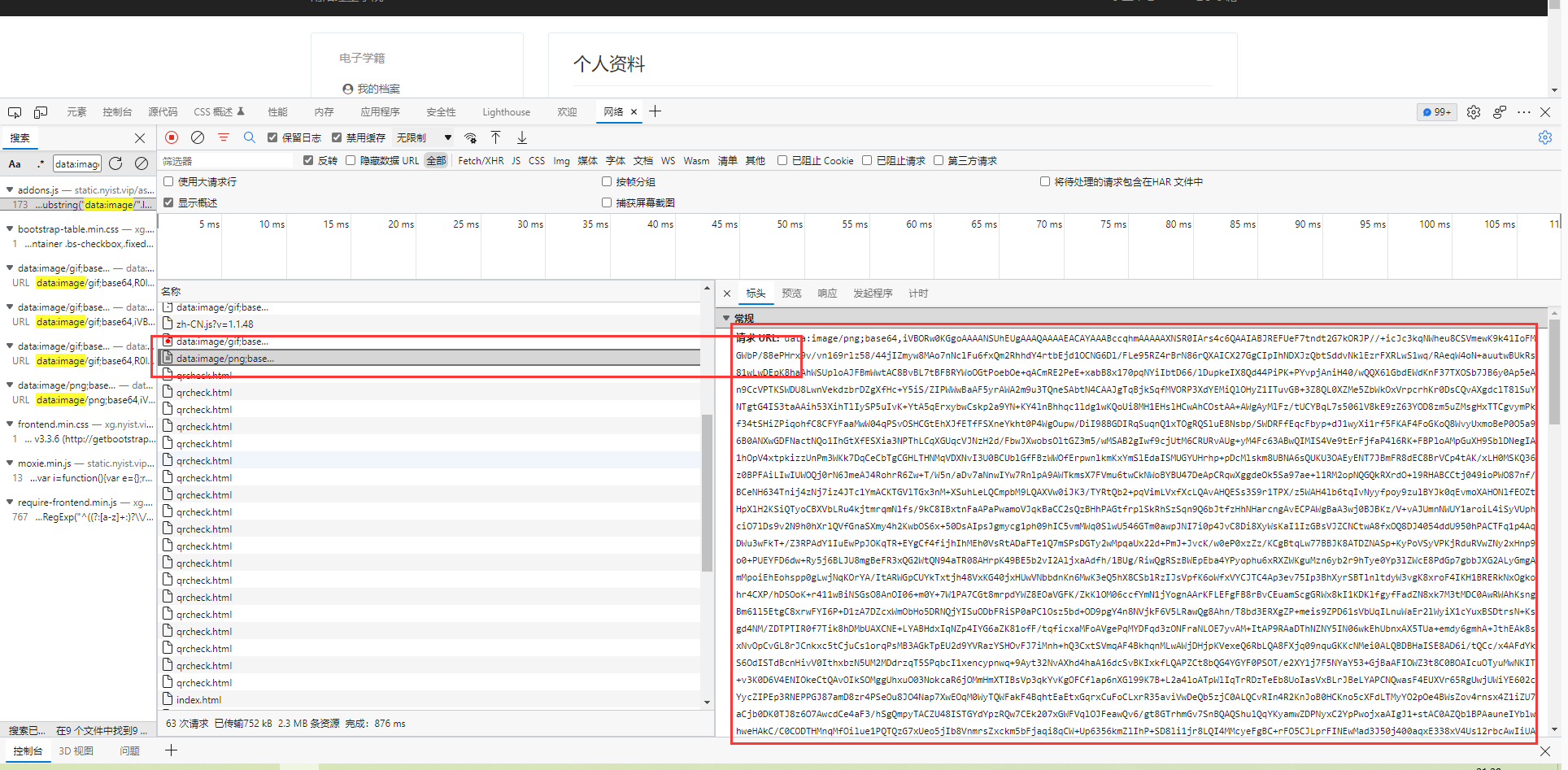
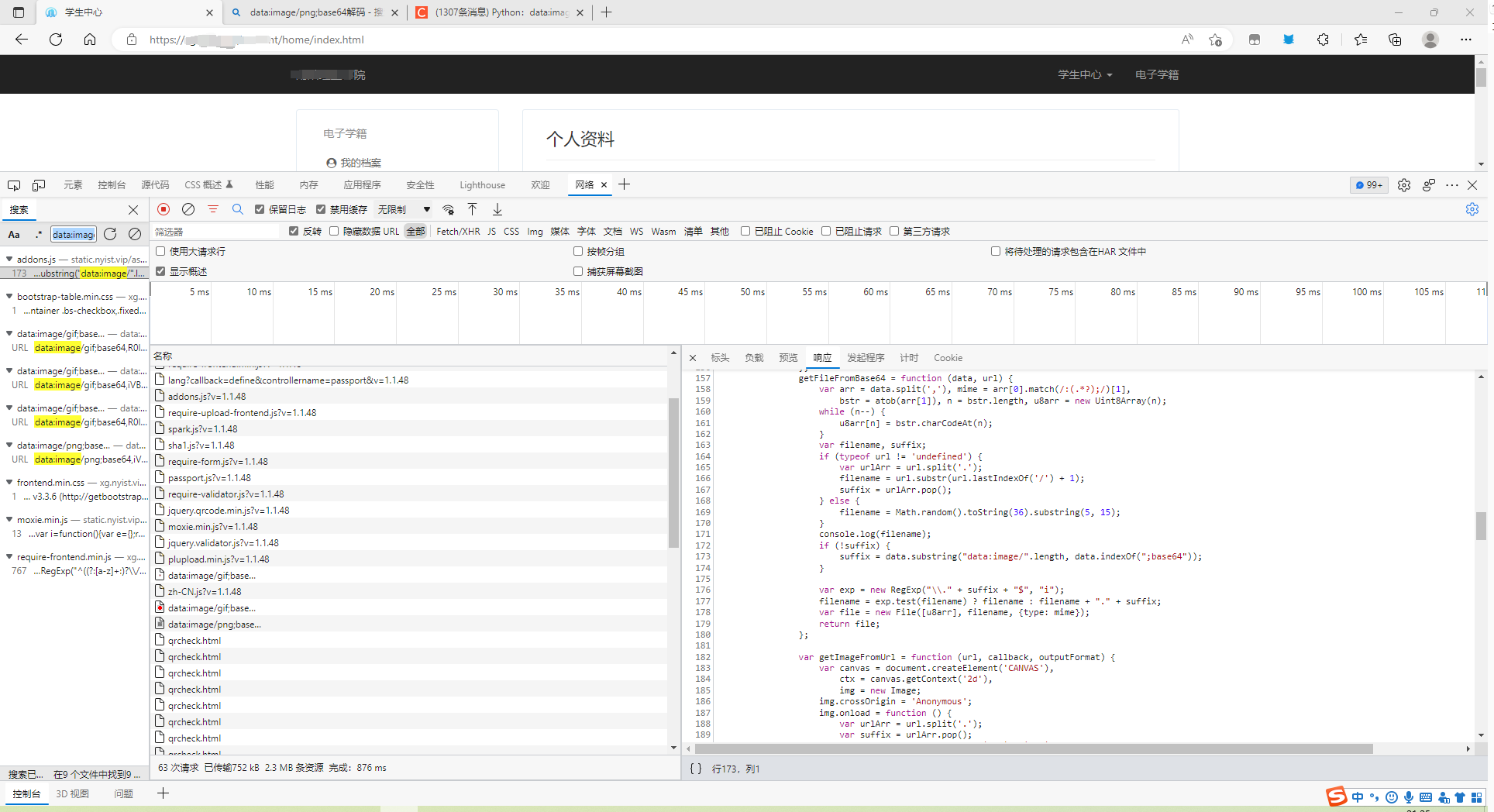

到此二维码可以解析出来,但是并不知道二维码的来源,于是可以追根溯源。只要找到二维码的来源就可大工告成。
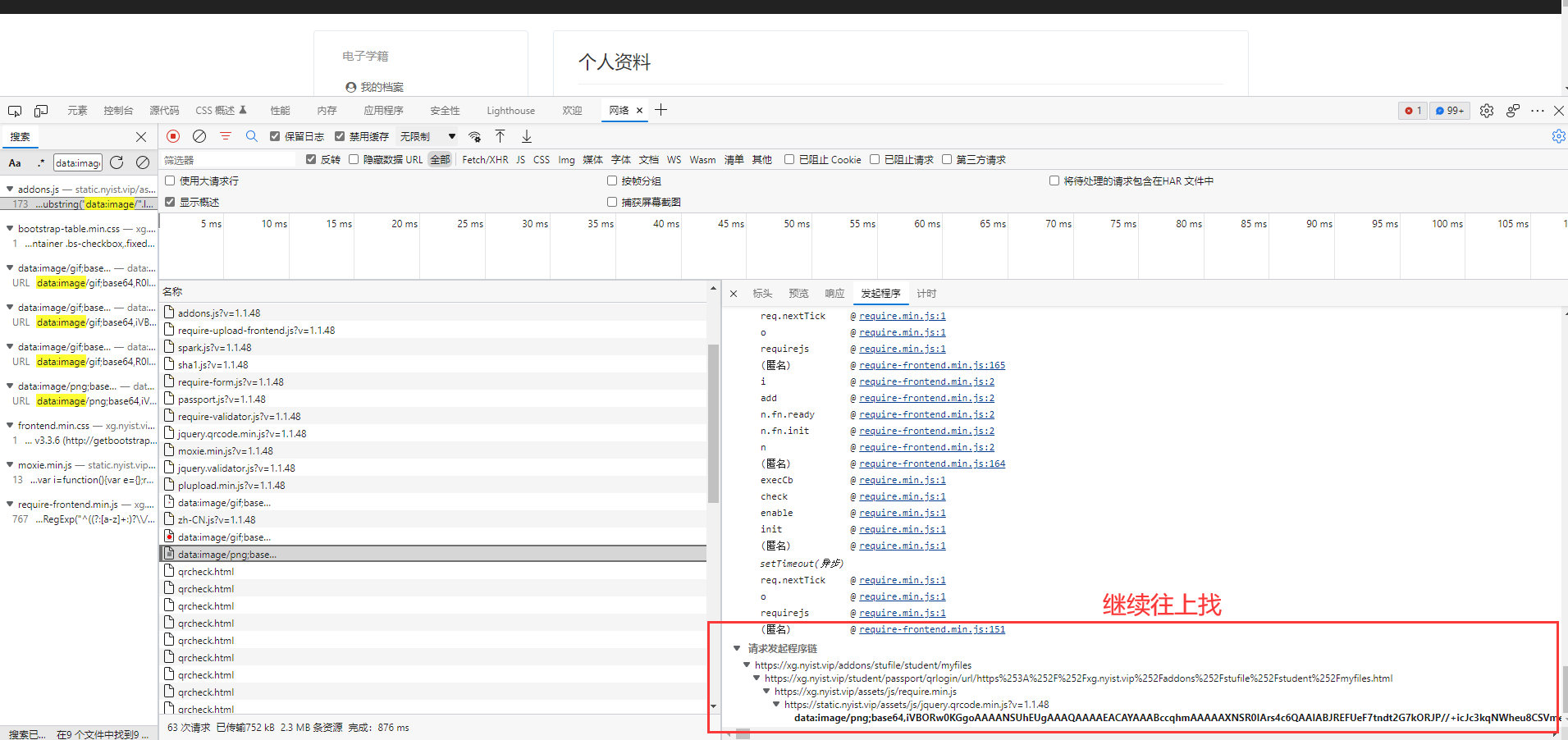
经过分析终于在网页中找到了相应的url
https://xg.nyist.vip/student/passport/qrscan/uuid/c4420d97-a52a-4f40-8b7e-9bf851bc7d46-559d04c3c380b5b0a7a5e281e1a141ff.html
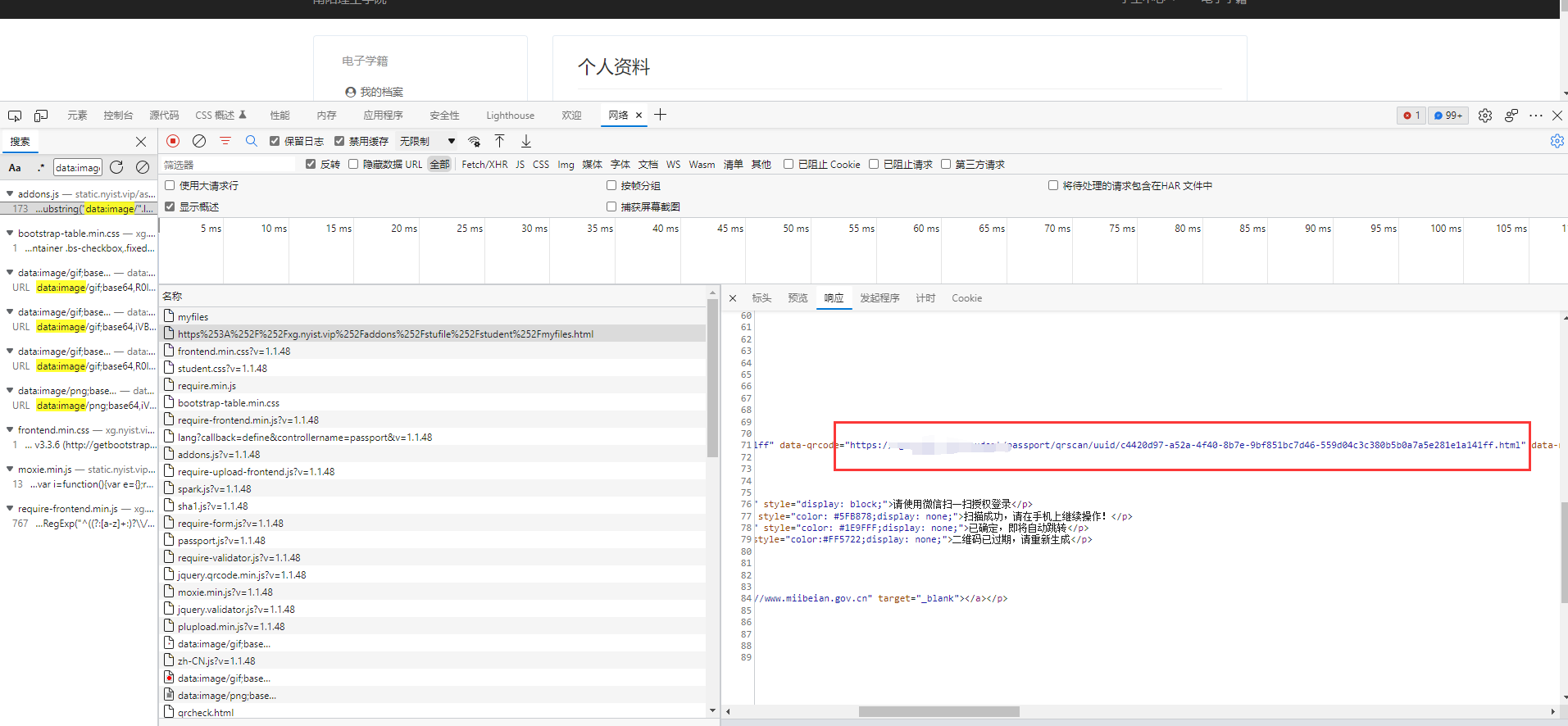

轮询、判断用户有没有扫码成功。
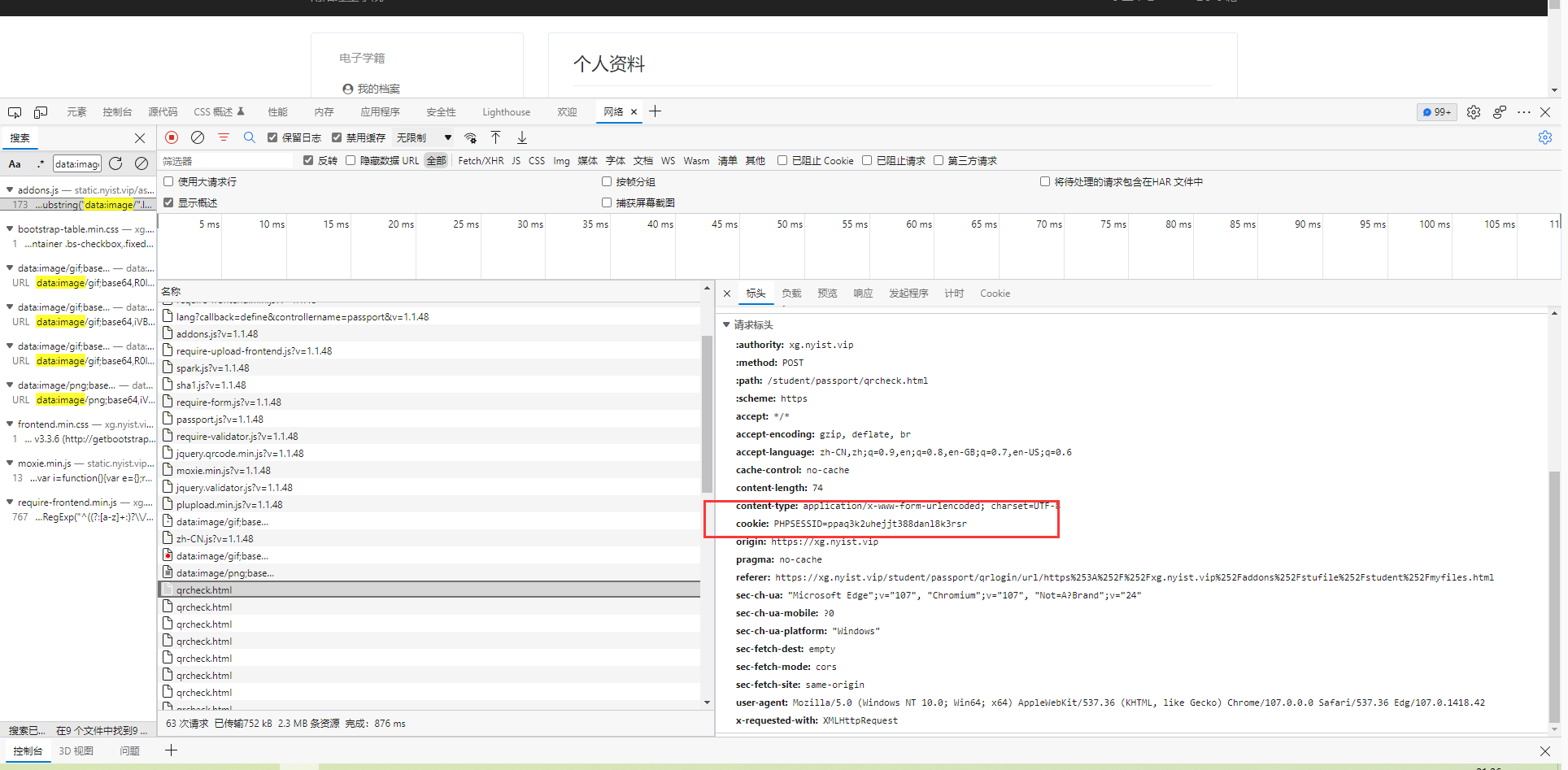
轮询成功、也就是用户成功扫码可以发现轮询成功之后会收到用户的身份信息。(可以进行验证,将获取到的字串复制到一个新的浏览器,然后刷新,看是否进入了个人的主页)
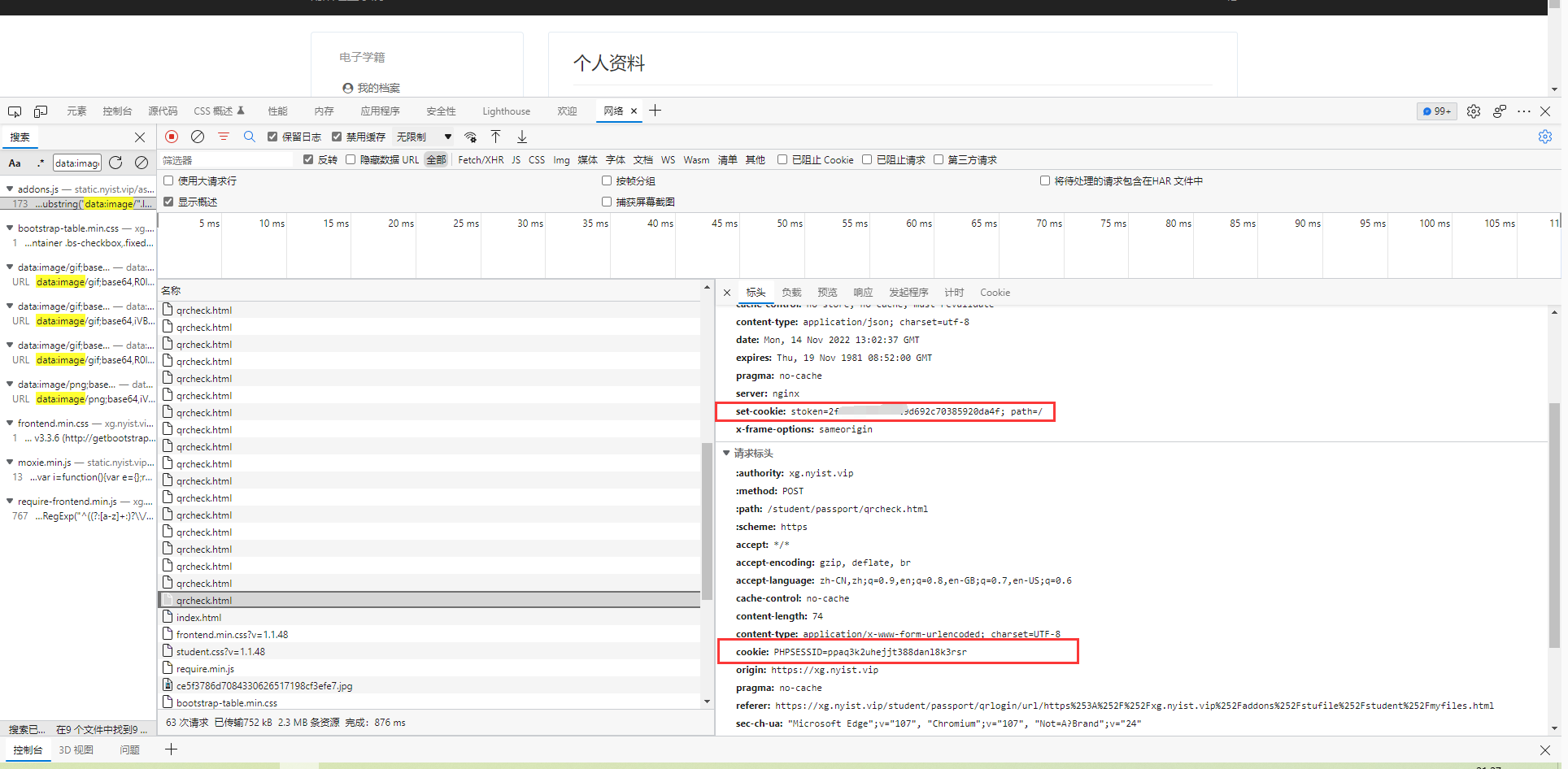
爬虫思路
请求https://xg.nyist.vip/student/passport/qrlogin/url/https%253A%252F%252Fxg.nyist.vip%252Faddons%252Fstufile%252Fstudent%252Fmyfiles.html
从页面中解析出一个uuid,大概uuid会与二维码的生成有关。
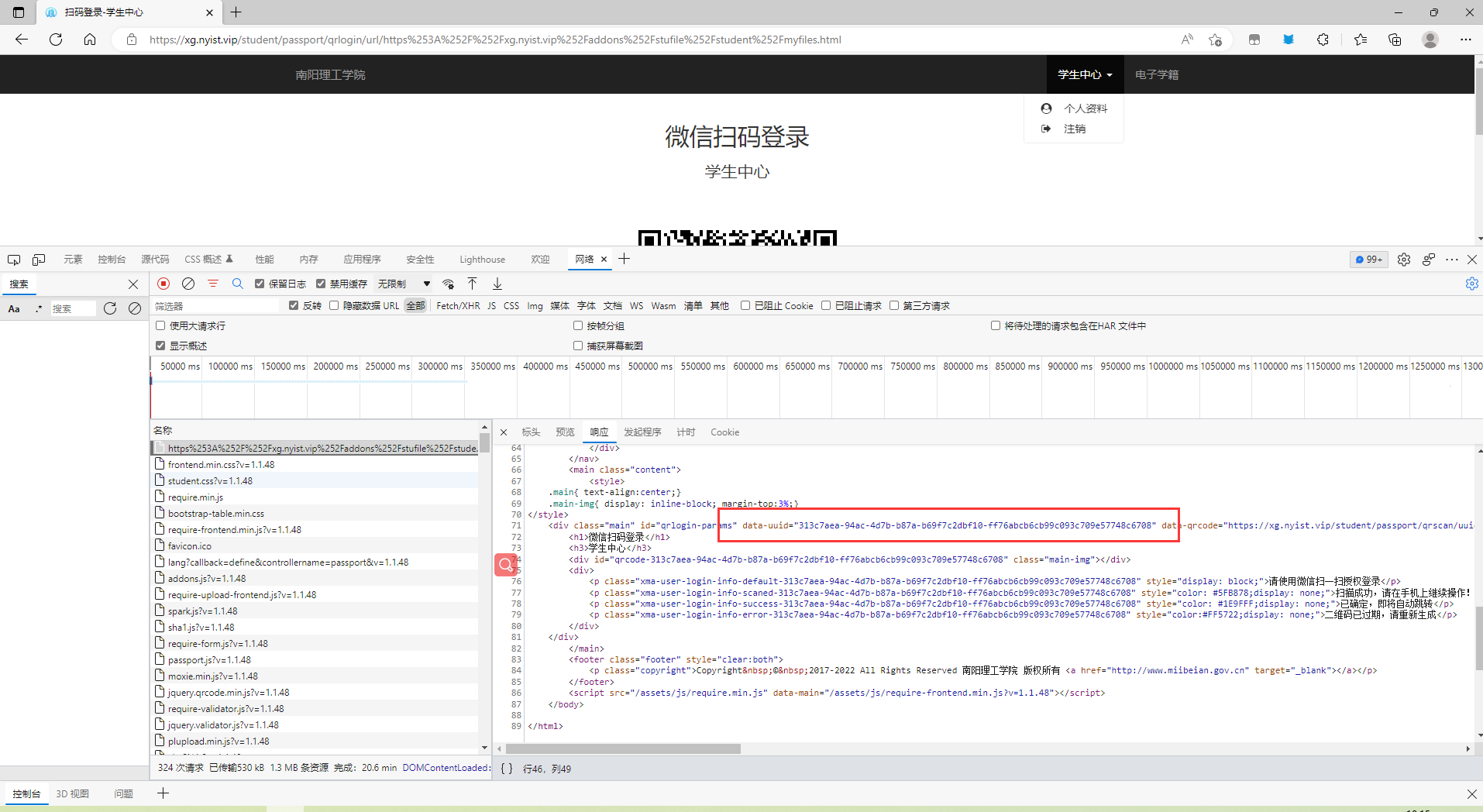
还有另一种方式就是直接通过uuid生成二维码,只需爬取页面中生成的uuid即可(二维码是后期渲染出来的,如果直接抓取下来会阻碍程序执行效率),显然这种方法是可行的,通过python的qrcode库,可以直接生成一个一毛一样的二维码。到这里也就明白了如何模拟登录,如何获取用户信息。接下来我,我们要解决的就是如何将SESSIONID与stoken信息进行保活(因为SESSIONID与stoken是绑定在一起的,并且具有时效性)。
这个工作看似简简单单,实际上不怎么好想,非常的考验Web网站开发能力,在我绞尽脑汁几天之后,我一个专门学Web的同学给我出了一个主意,像这种网站一直处于登录状态的话就不会掉线,一旦掉线信息可能会丢失,你只需要每隔一段时间请求一下该网站的页面即可。当然这也是可行的,至此这个机器人系统整体流程已经分析完,接下来就可以着手代码了。
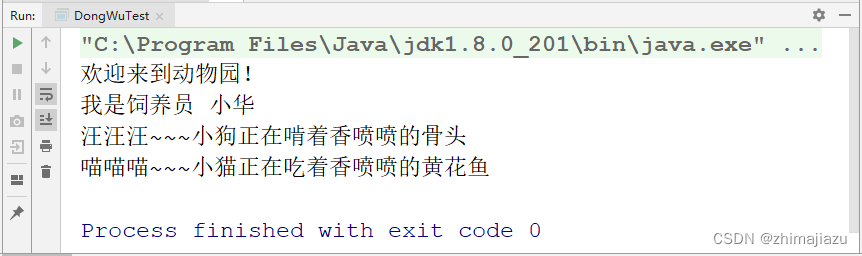
以下是机器人运行日志与效果图!

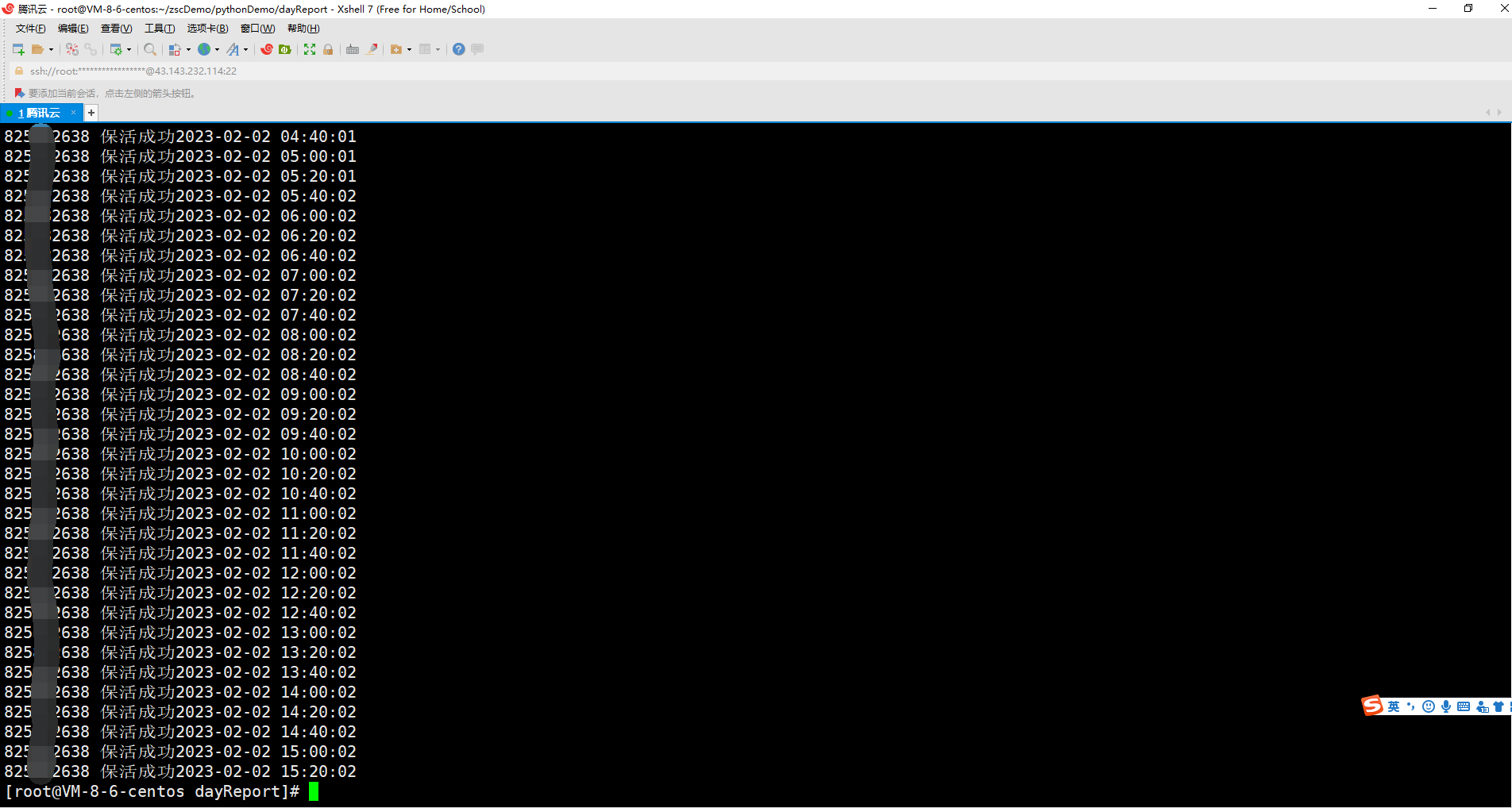
定时执行保活插件+每日执行健康日报上报插件!

2.分析代码编写过程
整体可以总结为以下流程:
- 1.编写Nonebot2与go-cqhttp机器人
- 2.编写爬虫插件
- 3.编写用户信息持久化代码
- 4.编写身份信息保活代码
- 5.云端部署
四、代码编写
Nonebot2插件:
# 处理健康日报信息更新等逻辑
from nonebot.adapters import Bot, Event
from nonebot.plugin import on_keyword
from nonebot.adapters.onebot.v11 import MessageSegment
from .funcStore import *
from nonebot.params import CommandArg, ArgPlainText
# 查询这个插件有什么功能(本插件合集第一个功能)
hdmenu = on_keyword({"健康日报菜单"},priority=50)
@hdmenu.handle()
async def hd_menu(bot: Bot, event: Event):
message='''欢迎使用本健康日报上报系统!
本系统有以下功能:
1.添加个人信息(QQ号为唯一标识)命令为:/健康日报 增
2.清除个人信息(终止打卡)命令为:命令为:/健康日报 删
打卡时表单填写均为学校地址,状态为在校!
不做任何盈利行为,各位身体不适请及时更新打卡状态!
如想在家打卡请联系管理员,更新位置信息及表单信息!
'''
await hdmenu.send(message)
# 增加用户信息(本插件合集第二个功能)
hdadd=on_keyword({"/健康日报 增"},priority=50)
@hdadd.handle()
async def hd_add_func(bot: Bot, event: Event):
# 二维码保存地址
qrcodeSave = "C:/Users/123/PycharmProjects/pyBot/GoCqhttp/data/images/"
# nyist.vip扫码登录时链接
url = "https://xg.nyist.vip/student/passport/qrlogin/url/https%253A%252F%252Fxg.nyist.vip%252Faddons%252Fstufile%252Fstudent%252Fmyfiles.html"
# 用户信息
cookie={
# session ID
'PHPSESSID': '',
# 微信授权成功获取的用户唯一标识
'stoken': ''
}
response = requests.get(url)
# SESSION ID 服务器创建会话的唯一标志
PHPSESSID = re.findall("PHPSESSID=(.*?);", str(response.headers))[0]
cookie['PHPSESSID']=PHPSESSID
# QRcodeuuid 信息用于获取 qrcode 的检测结果
QRcodeuuid = re.findall("data-uuid=\"(.*?)\"", str(response.text))[0]
# 获取二维码链接
url = re.findall("data-qrcode=\"(.*?)\"", str(response.text))[0]
qrcodeSave+=QRcodeuuid[:35]
qrcodeSave+=".png"
print(QRcodeuuid,url)
# 二维码生成(实际上二维码与链接等价,由链接生成一个二维码)
img = qrcode.make(url)
# 将二维码保存起来
img.save(qrcodeSave)
await hdadd.send("请用绑定有学生信息的微信扫码授权!"+MessageSegment.image(QRcodeuuid[:35]+".png"))
# 轮询刚刚创建的会话,等待捕获登录成功消息
status,stoken=check_link(PHPSESSID,QRcodeuuid)
if status==0:
cookie["stoken"]=stoken['stoken']
# 如果存在就更新,如果不存在就插入(由于数据库在进行插入时有锁,为了能够传递信息,设置了一个标志位)
flag=False
try:
saveCookies(cookie,event.get_user_id())
except sqlite3.IntegrityError:
flag=True
if flag:
updateCookies(cookie, event.get_user_id())
await hdadd.send("保存成功!")
else:
await hdadd.send("请重新获取二维码!")
# 清除用户信息(本插件合集第三个功能)
hddel=on_keyword({"/健康日报 删"})
@hddel.handle()
async def hd_del_func(bot: Bot, event: Event):
pass
# 二次确认
@hddel.got("flag", prompt="确定终止回复 1!")
async def handle_item(event: Event,flag: str = ArgPlainText("flag")):
if flag=="1":
deleteCookies(event.get_user_id())
await hddel.finish("信息清除成功!")
else:
await hddel.finish("行动终止!")
函数库:
# 函数库,存放健康日报用到的各种函数
from datetime import datetime
from pprint import pprint
import sqlite3
import requests
import re
import qrcode
import time
""" 本函数的作用是:通过轮询获取到用户的stoken信息"""
def check_link(PHPSESSID,QRcodeuuid):
""" PHPSESSID 为初次访问qrcode url时获得,登录成功后用户信息将于其进行关联"""
try:
# 成功状态
"""{"code":0,"msg":"","time":1669872758,"data":{"status":3,"msg":"授权登录成功"}}"""
# 失败状态
"""{"code":0,"msg":"","time":1669872942,"data":{"status":4,"msg":"二维码已过期, 请重新生成二维码扫码登录"}}"""
# 初始状态 二维码已过期
status = 4
# 开始时间
st = datetime.now()
# 轮询
while status != 3:
# 等待登录暂停时间
time.sleep(5)
# 请求需要携带的信息
cookies = {'PHPSESSID': PHPSESSID}
data = {'uuid': QRcodeuuid}
headers = {
"x-requested-with": "XMLHttpRequest"
}
# 轮询的url
url = "https://xg.nyist.vip/student/passport/qrcheck.html"
# 检查登录状态
response = requests.post(url=url, headers=headers, cookies=cookies, data=data)
# 登录检查的状态
status = int(re.findall("\"status\":(.*?),", response.text)[0])
duringtime = (datetime.now() - st).seconds
if status == 3:
Cookies = response.cookies.get_dict()
status=0
break
if duringtime > 1500: # 请求时间大于 3 分钟, 二维码过期
Cookies={}
status=-1
break
# 返回检查成功后的用户登录Cookies
return status,Cookies
except Exception as e:
# 返回错误信息
return e, Cookies
""" 本函数的作用是:通过sqlite3将用户cookie信息于qq号存储起来"""
def saveCookies(Cookies, QQ):
""" Cookies 为字典,可为 Qrcheck 的范围值"""
# 如果文件不存在,会在当前目录创建:
conn = sqlite3.connect('dayReport.db')
# 创建一个Cursor:
cursor = conn.cursor()
# 执行插入操作
sql = 'insert into healthydaily values( "{}", 0, "{}","{}", 0);'.format(QQ,Cookies["stoken"],Cookies["PHPSESSID"])
cursor.execute(sql)
# 关闭Cursor:
cursor.close()
# 提交事务:
conn.commit()
# 关闭Connection:
conn.close()
""" 本函数的作用是:通过sqlite3将用户cookie信息于qq号存储起来"""
def updateCookies(Cookies, QQ):
""" Cookies 为字典,可为 Qrcheck 的范围值"""
# 如果文件不存在,会在当前目录创建:
conn = sqlite3.connect('dayReport.db')
# 创建一个Cursor:
cursor = conn.cursor()
# 执行插入操作
pprint(Cookies)
cursor.execute(f'''update healthydaily set stoken='{Cookies["stoken"]}',PHPSESSID='{Cookies["PHPSESSID"]}' where QQ='{QQ}';''')
# 关闭Cursor:
cursor.close()
# 提交事务:
conn.commit()
# 关闭Connection:
conn.close()
def deleteCookies(QQ):
""" Cookies 为字典,可为 Qrcheck 的范围值"""
# 如果文件不存在,会在当前目录创建:
conn = sqlite3.connect('dayReport.db')
# 创建一个Cursor:
cursor = conn.cursor()
cursor.execute(f'''delete from healthydaily where QQ="{QQ}";''')
# 关闭Cursor:
cursor.close()
# 提交事务:
conn.commit()
# 关闭Connection:
conn.close()
if __name__=="__main__":
# 二维码保存地址
qrcodeSave = "./qrcode.png"
# nyist.vip扫码登录时链接
url = "https://xg.nyist.vip/student/passport/qrlogin/url/https%253A%252F%252Fxg.nyist.vip%252Faddons%252Fstufile%252Fstudent%252Fmyfiles.html"
# 用户信息
cookie={
# session ID
'PHPSESSID': '',
# 微信授权成功获取的用户唯一标识
'stoken': ''
}
response = requests.get(url)
# SESSION ID 服务器创建会话的唯一标志
PHPSESSID = re.findall("PHPSESSID=(.*?);", str(response.headers))[0]
cookie['PHPSESSID']=PHPSESSID
# QRcodeuuid 信息用于获取 qrcode 的检测结果
QRcodeuuid = re.findall("data-uuid=\"(.*?)\"", str(response.text))[0]
# 获取二维码链接
url = re.findall("data-qrcode=\"(.*?)\"", str(response.text))[0]
# 二维码生成(实际上二维码与链接等价,由链接生成一个二维码)
img = qrcode.make(url)
# 将二维码保存起来
img.save(qrcodeSave)
# 轮询刚刚创建的会话,等待捕获登录成功消息
status,stoken=check_link(PHPSESSID,QRcodeuuid)
if status==0:
cookie["stoken"]=stoken['stoken']
updateCookies(cookie,"825882638")
print("更新完毕!")
保活插件:
import time
import requests
import sqlite3
import re
def get_cookies():
# 如果文件不存在,会在当前目录创建:
conn = sqlite3.connect('/root/zscDemo/pythonDemo/dayReport/dayReport.db')
# 创建一个Cursor:
cursor = conn.cursor()
# 保活请求, status 为 1
sql = "select stoken,PHPSESSID,QQ from healthydaily where status=1"
# 继续执行一条SQL语句,插入一条记录:
cursor.execute(sql)
date_list = cursor.fetchall()
# 关闭Cursor:
cursor.close()
# 提交事务:
conn.commit()
# 关闭Connection:
conn.close()
# 返回 cookie 信息
return date_list
def connect_keep():
datalist = get_cookies()
for data in datalist:
try:
Cookies = {'PHPSESSID': data[1], 'stoken': data[0]}
# 扫码后获取的cookies信息
day = requests.session()
# 清空 cookies 信息, 用于多用户的并发
day.cookies.clear()
# 携带 cookies 信息访问
day.cookies.set("PHPSESSID", Cookies["PHPSESSID"])
day.cookies.set("stoken", Cookies["stoken"])
# 访问用户中心保活 PHPSESSID
response = day.get(url="https://xg.nyist.vip/student/home/index.html")
# 如果请求后的页面有以下字段证明身份信息过期
status = re.findall(">微信扫码登录<", response.text)
date_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
if len(status) == 0:
print(f"{data[2]} 保活成功"+date_str)
except:
pass
connect_keep()
定时上报插件:
只需将数据库中的需要上报的用户信息读取出来,然后替换到相应的位置即可。
import requests
# 爬取的token
msg_token = ""
# 爬取的guest
msg_guest = ""
def main():
# 健康日报打卡
headers = {
"POST": "/v1/trace/Student/dailyreportadd HTTP/1.1",
"Host": "xg.nyist.vip",
"Connection": "keep-alive",
"Content-Length": "88",
"appid": "1",
"content-type": "application/x-www-form-urlencoded",
"guest": "***",
"token": "***",
"Referer": "https://servicewechat.com/wx5d22ba28f10a2e09/48/page-frame.html",
"Accept-Encoding": "gzip, deflate, br",
}
#位置信息
data = {
"pcc": "410000,411300,411302",
"gps": "33.0036,112.5396",
"location": "2",
"status": "0",
"temp": "0",
"contact": 0,
}
#网络请求
r = requests.post(
"https://xg.nyist.vip/v1/trace/Student/dailyreportadd", headers=headers, data=data
)
# print(r.json()['msg'])
#终端输出结果
return r.json()['msg']
if __name__ == '__main__':
print(main())
至此这个插件的编写也就结束了,虽然编写的路途很曲折但是这个探索的过程真的很优美。